LangChain基础篇 (01)
LangChain 是什么

Langchain 是一个开源框架,它允许开发人员将大型语言模型与外部的计算和数据源结合起来,是一个通过组合模块和能力抽象来扩展 LLM 的助手
为什么需要 LangChain
增强语言模型的功能: LangChain 提供了可以将语言模型与各种数据源(如数据库、WebAPI、文档、搜索引擎等)连接的工具,使得语言模型能够在处理复杂任务时提供更丰富的回答。
流水线(Pipelines)支持: LangChain 允许构建复杂的“流水线”,即多个步骤的组合。例如,开发者可以设计一个任务,在多个步骤中使用不同的语言模型和数据源。这对于处理多阶段推理或需要上下文依赖的任务非常有用。
与外部工具的集成: LangChain 支持与其他外部服务和工具的集成,如数据库、搜索引擎、API等。这使得它特别适合构建需要动态获取外部数据、并基于这些数据生成响应的应用。
聊天和对话管理: LangChain 提供了内建的对话管理功能,能够追踪对话上下文,处理多轮对话,以及确保对话的连贯性。这对于构建对话型应用,如聊天机器人、虚拟助手等非常重要。
分布式和并行计算: 对于大型任务或高并发应用,LangChain 提供了并行处理和分布式计算的能力,这能够有效提升处理速度和效率。
自动化任务和工作流: 通过 LangChain,开发者可以构建自动化的工作流(如数据抓取、文本生成等),这些任务可以被组合成复杂的应用。
LangChain 典型使用场景
Langchain 的应用场景非常广泛,包括但不限于:
个人助手:可以帮助预订航班、转账、缴税等。
学习辅助:可以参考整个课程大纲,帮助你更快地学习材料。
数据分析和数据科学:连接到公司的客户数据或市场数据,极大地促进数据分析的进展。
总之,Langchain 打开了一个充满可能性的新世界,让AI技术更加贴近我们的实际需求和数据,使得机器学习应用的发展更加多样化和个性化。
LangChain 基础概念与模块化设计
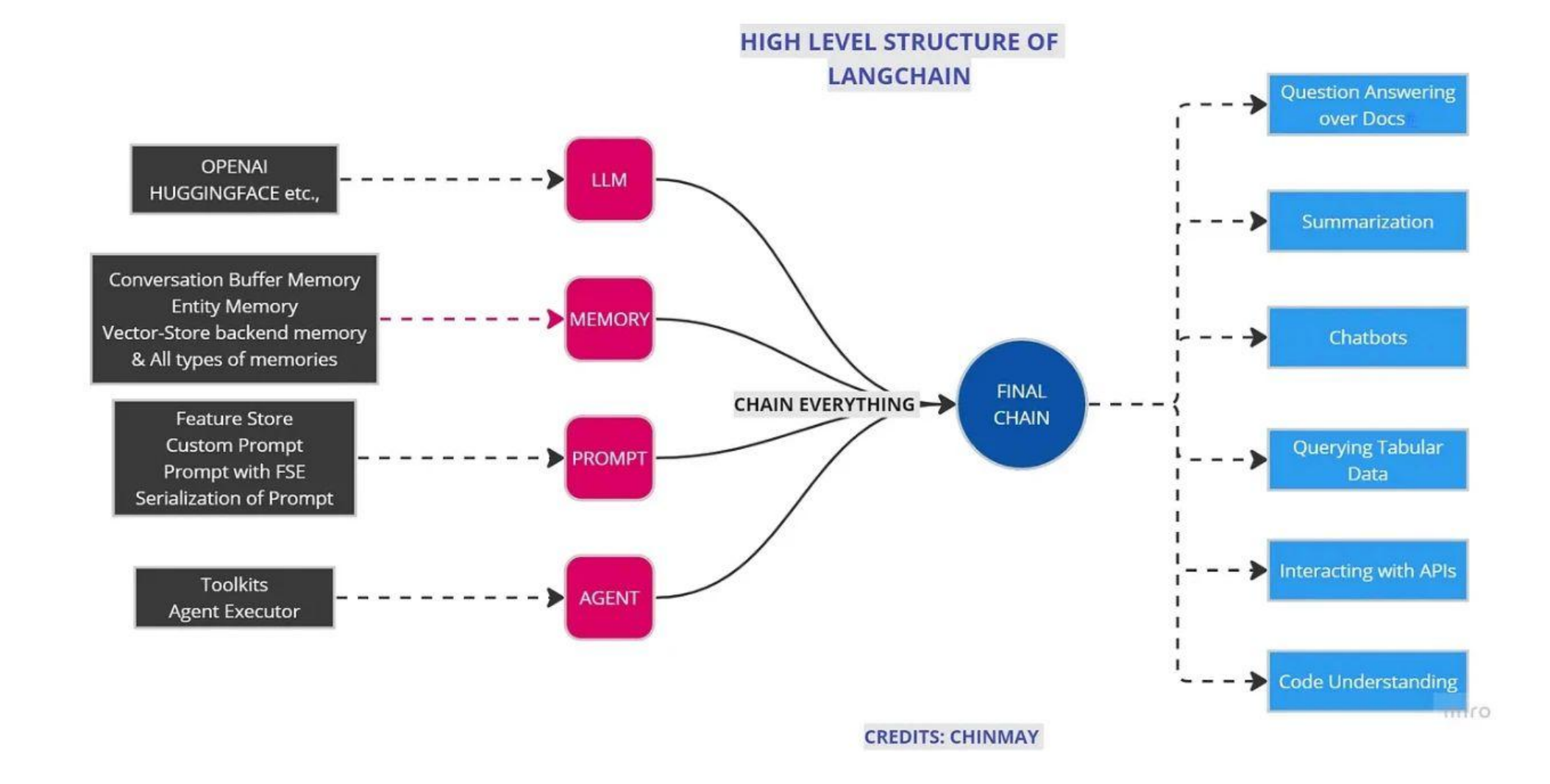
LangChain 核心模块
标准化的大模型抽象:Model I/O
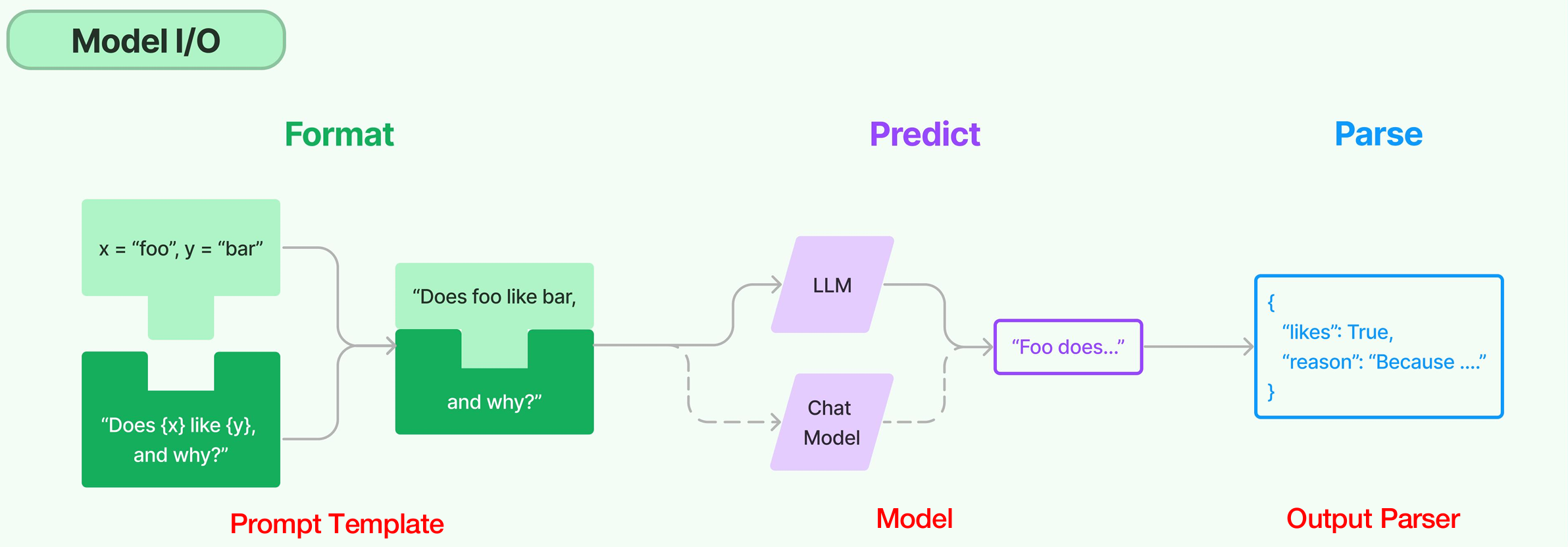
- Model I/O 是 LangChain 为开发者提供的一套面向 LLM 的标准化模型接口,包括模型本身(Models),模型输入(Prompts)和模型输出(Output Parsers)。
模型:Models
- 语言模型(LLMs): LangChain 的核心组件。LangChain并不提供自己的LLMs,而是为与许多不同的LLMs(OpenAI、Cohere、Hugging Face等)进行交互提供了一个标准接口。
- 聊天模型(Chat Models): 语言模型的一种变体。虽然聊天模型在内部使用了语言模型,但它们提供的接口略有不同。与其暴露一个“输入文本,输出文本”的API不同,它们提供了一个以“聊天消息”作为输入和输出的接口。
语言模型(LLMs)
类继承关系:
BaseLanguageModel --> BaseLLM --> LLM --> <name> # Examples: HuggingFaceHub, OpenAI
BaseLanguageModel Class (所有语言模型的封装器都应从 BaseLanguageModel 继承。)
# 定义 BaseLanguageModel 抽象基类,它从 Serializable, Runnable 和 ABC 继承
class BaseLanguageModel(
Serializable, Runnable[LanguageModelInput, LanguageModelOutput], ABC
):
这个基类为语言模型定义了一个接口,该接口允许用户以不同的方式与模型交互(例如通过提示或消息)。generate_prompt 是其中的一个主要方法,它接受一系列提示,并返回模型的生成结果。
主要提供三种方法 (每种方法都有对应的异步方法):
- generate_prompt: 为一系列的提示值生成语言模型输出。提示值是可以转换为任何语言模型输入格式的模型输入(如字符串或消息)。
- predict: 将单个字符串传递给语言模型并返回字符串预测。
- predict_messages: 将一系列 BaseMessages(对应于单个模型调用)传递给语言模型,并返回 BaseMessage 预测。
# 定义一个抽象方法 generate_prompt,需要子类进行实现
@abstractmethod
def generate_prompt(
self,
prompts: List[PromptValue], # 输入提示的列表
stop: Optional[List[str]] = None, # 生成时的停止词列表
callbacks: Callbacks = None, # 回调,用于执行例如日志记录或流式处理的额外功能
**kwargs: Any, # 任意的额外关键字参数,通常会传递给模型提供者的 API 调用
) -> LLMResult:
使用此方法时:
- 希望利用批处理调用,
- 需要从模型中获取的输出不仅仅是最顶部生成的值,
- 构建与底层语言模型类型无关的链(例如,纯文本完成模型与聊天模型)。
参数:
prompts: 提示值的列表。提示值是一个可以转换为与任何语言模型匹配的格式的对象(对于纯文本生成模型为字符串,对于聊天模型为 BaseMessages)。
stop: 生成时使用的停止词。模型输出在这些子字符串的首次出现处截断。
callbacks: 要传递的回调。用于执行额外功能,例如在生成过程中进行日志记录或流式处理。
kwargs: 任意的额外关键字参数。通常这些会传递给模型提供者的 API 调用。
返回值: LLMResult,它包含每个输入提示的候选生成列表以及特定于模型提供者的额外输出。
BaseLLM Class
# 定义 BaseLLM 抽象基类,它从 BaseLanguageModel[str] 和 ABC(Abstract Base Class)继承
class BaseLLM(BaseLanguageModel[str], ABC):
"""Base LLM abstract interface.
It should take in a prompt and return a string."""
# 定义可选的缓存属性,其初始值为 None
cache: Optional[bool] = None
# 定义 verbose 属性,该属性决定是否打印响应文本
# 默认值使用 _get_verbosity 函数的结果
verbose: bool = Field(default_factory=_get_verbosity)
"""Whether to print out response text."""
# 定义 callbacks 属性,其初始值为 None,并从序列化中排除
callbacks: Callbacks = Field(default=None, exclude=True)
# 定义 callback_manager 属性,其初始值为 None,并从序列化中排除
callback_manager: Optional[BaseCallbackManager] = Field(default=None, exclude=True)
# 定义 tags 属性,这些标签会被添加到运行追踪中,其初始值为 None,并从序列化中排除
tags: Optional[List[str]] = Field(default=None, exclude=True)
"""Tags to add to the run trace."""
# 定义 metadata 属性,这些元数据会被添加到运行追踪中,其初始值为 None,并从序列化中排除
metadata: Optional[Dict[str, Any]] = Field(default=None, exclude=True)
"""Metadata to add to the run trace."""
# 内部类定义了这个 pydantic 对象的配置
class Config:
"""Configuration for this pydantic object."""
# 允许使用任意类型
arbitrary_types_allowed = True
这段代码定义了一个名为 BaseLLM 的抽象基类。这个基类的主要目的是提供一个基本的接口来处理大型语言模型 (LLM),使用了 Pydantic 的功能,特别是 Field 方法,用于定义默认值和序列化行为。BaseLLM 的子类需要提供实现具体功能的方法。
LLM Class
# 继承自 BaseLLM 的 LLM 类
class LLM(BaseLLM):
"""Base LLM abstract class.
The purpose of this class is to expose a simpler interface for working
with LLMs, rather than expect the user to implement the full _generate method.
"""
# 使用 @abstractmethod 装饰器定义一个抽象方法,子类需要实现这个方法
@abstractmethod
def _call(
self,
prompt: str, # 输入提示
stop: Optional[List[str]] = None, # 停止词列表
run_manager: Optional[CallbackManagerForLLMRun] = None, # 运行管理器
**kwargs: Any, # 其他关键字参数
) -> str:
"""Run the LLM on the given prompt and input."""
# 此方法的实现应在子类中提供
# _generate 方法使用了 _call 方法,用于处理多个提示
def _generate(
self,
prompts: List[str], # 多个输入提示的列表
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> LLMResult:
"""Run the LLM on the given prompt and input."""
# TODO: 在此处添加缓存逻辑
generations = [] # 用于存储生成的文本
# 检查 _call 方法的签名是否支持 run_manager 参数
new_arg_supported = inspect.signature(self._call).parameters.get("run_manager")
for prompt in prompts: # 遍历每个提示
# 根据是否支持 run_manager 参数来选择调用方法
text = (
self._call(prompt, stop=stop, run_manager=run_manager, **kwargs)
if new_arg_supported
else self._call(prompt, stop=stop, **kwargs)
)
# 将生成的文本添加到 generations 列表中
generations.append([Generation(text=text)])
# 返回 LLMResult 对象,其中包含 generations 列表
return LLMResult(generations=generations)
这段代码定义了一个名为 LLM 的类,该类继承自 BaseLLM。这个类的目的是为了为用户提供一个简化的接口来处理LLM(大型语言模型),而不期望用户实现完整的 _generate 方法。
使用 LangChain 调用 OpenAI GPT Completion API
BaseOpenAI Class
class BaseOpenAI(BaseLLM):
"""OpenAI 大语言模型的基类。"""
@property
def lc_secrets(self) -> Dict[str, str]:
return {"openai_api_key": "OPENAI_API_KEY"}
@property
def lc_serializable(self) -> bool:
return True
client: Any #: :meta private:
model_name: str = Field("text-davinci-003", alias="model")
"""使用的模型名。"""
temperature: float = 0.7
"""要使用的采样温度。"""
max_tokens: int = 256
"""完成中生成的最大令牌数。
-1表示根据提示和模型的最大上下文大小返回尽可能多的令牌。"""
top_p: float = 1
"""在每一步考虑的令牌的总概率质量。"""
frequency_penalty: float = 0
"""根据频率惩罚重复的令牌。"""
presence_penalty: float = 0
"""惩罚重复的令牌。"""
n: int = 1
"""为每个提示生成多少完成。"""
best_of: int = 1
"""在服务器端生成best_of完成并返回“最佳”。"""
model_kwargs: Dict[str, Any] = Field(default_factory=dict)
"""保存任何未明确指定的`create`调用的有效模型参数。"""
openai_api_key: Optional[str] = None
openai_api_base: Optional[str] = None
openai_organization: Optional[str] = None
# 支持OpenAI的显式代理
openai_proxy: Optional[str] = None
batch_size: int = 20
"""传递多个文档以生成时使用的批处理大小。"""
request_timeout: Optional[Union[float, Tuple[float, float]]] = None
"""向OpenAI完成API的请求超时。 默认为600秒。"""
logit_bias: Optional[Dict[str, float]] = Field(default_factory=dict)
"""调整生成特定令牌的概率。"""
max_retries: int = 6
"""生成时尝试的最大次数。"""
streaming: bool = False
"""是否流式传输结果。"""
allowed_special: Union[Literal["all"], AbstractSet[str]] = set()
"""允许的特殊令牌集。"""
disallowed_special: Union[Literal["all"], Collection[str]] = "all"
"""不允许的特殊令牌集。"""
tiktoken_model_name: Optional[str] = None
"""使用此类时传递给tiktoken的模型名。
Tiktoken用于计算文档中的令牌数量以限制它们在某个限制以下。
默认情况下,设置为None时,这将与嵌入模型名称相同。
但是,在某些情况下,您可能希望使用此嵌入类与tiktoken不支持的模型名称。
这可以包括使用Azure嵌入或使用多个模型提供商的情况,这些提供商公开了类似OpenAI的API但模型不同。
在这些情况下,为了避免在调用tiktoken时出错,您可以在此处指定要使用的模型名称。"""
from langchain_openai import OpenAI
llm = OpenAI(model_name="gpt-3.5-turbo-instruct")
对比直接调用 OpenAI API:
from openai import OpenAI
client = OpenAI()
data = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt="Tell me a Joke",
)
print(llm.invoke("讲10个给程序员听得笑话"))
输出:
1. "Why did the programmer quit his job? He didn't get arrays."
2. "Why did the programmer wear glasses? Because he couldn't C#."
3. "Why was the JavaScript developer sad? He didn't know how to 'null' his feelings."
4. "Why was the database administrator so popular? Because he had lots of relationships."
5. "Why was the computer cold? Because it left its Windows open."
6. "Why did the programmer get stuck in the shower? He couldn't find the 'shampoo' function."
7. "Why was the programmer always hungry? He kept trying to feed his Python."
8. "Why couldn't the programmer go to the party? He had a strict NoSQL policy."
9. "Why did the programmer go to therapy? He had too many unresolved bugs."
10. "Why did the programmer get stuck in traffic? He was caught in an infinite loop."
LangChain 的 LLM 抽象维护了 OpenAI 连接状态(参数设定), 每次执行得到的笑话不一样
(经过本人多次测试, 通过LangChain调用 OPENAI_API 时, 只有 OPENAI 官方 OPENAI_API , 通过野卡中转得到的是无法使用的)
聊天模型(Chat Models)
类继承关系:
BaseLanguageModel --> BaseChatModel --> <name> # Examples: ChatOpenAI
BaseChatModel Class
class BaseChatModel(BaseLanguageModel[BaseMessageChunk], ABC):
cache: Optional[bool] = None
"""是否缓存响应。"""
verbose: bool = Field(default_factory=_get_verbosity)
"""是否打印响应文本。"""
callbacks: Callbacks = Field(default=None, exclude=True)
"""添加到运行追踪的回调函数。"""
callback_manager: Optional[BaseCallbackManager] = Field(default=None, exclude=True)
"""添加到运行追踪的回调函数管理器。"""
tags: Optional[List[str]] = Field(default=None, exclude=True)
"""添加到运行追踪的标签。"""
metadata: Optional[Dict[str, Any]] = Field(default=None, exclude=True)
"""添加到运行追踪的元数据。"""
# 需要子类实现的 _generate 抽象方法
@abstractmethod
def _generate(
self,
messages: List[BaseMessage],
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> ChatResult:
ChatOpenAI Class(调用 Chat Completion API)
class ChatOpenAI(BaseChatModel):
"""OpenAI Chat大语言模型的包装器。
要使用,您应该已经安装了``openai`` python包,并且
环境变量``OPENAI_API_KEY``已使用您的API密钥进行设置。
即使未在此类上明确保存,也可以传入任何有效的参数
至openai.create调用。
"""
@property
def lc_secrets(self) -> Dict[str, str]:
return {"openai_api_key": "OPENAI_API_KEY"}
@property
def lc_serializable(self) -> bool:
return True
client: Any = None #: :meta private:
model_name: str = Field(default="gpt-3.5-turbo", alias="model")
"""要使用的模型名。"""
temperature: float = 0.7
"""使用的采样温度。"""
model_kwargs: Dict[str, Any] = Field(default_factory=dict)
"""保存任何未明确指定的`create`调用的有效模型参数。"""
openai_api_key: Optional[str] = None
"""API请求的基础URL路径,
如果不使用代理或服务仿真器,请留空。"""
openai_api_base: Optional[str] = None
openai_organization: Optional[str] = None
# 支持OpenAI的显式代理
openai_proxy: Optional[str] = None
request_timeout: Optional[Union[float, Tuple[float, float]]] = None
"""请求OpenAI完成API的超时。默认为600秒。"""
max_retries: int = 6
"""生成时尝试的最大次数。"""
streaming: bool = False
"""是否流式传输结果。"""
n: int = 1
"""为每个提示生成的聊天完成数。"""
max_tokens: Optional[int] = None
"""生成的最大令牌数。"""
tiktoken_model_name: Optional[str] = None
"""使用此类时传递给tiktoken的模型名称。
Tiktoken用于计算文档中的令牌数以限制
它们在某个限制之下。默认情况下,当设置为None时,这将
与嵌入模型名称相同。但是,在某些情况下,
您可能希望使用此嵌入类,模型名称不
由tiktoken支持。这可能包括使用Azure嵌入或
使用其中之一的多个模型提供商公开类似OpenAI的
API但模型不同。在这些情况下,为了避免在调用tiktoken时出错,
您可以在这里指定要使用的模型名称。"""
from langchain_openai import ChatOpenAI
chat_model = ChatOpenAI(model_name="gpt-3.5-turbo")
对比调用 OpenAI API:
import openai
data = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
messages = [SystemMessage(content="You are a helpful assistant."),
HumanMessage(content="Who won the world series in 2020?"),
AIMessage(content="The Los Angeles Dodgers won the World Series in 2020."),
HumanMessage(content="Where was it played?")]
print(messages)
输出:
[SystemMessage(content='You are a helpful assistant.'), HumanMessage(content='Who won the world series in 2020?'), AIMessage(content='The Los Angeles Dodgers won the World Series in 2020.'), HumanMessage(content='Where was it played?')]
chat_model.invoke(messages)
AIMessage(content='The 2020 World Series was played at Globe Life Field in Arlington, Texas.', response_metadata={'token_usage': {'completion_tokens': 17, 'prompt_tokens': 53, 'total_tokens': 70}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run-17b0f35a-460a-42f4-b7c9-1b6fa2871416-0')
模板化输入:Prompts
模型输入
一个语言模型的提示是用户提供的一组指令或输入,用于引导模型的响应,帮助它理解上下文并生成相关和连贯的基于语言的输出,如回答问题、完成句子或进行对话。
- 提示模板(Prompt Templates):参数化的模型输入
- 示例选择器(Example Selectors):动态选择要包含在提示中的示例
提示模板 Prompt Templates
Prompt Templates 提供了一种预定义、动态注入、模型无关和参数化的提示词生成方式,以便在不同的语言模型之间重用模板。
一个模板可能包括指令、少量示例以及适用于特定任务的具体背景和问题。
通常,提示要么是一个字符串(LLMs),要么是一组聊天消息(Chat Model)。
类继承关系:
BasePromptTemplate --> PipelinePromptTemplate
StringPromptTemplate --> PromptTemplate
FewShotPromptTemplate
FewShotPromptWithTemplates
BaseChatPromptTemplate --> AutoGPTPrompt
ChatPromptTemplate --> AgentScratchPadChatPromptTemplate
BaseMessagePromptTemplate --> MessagesPlaceholder
BaseStringMessagePromptTemplate --> ChatMessagePromptTemplate
HumanMessagePromptTemplate
AIMessagePromptTemplate
SystemMessagePromptTemplate
PromptValue --> StringPromptValue
ChatPromptValue
使用 PromptTemplate 类生成提升词
通常,PromptTemplate 类的实例,使用Python的str.format语法生成模板化提示;也可以使用其他模板语法(例如jinja2)。
使用 from_template 方法实例化 PromptTemplate:
from langchain_core.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template(
"Tell me a {adjective} joke about {content}."
)
# 使用 format 生成提示
prompt = prompt_template.format(adjective="funny", content="chickens")
print(prompt)
输出:
Tell me a funny joke about chickens.
print(prompt_template)
输出:
input_variables=['adjective', 'content'] template='Tell me a {adjective} joke about {content}.'
prompt_template = PromptTemplate.from_template(
"Tell me a joke"
)
# 生成提示
prompt = prompt_template.format()
print(prompt)
Tell me a joke
使用 ChatPromptTemplate 类生成适用于聊天模型的聊天记录
ChatPromptTemplate 类的实例,使用format_messages方法生成适用于聊天模型的提示。
使用from_messages 方法实例化 ChatPromptTemplate:
from langchain.prompts import ChatPromptTemplate
template = ChatPromptTemplate.from_messages([
("system", "You are a helpful AI bot. Your name is {name}."),
("human", "Hello, how are you doing?"),
("ai", "I'm doing well, thanks!"),
("human", "{user_input}"),
])
# 生成提示
messages = template.format_messages(
name="Bob",
user_input="What is your name?"
)
输出:
My name is Bob, and I am a helpful AI bot. I am here to assist you with any questions or information you may need.
使用 FewShotPromptTemplate 类生成 Few-shot Prompt
构造 few-shot prompt 的方法通常有两种:
- 从示例集(set of examples)中手动选择;
- 通过示例选择器(Example Selector)自动选择.
from langchain.prompts.prompt import PromptTemplate
examples = [
{
"question": "谁活得更久,穆罕默德·阿里还是艾伦·图灵?",
"answer":
"""
这里需要进一步的问题吗:是的。
追问:穆罕默德·阿里去世时多大了?
中间答案:穆罕默德·阿里去世时74岁。
追问:艾伦·图灵去世时多大了?
中间答案:艾伦·图灵去世时41岁。
所以最终答案是:穆罕默德·阿里
"""
},
{
"question": "craigslist的创始人是什么时候出生的?",
"answer":
"""
这里需要进一步的问题吗:是的。
追问:谁是craigslist的创始人?
中间答案:Craigslist是由Craig Newmark创办的。
追问:Craig Newmark是什么时候出生的?
中间答案:Craig Newmark出生于1952年12月6日。
所以最终答案是:1952年12月6日
"""
},
{
"question": "乔治·华盛顿的外祖父是谁?",
"answer":
"""
这里需要进一步的问题吗:是的。
追问:谁是乔治·华盛顿的母亲?
中间答案:乔治·华盛顿的母亲是Mary Ball Washington。
追问:Mary Ball Washington的父亲是谁?
中间答案:Mary Ball Washington的父亲是Joseph Ball。
所以最终答案是:Joseph Ball
"""
},
{
"question": "《大白鲨》和《皇家赌场》的导演是同一个国家的吗?",
"answer":
"""
这里需要进一步的问题吗:是的。
追问:谁是《大白鲨》的导演?
中间答案:《大白鲨》的导演是Steven Spielberg。
追问:Steven Spielberg来自哪里?
中间答案:美国。
追问:谁是《皇家赌场》的导演?
中间答案:《皇家赌场》的导演是Martin Campbell。
追问:Martin Campbell来自哪里?
中间答案:新西兰。
所以最终答案是:不是
"""
}
]
example_prompt = PromptTemplate(
input_variables=["question", "answer"],
template="Question: {question}\n{answer}"
)
# **examples[0] 是将examples[0] 字典的键值对(question-answer)解包并传递给format,作为函数参数
print(example_prompt.format(**examples[0]))
输出:
Question: 谁活得更久,穆罕默德·阿里还是艾伦·图灵?
这里需要进一步的问题吗:是的。
追问:穆罕默德·阿里去世时多大了?
中间答案:穆罕默德·阿里去世时74岁。
追问:艾伦·图灵去世时多大了?
中间答案:艾伦·图灵去世时41岁。
所以最终答案是:穆罕默德·阿里
生成 Few-shot Prompt:
# 导入 FewShotPromptTemplate 类
from langchain.prompts.few_shot import FewShotPromptTemplate
# 创建一个 FewShotPromptTemplate 对象
few_shot_prompt = FewShotPromptTemplate(
examples=examples, # 使用前面定义的 examples 作为范例
example_prompt=example_prompt, # 使用前面定义的 example_prompt 作为提示模板
suffix="Question: {input}", # 后缀模板,其中 {input} 会被替换为实际输入
input_variables=["input"] # 定义输入变量的列表
)
print(few_shot_prompt.format(input="玛丽·波尔·华盛顿的父亲是谁?"))
输出:
Question: 谁活得更久,穆罕默德·阿里还是艾伦·图灵?
这里需要进一步的问题吗:是的。
追问:穆罕默德·阿里去世时多大了?
中间答案:穆罕默德·阿里去世时74岁。
追问:艾伦·图灵去世时多大了?
中间答案:艾伦·图灵去世时41岁。
所以最终答案是:穆罕默德·阿里
Question: craigslist的创始人是什么时候出生的?
这里需要进一步的问题吗:是的。
追问:谁是craigslist的创始人?
中间答案:Craigslist是由Craig Newmark创办的。
追问:Craig Newmark是什么时候出生的?
中间答案:Craig Newmark出生于1952年12月6日。
所以最终答案是:1952年12月6日
Question: 乔治·华盛顿的外祖父是谁?
这里需要进一步的问题吗:是的。
追问:谁是乔治·华盛顿的母亲?
中间答案:乔治·华盛顿的母亲是Mary Ball Washington。
追问:Mary Ball Washington的父亲是谁?
中间答案:Mary Ball Washington的父亲是Joseph Ball。
所以最终答案是:Joseph Ball
Question: 《大白鲨》和《皇家赌场》的导演是同一个国家的吗?
这里需要进一步的问题吗:是的。
追问:谁是《大白鲨》的导演?
中间答案:《大白鲨》的导演是Steven Spielberg。
追问:Steven Spielberg来自哪里?
中间答案:美国。
追问:谁是《皇家赌场》的导演?
中间答案:《皇家赌场》的导演是Martin Campbell。
追问:Martin Campbell来自哪里?
中间答案:新西兰。
所以最终答案是:不是
Question: 玛丽·波尔·华盛顿的父亲是谁?
示例选择器 Example Selectors
- 如果你有大量的参考示例,就得选择哪些要包含在提示中。最好还是根据某种条件或者规则来自动选择,Example Selector 是负责这个任务的类。
BaseExampleSelector 定义如下:
class BaseExampleSelector(ABC):
"""用于选择包含在提示中的示例的接口。"""
@abstractmethod
def select_examples(self, input_variables: Dict[str, str]) -> List[dict]:
"""根据输入选择要使用的示例。"""
ABC 是 Python 中的 abc 模块中的一个缩写,它表示 "Abstract Base Class"(抽象基类)。在 Python 中,抽象基类用于定义其他类必须遵循的基本接口或蓝图,但不能直接实例化。其主要目的是为了提供一种形式化的方式来定义和检查子类的接口。
使用抽象基类的几点关键信息:
抽象方法:在抽象基类中,你可以定义抽象方法,它没有实现(也就是说,它没有方法体)。任何继承该抽象基类的子类都必须提供这些抽象方法的实现。
不能直接实例化:你不能直接创建抽象基类的实例。试图这样做会引发错误。它们的主要目的是为了被继承,并在子类中实现其方法。
强制子类实现:如果子类没有实现所有的抽象方法,那么试图实例化该子类也会引发错误。这确保了继承抽象基类的所有子类都遵循了预定的接口。
# 导入需要的模块和类
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
# 定义一个提示模板
example_prompt = PromptTemplate(
input_variables=["input", "output"], # 输入变量的名字
template="Input: {input}\nOutput: {output}", # 实际的模板字符串
)
# 这是一个假设的任务示例列表,用于创建反义词
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
# 从给定的示例中创建一个语义相似性选择器
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples, # 可供选择的示例列表
OpenAIEmbeddings(), # 用于生成嵌入向量的嵌入类,用于衡量语义相似性
Chroma, # 用于存储嵌入向量并进行相似性搜索的 VectorStore 类
k=1 # 要生成的示例数量
)
# 创建一个 FewShotPromptTemplate 对象
similar_prompt = FewShotPromptTemplate(
example_selector=example_selector, # 提供一个 ExampleSelector 替代示例
example_prompt=example_prompt, # 前面定义的提示模板
prefix="Give the antonym of every input", # 前缀模板
suffix="Input: {adjective}\nOutput:", # 后缀模板
input_variables=["adjective"], # 输入变量的名字
)
# 输入是一种感受,所以应该选择 happy/sad 的示例。
print(similar_prompt.format(adjective="worried"))
输出:
Give the antonym of every input
Input: happy
Output: sad
Input: worried
Output:
规范化输出:Output Parsers
输出解析器 Output Parser
语言模型的输出是文本。
但很多时候,希望获得比纯文本更结构化的信息。这就是输出解析器的价值所在。
输出解析器是帮助结构化语言模型响应的类。它们必须实现两种主要方法:
- "获取格式指令":返回一个包含有关如何格式化语言模型输出的字符串的方法。
- "解析":接受一个字符串(假设为来自语言模型的响应),并将其解析成某种结构。
然后还有一种可选方法:
- "使用提示进行解析":接受一个字符串(假设为来自语言模型的响应)和一个提示(假设为生成此响应的提示),并将其解析成某种结构。在需要重新尝试或修复输出,并且需要从提示中获取信息以执行此操作时,通常会提供提示。
LangChain基础篇 (01)的更多相关文章
- iOS系列 基础篇 01 构建HelloWorld,剖析并真机测试
iOS基础 01 构建HelloWorld,剖析并真机测试 前言: 从控制台输出HelloWorld是我们学习各种语言的第一步,也是我们人生中非常重要的一步. 多年之后,我希望我们仍能怀有学习上进的心 ...
- Java多线程系列 基础篇01 线程的状态
1.进程和线程 进程: 计算机中程序关于某数据集合的一次运行活动,是计算机系统进行资源分配和调度的基本单位,是操作系统结构的基础. 线程: 线程是进程的实例,是CPU进行资源分配和调度的最小单位,线程 ...
- 【matlab 基础篇 01】快速开始第一个程序(详细图文+文末资源)
快速入门matlab,系统地整理一遍,如何你和我一样是一个新手,那么此文很适合你: 文章目录 1 软件安装 2 打开软件 3 编写程序 3.1 基础步骤 3.2 添加PATH 3.3 命令行模式 4 ...
- Java多线程系列--“基础篇”01之 基本概念
多线程是Java中不可避免的一个重要主体.从本章开始,我们将展开对多线程的学习.接下来的内容,是对“JDK中新增JUC包”之前的Java多线程内容的讲解,涉及到的内容包括,Object类中的wait( ...
- Java岗 面试考点精讲(基础篇01期)
即将到来金三银四人才招聘的高峰期,渴望跳槽的朋友肯定跟我一样四处找以往的面试题,但又感觉找的又不完整,在这里我将把我所见到的题目做一总结,并尽力将答案术语化.标准化.预祝大家面试顺利. 术语会让你的面 ...
- python 基础篇01
一.python介绍年的圣诞节期间,吉多亿个文件的上传和下载千万张照片被分享,全部用倍年,为了打发圣诞节假期,年,第一个Python编译器诞生.它是用C语言实现的,并能够调用C语言的库文件.从一出生, ...
- Java基础篇01
01. 面向对象 --> 什么是面向对象 面向对象 面向对象程序设计,简称OOP(Object Oriented Programming). 对象: 指人们要研究的任何事物,不管是物理上具体的事 ...
- Django入门之基础篇01
这是第一篇Django(花音:浆够)入门博客,学习Django的初衷是为了开发自己的个人小小网站(虽然有了博客园,还是想建立自己的博客,因为自主定制,香香香~!)
- Java基础篇(01):基本数据类型,核心点整理
本文源码:GitHub·点这里 || GitEE·点这里 一.基本类型 1.基本类型 不使用New创建,声明一个非引用传递的变量,且变量的值直接置于堆栈中,大小不随运行环境变化,效率更高.使用new创 ...
- C#基础篇01
vs20vs2013快捷键小节: 1>: #region #endregion(用来折叠冗余代码) 2>:Ctril+K+D快速对其代码: 3>:Ctril+K+C注释选中代码 Ct ...
随机推荐
- Jx.Cms开发笔记(三)-Views主题动态切换
效果展示 我们可以在后台动态切换主题 目前Jx.Cms有两个主题,其中一个是默认主题,另一个是仿的Blogs主题. 我们可以通过点击启用按钮来动态切换两个主题. 实现方法 首先写一个实现IViewLo ...
- 设计模式【3.2】-- JDK动态代理源码分析有多香?
前面文章有说到代理模式:http://aphysia.cn/archives/dynamicagentdesignpattern 那么回顾一下,代理模式怎么来的?假设有个需求: 在系统中所有的 con ...
- 2024年1月Java项目开发指南13:登录注册实现
创建文件,如上图 创建好文件后去router.index.js配置路由 import { createRouter, createWebHistory } from 'vue-router'; // ...
- Qt编写可视化大屏电子看板系统32-模块10大屏地图
一.前言 大屏地图模块采用浏览器模块+echart组件,Qt自带了webkit或者webengine模块,其中在win上mingw编译器的Qt5.6以后的版本,没有了浏览器模块,这个就需要用第三方的浏 ...
- Qt开发经验小技巧146-150
Qt中自带的很多控件,其实都是由一堆基础控件(QLabel.QPushButton等)组成的,比如日历面板 QCalendarWidget 就是 QToolButton+QSpinBox+QTable ...
- UML之集合类型
无论何时当我们要使用一个多值对象时,我们必须要清楚两个问题,一是这些值的顺序重要吗?二是允许重复值的存在吗?在编程语言中还会有其他的明确的信息,在UML中,只需明确这两个问题的答案即可确定对应的集合类 ...
- 从异常{ 无法将 匿名方法 转换为类型“System.Delegate”,因为它不是委托类型 }说开去
从异常{ 无法将 匿名方法 转换为类型"System.Delegate",因为它不是委托类型 }说开去. 查看如下代码: this.Invoke(delegate { Messag ...
- C# 设置label(标签)控件的背景颜色为透明
有时候,我们需要将控件的背景颜色设定为透明,比如说label(标签)控件.那么,如何将控件的背景颜色设定为透明?是不是只要将控件的BackColor属性设为Transparent(透明)就可以了呢?答 ...
- 即时通讯技术文集(第14期):WebSocket精华文章合集 [共15篇]
为了更好地分类阅读52im.net 总计1000多篇精编文章,我将在每周三推送新的一期技术文集,本次是第14 期. [- 1 -] 新手快速入门:WebSocket简明教程 [链接] http://w ...
- JMeter 采样器超详细教程
宝子们,今天咱就来好好唠唠 JMeter 里那些厉害的采样器,让你轻松拿捏性能测试和接口测试! 一.采样器大集合 先给宝子们来个采样器的 "全家福",让你们心里有个底: HTTP ...