第5讲、Transformer 编码器(Encoder)处理过程详解
Transformer 编码器(Encoder)处理过程详解
Transformer Encoder 是一个由 N 层(一般为 6 层)堆叠而成的模块结构。每一层的本质是两个核心子模块:
- 多头自注意力(Multi-Head Self-Attention)
- 前馈神经网络(Feed Forward Network)
每个子模块都通过:
- 残差连接(Residual Connection)
- 层归一化(LayerNorm)
进行包裹与标准化,保持训练稳定性。
总体流程图解(以一层为例)
嵌入输入
│
+───> 位置编码(Position Encoding)
│
▼
输入表示(X) → ┐
│
多头自注意力(Self-Attention)
│
+ Residual + LayerNorm(第一步)
▼
前馈神经网络(Feed Forward)
│
+ Residual + LayerNorm(第二步)
▼
输出 H1(传入下一层)
输入嵌入层(Input Embedding + Position Encoding)
- 每个输入 token 首先通过词向量矩阵映射为一个固定维度向量(如 512维)。
- 然后加上 位置编码(固定正余弦或可学习向量),使模型具备位置信息。

第一子模块:多头自注意力 Multi-Head Self-Attention
自注意力(Self-Attention)核心思想:
每个词在计算时都可以关注句中其他所有词,捕捉到全局语义信息。
计算过程:

作用:
- 让每个词语动态地感知上下文语义
- 多头机制让模型从多个表示子空间学习依赖关系
残差连接 + LayerNorm(第一次)
自注意力输出后,加入输入值(残差连接),再做归一化:

目的:
- 防止训练过程中的梯度消失
- 保持信息流动稳定
- LayerNorm 保证激活值分布统一,提升收敛速度
第二子模块:前馈神经网络 Feed Forward
结构:
每个位置上的 token 单独经过一个两层的全连接网络(MLP):
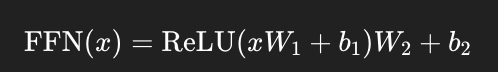
虽然是点对点操作,但提供了非线性特征转换能力。
特点:
- 输入维度保持不变(如 512 → 2048 → 512)
- 提升模型表达能力与抽象能力
残差连接 + LayerNorm(第二次)
对 FFN 输出再做一次残差与归一化:

多层堆叠(Layer Stacking)
Encoder 模块通常堆叠 6 层(或更多),形成深度网络:
Input → EncoderLayer × N → Encoder Output
每层都重复上述两步:自注意力 → FFN,逐层提炼抽象特征。
最终输出
Encoder 最终输出是一个张量:
- 形状为
[batch_size, seq_len, d_model] - 每个 token 都被映射为一个"上下文增强"的向量表示
这个输出将供 Decoder 或下游任务使用(如分类、问答、生成等)。
小结:每一层 Encoder 的设计哲学
| 组件 | 作用 |
|---|---|
| Position Encoding | 弥补无序缺陷,提供位置信息 |
| Self-Attention | 捕捉词与词之间全局依赖 |
| Feed Forward | 增强模型非线性表达能力 |
| Residual Connection | 保持信息路径,减缓梯度消失 |
| LayerNorm | 保证数值稳定,加快训练 |
Encoder 是一个结构精巧的"信息提炼器",将原始嵌入压缩为包含上下文的丰富表示,是 Transformer 模型成功的根本所在。
PyTorch 代码实现与详细讲解
下面以 PyTorch 为例,逐步实现 Transformer 编码器的各个核心模块,并结合代码详细说明其原理与设计。
1. 输入嵌入与位置编码
import torch
import torch.nn as nn
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-torch.log(torch.tensor(10000.0)) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # [1, max_len, d_model]
self.register_buffer('pe', pe)
def forward(self, x):
# x: [batch_size, seq_len, d_model]
x = x + self.pe[:, :x.size(1)]
return x
class InputEmbedding(nn.Module):
def __init__(self, vocab_size, d_model):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_encoding = PositionalEncoding(d_model)
def forward(self, x):
x = self.embedding(x) # [batch, seq_len, d_model]
x = self.pos_encoding(x)
return x
讲解:
- InputEmbedding 将 token id 映射为向量,并加上位置编码,补充序列顺序信息。
- PositionalEncoding 用正余弦函数实现,保证不同位置有唯一编码。
2. 多头自注意力机制
class MultiHeadSelfAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
assert d_model % num_heads == 0
self.d_k = d_model // num_heads
self.num_heads = num_heads
self.qkv_linear = nn.Linear(d_model, d_model * 3)
self.out_linear = nn.Linear(d_model, d_model)
def forward(self, x, mask=None):
batch_size, seq_len, d_model = x.size()
qkv = self.qkv_linear(x) # [batch, seq_len, 3*d_model]
qkv = qkv.reshape(batch_size, seq_len, 3, self.num_heads, self.d_k)
qkv = qkv.permute(2, 0, 3, 1, 4) # [3, batch, heads, seq_len, d_k]
q, k, v = qkv[0], qkv[1], qkv[2]
scores = torch.matmul(q, k.transpose(-2, -1)) / self.d_k ** 0.5 # [batch, heads, seq_len, seq_len]
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
attn = torch.softmax(scores, dim=-1)
context = torch.matmul(attn, v) # [batch, heads, seq_len, d_k]
context = context.transpose(1, 2).reshape(batch_size, seq_len, d_model)
out = self.out_linear(context)
return out
讲解:
- Q、K、V 通过线性变换获得,分多头并行计算注意力。
- 每个头可关注不同子空间的依赖,最后拼接。
- mask 用于屏蔽无效位置(如 padding)。
3. 前馈神经网络
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.relu = nn.ReLU()
self.linear2 = nn.Linear(d_ff, d_model)
def forward(self, x):
return self.linear2(self.relu(self.linear1(x)))
讲解:
- 两层全连接+ReLU,提升非线性表达能力。
- 逐位置独立处理,不引入序列间交互。
4. 残差连接与 LayerNorm
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff):
super().__init__()
self.self_attn = MultiHeadSelfAttention(d_model, num_heads)
self.norm1 = nn.LayerNorm(d_model)
self.ffn = FeedForward(d_model, d_ff)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, x, mask=None):
# Self-Attention + Residual + Norm
attn_out = self.self_attn(x, mask)
x = self.norm1(x + attn_out)
# FFN + Residual + Norm
ffn_out = self.ffn(x)
x = self.norm2(x + ffn_out)
return x
讲解:
- 每个子模块后都加残差和 LayerNorm,保证梯度流动和数值稳定。
- 先自注意力,再前馈网络。
5. 编码器整体结构
class TransformerEncoder(nn.Module):
def __init__(self, vocab_size, d_model, num_heads, d_ff, num_layers):
super().__init__()
self.embedding = InputEmbedding(vocab_size, d_model)
self.layers = nn.ModuleList([
EncoderLayer(d_model, num_heads, d_ff) for _ in range(num_layers)
])
def forward(self, x, mask=None):
x = self.embedding(x)
for layer in self.layers:
x = layer(x, mask)
return x # [batch, seq_len, d_model]
讲解:
- 多层 EncoderLayer 堆叠,每层提炼更高层次特征。
- 输出为每个 token 的上下文增强表示。
总结
- 输入嵌入+位置编码:为每个 token 提供唯一、可区分的向量表示。
- 多头自注意力:全局建模 token 间依赖,多头提升表达力。
- 前馈网络:增强非线性特征转换。
- 残差+LayerNorm:稳定训练,防止梯度消失。
- 多层堆叠:逐层抽象,获得丰富的上下文表示。
Streamlit Transformer Encoder 可视化案例(PyTorch版)
完整案例代码
import streamlit as st
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
# 1. 输入嵌入与位置编码
st.header("1. 输入嵌入与位置编码")
st.markdown("""
**要做的事情**:将输入的token序列映射为向量,并加上位置编码。
**作用**:让模型既能理解词语含义,又能感知顺序信息。
""")
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=50):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-np.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.pe = pe.unsqueeze(0) # [1, max_len, d_model]
def forward(self, x):
return x + self.pe[:, :x.size(1)]
vocab_size, d_model, seq_len = 20, 8, 10
embedding = nn.Embedding(vocab_size, d_model)
pos_encoding = PositionalEncoding(d_model, max_len=seq_len)
tokens = torch.randint(0, vocab_size, (1, seq_len))
embed = embedding(tokens)
embed_pos = pos_encoding(embed)
fig, ax = plt.subplots(1, 2, figsize=(10, 3))
ax[0].imshow(embed[0].detach().numpy(), aspect='auto')
ax[0].set_title("Token Embedding")
ax[1].imshow(embed_pos[0].detach().numpy(), aspect='auto')
ax[1].set_title("Embedding + PositionalEncoding")
st.pyplot(fig)
# 2. 多头自注意力
st.header("2. 多头自注意力机制")
st.markdown("""
**要做的事情**:让每个token关注序列中其它token,捕捉全局依赖。
**作用**:模型能理解上下文关系,提升表达能力。
""")
class MultiHeadSelfAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
assert d_model % num_heads == 0
self.d_k = d_model // num_heads
self.num_heads = num_heads
self.qkv_linear = nn.Linear(d_model, d_model * 3)
self.out_linear = nn.Linear(d_model, d_model)
def forward(self, x):
batch_size, seq_len, d_model = x.size()
qkv = self.qkv_linear(x)
qkv = qkv.reshape(batch_size, seq_len, 3, self.num_heads, self.d_k)
qkv = qkv.permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
scores = torch.matmul(q, k.transpose(-2, -1)) / np.sqrt(self.d_k)
attn = torch.softmax(scores, dim=-1)
context = torch.matmul(attn, v)
context = context.transpose(1, 2).reshape(batch_size, seq_len, d_model)
out = self.out_linear(context)
return out, attn
mhsa = MultiHeadSelfAttention(d_model, num_heads=2)
attn_out, attn_weights = mhsa(embed_pos)
fig, ax = plt.subplots(1, 2, figsize=(10, 3))
ax[0].imshow(attn_out[0].detach().numpy(), aspect='auto')
ax[0].set_title("Self-Attention Output")
ax[1].imshow(attn_weights[0][0].detach().numpy(), aspect='auto')
ax[1].set_title("Attention Weights (Head 1)")
st.pyplot(fig)
# 3. 前馈神经网络
st.header("3. 前馈神经网络")
st.markdown("""
**要做的事情**:对每个token的表示做非线性变换。
**作用**:提升模型的非线性表达能力。
""")
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.relu = nn.ReLU()
self.linear2 = nn.Linear(d_ff, d_model)
def forward(self, x):
return self.linear2(self.relu(self.linear1(x)))
ffn = FeedForward(d_model, d_ff=16)
ffn_out = ffn(attn_out)
fig, ax = plt.subplots()
ax.imshow(ffn_out[0].detach().numpy(), aspect='auto')
ax.set_title("Feed Forward Output")
st.pyplot(fig)
# 4. 残差连接与LayerNorm
st.header("4. 残差连接与LayerNorm")
st.markdown("""
**要做的事情**:每个子模块后加残差和归一化。
**作用**:防止梯度消失,提升训练稳定性。
""")
layernorm = nn.LayerNorm(d_model)
residual_out = layernorm(embed_pos + attn_out)
fig, ax = plt.subplots()
ax.imshow(residual_out[0].detach().numpy(), aspect='auto')
ax.set_title("Residual + LayerNorm Output")
st.pyplot(fig)
# 5. 多层堆叠
st.header("5. 多层堆叠")
st.markdown("""
**要做的事情**:重复上述结构,逐层提炼特征。
**作用**:获得更丰富的上下文表示。
""")
st.markdown("(此处可用多层循环堆叠,原理同上,略)")
st.success("案例演示完毕!你可以修改参数、输入等,观察每一步的可视化效果。")


第5讲、Transformer 编码器(Encoder)处理过程详解的更多相关文章
- 【STM32H7教程】第13章 STM32H7启动过程详解
完整教程下载地址:http://forum.armfly.com/forum.php?mod=viewthread&tid=86980 第13章 STM32H7启动过程详解 本章教 ...
- Mysql加锁过程详解(8)-理解innodb的锁(record,gap,Next-Key lock)
Mysql加锁过程详解(1)-基本知识 Mysql加锁过程详解(2)-关于mysql 幻读理解 Mysql加锁过程详解(3)-关于mysql 幻读理解 Mysql加锁过程详解(4)-select fo ...
- Mysql加锁过程详解(3)-关于mysql 幻读理解
Mysql加锁过程详解(1)-基本知识 Mysql加锁过程详解(2)-关于mysql 幻读理解 Mysql加锁过程详解(3)-关于mysql 幻读理解 Mysql加锁过程详解(4)-select fo ...
- Mysql加锁过程详解(7)-初步理解MySQL的gap锁
Mysql加锁过程详解(1)-基本知识 Mysql加锁过程详解(2)-关于mysql 幻读理解 Mysql加锁过程详解(3)-关于mysql 幻读理解 Mysql加锁过程详解(4)-select fo ...
- fabric网络环境启动过程详解
这篇文章对fabric的网络环境启动过程进行讲解,也就是我们上节讲到的启动测试fabric网络环境时运行network_setup.sh这个文件的执行流程 fabric网络环境启动过程详解 上一节我们 ...
- uboot主Makefile分析(t配置和编译过程详解)
1.编译uboot前需要三次make make distcleanmake x210_sd_configmake -j4 make distclean为清楚dist文件. make x210_sd_c ...
- BabyLinux制作过程详解
转:http://www.360doc.com/content/05/0915/14/1429_12641.shtml BabyLinux制作过程详解 作者:GuCuiwen email:win2li ...
- uboot配置和编译过程详解【转】
本文转载自:http://blog.csdn.net/czg13548930186/article/details/53434566 uboot主Makefile分析1 1.uboot version ...
- Android View 的绘制流程之 Layout 和 Draw 过程详解 (二)
View 的绘制系列文章: Android View 的绘制流程之 Measure 过程详解 (一) Android View 绘制流程之 DecorView 与 ViewRootImpl 在上一篇 ...
- uboot配置和编译过程详解
根据朱有鹏老师讲解整理 一.uboot主Makefile分析 1.uboot version确定(Makefile的24-29行) include/version_autogenerated.h文件是 ...
随机推荐
- 关于我在使用Steamlit中碰到的问题及解决方案总结
Steamlit 并不支持一个可以预览本地文件的路径选择器(并不上传文件) 解决方案:使用 Python 自带的 tkinter 来完成 参考:[Streamlit 选择文件夹的曲折方案]Stream ...
- Linux 下载安装CUDA Toolkit 12.8,配置Nvidia Driver
cuda下载地址 https://developer.nvidia.com/cuda-downloads nvidia-smi Mon Mar 17 02:08:35 2025 +---------- ...
- python 函数与方法的区别
函数与方法的区别 并不是类中的调用都叫方法 1.函数要手动传self,方法不用传self. 2.如果是一个函数,用类名去调用,如果是一个方法,用对象去调用. class Foo(object): de ...
- IvorySQL 4.2 发布
IvorySQL 4.2 已于 2025 年 1 月 13 日正式发布.新版本全面支持 PostgreSQL 17.2,并修复了多项 bug. 增强功能 PostgreSQL 17.1 增强功能 确保 ...
- map标签是什么
<map>标签用于在HTML中定义一个 图像映射(image map),它允许你将图像划分为多个可点击的区域(称为"热点"),每个区域可以链接到不同的URL或执行不同的 ...
- java学习-6-核心类:字符串StringJoiner 和数组一起玩
public class Main { public static void main(String[] args) { String[] names = {"Bob", &quo ...
- WgelCTF打靶笔记(2)
参考视频:https://www.bilibili.com/video/BV1itwgeHEEk/?spm_id_from=333.1387.upload.video_card.click&v ...
- 2025年最流行的5个Python ASGI服务器及其核心特性与适用场景
以下是2025年最流行的5个Python ASGI服务器及其核心特性与适用场景: 1. Uvicorn • 核心优势: • 基于uvloop和httptools,性能远超传统WSGI服务器,支持HTT ...
- zk基础—5.Curator的使用与剖析
大纲 1.基于Curator进行基本的zk数据操作 2.基于Curator实现集群元数据管理 3.基于Curator实现HA主备自动切换 4.基于Curator实现Leader选举 5.基于Curat ...
- idea的配置优化
一.显示工具条 二.设置鼠标悬浮提示 三.显示方法分隔符 四.忽略大小写提示 五.主题设置 如果需要很好看的编码风格,这里有很多主题 http://color-themes.com/?view=ind ...