Golang sync.pool源码解析
Golang sync.pool源码解析
- sync.pool
- 是什么
- 怎么用
- demo
- 真实世界的使用
- 源码解读-数据结构
- 源码解读-读写流程
- 写流程
- 读流程
- 源码解读-细节补充
- 总结
引言
sync.pool 是 golang 语言提供的一种用于缓存对象的“池子”。
可以通过 sync.pool 将对象放入“池”中缓存,在后续创建对象时避免真正申请内存创造对象的步骤,是一种典型的空间换时间的优化思路~
是什么 | 怎么用
sync.pool 是 golang 语言提供的一种对象缓存机制,通过将对象缓存在 pool 中,可以避免每次创建对象的时候都重新申请内存构造对象,而是直接从 pool 中取出对象使用即可,在频繁创建对象和销毁对象的时候极大的缓解了 gc 压力。
使用 demo 和注意事项
sync.pool的使用非常简单,创建池子之后put、get对象即可,全部代码可见:「我的github仓库」。
func NewStudent() *Student {
return &Student{}
}
type Student struct {
Name string
Age int
Right bool
}
func (s *Student) Clear() {
s.Name = ""
s.Age = 0
s.Right = false
}
var studentPool = sync.Pool{
New: func() interface{} {
return NewStudent()
},
}
func main() {
student := studentPool.Get().(*Student)
// 使用student
student.Clear() //返回给studentPool之前必须清空
studentPool.Put(student)
}
虽然使用非常简单,但是在使用的过程中,我们必须注意下面几个事项,以防使用出错。
「非常重要」pool 在使用的时候需要在创建对象的时候或者是销毁的时候清空自己,如果不清空,产生的错误及其难排查错误。具体来说:对于基础数据类型,赋予零值,对于数组之类的,可以使用
[:0]来清空,避免重新申请内存(当然同时要注意数组长度过长还是直接make(T,0)清空合适)。池子对外暴露的方法
Put和Get,其执行顺序没有任何依赖。Put后马上Get,存取的对象没有任何保证是同一个。对大对象使用池优化效果明显:池子本身是对对象的复用,减少了重复创建对象和反复GC的开销,但是由于将对象放入池子中本身也存在一定的开销,因此一般来说对大对象才使用池进行优化,对于小对象可能还有反向优化。
真实世界的使用
在基于 gin 启动的 http server 中,针对到来的 http 请求,会为之分配一个 gin.Context 实例,由于承载关于这次请求链路的上下文信息.
在这个场景中,gin.Context 就是一个可能被量产使用的工具类,其本身创建销毁成本不高,但随着 qps(Query Per-Second) 的增长,可能在短时间内被重复创建、销毁,因此很适合使用对象池技术进行缓存复用.
fmt.Printf ,来源于golang源码:
// go 1.13.6
// pp is used to store a printer's state and is reused with sync.Pool to avoid allocations.
type pp struct {
buf buffer
...
}
var ppFree = sync.Pool{
New: func() interface{} { return new(pp) },
}
// newPrinter allocates a new pp struct or grabs a cached one.
func newPrinter() *pp {
p := ppFree.Get().(*pp)
p.panicking = false
p.erroring = false
p.wrapErrs = false
p.fmt.init(&p.buf)
return p
}
源码解读-数据结构
结构总览
sync.pool设计的结构体的总览图如下:
Pool是对外提供的结构体,作为go的使用方可以直接看到。
local是一个数组,每个元素为poolLocal。其类型是unsafe.pointer也可以用来表示数组,后面单独总结,这先就看成数组即可。poolLocal里面就两个元素:
poolLocalInternal和pad。poolLocalInternal是核心,pad只是为了字节对齐128而产生填充。
poolLocalInternal中两个元素:-
private:每个p私有的元素,不会被其他p操作。 -
poolChain:对外提供双向链表的能力。不同于普通双向链表,其每个节点是一个环形数组而非一个数据。并且提供“有限制的”并发能力。
-
为什么
poolChain中的每个节点是 环形数组 而非节点,大概原因是因为环形数组这样的结构是内存连续的,可以更好的利用cpu缓存的特性,这点更优于链表。而既然环形数组这么优秀,那么为什么
poolChain为什么还是一个链表呢?为什么不把它直接做成一个环形数组?因为环形数组虽然可以利用缓存,但是其必须要提前申请空间,在元素数量不多的情况下会对空间有比较多的浪费。
poolchain的设计
poolChain有如下几个特点:
- lock-free
- 固定大小,ring形结构(底层存储使用数组,使用两个指针标记ehead、tail)
- 单生产者
- 多消费者
- 生产者可以从head进行
pushHead、popHead - 消费者可以从tail进行
popTail
上面提到【poolChain:对外提供双向链表的能力。不同于普通双向链表,其每个节点是一个环形数组而非一个数据。并且提供有限制的并发能力。】,对于有限制的并发能力,指的是:单生产者,可以从head进行pushHead生产、popHead消费;多消费者,消费者可以从tail进行popTail消费。
其具体设计细节虽然对pool的使用性能有很重要的影响,但是并不是本篇文章的重点,因此将其拆分在sync.pool中的“并发”“双向链表”poolChain的设计学习[1]中。
源码解读-主要流程走读
sync.pool在创建之后,对外提供的操作入口之后两个:读(Get)和写(Put),两种操作在某种程度上是”逆反操作“。
归还对象流程
写流程的入口函数是Put函数,其函数如下代码块。主要逻辑也是很简单:
核心源码如下:
// Put adds x to the pool.
func (p *Pool) Put(x any) {
if x == nil {
return
}
l, _ := p.pin() //pin返回的两个元素:当前p对应的poolLocal,当前p的id
if l.private == nil { //private对象对p来说是私有的,存取效率更高,因此优先存取,这里发现没有,就存到这
l.private = x
x = nil
}
if x != nil { //private已经有了,就往shared里面放了,放入shared使用的是头插!
l.shared.pushHead(x)
}
runtime_procUnpin() //接触当前g独占p的状态
}
其中pin元素是比较有意思的,其主要功能是:让当前的g独占当前的p,并获取当前p对应的poolLocal,其源码如下:
// pin pins the current goroutine to P, disables preemption and
// returns poolLocal pool for the P and the P's id.
// Caller must call runtime_procUnpin() when done with the pool.
// pin函数让当前的g独占p,并且返回当前p的poolLocal和P的id
// 调用方必须在使用pool完毕后调用runtime_procUnpin()函数
func (p *Pool) pin() (*poolLocal, int) {
pid := runtime_procPin()
// In pinSlow we store to local and then to localSize, here we load in opposite order.
// Since we've disabled preemption, GC cannot happen in between.
// Thus here we must observe local at least as large localSize.
// We can observe a newer/larger local, it is fine (we must observe its zero-initialized-ness).
s := runtime_LoadAcquintptr(&p.localSize) // load-acquire
l := p.local // load-consume
if uintptr(pid) < s {
return indexLocal(l, pid), pid
}
return p.pinSlow()
}
按理来说没有太多特别的地方,因为按照预想的节奏,每个p与poolLocal是一一对应的关系,因此按照当前p的pid去数组对应下标取poolLocal就可以了!
但是有一点很重要也很有意思,这种p和poolLocal一一对应的关系是什么时候建立的?初始化的时候并没有这个操作! 其奥秘就在pinSlow函数中!
pinSlow的源码如下,简单易懂,主要逻辑是解锁后重新拿锁,并尝试重新分配local和localSize。
func (p *Pool) pinSlow() (*poolLocal, int) {
// Retry under the mutex.
// Can not lock the mutex while pinned.
runtime_procUnpin() //先解绑p与g
allPoolsMu.Lock() //所有pool共享这个锁
defer allPoolsMu.Unlock()
pid := runtime_procPin() //绑定
// poolCleanup won't be called while we are pinned.
s := p.localSize
l := p.local
if uintptr(pid) < s { // 在解绑p与g之后,加锁之前,可能已经有其他的goroutine执行了pinSlow函数,因此再校验一次
return indexLocal(l, pid), pid
}
if p.local == nil {
allPools = append(allPools, p)
}
// If GOMAXPROCS changes between GCs, we re-allocate the array and lose the old one.
// 如果全局(所有goroutine)第一次进入pinSlow函数,或者改变了runtime.GOMAXPROCS导致进入pinSlow函数
// 就会触发local和localSize的重新分配。(原来的直接全部舍弃掉)
size := runtime.GOMAXPROCS(0)
local := make([]poolLocal, size)
atomic.StorePointer(&p.local, unsafe.Pointer(&local[0])) // store-release
runtime_StoreReluintptr(&p.localSize, uintptr(size)) // store-release
return &local[pid], pid
}
下面我们再来看下Put函数的最后一步:l.shared.pushHead(x),函数的定义如下,其主要功能是向共享的双向链表poolChain头插入一个节点。
func (c *poolChain) pushHead(val any) {
d := c.head //对于头的操作是当前p特有的,因此不用考虑并发安全
if d == nil { // 头为nil,即链表中没有元素(没有环形数组),建立环形数组
// Initialize the chain.
const initSize = 8 // 环形数组大小必须是2的次方
d = new(poolChainElt)
d.vals = make([]eface, initSize)
c.head = d
storePoolChainElt(&c.tail, d) //对于尾的操作不是当前p特有的,因此需要用atom相关函数保证并发安全
}
if d.pushHead(val) { //对于环形数组的操作并不是p特有的,因此里面需要考虑并发安全
return
}
// 满了就新建一个元素(环形数组),大小为2倍,最大大小为dequeueLimit(32)
newSize := len(d.vals) * 2
if newSize >= dequeueLimit {
// Can't make it any bigger.
newSize = dequeueLimit
}
d2 := &poolChainElt{prev: d}
d2.vals = make([]eface, newSize)
c.head = d2
storePoolChainElt(&d.next, d2)
d2.pushHead(val)
}
这里面涉及了一些很有意思的设计:
-
poolChain.head不用考虑并发,poolChain.tail需要考虑并发:因为当前p是头插头取,而p操作的时候会使用pin使得当前g独占当前p,因此操作head不会涉及并发;对于其他p的操作是尾取,因此需要考虑并发安全。
拿取对象流程
拿取对象入口是Get函数,Get流程相较于Put稍微复杂,因为Put流程无论什么状态下只会涉及操作当前p绑定的local,但是Get可能会跑到其他p对应的local中的shared的双向链表中“偷取”对象;如果偷不到的话还可能取Vctim中去偷。
Get核心流程图如下,link

从Victim拿取的流程与从Local拿取相比,区别主要是不会优先从shared列表中拿取,原因在于Victim不会再有生产,因此也不用优先从当前的拿取了!
核心源码如下:
func (p *Pool) Get() any {
l, pid := p.pin()
x := l.private //尝试从private拿取
l.private = nil
if x == nil {
// Try to pop the head of the local shard. We prefer
// the head over the tail for temporal locality of
// reuse.
x, _ = l.shared.popHead() //private拿不到就自己的shared拿取,从头部拿取
if x == nil {
x = p.getSlow(pid) //再拿不到就从其他p的local拿取,从尾部开始遍历; 再不行就走Victim拿取的流程
}
}
runtime_procUnpin()
if x == nil && p.New != nil { //最后的兜底,如果还没有拿到,那么就new一个新的出来
x = p.New()
}
return x
}
清理pool流程|poolCleanup函数
主要涉及的是:poolCleanup函数(GC的时候对池化对象的释放)
与 清理pool的流程 强相关的有victim和victimSize两个变量。
victim unsafe.Pointer // local from previous cycle,上一轮的local
victimSize uintptr // size of victims array ,上一轮的localSize
在pool文件的init函数中,其将清理pool的函数poolCleanup注册到gc的钩子中,在每次gc的时候都会执行poolCleanup函数清理sync.pool。
// pool.go文件 start
func init() {
runtime_registerPoolCleanup(poolCleanup)
}
//pool.go文件 end
//mgc.go文件 start
var poolcleanup func()
//go:linkname sync_runtime_registerPoolCleanup sync.runtime_registerPoolCleanup
func sync_runtime_registerPoolCleanup(f func()) {
poolcleanup = f
}
func clearpools() {
// clear sync.Pools
if poolcleanup != nil {
poolcleanup()
}
...
}
// gc入口
func gcStart(trigger gcTrigger) {
//...
clearpools()
//...
}
在sync.pool的中总览图中,对于victim 和victimSize介绍其是上一轮的local和localSize变量,这里的“上一轮”指的是每一次清理sync.pool,因此在每一次gc的时候都会:会将local pool中缓存对象移动到victim cache中,然后在下一次GC时候,清空victim cache对象。
这也是为什么有种说法是
sync.pool中的对象会保留两个gc的时间:第一个gc从local-->victim,第二个gc从victim-->内存释放。
再来看下poolCleanup函数,因为其发生的实际一定是gc期间,因此不用考虑锁、pin绑定之类的函数,一顿操作就行了。
func poolCleanup() {
// This function is called with the world stopped, at the beginning of a garbage collection.
// It must not allocate and probably should not call any runtime functions.
// Because the world is stopped, no pool user can be in a
// pinned section (in effect, this has all Ps pinned).
// Drop victim caches from all pools.
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
// Move primary cache to victim cache.
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
// The pools with non-empty primary caches now have non-empty
// victim caches and no pools have primary caches.
oldPools, allPools = allPools, nil
}
源码解读-其它问题补充
victim数组
Q:在正文的「清理pool流程」部分,我们提到 sync.pool中的某个对象在第一轮gc的时候会从local-->victim,第二轮gc的时候才会从victim中被清理掉,那么为什么要有个victim这一步,而不直接被清理掉呢?
A:victim是“受害者”缓存,相当于是一个gc的缓冲。如果没有victim,那么一次gc之后,下次对象又需要完全重新申请,这时候会增加gc和内存申请的压力。显然victim也是一个空间换时间的做法,保留Victim优化性能的同时,也会带来额外的内存占用的开销!
因此这样的设计思想实际上是与gc类型的语言强绑定的,如果是非gc类的语言,也许需要一些其他类似思想机制代替victim数组。
软件开发领域很少有“银弹“。
unsafe.Pointer代表数组
Q1:local unsafe.Pointer 既然本质上是一个数组,那么为什么不直接按照数组来使用,要搞成 unsafe.Pointer的形式来使用呢?
A1:这里使用unsafe.Pointer的目的是为了性能,如果使用slice,那么为了保证原子性,不可避免的就需要引入Mutex来保证并发安全,而使用unsafe.Pointer之后,就可以使用atomic相关函数。
Q2:在sync.pool中,分别用local和localSize维护数组和数组长度,怎么保证“数据的一致性”的?
A2:既然有两个变量,那么不适用Mutex的情况下肯定是没办法维护两个变量的一致性的。为了防止使用问题,因此只需要保证localSize小于等于数组实际大小即可。
可以从源码中看出,在重新分配的时候是先分配local然后才分配localSize。
// pinSlow函数 重新分配local和localSize,重新分配只会扩容,不会缩容
atomic.StorePointer(&p.local, unsafe.Pointer(&local[0])) // store-release
runtime_StoreReluintptr(&p.localSize, uintptr(size)) // store-release
在读取的时候与分配的时候是相反,先读取localSize再读取local,这样保证不会出现使用问题。
// pin函数
// In pinSlow we store to local and then to localSize, here we load in opposite order.
// 在pinSlow函数中,先储存local,然后储存localSize,因此以反着顺序来转载。
s := runtime_LoadAcquintptr(&p.localSize) // load-acquire
l := p.local // load-consume
Q3:使用了unsafe.Pointer来模拟一个array,那么增删改查操作应该如何完成?
A3:这是一个典型的通用问题,范例代码放在下方,如果刨去疯狂的类型转换,还是非常好理解的!
读取:
// indexLocal
// @Description: 读取对应的内存
// @param l 为数组刚开始的位置转换成的unsafe.Pointer
// @param i 偏移量,相当于[i]中的i
// @return *poolLocal 返回[i]命中的元素
func indexLocal(l unsafe.Pointer, i int) *poolLocal {
lp := unsafe.Pointer(uintptr(l) + uintptr(i)*unsafe.Sizeof(poolLocal{})) //为了能够进行+操作,因此转成uintptr进行操作
return (*poolLocal)(lp)
}
写入:创建一个slice,然后取第0个元素的地址即可。需要注意的是取的是第0个元素的地址,而非slice的地址!
// pinSlow 函数
// @Description: 初始化赋值就直接使用slice的方式来初始化,并且unsafe.Pointer(&local[0])来赋值。
size := xxx
local := make([]poolLocal, size)
atomic.StorePointer(&p.local, unsafe.Pointer(&local[0])) // store-release
runtime_StoreReluintptr(&p.localSize, uintptr(size)) // store-release
golang既然自带gc,为什么官方不从需要被内存回收,但是还没有被内存回收的对象里面拿对象呢?
因为golang中gc的时候是会STW(stop the world)的,这个问题的前提是gc和pool.Get时间上是并行的,因此不存在这样的前提。
noCopy相关
Q:pool结构体相关部分中见到了noCopy相关的成员和注释,like:noCopy noCopy // nocopy机制,用于go vet命令检查是否复制后使用,这个用处是什么?
A:作用就是禁止这个结构产生复制行为,可以禁止的复制行为包括但是不限于显式的复制、隐式的函数传参复制,like:
type User struct {
noCopy noCopy
}
func main() {
u1 := User{}
_ = u1
testFunc(u1)
}
func testFunc(u User) {
}
这时候如果使用go vet {文件名}的命令,就可以检测到是否存在不合理的复制:
(base) ➜ test26 git:(main) ✗ go vet main.go
# command-line-arguments
# [command-line-arguments]
./main.go:10:6: assignment copies lock value to _: command-line-arguments.User contains command-line-arguments.noCopy
./main.go:11:11: call of testFunc copies lock value: command-line-arguments.User contains command-line-arguments.noCopy
./main.go:13:17: testFunc passes lock by value: command-line-arguments.User contains command-line-arguments.noCopy
需要注意的是:go vet检测不合理的复制 != 编译失败。
实际上,现代的IDE也会直接在编译之前提示,like:
Q2:noCopy在源码中是没有暴露出来的,我该怎么使用呢?
A2:没有太好的办法直接使用,最简单的办法就是把源码的视线部分搬到自己的代码中即可:其实就是实现Locker即可,源码如下:
// noCopy may be embedded into structs which must not be copied
// after the first use.
//
// See https://golang.org/issues/8005#issuecomment-190753527
// for details.
type noCopy struct{}
// Lock is a no-op used by -copylocks checker from `go vet`.
func (*noCopy) Lock() {}
func (*noCopy) Unlock() {}
全部代码可见:我的代码仓库
总结
sync.pool为我们提供了一个并发安全的对象池,让我们放心的存取对象,在使用的时候,需要注意”清空“对象。
sync.pool中有很多精妙的设计思想值得我们学习,包括但不限于:poolChain、内存对齐、sync.pool与golang的gpm体系的结合等等。
poolChain:无锁实现一定并发安全能力的poolChain、并且综合链表和环形数组的优劣势。
底层原理中充分考虑到了cpu的缓存,128bit的padding对齐;localPool的private变量
代码是逐步优化来的,就算是golang源码编写者这样级别的大佬们,也没法一步就编写出如此精妙的代码,包括但不限于poolChain环形链表和victim数组的设计都是不断演进来的,而不是一开始就全部设计好的,具体见:Go 1.13中 sync.Pool 是如何优化的?
参考:
https://geektutu.com/post/hpg-sync-pool.html#4-1-fmt-Printf
深度解密 Go 语言之 sync.Pool - Stefno - 博客园
Go 并发编程 — 深度剖析 sync.Pool 源码级原理_并发编程_奇伢云存储_InfoQ写作社区
sync.pool中的“并发”“双向链表”poolChain的设计学习
poolChain在sync.pool中担任了很重要的角色,其作为实际存储对象的结构,在性能、空间消耗上都有比较好的设计值得学习。
poolChain的整体讨论
数据结构上poolChain在sync.pool中的位置大概如下图中的绿色部分,是储存对象的实际结构。
从对外提供的能力来看,其是一个“部分并发安全“的"双向链表",为了保证性能和内存占用,相比于mutex保证并发安全+普通双链表的设计,其在并发安全和节点的设计上都有优化:
双向链表
普通的双向链表中每个节点有三个字段:两个指针+一个值,poolChain中也是类似,不过这个所谓的值是一个环形数组。使用不同容量的环形数组的主要考虑在于:
- 速度更快:双向链表取数没办法很好的利用cpu cache,在高并发读取的时候性能比环形数组差很多。
- 空间占用:环形数组虽然快,但是需要提前申请内存,空间占用比较大,因此采用多级不同容量的环形数组担任节点,平衡了空间消耗和速度。
这样的设计相比于先申请一个小的环形数组,容量不够再申请一个大的来说,减少了搬移之类的消耗。
并发安全
需要注意的是,poolChain提供的是有限制的并发安全,具体来说:
- 单生产者
- 多消费者
- 生产者可以从head进行
pushHead、popHead - 消费者可以从tail进行
popTail
因此head的相关操作,并不需要考虑并发;而tail的相关操作,则需要使用到atomic等相关变量。
在poolChain的设计架构下,需要考虑并发安全的要分成两层来考虑:
对环形数组的增加和删除:
增加只会通过
pushHead函数,删除只会通过popTail函数。pushHead逻辑:
// func (c *poolChain) pushHead
d2 := &poolChainElt{prev: d} //赋予pre
d2.vals = make([]eface, newSize)
c.head = d2
storePoolChainElt(&d.next, d2) //由于popTail会读取poolDeque的next,因此atomic
//先赋值pre和先赋值next都可以,只是赋值next之后,可能popTail就能走到这个新节点d2了,而此时还没有元素进来
//因此走到d2没有任何意义
popTail逻辑:
// func (c *poolChain) popTail
for {
// It's important that we load the next pointer
// *before* popping the tail. 这段注释一直没明白为什么?todo
d2 := loadPoolChainElt(&d.next) if val, ok := d.popTail(); ok {
return val, ok
} if d2 == nil {
// 如果d2为空,说明目前双向链表里面就一个环形数组,不删掉
return nil, false
} // 说明双向链表里面不只一个环形数组,且当前的d已经被排空
// 排空的d是不会再有元素的,因为只会pushHead,如果满了就新建一个,而不是填充到排空的d里面
// 因此排空的d是可以删除的,而且为了后续popHead的时候不走没有意义的空的d,也应该删除
if atomic.CompareAndSwapPointer((*unsafe.Pointer)(unsafe.Pointer(&c.tail)), unsafe.Pointer(d), unsafe.Pointer(d2)) {
storePoolChainElt(&d2.prev, nil)
}
d = d2
}
}环形数组内部
在考虑环形数组的内部的并发安全之前,我们需要知道,在源码中维度的poolChain.popHead、poolChain.popTail等函数,底层调用的,like:
因此对于环形数组内部,对外暴露的同样是
popHead、popTail、pushHead函数,需要考虑并发安全的地方有:
pushHead与popTail
popHead与popTail
popTail之间(不同的p之间popTail存在并发)对头操作的函数之间不用考虑并发,因为在同一个p上的操作已经通过pin相关函数绑定了p与g,不存在并发。
以
poolDequeue.pushHead函数为例,来看看这部分的并发控制管理。
func (d *poolDequeue) pushHead(val any) bool {
//xxx 获取一个slot // 这里需要用atomic来检查当前位置的typ
typ := atomic.LoadPointer(&slot.typ)
// xxx // 在确定当前位置没有值之后,就不用考虑当前head的并发了!因为和pushHead并发的只有popTail,
// 其只会改变tail指向的值,不会改变head的值!
// The head slot is free, so we own it.
if val == nil {
val = dequeueNil(nil)
}
*(*any)(unsafe.Pointer(slot)) = val // Increment head. This passes ownership of slot to popTail
// and acts as a store barrier for writing the slot.
atomic.AddUint64(&d.headTail, 1<<dequeueBits)
return true
}
通用设计:环形数组
poolDequeue的headTail字段是由环形队列的head索引(即rear索引)和tail索引(即front索引)打包而来,headTail是64位无符号整形,其高32位是head索引,低32位是tail索引:
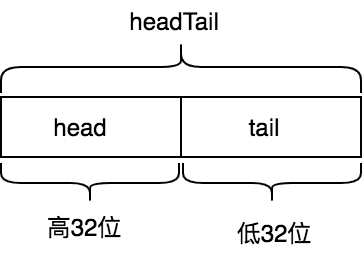
const dequeueBits = 32 func (d *poolDequeue) unpack(ptrs uint64) (head, tail uint32) {
const mask = 1<<dequeueBits - 1
head = uint32((ptrs >> dequeueBits) & mask)
tail = uint32(ptrs & mask)
return
} func (d *poolDequeue) pack(head, tail uint32) uint64 {
const mask = 1<<dequeueBits - 1
return (uint64(head) << dequeueBits) |
uint64(tail&mask)
}
head索引指向的是环形队列中下一个需要填充的槽位,即新入队元素将会写入的位置,tail索引指向的是环形队列中最早入队元素位置。环形队列中元素位置范围是[tail, head)。
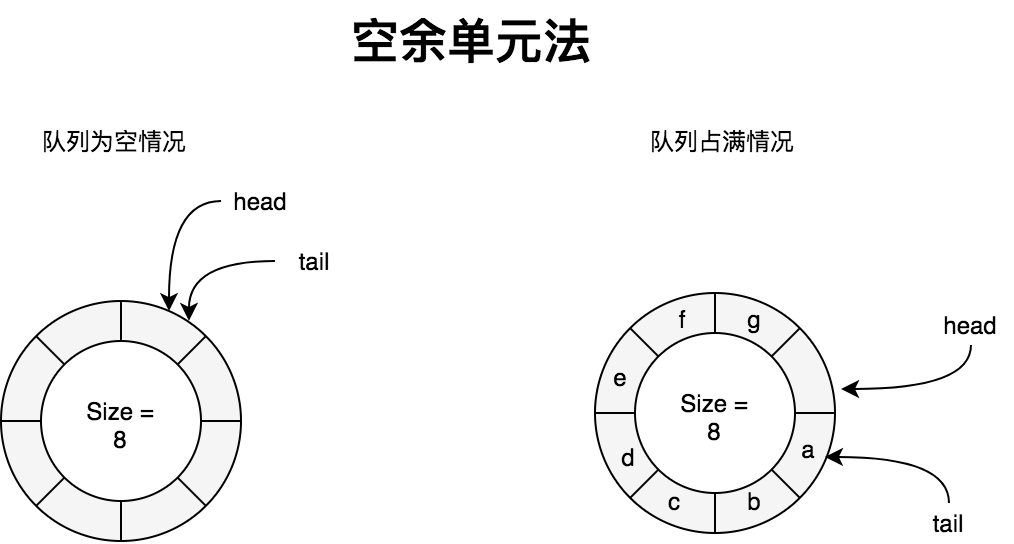
我们知道环形队列中,为了解决
head == tail即可能是队列为空,也可能是队列空间全部占满的二义性,有两种解决办法:1. 空余单元法, 2. 记录队列元素个数法。采用空余单元法时,队列中永远有一个元素空间不使用,即队列中元素个数最多有QueueSize -1个。此时队列为空和占满的判断条件如下:
此时head和tail的取值范围为[0,size-1]
head == tail // 队列为空
(head + 1)%QueueSize == tail // 队列已满
而
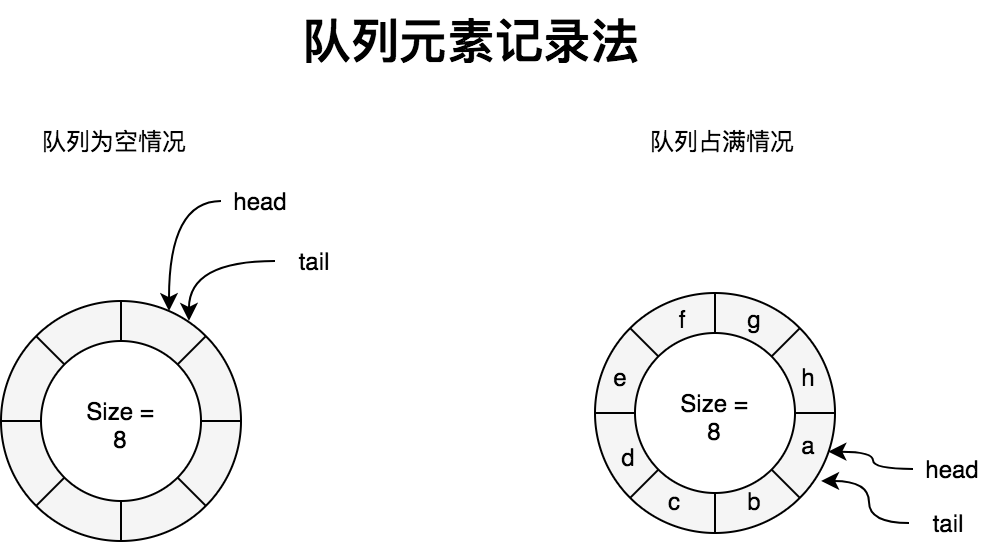
poolDequeue采用的是记录队列中元素个数法,相比空余单元法好处就是不会浪费一个队列元素空间。这种方案队列为空和占满的判断条件如下:此时head和tail的取值为[0,取值max],一直++操作移位即可,一般直接使用uxxx(正整型)相关的变量类型,不会产生绕回问题。
head == tail // 队列为空
tail + nums_of_elment_in_queue == head
参考:
golang 源码
Golang sync.pool源码解析的更多相关文章
- 多图详解Go的sync.Pool源码
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com 本文使用的go的源码时14.4 Pool介绍 总所周知Go 是一个自动垃圾回收的编程语言 ...
- go sync.map源码解析
go中的map是并发不安全的,同时多个协程读取不会出现问题,但是多个协程 同时读写就会出现 fatal error:concurrent map read and map write的错误.通用的解决 ...
- 深入浅出ReentrantLock源码解析
ReentrantLock不但是可重入锁,而且还是公平或非公平锁,在工作中会经常使用到,将自己对这两种锁的理解记录下来,希望对大家有帮助. 前提条件 在理解ReentrantLock时需要具备一些基本 ...
- 深入浅出Semaphore源码解析
Semaphore通过permits的值来限制线程访问临界资源的总数,属于有限制次数的共享锁,不支持重入. 前提条件 在理解Semaphore时需要具备一些基本的知识: 理解AQS的实现原理 之前有写 ...
- Gin框架源码解析
Gin框架源码解析 Gin框架是golang的一个常用的web框架,最近一个项目中需要使用到它,所以对这个框架进行了学习.gin包非常短小精悍,不过主要包含的路由,中间件,日志都有了.我们可以追着代码 ...
- TiKV 源码解析系列文章(三)Prometheus(上)
本文为 TiKV 源码解析系列的第三篇,继续为大家介绍 TiKV 依赖的周边库 rust-prometheus,本篇主要介绍基础知识以及最基本的几个指标的内部工作机制,下篇会介绍一些高级功能的实现原理 ...
- 【协作式原创】查漏补缺之Golang中mutex源码实现(预备知识)
预备知识 CAS机制 1. 是什么 参考附录3 CAS 是项乐观锁技术,当多个线程尝试使用 CAS 同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是 ...
- RxJava2源码解析(二)
title: RxJava2源码解析(二) categories: 源码解析 tags: 源码解析 rxJava2 前言 本篇主要解析RxJava的线程切换的原理实现 subscribeOn 首先, ...
- [源码解析] 并行分布式框架 Celery 之架构 (2)
[源码解析] 并行分布式框架 Celery 之架构 (2) 目录 [源码解析] 并行分布式框架 Celery 之架构 (2) 0x00 摘要 0x01 上文回顾 0x02 worker的思考 2.1 ...
- [源码解析] 深度学习流水线并行 GPipe(3) ----重计算
[源码解析] 深度学习流水线并行 GPipe(3) ----重计算 目录 [源码解析] 深度学习流水线并行 GPipe(3) ----重计算 0x00 摘要 0x01 概述 1.1 前文回顾 1.2 ...
随机推荐
- 贴代码框架PasteForm特性介绍之markdown和richtext
简介 PasteForm是贴代码推出的 "新一代CRUD" ,基于ABPvNext,目的是通过对Dto的特性的标注,从而实现管理端的统一UI,借助于配套的PasteBuilder代 ...
- 高性能计算-gemm-openmp效率测试(10)
1. 目标 设计一个程序,使用OpenMP并行化实现矩阵乘法.给定两个矩阵 A 和 B,矩阵大小均为1024*1024,你的任务是计算它们的乘积 C. 要求: (1).使用循环结构体的知识点,包括fo ...
- JDBC中驱动加载的过程分析
江苏 无锡 缪小东 本篇从java.sql.Driver接口.java.sql.DriveManager类以及其它开源数据库的驱动类讨论JDBC中驱动加载的全过程以及JDBC的Framework如何做 ...
- 基于antlr的表达式解析器——函数生成(通过freemarker)
第一步.新建一个模板文件以.ftl结尾. Max.ftl /* * Copyright 2002-2007 Robert Breidecker. * * Licensed under the Apac ...
- Linux常用系统性能监控工具
top 首先关于top命令,我想大家应该都挺熟悉的了. Linux系统下的top命令有点类似于Windows系统里的任务管理器,能够实时动态地给出系统中各个进程的资源占用状况,是Linux下比较常用的 ...
- pg_index
在pg11之后,引入了indnkeyatts字段,根据官方文档解释其作用:The number of key columns in the index, not counting any includ ...
- 你真的懂System.out.println()吗?
简介 众所周知,Java语言是面向对象的,那如果让你用一行代码体现出来呢? 如果你能自己读懂System.out.println(),就真正了解了Java面向对象编程的含义. 面向对象编程即创建了对象 ...
- Java JUC&多线程 基础完整版
Java JUC&多线程 基础完整版 目录 Java JUC&多线程 基础完整版 1. 多线程的第一种启动方式之继承Thread类 2.多线程的第二种启动方式之实现Runnable接口 ...
- go编译可以指定os和arch
是的,Go 编译器支持通过环境变量来指定目标操作系统(OS)和架构(Arch).这允许你为不同的平台交叉编译 Go 程序.你可以使用 GOOS 和 GOARCH 环境变量来指定目标系统. 例如,如果你 ...
- Linux安装EasyConnect
首先下载并安装EasyConnect客户端 wget http://download.sangfor.com.cn/download/product/sslvpn/pkg/linux_767/Easy ...