工作中这样用MQ,很香!
前言
消息队列(MQ)是分布式系统中不可或缺的技术之一。
对很多小伙伴来说,刚接触MQ时,可能觉得它只是个“传话工具”,但用着用着,你会发现它简直是系统的“润滑剂”。
无论是解耦、削峰,还是异步任务处理,都离不开MQ的身影。
下面我结合实际场景,从简单到复杂,逐一拆解MQ的10种经典使用方式,希望对你会有所帮助。
1. 异步处理:让系统轻松一点
场景
小伙伴们是不是经常遇到这样的情况:用户提交一个操作,比如下单,然后要发送短信通知。
如果直接在主流程里调用短信接口,一旦短信服务响应慢,就会拖累整个操作。
用户等得不耐烦,心态直接崩了。
解决方案
用MQ,把非关键流程抽出来异步处理。下单时,直接把“发短信”这件事丢给MQ,订单服务就能立刻响应用户,而短信的事情让MQ和消费者去搞定。
示例代码
// 订单服务:生产者
Order order = createOrder(); // 订单生成逻辑
rabbitTemplate.convertAndSend("order_exchange", "order_key", order);
System.out.println("订单已生成,发短信任务交给MQ");
// 短信服务:消费者
@RabbitListener(queues = "sms_queue")
public void sendSms(Order order) {
System.out.println("发送短信,订单ID:" + order.getId());
// 调用短信服务接口
}
深度解析
这种方式的好处是:主流程解耦,不受慢服务的拖累。订单服务只管自己的事,短信服务挂了也没关系,MQ会把消息暂存,等短信服务恢复后继续处理。
2. 流量削峰:稳住系统别崩
场景
每年的“双十一”电商大促,用户秒杀商品时一窝蜂冲进来。
突然涌入的高并发请求,不仅会压垮应用服务,还会直接让数据库“趴窝”。
解决方案
秒杀请求先写入MQ,后端服务以稳定的速度从MQ中消费消息,处理订单。
这样既能避免系统被瞬时流量压垮,还能提升处理的平稳性。
示例代码
// 用户提交秒杀请求:生产者
rabbitTemplate.convertAndSend("seckill_exchange", "seckill_key", userRequest);
System.out.println("用户秒杀请求已进入队列");
// 秒杀服务:消费者
@RabbitListener(queues = "seckill_queue")
public void processSeckill(UserRequest request) {
System.out.println("处理秒杀请求,用户ID:" + request.getUserId());
// 执行秒杀逻辑
}
深度解析
MQ在这里相当于一个缓冲池,把瞬时流量均匀分布到一段时间内处理。系统稳定性提升,用户体验更好。
3. 服务解耦:减少相互牵制
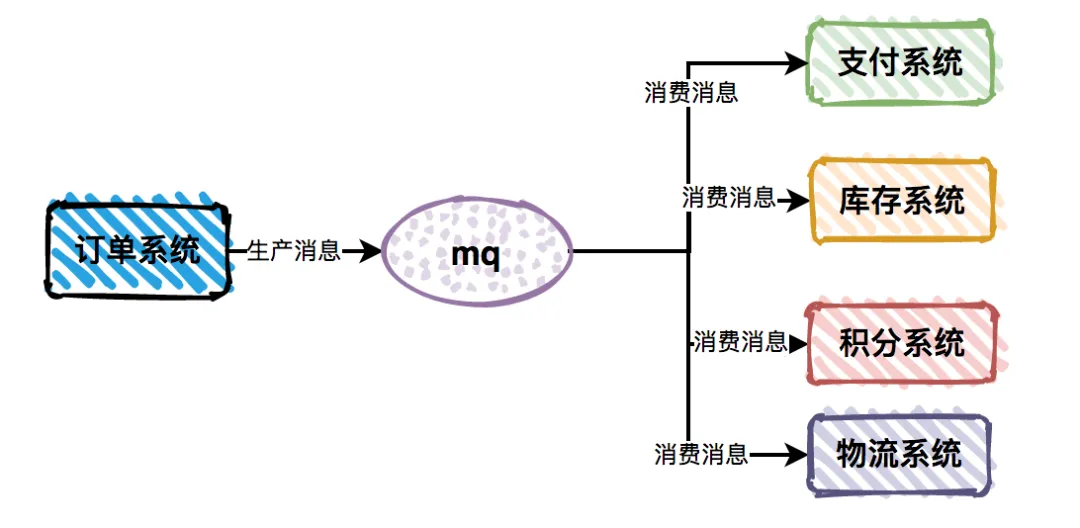
场景
比如一个订单系统需要通知库存系统扣减库存,还要通知支付系统完成扣款。
如果直接用同步接口调用,服务间的依赖性很强,一个服务挂了,整个链条都会被拖垮。
解决方案
订单服务只负责把消息丢到MQ里,库存服务和支付服务各自从MQ中消费消息。
这样订单服务不需要直接依赖它们。
示例代码
// 订单服务:生产者
rabbitTemplate.convertAndSend("order_exchange", "order_key", order);
System.out.println("订单生成消息已发送");
// 库存服务:消费者
@RabbitListener(queues = "stock_queue")
public void updateStock(Order order) {
System.out.println("扣减库存,订单ID:" + order.getId());
}
// 支付服务:消费者
@RabbitListener(queues = "payment_queue")
public void processPayment(Order order) {
System.out.println("处理支付,订单ID:" + order.getId());
}
深度解析
通过MQ,各个服务之间可以实现松耦合。
即使库存服务挂了,也不会影响订单生成的流程,大幅提升系统的容错能力。
4. 分布式事务:保证数据一致性
场景
订单服务需要同时生成订单和扣减库存,这涉及两个不同的数据库操作。
如果一个成功一个失败,就会导致数据不一致。
解决方案
通过MQ实现分布式事务。
订单服务生成订单后,将扣减库存的任务交给MQ,最终实现数据的一致性。
示例代码
// 订单服务:生产者
rabbitTemplate.convertAndSend("order_exchange", "order_key", order);
System.out.println("订单创建消息已发送");
// 库存服务:消费者
@RabbitListener(queues = "stock_queue")
public void updateStock(Order order) {
System.out.println("更新库存,订单ID:" + order.getId());
// 执行扣减库存逻辑
}
深度解析
通过“最终一致性”解决了分布式事务的难题,虽然短时间内可能有数据不一致,但最终状态一定是正确的。
5. 广播通知:一条消息,通知多个服务
场景
比如商品价格调整,库存、搜索、推荐服务都需要同步更新。
如果每个服务都要单独通知,工作量会很大。
解决方案
MQ的广播模式(Fanout)可以让多个消费者订阅同一条消息,实现消息的“一发多收”。
示例代码
// 生产者:广播消息
rabbitTemplate.convertAndSend("price_update_exchange", "", priceUpdate);
System.out.println("商品价格更新消息已广播");
// 消费者1:库存服务
@RabbitListener(queues = "stock_queue")
public void updateStockPrice(PriceUpdate priceUpdate) {
System.out.println("库存价格更新:" + priceUpdate.getProductId());
}
// 消费者2:搜索服务
@RabbitListener(queues = "search_queue")
public void updateSearchPrice(PriceUpdate priceUpdate) {
System.out.println("搜索价格更新:" + priceUpdate.getProductId());
}
深度解析
这种模式让多个服务都能接收到同一条消息,扩展性非常强。
6. 日志收集:分布式日志集中化
场景
多个服务产生的日志需要统一存储和分析。
如果直接写数据库,可能导致性能瓶颈。
解决方案
各服务将日志写入MQ,日志分析系统从MQ中消费消息并统一处理。
示例代码
// 服务端:生产者
rabbitTemplate.convertAndSend("log_exchange", "log_key", logEntry);
System.out.println("日志已发送");
// 日志分析服务:消费者
@RabbitListener(queues = "log_queue")
public void processLog(LogEntry log) {
System.out.println("日志处理:" + log.getMessage());
// 存储或分析逻辑
}
7. 延迟任务:定时触发操作
场景
用户下单后,如果30分钟内未支付,需要自动取消订单。
解决方案
使用MQ的延迟队列功能,设置消息延迟消费的时间。
示例代码
// 生产者:发送延迟消息
rabbitTemplate.convertAndSend("delay_exchange", "delay_key", order, message -> {
message.getMessageProperties().setDelay(30 * 60 * 1000); // 延迟30分钟
return message;
});
System.out.println("订单取消任务已设置");
// 消费者:处理延迟消息
@RabbitListener(queues = "delay_queue")
public void cancelOrder(Order order) {
System.out.println("取消订单:" + order.getId());
// 取消订单逻辑
}
8. 数据同步:跨系统保持数据一致
场景
在一个分布式系统中,多个服务依赖同一份数据源。
例如,电商平台的订单状态更新后,需要同步到缓存系统和推荐系统。
如果让每个服务直接从数据库拉取数据,会增加数据库压力,还可能出现延迟或不一致的问题。
解决方案
利用MQ进行数据同步。订单服务更新订单状态后,将更新信息发送到MQ,缓存服务和推荐服务从MQ中消费消息并同步数据。
示例代码
订单服务:生产者
// 更新订单状态后,将消息发送到MQ
Order order = updateOrderStatus(orderId, "PAID"); // 更新订单状态为已支付
rabbitTemplate.convertAndSend("order_exchange", "order_status_key", order);
System.out.println("订单状态更新消息已发送:" + order.getId());
缓存服务:消费者
@RabbitListener(queues = "cache_update_queue")
public void updateCache(Order order) {
System.out.println("更新缓存,订单ID:" + order.getId() + " 状态:" + order.getStatus());
// 更新缓存逻辑
cacheService.update(order.getId(), order.getStatus());
}
推荐服务:消费者
@RabbitListener(queues = "recommendation_queue")
public void updateRecommendation(Order order) {
System.out.println("更新推荐系统,订单ID:" + order.getId() + " 状态:" + order.getStatus());
// 更新推荐服务逻辑
recommendationService.updateOrderStatus(order);
}
深度解析
通过MQ实现数据同步的好处是:
- 减轻数据库压力:避免多个服务同时查询数据库。
- 最终一致性:即使某个服务处理延迟,MQ也能保障消息不丢失,最终所有服务的数据状态一致。
9. 分布式任务调度
场景
有些任务需要定时执行,比如每天凌晨清理过期订单。
这些订单可能分布在多个服务中,如果每个服务独立运行定时任务,可能会出现重复处理或任务遗漏的问题。
解决方案
使用MQ统一分发调度任务,每个服务根据自身的业务需求,从MQ中消费任务并执行。
示例代码
任务调度服务:生产者
// 定时任务生成器
@Scheduled(cron = "0 0 0 * * ?") // 每天凌晨触发
public void generateTasks() {
List<Task> expiredTasks = taskService.getExpiredTasks();
for (Task task : expiredTasks) {
rabbitTemplate.convertAndSend("task_exchange", "task_routing_key", task);
System.out.println("任务已发送:" + task.getId());
}
}
订单服务:消费者
@RabbitListener(queues = "order_task_queue")
public void processOrderTask(Task task) {
System.out.println("处理订单任务:" + task.getId());
// 执行订单清理逻辑
orderService.cleanExpiredOrder(task);
}
库存服务:消费者
@RabbitListener(queues = "stock_task_queue")
public void processStockTask(Task task) {
System.out.println("处理库存任务:" + task.getId());
// 执行库存释放逻辑
stockService.releaseStock(task);
}
深度解析
分布式任务调度可以解决:
- 重复执行:每个服务只处理自己队列中的任务。
- 任务遗漏:MQ确保任务可靠传递,防止任务丢失。
10. 文件处理:异步执行大文件任务
场景
用户上传一个大文件后,需要对文件进行处理(如格式转换、压缩等)并存储。
如果同步执行这些任务,前端页面可能会一直加载,导致用户体验差。
解决方案
用户上传文件后,立即将任务写入MQ,后台异步处理文件,处理完成后通知用户或更新状态。
示例代码
上传服务:生产者
// 上传文件后,将任务写入MQ
FileTask fileTask = new FileTask();
fileTask.setFileId(fileId);
fileTask.setOperation("COMPRESS");
rabbitTemplate.convertAndSend("file_task_exchange", "file_task_key", fileTask);
System.out.println("文件处理任务已发送,文件ID:" + fileId);
文件处理服务:消费者
@RabbitListener(queues = "file_task_queue")
public void processFileTask(FileTask fileTask) {
System.out.println("处理文件任务:" + fileTask.getFileId() + " 操作:" + fileTask.getOperation());
// 模拟文件处理逻辑
if ("COMPRESS".equals(fileTask.getOperation())) {
fileService.compressFile(fileTask.getFileId());
} else if ("CONVERT".equals(fileTask.getOperation())) {
fileService.convertFileFormat(fileTask.getFileId());
}
// 更新任务状态
taskService.updateTaskStatus(fileTask.getFileId(), "COMPLETED");
}
前端轮询或回调通知
// 前端轮询文件处理状态
setInterval(() => {
fetch(`/file/status?fileId=${fileId}`)
.then(response => response.json())
.then(status => {
if (status === "COMPLETED") {
alert("文件处理完成!");
}
});
}, 5000);
深度解析
异步文件处理的优势:
- 提升用户体验:主线程迅速返回,减少用户等待时间。
- 后台任务灵活扩展:支持多种操作逻辑,适应复杂文件处理需求。
总结
消息队列不只是传递消息的工具,更是系统解耦、提升稳定性和扩展性的利器。
在这10种经典场景中,每一种都能解决特定的业务痛点。
希望这篇文章对你理解MQ的应用场景有帮助!
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙关注一下我的同名公众号:苏三说技术,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
关注公众号:【苏三说技术】,在公众号中回复:进大厂,可以免费获取我最近整理的10万字的面试宝典,好多小伙伴靠这个宝典拿到了多家大厂的offer。
工作中这样用MQ,很香!的更多相关文章
- SqlServer一张表数据导入另一张表,收藏使用,工作中更新数据错误很有用
sql一张表数据导入另一张表 1.如果2张表的字段一致,并且希望插入全部数据,可以用这种方法: INSERT INTO 目标表 SELECT * FROM 来源表; 2.比如要将 arti ...
- 2020-04-28:工作中如何解决MQ消息堆积和消息重复的问题?
福哥答案2020-04-28:此答案来自群员,感谢群员支持. 消息堆积 只能考虑 增多消费者 以及后端其他服务 组件的吞吐能力 别的有办法吗 如果更彻底一点 分撒单个队列里的消息 队列 更分门别类 或 ...
- 工作中后端是如何将API提供出去的?swaggo很不错
工作中后端是如何将API提供出去的?swaggo很不错 咱们上一次简单分享了 GO 权限管理之 Casbin ,他一般指根据系统设置的安全规则或者安全策略 分享了权限管理是什么 Casbin 是什么 ...
- ES6在工作中会用到的核心知识点讲解
一.var, let, const 谈到ES6,估计大家首先肯定会想到var,let,const 咱就先谈谈这三者的区别 var a = 3; { var a = 4; } console.log(a ...
- 随机记录工作中常见的sql用法错误(一)
没事开始写博客,留下以前工作中常用的笔记,内容不全或者需要补充的可以留言,我只写我常用的. 网上很多类似动软生成器的小工具,这类工具虽然在表关系复杂的时候没什么软用,但是在一些简单的表结构关系还是很方 ...
- 工作中那些提高你效率的神器(第二篇)_Listary
引言 无论是工作还是科研,我们都希望工作既快又好,然而大多数时候却迷失在繁杂的重复劳动中,久久无法摆脱繁杂的事情. 你是不是曾有这样一种想法:如果我有哆啦A梦的口袋,只要拿出神奇道具就可解当下棘手的问 ...
- Atitit 软件开发中 瓦哈比派的核心含义以及修行方法以及对我们生活与工作中的指导意义
Atitit 软件开发中 瓦哈比派的核心含义以及修行方法以及对我们生活与工作中的指导意义 首先我们指明,任何一种行动以及教派修行方法都有他的多元化,只看到某一方面,就不能很好的评估利弊,适不适合自己使 ...
- C# 工作中遇到的几个问题
C# 工作中遇到的几个问题 1.将VS2010中的代码编辑器的默认字体“新宋体”改为“微软雅黑”后,代码的注释,很难对齐,特别是用SandCastle Help File Builder生成帮助文档 ...
- [工作中的设计模式]解释器模式模式Interpreter
一.模式解析 解释器模式是类的行为模式.给定一个语言之后,解释器模式可以定义出其文法的一种表示,并同时提供一个解释器.客户端可以使用这个解释器来解释这个语言中的句子. 以上是解释器模式的类图,事实上我 ...
- [工作中的设计模式]中介模式模式Mediator
一.模式解析 用一个中介者对象封装一系列的对象交互,中介者使各对象不需要显示地相互作用,从而使耦合松散,而且可以独立地改变它们之间的交互. 中介模式又叫调停者模式,他有如下特点: 1.有多个系统或者对 ...
随机推荐
- Java如何将Object转换成指定Class对象
在Java中,将Object转换为指定类型的Class对象实际上是两个不同概念的操作: 将Object实例转换为特定类型的实例:这通常涉及到类型转换(如(MyType) myObject)或者通过反射 ...
- FirewallD is not running 原因与解决方法
解决方法关于linux系统防火墙: centos5.centos6.redhat6系统自带的是iptables防火墙.centos7.redhat7自带firewall防火墙.ubuntu系统使用的是 ...
- excel导出功能的实现流程说⼀下?
导出的话,我们因为到处的数据量不⼤,所以直接采取的时候前端主导的⽅案,参考的现成⽅案实现的 导出 ⼤概得流程就是 1. 调⽤后端接⼝得到要导出的数据 2. 把数据简单处理⼀下转化成导出插件需要的格式 ...
- python中的时间处理
python程序编写中的时间处理涉及三种: 1.时间的显示: 2.时间的转换: 3.时间的运算. 时间处理模块:time模块 时间的三种表示方式: ①时间戳,从1970年1月1日开始,每过1s增加1, ...
- 鲸鸿动能广告助力App流量高效变现,促进商业增长
广告是App开发者实现流量变现的常用方法之一.当App积累了一定数量的用户后,开发者需要考虑如何有效地将流量转化为收入,以支持App的商业可持续增长. HarmonyOS SDK广告服务(Ads Ki ...
- Oracle 11.2 RAC 添加节点
软硬件环境:与上一篇文章一致: 集群中增加节点大致分为 4 个步骤: 1. 前期准备阶段:2. 新节点加入集群(安装 GI 软件):3. 新节点安装 DB 软件:4. 给新节点分配实例: 1.前期准备 ...
- AI五子棋_10 更多的算法探索
AI五子棋 第十步 恭喜你到达第十步! 你已经完成了一个AI的设计,下面就需要发动你的智慧让你的机器大脑变得更聪明了! 我们的征途是星辰大海! 更多资料可以参考这个列表 https://gomocup ...
- 多模型COE方法
1.概述 在当前的人工智能发展中,单一模型的表现往往难以满足复杂任务的需求.为应对这些挑战,多模型协作的方法应运而生,"专家组合"(Mixture of Experts)便是其中一 ...
- spring boot中使用quratz实现定时。 使用task直接调用的实现方法
1.定义工作类 2.创建配置类,将工作对象绑定到工作明细,然后创建触发器 与工作明细进行绑定 二.使用task实现定时任务 1.启动类上开启定时功能 2.在需要定时的任务上增加Schedule注解,并 ...
- Centos7安装部署prometheus
普罗米修斯的主要特点是: 具有由度量名称和键/值对标识的时间序列数据的多维数据模型 PromQL,一种灵活的查询语言, 可以利用这一维度 不依赖分布式存储; 单个服务器节点是自治的 时间序列集合通过H ...