SQL 强化练习 (十二)
还是 sql 冲鸭... , 停不下来了都, 趁着激情还在, 赶紧再整一把, 也渐渐发现, sql 果然是非常强大的, 然后搞了半天, 发现在写sql 的时候, 从它执行顺序来思考, 这样反而会轻松很多哦.
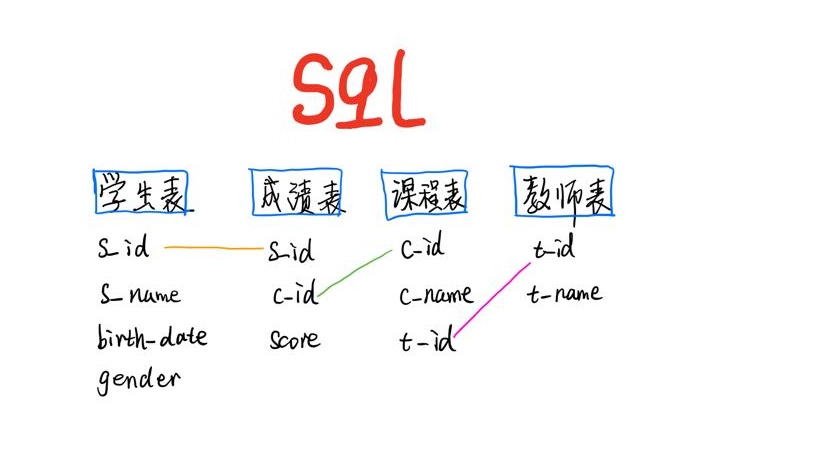
表关系
需求 01
查询 每门课程 被选修的学生人数
分析
纯练练手而已, 毫无难度. 还是不断在强调关于 group by 的用法, 即, 用了 group by 后, select 的字段必须是在 group by 中 或者 是聚合函数. 不然则报错或引发歧义, 这个非常重要. 然后就是新手,比如像我这种, 分组筛选的. where 是在 group by 之前, having 是 group by 之后.
select
a.c_id,
b.c_name,
count(distinct a.s_id)
from score as a
inner join course as b
on a.c_id = b.c_id
group by a.c_id, b.c_name
+------+--------+------------------------+
| c_id | c_name | count(distinct a.s_id) |
+------+--------+------------------------+
| 0001 | 语文 | 2 |
| 0002 | 数学 | 3 |
| 0003 | 英语 | 3 |
+------+--------+------------------------+
3 rows in set (0.00 sec)
mysql>
需求 02
查询 只有两门课程的全部学生的学号和姓名.
分析
先按 s_id 分组, 然后分组过滤(having) 出 课程数量为 2 的学号, 再匹配下学生表即可.
-- 先看有哪些学号
select * from score
group by s_id
having count(distinct c_id) = 2
+------+------+-------+
| s_id | c_id | score |
+------+------+-------+
| 0002 | 0002 | 60 |
+------+------+-------+
1 row in set (0.00 sec)
然后再做一个子查询, 作为学生表的一个筛选条件.
select
s_id as 学号,
s_name as 姓名
from student where s_id in (
select s_id
from score
group by s_id
having count(distinct c_id) = 2
)
+--------+--------+
| 学号 | 姓名 |
+--------+--------+
| 0002 | 星落 |
+--------+--------+
1 row in set (0.01 sec)
拓展一波, 其实我现在, 反而是更加喜欢先多表连接的方式来弄, 这样对于更加复杂的逻辑, 也是能够处理的, 涉及的表都给它拼接起来, 要啥字段就拿啥字段, 随便玩..
select
b.s_id 学号,
b.s_name 姓名
from score as a
inner join student as b
on a.s_id = b.s_id
group by a.s_id
having count(distinct a.c_id) = 2
我发现自己, 在写 join 的时候, 常常忘了 写 on 的条件, 就瞎连接...真是无语了.
+--------+--------+
| 学号 | 姓名 |
+--------+--------+
| 0002 | 星落 |
+--------+--------+
1 row in set (0.00 sec)
今天的这两个, 都是练手题, 蛮简单的, 还是关键在于掌握着两种思路, 一种是 "子查询" 风格的, 有点像咱编程的 面向过程写法; 另外一种是 "Join" 风格的, 将相关的表,都给关联上, 然后再来慢慢优化, 就跟咱编程的 "面向对象" 有点像, 差不多这样吧. 然后我发现, 现在还是挺喜欢后者这种 join 的方式的, 都先给怼出来, 然后再优化. 具体看场景吧还是.
小结
- 从 sql 的执行顺序去写sql 会事半功倍, 兼顾 子查询 和 join 两种思维方式的结合
- group by , select 中只能放 与 group by 的字段 或聚合函数, where > group by > having
- join 的时候, on 理解为 True ... 如不写或 True 则是会全部连接起来..一定要写清楚 或者 多条件判断 结合 and 和 or
SQL 强化练习 (十二)的更多相关文章
- SQL语句(十二)分组查询
(十二)分组查询 将数据表中的数据按某种条件分成组,按组显示统计信息 查询各班学生的最大年龄.最小年龄.平均年龄和人数 分组 SELECT <字段名表1> FROM <表名> ...
- 强化学习(十二) Dueling DQN
在强化学习(十一) Prioritized Replay DQN中,我们讨论了对DQN的经验回放池按权重采样来优化DQN算法的方法,本文讨论另一种优化方法,Dueling DQN.本章内容主要参考了I ...
- SQL系列(十二)—— insert update delete
前言 这个系列的前面都一直在介绍查询select.但是SQL中十分广泛,按对数据的不同处理可以分为: DML:全称Data Manipulation Language,从名字上可以看出,DML是对数据 ...
- 强化学习(十四) Actor-Critic
在强化学习(十三) 策略梯度(Policy Gradient)中,我们讲到了基于策略(Policy Based)的强化学习方法的基本思路,并讨论了蒙特卡罗策略梯度reinforce算法.但是由于该算法 ...
- 第十二篇 SQL Server代理多服务器管理
本篇文章是SQL Server代理系列的第十二篇,详细内容请参考原文 在这一系列的上一篇,我们查看了维护计划,一个维护计划可能会创建多个作业,多个计划.你还简单地看了SSIS子系统,并查看了维护计划作 ...
- SQL Server 2008空间数据应用系列十二:Bing Maps中呈现GeoRSS订阅的空间数据
原文:SQL Server 2008空间数据应用系列十二:Bing Maps中呈现GeoRSS订阅的空间数据 友情提示,您阅读本篇博文的先决条件如下: 1.本文示例基于Microsoft SQL Se ...
- SQL注入之Sqli-labs系列第五十关,第五十一关,第五十二关,第五十三关(ORDER BY堆叠注入)
0x1第五十关 源码中使用的mysqli_multi_query()函数,而之前使用的是mysqli_query(),区别在于mysqli_multi_query()可以执行多个sql语句,而mysq ...
- SQL注入之Sqli-labs系列第四十一关(基于堆叠注入的盲注)和四十二关四十三关四十四关四十五关
0x1普通测试方式 (1)输入and1=1和and1=2测试,返回错误,证明存在注入 (2)union select联合查询 (3)查询表名 (4)其他 payload: ,( ,( 0x2 堆叠注入 ...
- 【译】第十二篇 SQL Server代理多服务器管理
本篇文章是SQL Server代理系列的第十二篇,详细内容请参考原文 在这一系列的上一篇,我们查看了维护计划,一个维护计划可能会创建多个作业,多个计划.你还简单地看了SSIS子系统,并查看了维护计划作 ...
- (二十二)SpringBoot之使用Druid连接池以及SQL监控和spring监控
一.引入maven依赖 <dependencies> <dependency> <groupId>org.springframework.boot</grou ...
随机推荐
- KUKA库卡机器人常见故障都有哪些解决办法
如何解决机器人线路板维修查不出故障 在进行机器人电路板维修工作时,有时会遇到查不出故障原因的情况,对于这种故障维修业界称之为疑难杂症,这时维修人员该如何应对呢?在这里向朋友们介绍机器人维修一些解决的方 ...
- 当 GPT 告诉我9.11大于9.9的时候:AI 仍需完善的一面
在当今 AI 技术飞速发展的时代,我们对其能力寄予了厚望,期待它们能够准确无误地处理各种任务.然而,最近发生的一件事情让我们意识到,AI 仍然有需要改进和完善的地方. GPT 作为一款备受瞩目的语言模 ...
- Windows编程----进程:命令行参数
什么是进程的命令行参数 每个进程在启动(双击exe启动.cmd命令行启动或者由其他程序通过CreateProcess启动)的时候,都会有一个命令行参数给它.命令行的参数以空格区分.这个命令行总是不为空 ...
- pandas 判断列是否包含某个字符串
亲测第二种好用 in 语句 不包含使用not in food = df['日期'].values.tolist() if '休息' in food: print(food) if df['共计小时'] ...
- 为什么将malloc()和printf()称为不可重入?
转载自https://mlog.club/article/1807704 在unix系统中,我们知道malloc()是一个不可重入的函数(系统调用).为什么? 类似地,printf()也被认为是不可重 ...
- PHP的curl获取header信息
PHP的curl功能十分强大,简单点说,就是一个PHP实现浏览器的基础. 最常用的可能就是抓取远程数据或者向远程POST数据.但是在这个过程中,调试时,可能会有查看header的必要. echo ge ...
- docker报错 ERROR: Service 'workspace' failed to build: ERROR: Service 'php-fpm' failed to build:
在 Windows 系统中使用 Laradock 搭建基于 Docker 的 PHP 开发环境 执行命令 docker-compose up nginx mysql redis 执行过程中出现错误 报 ...
- Cython二进制逆向系列(三)运算符
Cython二进制逆向系列(三)运算符 在开始前,先给出本文用到的py源代码 def test1(x, y): # 数学运算符 a = x + y b = x - y c = x * y d = x ...
- 模型蒸馏(Distillation)案例--从DeepSeek-R1-1.5B 到 Qwen-2.5-1.5B 的模型蒸馏
DeepSeek-R1-1.5B 到 Qwen-2.5-1.5B 的模型蒸馏(Distillation) 本文重点进行DeepSeek-R1-1.5B 到 Qwen-2.5-1.5B 的模型蒸馏(Di ...
- AI与.NET技术实操系列(九):总结篇 ── 探讨.NET 开发 AI 生态:工具、库与未来趋势
1. 引言 本文作为本系列的最后一篇,旨在全面探讨 .NET 生态中与 AI 相关的工具.库.框架和资源,帮助开发者了解如何在 .NET 环境中开发 AI 应用.我们将分析 Microsoft 的 A ...