Flume日志采集系统——初体验(Logstash对比版)
这两天看了一下Flume的开发文档,并且体验了下Flume的使用。
本文就从如下的几个方面讲述下我的使用心得:
- 初体验——与Logstash的对比
- 安装部署
- 启动教程
- 参数与实例分析
Flume初体验
Flume的配置是真繁琐,source,channel,sink的关系在配置文件里面交织在一起,没有Logstash那么简单明了。
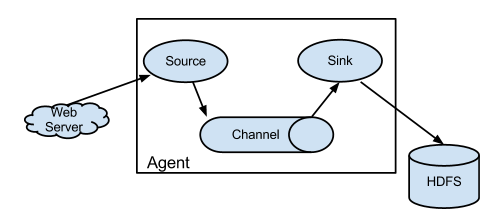
Flume与Logstash相比,我个人的体会如下:
- Logstash比较偏重于字段的预处理;而Flume偏重数据的传输;
- Logstash有几十个插件,配置灵活;FLume则是强调用户的自定义开发(source和sink的种类也有一二十个吧,channel就比较少了)。
- Logstash的input和filter还有output之间都存在buffer,进行缓冲;Flume直接使用channel做持久化(可以理解为没有filter)
Logstash浅谈:
Logstash中:
- input负责数据的输入(产生或者说是搜集,以及解码decode);
- Filter负责对采集的日志进行分析,提取字段(一般都是提取关键的字段,存储到elasticsearch中进行检索分析);
- output负责把数据输出到指定的存储位置(如果是采集agent,则一般是发送到消息队列中,如kafka,redis,mq;如果是分析汇总端,则一般是发送到elasticsearch中)
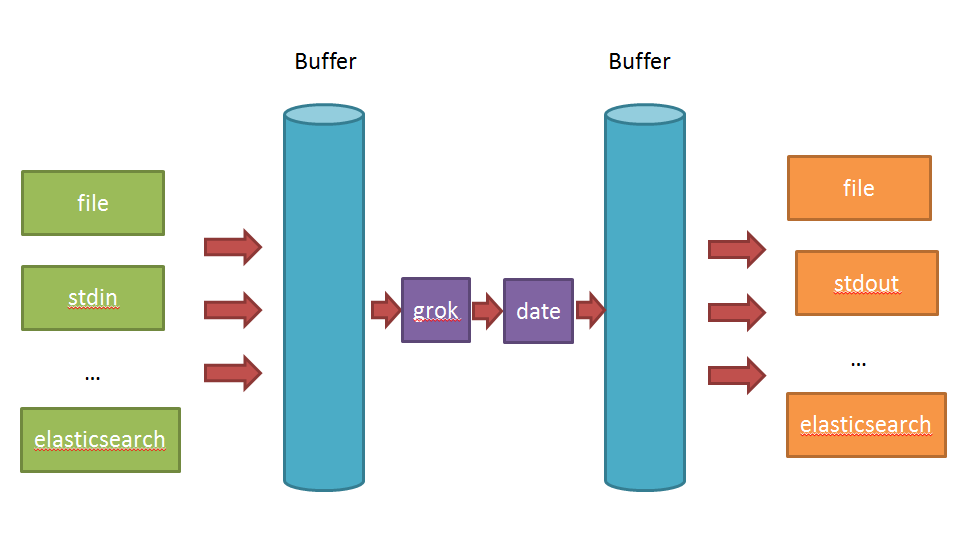
在Logstash比较看重input,filter,output之间的协同工作,因此多个输入会把数据汇总到input和filter之间的buffer中。filter则会从buffer中读取数据,进行过滤解析,然后存储在filter于output之间的Buffer中。当buffer满足一定的条件时,会触发output的刷新。
Flume浅谈:
在Flume中:
- source 负责与Input同样的角色,负责数据的产生或搜集(一般是对接一些RPC的程序或者是其他的flume节点的sink)
- channel 负责数据的存储持久化(一般都是memory或者file两种)
- sink 负责数据的转发(用于转发给下一个flume的source或者最终的存储点——如HDFS)
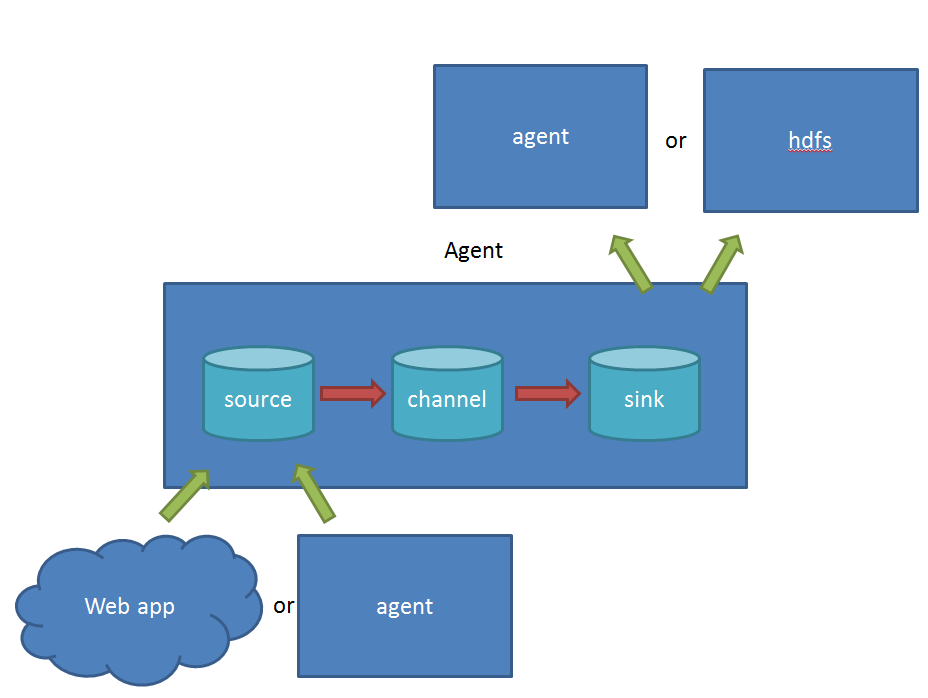
Flume比较看重数据的传输,因此几乎没有数据的解析预处理。仅仅是数据的产生,封装成event然后传输。传输的时候flume比logstash多考虑了一些可靠性。因为数据会持久化在channel中(一般有两种可以选择,memoryChannel就是存在内存中,另一个就是FileChannel存储在文件种),数据只有存储在下一个存储位置(可能是最终的存储位置,如HDFS;也可能是下一个Flume节点的channel),数据才会从当前的channel中删除。这个过程是通过事务来控制的,这样就保证了数据的可靠性。
不过flume的持久化也是有容量限制的,比如内存如果超过一定的量,也一样会爆掉。
安装
在官网下载最新版本http://flume.apache.org/download.html,目前最新的版本是1.6.0
默认flume是不支持windows的,没有bat的启动命令。不过有一个flume-ng.cmd,其实它也不是启动文件,只是启动了一个powershell而已,如果你本地有这个软件,就可以在windows下运行了。
powershell.exe -NoProfile -InputFormat none -ExecutionPolicy unrestricted -File %~dp0flume-ng.ps1 %*
目录介绍
bin
存放了启动脚本
lib
启动所需的所有组件jar包
conf
提供了几个测试配置文件
docs
文档
tools
跟日志输出有关的一个jar包(不知道有什么不同)
先来看看配置文件
# 关于license的一大堆 blabla
# 配置sources,channels,sinks的名称
agent.sources = seqGenSrc
agent.channels = memoryChannel
agent.sinks = loggerSink
# 配置sources是哪一种类型,注意可以由多个source哦!
# seq 是专门给测试用的,会自动产生一大堆数据。
# (其实我觉得stdin最好,不过flume没这个source)
agent.sources.seqGenSrc.type = seq
# 配置source输出的channel为memoryChannel(名称,你也可以叫c1)
agent.sources.seqGenSrc.channels = memoryChannel
# 配置sink是哪一种类型,本例子为logger,即log4j输出。
# (log4j会参考conf下的log4j.properties文件,一般开启consoleAppender做测试就行)
agent.sinks.loggerSink.type = logger
# 配置sink取数据的channel为memoryChannel,注意跟上面的名字保持一致哦!
agent.sinks.loggerSink.channel = memoryChannel
# 配置channel的类型
agent.channels.memoryChannel.type = memory
# 配置channel的容量
agent.channels.memoryChannel.capacity = 100
然后在flume目录下,输入下面的命令:
bin/flume-ng agent --conf-file conf/flume-conf.properties.template --name agent -Dflume.root.logger=INFO,console -C .
然后就可以看到满屏滚动的信息了!
注意:上面启动命令没一个字母是废话!
启动参数详解
你可以输入flume-ng help 获得帮助提示:
[root@10 /xinghl/flume]$ bin/flume-ng hekp
Usage: bin/flume-ng <command> [options]...
commands:
help display this help text
agent run a Flume agent
avro-client run an avro Flume client
version show Flume version info
global options:
--conf,-c <conf> use configs in <conf> directory
--classpath,-C <cp> append to the classpath
--dryrun,-d do not actually start Flume, just print the command
--plugins-path <dirs> colon-separated list of plugins.d directories. See the
plugins.d section in the user guide for more details.
Default: $FLUME_HOME/plugins.d
-Dproperty=value sets a Java system property value
-Xproperty=value sets a Java -X option
agent options:
--name,-n <name> the name of this agent (required)
--conf-file,-f <file> specify a config file (required if -z missing)
--zkConnString,-z <str> specify the ZooKeeper connection to use (required if -f missing)
--zkBasePath,-p <path> specify the base path in ZooKeeper for agent configs
--no-reload-conf do not reload config file if changed
--help,-h display help text
avro-client options:
--rpcProps,-P <file> RPC client properties file with server connection params
--host,-H <host> hostname to which events will be sent
--port,-p <port> port of the avro source
--dirname <dir> directory to stream to avro source
--filename,-F <file> text file to stream to avro source (default: std input)
--headerFile,-R <file> File containing event headers as key/value pairs on each new line
--help,-h display help text
Either --rpcProps or both --host and --port must be specified.
这里就挑重要的参数将了:
commands 命令参数
这个是很重要的参数,因为flume可以使用不同的角色启动,比如agent以及client等等。暂时搞不清楚avro-client有什么特殊的,先了解一下吧!平时启动就使用agent就可以了。
global options 全局参数
--conf 或者 -c ,指定去conf目录下加载配置文件
--classpath 或者 -C,指定类加载的路径(不知道为什么我下载flume版本启动的时候找不到log4j配置,只能加上 -C .才能启动!)
command 指定
-Dproperty=value 这个参数比较重要,比如logger就需要它来指定传输的级别等信息。如果没有这个参数,logger就不好使了。
agent options agent启动选项
其中最终要的就是 --name 或者 -n ,它指定了启动agent的名称,注意是启动agent的名称。
这个名称必须与配置文件中的一样
这个名称必须与配置文件中的一样
这个名称必须与配置文件中的一样
重要的事情重复三遍!
如果写错了!一段小异常就跑来了~(比如我配置文件中为agent,启动命令中写agent123)
2016-06-30 17:04:19,529 (conf-file-poller-0) [WARN - org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:133)] No configuration found for this host:agent123
另外,就是通过--conf-file 或者 -f 指定配置文件。如果配置文件放在conf,也等同于--conf。
参数就介绍到这里了。
参考
Flume日志采集系统——初体验(Logstash对比版)的更多相关文章
- Flume 实战(1) -- 初体验
前言: Flume-ng是数据收集/聚合/传输的组件, Flume-ng抛弃了Flume OG原本繁重的zookeeper和Master, Collector, 其整体的架构更加的简洁和明了. 其基础 ...
- Flume日志采集系统
1.简介 Flume是Cloudera提供的一个高可用.高可靠.分布式的海量日志采集.聚合和传输的系统. Flume支持在日志系统中定制各类数据发送方用于收集数据,同时Flume提供对数据进行简单的处 ...
- 在同一个硬盘上安装多个 Linux 发行版及 Fedora 21 、Fedora 22 初体验
在同一个硬盘上安装多个 Linux 发行版 以前对多个 Linux 发行版的折腾主要是在虚拟机上完成.我的桌面电脑性能比较强大,玩玩虚拟机没啥问题,但是笔记本电脑就不行了.要在我的笔记本电脑上折腾多个 ...
- Net Core平台灵活简单的日志记录框架NLog+SqlServer初体验
Net Core平台灵活简单的日志记录框架NLog+SqlServer初体验 前几天分享的"[Net Core平台灵活简单的日志记录框架NLog+Mysql组合初体验][http://www ...
- Net Core平台灵活简单的日志记录框架NLog+Mysql组合初体验
Net Core平台灵活简单的日志记录框架NLog初体验 前几天分享的"[Net Core集成Exceptionless分布式日志功能以及全局异常过滤][https://www.cnblog ...
- scribe、chukwa、kafka、flume日志系统对比
scribe.chukwa.kafka.flume日志系统对比 1. 背景介绍许多公司的平台每天会产生大量的日志(一般为流式数据,如,搜索引擎的pv,查询等),处理 这些日志需要特定的日志系统,一 ...
- Python 3.8.0 正式版发布,新特性初体验 全面介绍
Python 3.8.0 正式版发布,新特性初体验 北京时间 10 月 15 日,Python 官方发布了 3.8.0 正式版,该版本较 3.7 版本再次带来了多个非常实用的新特性. 赋值表达式 PE ...
- Serverless 初体验:快速开发与部署一个Hello World(Java版)
昨天被阿里云的这个酷炫大屏吸引了! 我等85后开发者居然这么少!挺好奇到底什么鬼东西都是90.95后在玩?就深入看了一下. 这是一个关于Serverless的体验活动,Serverless在国内一直都 ...
- 【转】Flume日志收集
from:http://www.cnblogs.com/oubo/archive/2012/05/25/2517751.html Flume日志收集 一.Flume介绍 Flume是一个分布式.可 ...
随机推荐
- 图片轮播 js代码
<script type="text/javascript"> //图片轮换 $(function () { //------------------ var sWid ...
- CSS有三种基本的定位机制
CSS有三种基本的定位机制:普通流,浮动和绝对定位. 普通流:在普通流中元素框的位置由元素在html中的位置决定, 1.元素position属性为static或继承来的static时就会按照普通流定位 ...
- 【洛谷P2513】逆序对数列
前缀和.滚动数组优化dp f[i][j]表示前i个数,逆序对数为j的方案数 我们知道,在第k个位置放第i个数,单步得到的逆序对数为i-k 则在前i个数,最多能产生的逆序对数为i个,最少0个,均可转移到 ...
- spfa判断负环
会了spfa这么长时间竟然不会判断负环,今天刚回.. [例题]poj3259 题目大意:当农场主 John 在开垦他的农场时,他发现了许多奇怪的昆虫洞.这些昆虫洞是单向的,并且可以把你从入口送到出口, ...
- btn-default
Bootstrap 还有一种属于按钮的 class 属性叫做btn-default . to
- 最小和(min)
题目描述: N 个数排成一排,你可以任意选择连续的若干个数,算出它们的和.问该如何选择才能 使得和的绝对值最小. 如:N=8 时,8个数如下: 1 2 3 4 5 6 ...
- 51单片机对无线模块nRF24L01简单的控制收发程序
它的一些物理特性如工作频段.供电电压.数据传输速率就不详细介绍了,直接上代码. 1.首先是发送端: // Define SPI pins #include <reg51.h> #defin ...
- FreeMarker如何输出特殊含义字符
$.#.{.}这几个字符在FreeMarker中有着特殊的含义,当需要在FreeMarker中输出这几个字符时,可采取如下办法: ${r"#{foo}"}.${r"#{& ...
- 第54讲:Scala中复合类型实战详解
今天学习了scala的复合类型的内容,让我们通过实战来看看代码: trait Compound_Type1trait Compound_Type2class Compound_Type extends ...
- Linux系统部署体验中心
Linux系统部署体验中心 安装Linux虚拟机 1. 下载安装VMware,安装64位Linux系统(Ubuntu),要求:CPU双核,2G内存,60G硬盘 2. 安装系统时,选择安装ssh服务 ...