你应该了解的hooks式接口编程 - useSWR
什么是 useSWR ?
听名字我们都知道是一个 React 的 hooks,SWR 是stale-while-revalidate的缩写, stale 的意思是陈旧的, revalidate 的意思是重新验证/使重新生效, 合起来的意识可以理解成 在重新验证的过程中先使用陈旧的,在http 请求中意味着先使用已过期的数据缓存,同时请求新的数据去刷新缓存。
这在 http 请求中Cache-Control响应头中已经实现,比如:
Cache-Control: max-age=60, stale-while-revalidate=3600
这意味着在缓存过期时间为60秒,当缓存过期时,你请求了该接口,并且在缓存过期后的3600内,会先使用原来过期的缓存作为结果返回,同时会请求服务器去刷新缓存。
示例:
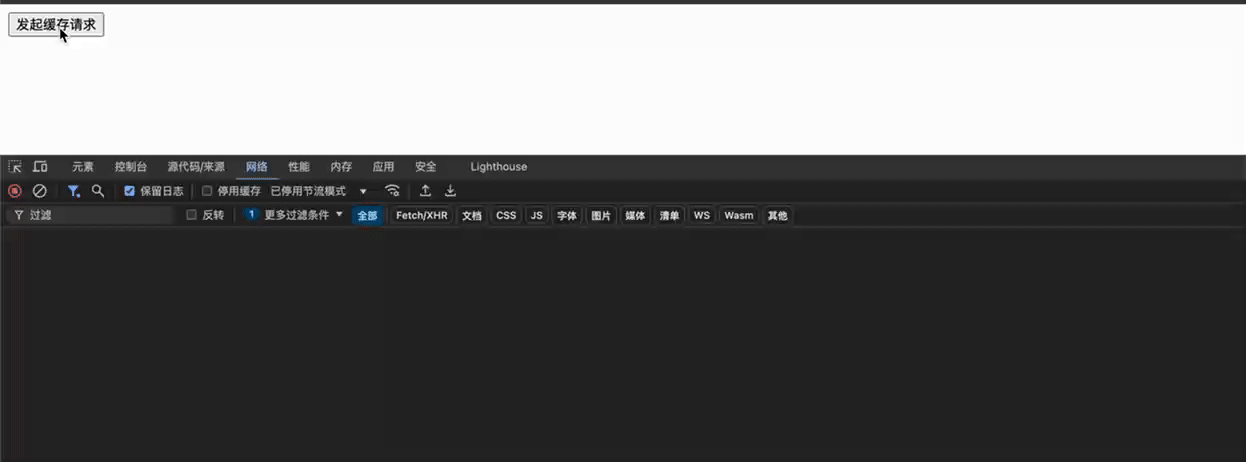
未使用 swr 的情况,缓存过期后直接重放304协商缓存请求
使用 swr 的情况,缓存过期后直接返回200过期的缓存数据,再进行304协商缓存请求
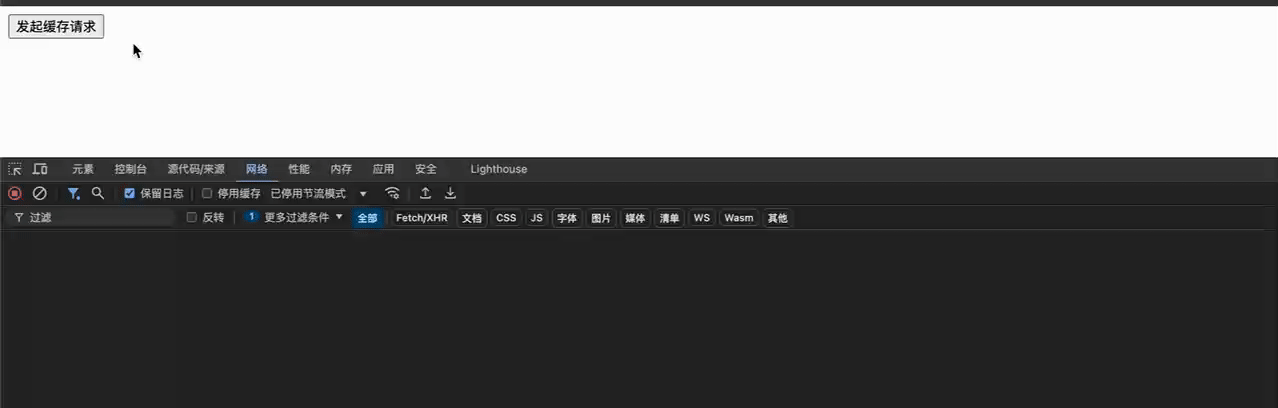
但通过 nginx 等网关层来实现 swr ,没法做到接口缓存的精确控制,并且即使revalidate后的fresh数据返回了,也没法让页面重新渲染,只能等待下次接口请求。
useSWR直接在前端代码层实现了http请求SWR缓存的功能。
使用方式
在传统模式下,我们会这样写一个数据请求, 需要通过定义多个状态来管理数据请求, 并在副作用中进行指令式的接口调用。
import { useEffect, useState } from "react";
import Users from "./Users";
export default function App() {
const [users, setUsers] = useState([]);
const [isLoading, setLoading] = useState(false);
const getUsers = () => {
setLoading(true);
fetch("/api/getUsers")
.then((res) => res.json())
.then((data) => {
setUsers(data);
})
.finally(() => {
setLoading(false)
})
}
useEffect(() => {
getUsers();
}, []);
return (
<div>
{isLoading && <h2>loading... </h2>}
<UserList users={users} />
</div>
);
}
使用 useSWR 后, 我们只需要告诉 SWR 这个请求的唯一 key, 与如何处理该请求的 fetcher 方法,在组件挂载后会自动进行请求
import useSWR from "swr";
import Users from "./Users";
const fetcher = (...args) => fetch(...args).then((res) => res.json())
export default function App() {
const { data: users, isLoading, mutate } = useSWR('/api/getUsers', fetcher)
return (
<div>
{isLoading && <h2>loading... </h2>}
<UserList users={users} />
</div>
);
}
useSWR的入参
key: 请求的唯一key,可以为字符串、函数、数组、对象等fetcher:(可选)一个请求数据的 Promise 返回函数options:(可选)该 SWR hook 的选项对象
key 会作为入参传递给 fetcher 函数, 一般来说可以是请求的URL作为key。可以根据场景自定义 key 的格式,比如我有额外请求参数,那么就把 key 定义成一个数组 ['/api/getUsers', { pageNum: 1 }], SWR会在内部自动序列化 key 值,以进行缓存匹配。
useSWR的返回
data: 通过fetcher处理后的请求结果, 未返回前为undefinederror:fetcher抛出的错误isLoading: 是否有一个正在进行中的请求且当前没有“已加载的数据“。isValidating: 是否有请求或重新验证加载mutate(data?, options?): 更改缓存数据的函数
核心
全局缓存机制
我们每次使用 SWR 时都有用到 key,这将作为唯一标识将结果存入全局缓存中,这种默认缓存的行为其实非常有用。
例如获取用户列表在我们产品中是一个非常频繁的请求,细分下来用户列表都会有很多个接口
我们在写需求时,可能不知道这个接口数据有没有往 redux 中存过,并且往 redux 中放数据是个相对麻烦的操作有管理成本,那么大多数人的做法就是那有地方用,我就重新请求一遍。
例如一个模态框里存在用户列表,每次打开都要请求一次 (带远程搜索),用户每次都需要等待,当然你也可以把用户列表状态提升到模态框外面,但对应的就会有取舍,外部父组件其实根本不关心用户列表状态。
请求状态区分
当第一次请求,也就是没有找到对应 key 的缓存时,那么就会立即发起请求,isLoading 与 isValidating 都为 true。
当第二次请求时,有缓存,那么先拿缓存数据渲染,再进行请求,isValidating 为 true。
也就是说只要正在请求中,就是 isValidating, 无缓存数据且正在请求时才为isLoading状态。
对应的状态图:

以上的案例中都是 key 为固定值的情况,但更多场景下 key 值会由于请求参数的变动而变动。
如一个搜索用户的 key 这样定义
const [search, setSearch] = useState('');
const { data } = useSWR(['/api/users', search], fetcher)
每次输入都会导致 key 变化,key 变化默认就会重新请求接口,但其实 key 变化了也就代表了数据不可信了,需要里面重置数据,因此 data 会被立即重置为 undfined 。如果新的 key 已经有缓存值,那么也会先拿缓存值进行渲染。
那么其实我们几乎什么额外代码也没加,就实现了一个自带数据缓存的用户搜索功能。
对应的key变化时的状态图:

假如我们偏要保留 key 变化前的数据先展示呢?因为我们还是会看到短暂的no-data
我们主要在第三个参数 options 中加入配置项 keepPreviousData 即可实现

实现效果与我们 gitlab 搜索分支时其实是一致的
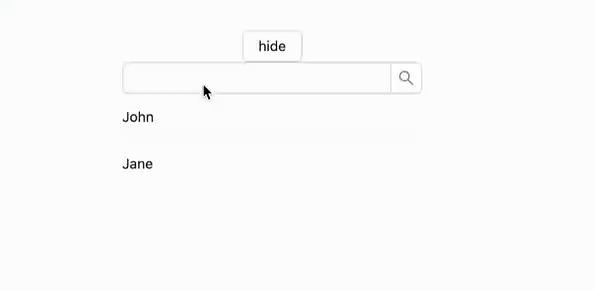
key变化且保留数据的状态图:

联动请求与手动触发
很多情况下接口请求都依赖于另外一个接口请求的结果,或者在某种情况下才发起请求。
首先如何让组件挂载时不进行请求,有三种方法
配置项实现
设置 options 参数 revalidateOnMount , 这种方法如果已有缓存数据,仍然会拿缓存数据渲染\
依赖模式
给定 key 时返回 falsy 值 或者 提供函数并抛出错误
const { data } = useSWR(isMounted ? '/api/users' : null, fetcher)
const { data } = useSWR(() => isMounted ? '/api/users' : null, fetcher)
// 抛出错误
const { data: userInfo } = useSWR('/api/userInfo')
const { data } = useSWR(() => '/api/users?uid=' + userInfo.id, fetcher)
那我们实现一个业务场景:数据源-数据库-数据表的联动请求

我们几乎以一种自动化的方式实现了联动请求。
以下是代码示例:
const DependenceDataSource = () => {
const [form] = Form.useForm();
const dataSourceId = Form.useWatch("dataSourceId", form);
const dbId = Form.useWatch("dbId", form);
const { data: dataSourceList = [], isValidating: isDataSourceFetching } =
useSWR({ url: "/getDataSource" }, dataSourceFetcher);
const { data: dbList = [], isValidating: isDatabaseFetching } = useSWR(
() =>
dataSourceId
? { url: "/getDatabase", params: { dataSourceId } }
: null,
databaseFetcher
);
const { data: tableList = [], isValidating: isTableFetching } = useSWR(
() =>
dataSourceId && dbId
? { url: "/getTable", params: { dataSourceId, dbId } }
: null,
tableFetcher
);
return (
<Form
form={form}
style={{width: 400}}
layout="vertical"
onValuesChange={(changedValue) => {
if ("dataSourceId" in changedValue) {
form.resetFields(["dbId", "tableId"]);
}
if ("dbId" in changedValue) {
form.resetFields(["tableId"]);
}
}}
>
<Form.Item name="dataSourceId" label="数据源">
<Select
placeholder="请选择数据源"
options={dataSourceList}
loading={isDataSourceFetching}
allowClear
/>
</Form.Item>
<Form.Item name="dbId" label="数据库">
<Select
placeholder="请选择数据库"
options={dbList}
loading={isDatabaseFetching}
allowClear
/>
</Form.Item>
<Form.Item name="tableId" label="数据表">
<Select
placeholder="请选择数据表"
options={tableList}
loading={isTableFetching}
allowClear
/>
</Form.Item>
</Form>
);
};
采用手动挡模式
使用上面这种方法利用了 key 变化会自动revalidate数据的机制实现了联动,但是有个非常大的弊端,你需要把 key 中所有的依赖参数都提取为state使组件能够重新 render 以进行revalidate。有点强制你使用受控模式的感觉,这会造成性能问题。
所以我们需要利用mutate进行手动请求, mutate(key?, data, options),
你可以直接从 swr 全局引入mutate方法,也可以使用 hooks 返回的 mutate 方法。
区别:
- 全局
mutate需要额外提供 key - hooks 内
mutate直接绑定了key
// 全局使用
import { mutate } from "swr"
function App() {
mutate(key, data, options)
}
// hook使用
const UsersMutate = () => {
const { data, mutate } = useSWR({ url: "/getNewUsers" }, fetcher, {
revalidateOnFocus: false,
dedupingInterval: 0,
revalidateOnMount: false
});
return (
<div>
<Input.Search
onSearch={(value) => {
mutate([{ id: 3, name: "user_" + value }]);
}}
/>
<List style={{ width: 300 }}>
{data?.map((user) => (
<List.Item key={user.id}>{user.name}</List.Item>
))}
</List>
</div>
);
}
mutate 后会立马使用传入的 data 更新缓存,然后会再次进行一次 revalidate 数据刷新
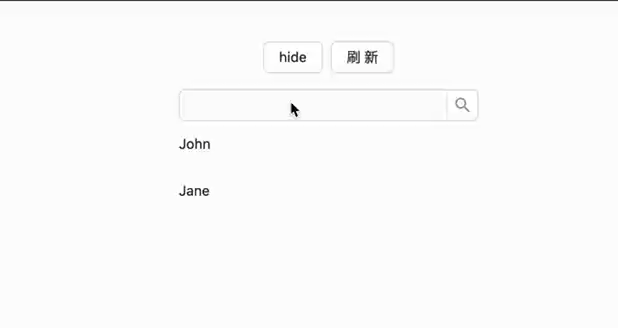
使用全局mutate传入 key { url: "/getNewUsers" } 后能够实现一样的效果,并且使用全局mutate
传入的 key 为函数时,你可以批量清除缓存。注意: mutate 中 key 传入函数表示过滤函数,与 useSWR 中传入 key 函数意义不同。
mutate(
(key) => typeof key === 'object' && key.api === getUserAPI && key.params.search !== '',
undefined,
{
revalidate: false
}
);
但是,我们可以注意到现在传入的key是不带有请求参数的,hooks中mutate也无法修改绑定的key值,那么怎么携带请求参数呢?
useSWRMutation
useSWRMutation为一种手动模式的 SWR,只能通过返回的trigger方法进行数据更新。
这意味着:
- 它不会自动使用缓存数据
- 它不会自动写入缓存(可以通过配置修改默认行为)
- 不会在组件挂载时或者 key 变化时自动请求数据
它的函数返回稍有不同:
const { data, isMutating, trigger, reset, error } = useSWRMutation(
key,
fetcher, // fetcher(key, { arg })
options
);
trigger('xxx')
useSWRMutation 的fetcher函数额外可以传递一个arg参数, 在 trigger可以中传递该参数,那么我们再来实现2.1依赖模式中的依赖联动请求。
- 定义三个 fetcher, 接收参数, 这里参数不晓得为啥一定设计成
{ arg }形式
const dataSourceFetcher = (key) => {
return new Promise<any[]>((resolve) => {
request(key).then((res) => resolve(res))
});
};
const databaseFetcher = (key, { arg }: { arg: DatabaseParams }) => {
return new Promise<any[]>((resolve) => {
const { dataSourceId } = arg;
if (!dataSourceId) return resolve([])
request(key, { dataSourceId }).then((res) => resolve(res))
});
};
const tableFetcher = (key, { arg }: { arg: TableParams }) => {
return new Promise<any[]>((resolve) => {
const { dataSourceId, dbId } = arg;
if (!dataSourceId || !dbId) return resolve([])
request(key, { dataSourceId, dbId }).then((res) => resolve(res))
});
};
- 定义 hooks
const { data: dataSourceList = [], isValidating: isDataSourceFetching } =
useSWR({ url: "/getDataSource" }, dataSourceFetcher);
const { data: dbList = [], isMutating: isDatabaseFetching, trigger: getDatabase, reset: clearDatabase } = useSWRMutation(
{ url: "/getDatabase" },
databaseFetcher,
);
const { data: tableList = [], isMutating: isTableFetching, trigger: getTable, reset: clearTable } = useSWRMutation(
{ url: "/getTable" },
tableFetcher
);
- 手动触发
<Form
onValuesChange={(changedValue) => {
if ("dataSourceId" in changedValue) {
form.resetFields(["dbId", "tableId"]);
clearDatabase();
clearTable();
getDatabase({ dataSourceId: changedValue.dataSourceId });
}
if ("dbId" in changedValue) {
form.resetFields(["tableId"]);
clearTable();
getTable({
dataSourceId: form.getFieldValue("dataSourceId"),
dbId: changedValue.dbId,
});
}
}}
>
// FormItem略
</Form>
无缓存写入

但是使用useSWRMutation这种方式,如果库表还带有远程数据搜索,就没法用到缓存特性了。
性能优化
useSWR 在设计的时候充分考虑了性能问题
- 自带节流
当我们短时间内多次调用同一个接口时,只会触发一次请求。如同时渲染多个用户组件,会触发revalidate机制,但实际只会触发一次。这个时间节流时间由dedupingInterval配置控制,默认为2000ms。
A Question, 如何实现防抖呢?无可用配置项
revalidate后freshData与staleData间进行的是深比较,避免不必要渲染, 详见dequal。依赖收集
如果没有消费hooks返回的状态,则状态变化不会导致重新渲染
const { data } = useSWR('xxx', fetcher);
// 仅在data变化时render, isValidating, isLoading由于没有引入及时变化也不会触发渲染
依赖收集的实现很巧妙
定义个ref进行依赖收集, 默认没有任何依赖

通过
get实现访问后添加

由于
state改变必定会导致渲染,所以这些状态全部由useSyncExternalStore管理

只有在不相等时才会触发渲染,如果不在stateDependencies收集中,则直接

总结
useSWR能够极大的提升用户体验,但在实际使用时,可能仍需留点小心思结合业务来看是否要使用缓存特性,如某些提交业务场景下对库表的实时性很高,这时就该考虑是否要有useSWR了。
再者,数栈产品中在实际开发中很少会对业务数据进行hooks封装,如用户列表可以封装成useUserList,表格使用useList等。感觉更多是开发习惯的原因,觉得以后自己可能也不会复用不会做过多的封装,指令式编程一把梭。
最后
欢迎关注【袋鼠云数栈UED团队】~
袋鼠云数栈 UED 团队持续为广大开发者分享技术成果,相继参与开源了欢迎 star
- 大数据分布式任务调度系统——Taier
- 轻量级的 Web IDE UI 框架——Molecule
- 针对大数据领域的 SQL Parser 项目——dt-sql-parser
- 袋鼠云数栈前端团队代码评审工程实践文档——code-review-practices
- 一个速度更快、配置更灵活、使用更简单的模块打包器——ko
- 一个针对 antd 的组件测试工具库——ant-design-testing
你应该了解的hooks式接口编程 - useSWR的更多相关文章
- 【GoLang】golang 面向对象编程 & 面向接口编程
005.面向对象&接口编程 1 面向函数编程 1.1 将数据作为参数传递到函数入参 1.2 对象与函数是分离的 2 面向对象编程 2.1 使用者看起来函数作为对象的属性而非参数 2.2 函数属 ...
- 读书笔记 effective c++ Item 41 理解隐式接口和编译期多态
1. 显示接口和运行时多态 面向对象编程的世界围绕着显式接口和运行时多态.举个例子,考虑下面的类(无意义的类), class Widget { public: Widget(); virtual ~W ...
- Java面向接口编程,低耦合高内聚的设计哲学
接口体现的是一种规范和实现分离的设计哲学,充分利用接口可以极大的降低程序中各个模块之间的耦合,提高系统的可维护性以及可扩展性. 因此,很多的软件架构设计理念都倡导"面向接口编程"而 ...
- 脑残式网络编程入门(三):HTTP协议必知必会的一些知识
本文原作者:“竹千代”,原文由“玉刚说”写作平台提供写作赞助,原文版权归“玉刚说”微信公众号所有,即时通讯网收录时有改动. 1.前言 无论是即时通讯应用还是传统的信息系统,Http协议都是我们最常打交 ...
- 008.在C#中,显式接口VS隐式接口
原文http://www.codeproject.com/Articles/1000374/Explicit-Interface-VS-Implicit-Interface-in-Csharp (At ...
- go 学习笔记之万万没想到宠物店竟然催生出面向接口编程?
到底是要猫还是要狗 在上篇文章中,我们编撰了一则简短的小故事用于讲解了什么是面向对象的继承特性以及 Go 语言是如何实现这种继承语义的,这一节我们将继续探讨新的场景,希望能顺便讲解面向对象的接口概念. ...
- 转】C#接口-显式接口和隐式接口的实现
[转]C#接口-显式接口和隐式接口的实现 C#中对于接口的实现方式有隐式接口和显式接口两种: 类和接口都能调用到,事实上这就是“隐式接口实现”. 那么“显示接口实现”是神马模样呢? interface ...
- 多媒体(1):MCI接口编程
目录 多媒体(1):MCI接口编程 多媒体(2):WAVE文件格式分析 多媒体(3):基于WindowsAPI的视频捕捉卡操作 多媒体(4):JPEG图像压缩编码 多媒体(1):MCI接口编程
- Hibernate(八)__级联操作、struts+hibernate+接口编程架构
级联操作 所谓级联操作就是说,当你进行主对象某个操作时,从对象hibernate自动完成相应操作. 比如: Department <---->Student 对象关系,我希望当我删除一个d ...
- mybatis(二)接口编程 、动态sql 、批量删除 、动态更新、连表查询
原理等不在赘述,这里主要通过代码展现. 在mybatis(一)基础上,新建一个dao包,并在里面编写接口,然后再在xml文件中引入接口路径,其他不变,在运用阶段将比原始方法更节约时间,因为不用再去手动 ...
随机推荐
- 实用技巧:根据menuconfig定位一个驱动涉及到的源文件
根据menuconfig定位一个驱动涉及到的源文件,这个是很常用的,因为有时候你需要参考别人的驱动代码.新手不知道如何定位驱动相关源码,这篇文章将告之. 假设我手头有一块开发板,现在我想要获取板载ov ...
- CCF CSP-S 2024 提高组初赛解析
本解析不提供阅读程序与完善程序题目的代码,如有需要请通过 luogu.com.cn 相关链接 下载 如有谬误烦请指正 答案 AACBB BDABD ACBCD ✓××BC ✓✓✓BCC ✓×✓CAC ...
- 暑假集训CSP提高模拟 16
\[暑假集训CSP提高模拟 \lim_{x\rightarrow\infty}\frac{8f_{x}}{f_{x+1}}\times(\sqrt{5}+1),\ \forall f_{x}=f_{x ...
- 浅谈数栈产品里的 Descriptions 组件
我们是袋鼠云数栈 UED 团队,致力于打造优秀的一站式数据中台产品.我们始终保持工匠精神,探索前端道路,为社区积累并传播经验价值. 本文作者:修能 What's? 数栈产品里的 Description ...
- P1438 无聊的数列 题解
背景 看到题解都是差分,竟然还有建两颗线段树和二阶差分的大佬. 我感到不理解,很不理解. 题目正解 本题正解很明显就是:线段树 是的,你没有看错,就只有线段树. 很显然我们直接按照线段树板题写就可以了 ...
- AntDesign-Vue Table 查询与分页
前言 之前的增删改查小 Demo 已经快要进行到最后一步了,这节的任务是将请求数据的方式改为 分页,并且增加 分页条件查询 的功能. 页面布局 <a-table :data-source=&qu ...
- otdolist 案例
1. 渲染默认任务 2. 回车添加任务 3. 删除任务 4. 底部任务数量 5. tab栏切换 6. tab切换显示不同任务 7. 清除已完成的任务 8. 头部全选 9. 删除任务
- centos7安装python3.12
centos7 安装升级 python3.12 centos7 默认的 gcc 和 g++ 版本都很低,在有 --enable-optimizations 选项时会编译报错,因此要在 scl 环境下编 ...
- 云原生周刊:Gateway API v1.1 发布 | 2024.6.3
开源项目推荐 Grafana Tanka Tanka 是 Grafana 开发的一款用于 Kubernetes 的灵活.可重用和简洁的配置工具,是使用 YAML 进行 Kubernetes 配置的一种 ...
- CSS动画效果(鼠标滑过按钮动画)
1.整体效果 https://mmbiz.qpic.cn/sz_mmbiz_gif/EGZdlrTDJa5SXiaicFfsrcric7TJmGO6YddqC4wFPdM7PGzPHuFgvtDS7M ...