Spark读写Hbase的二种方式对比
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处
一.传统方式
这种方式就是常用的TableInputFormat和TableOutputFormat来读写hbase,如下代码所示
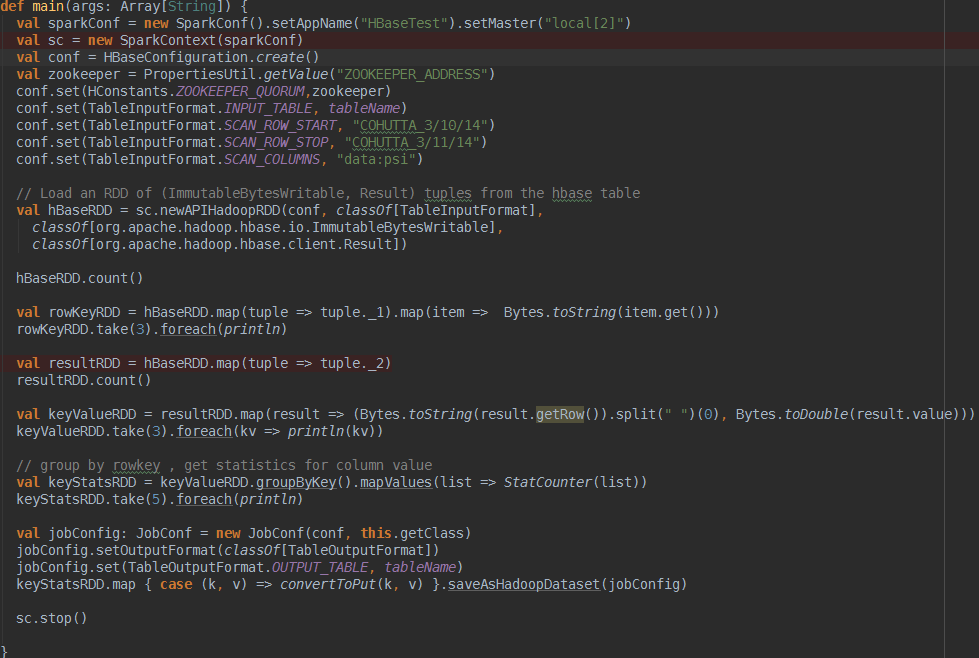
简单解释下,用sc.newAPIHadoopRDD根据conf中配置好的scan来从Hbase的数据列族中读取包含(ImmutableBytesWritable, Result)的RDD,
随后取出rowkey和value的键值对儿利用StatCounter进行一些最大最小值的计算最终写入hbase的统计列族.
二.SparkOnHbase方式
重点介绍第二种方式,这种方式其实是利用Cloudera-labs开源的一个HbaseContext的工具类来支持spark用RDD的方式批量读写hbase,先给个传送门大家感受下
https://issues.apache.org/jira/browse/HBASE-13992
https://issues.apache.org/jira/browse/HBASE-14160
虽然这个hbase-spark的module在Hbase上的集成任务很早就完成了,但是已知发布的任何版本我还没找到该模块,不知道什么情况,再等等吧
那么问题来了,这种方式的优势在哪儿呢,官方的解释我翻译如下
1>无缝的使用Hbase connection
2>和Kerberos无缝集成
3>通过get或者scan直接生成rdd
4>利用RDD支持hbase的任何组合操作
5>为通用操作提供简单的方法,同时通过API允许不受限制的未知高级操作
6>支持java和scala
7>为spark和 spark streaming提供相似的API
ok,由于hbaseContext是一个只依赖hadoop,hbase,spark的jar包的工具类,因此可以拿过来直接用
废话不说,直接用我调试过的代码来感受下
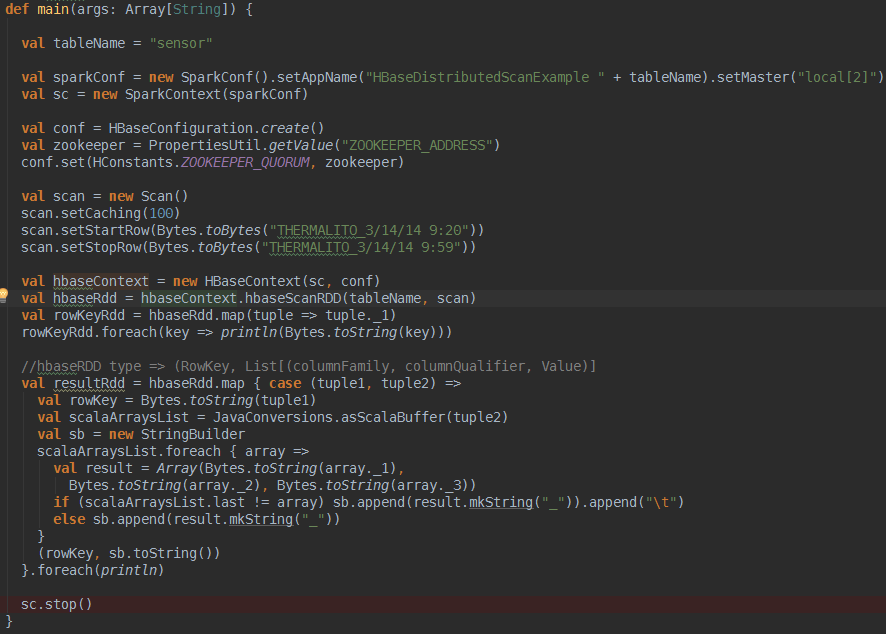
想用HbaseContext很简单,如上面代码所示,需要说明的是hbaseContext的hbaseScanRDD方法,这个方法返回的是一个
(RowKey, List[(columnFamily, columnQualifier, Value)]类型的RDD,如下
刚开始用的挺不习惯的.还得循环取出来rowkey对应的这么多列,这里你如果对它的RDD返回类型不爽,官方很贴心的提供了另外一个方法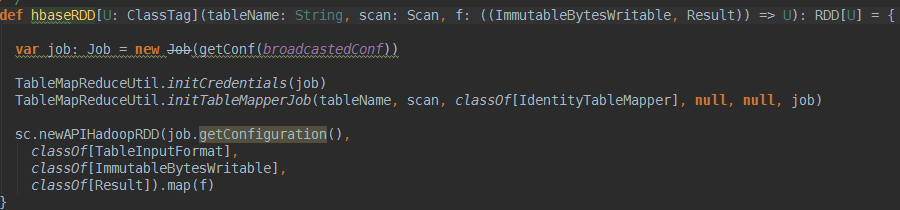
怎么样,是不是看着很眼熟了?你可以自定义第三个参数(ImmutableBytesWritable, Result),对函数f进行自定义来返回你自己喜欢的RDD格式,
程序运行结果如下,过滤出了9:20到9:58所有的rowkey以及对应的列

当然HbaseContext还有其他bulkGet,bulkPut,bulkDelete等,都是可以直接将hbase的操作转换成RDD,只要转成RDD了,那么rdd的这么多transform和action就可以玩的很happy了.
参考资料
https://github.com/cloudera-labs/SparkOnHBase
http://blog.cloudera.com/blog/2015/03/how-edmunds-com-used-spark-streaming-to-build-a-near-real-time-dashboard/
https://blog.cloudera.com/blog/2014/12/new-in-cloudera-labs-sparkonhbase/
Spark读写Hbase的二种方式对比的更多相关文章
- Spark入Hbase的四种方式效率对比
一.方式介绍 本次测试一种采用了四种方式进行了对比,分别是:1.在RDD内部调用java API.2.调用saveAsNewAPIHadoopDataset()接口.3.saveAsHadoopDat ...
- Spark:DataFrame批量导入Hbase的两种方式(HFile、Hive)
Spark处理后的结果数据resultDataFrame可以有多种存储介质,比较常见是存储为文件.关系型数据库,非关系行数据库. 各种方式有各自的特点,对于海量数据而言,如果想要达到实时查询的目的,使 ...
- UserView--第二种方式(避免第一种方式Set饱和),基于Spark算子的java代码实现
UserView--第二种方式(避免第一种方式Set饱和),基于Spark算子的java代码实现 测试数据 java代码 package com.hzf.spark.study; import ...
- Linux上删除大量文件几种方式对比
目录 Linux上删除大量文件几种方式对比 1. rm删除:因为文件数量太多,rm无法删除(报错) 2. find查找删除:-exec 3. find查找删除:xargs 4. find调用-dele ...
- Spark读写HBase
Spark读写HBase示例 1.HBase shell查看表结构 hbase(main)::> desc 'SDAS_Person' Table SDAS_Person is ENABLED ...
- Android自动化测试中AccessibilityService获取控件信息(2)-三种方式对比
Android自动化测试中AccessibilityService获取控件信息(2)-三种方式对比 上一篇文章: Android自动化测试中AccessibilityService获取控件信息(1 ...
- spark读写hbase性能对比
一.spark写入hbase hbase client以put方式封装数据,并支持逐条或批量插入.spark中内置saveAsHadoopDataset和saveAsNewAPIHadoopDatas ...
- Python读写文件的几种方式
一.pandas pandas模块是数据分析的大杀器,它使得对于文件相关的操作变得简单. 看一下它的简单使用 import pandas as pd # 读取 df = pd.read_csv('al ...
- spark DataFrame的创建几种方式和存储
一. 从Spark2.0以上版本开始,Spark使用全新的SparkSession接口替代Spark1.6中的SQLContext及HiveContext接口来实现其对数据加载.转换.处理等功能.Sp ...
随机推荐
- CSS 3学习——animation动画
以下内容根据官方文档翻译以及自己的理解整理. 1. 介绍 本方案介绍动画(animations).通过动画,开发者可以将CSS属性值的变化指定为一个随时间变化的关键帧(keyframes)的集合.在 ...
- 前端框架 EasyUI (0) 重新温习(序言)
几年前,参与过一个项目.那算是一个小型的信息管理系统,BS 结构的,前端用的是基于 jQuery 的 EasyUI 框架. 我进 Team 的时候,项目已经进入开发阶段半个多月了.听说整个项目的框架是 ...
- DBImport V3.7版本发布及软件稳定性(自动退出问题)解决过程分享
DBImport V3.7介绍: 1:先上图,再介绍亮点功能: 主要的升级功能为: 1:增加(Truncate Table)清表再插入功能: 清掉再插,可以保证两个库的数据一致,自己很喜欢这个功能. ...
- 微软.NET Core RC2正式发布,横跨所有平台
.NET官方博客宣布了<Announcing .NET Core RC2 and .NET Core SDK Preview 1>,正式如期发布了.NET Core RC2, 现在可以放心 ...
- Spring之旅
Java使得以模块化构建复杂应用系统成为可能,它为Applet而来,但为组件化而留. Spring是一个开源的框架,最早由Rod Johnson创建.Spring是为了解决企业级应用开发的复杂性而创建 ...
- 设置tomcat远程debug
查看端口占用情况命令: netstat -tunlp |grep 8000 tomcat 启动远程debug: startup.sh 中的最后一行 exec "$PRGDIR"/& ...
- PHP之用户验证和标签推荐的简单使用
本篇主要是讲解一些最简单的验证知识 效果图 bookmark_fns.php <?php require_once('output_fns.php'); require_once('db_fns ...
- JAVA面试题
在这里我将收录我面试过程中遇到的一些好玩的面试题目 第一个面试题:ABC问题,有三个线程,工作的内容分别是打印出"A""B""C",需要做的 ...
- BPM协同平台解决方案分享
一.需求分析 企业信息化的过程都是从单纯解决一个业务功能问题,到解决企业内部业务流程问题,再扩展到解决不同业务流程的关联互动问题, 核心是业务的集成和业务的协同,需要有一个统一的业务协同平台. 国内的 ...
- 易用BPM时代,软件开发者缘何选择H3?
近年来,企业级软件开发市场暗流汹涌,呈现出多种态势.软件开发团队规模趋于小型化,工作方式趋于快捷化,超过半数的软件开发者在工作中会选择使用易用的软件开发工具.随着流程管理越来越受到企业的重视,流程开发 ...