DeepSeek引发的AI发展路径思考
DeepSeek引发的AI发展路径思考
参考文章来源于科技导报 ,作者李国杰院士 | 哈工大 DeepSeek 技术前沿与应用讲座
1. DeepSeek 的科技突破
7 天之内 DeepSeek 的用户增长超过 1 亿,此同时,芯片巨头公司英伟达(NVIDIA)的股价单日暴跌 17%,市值缩水 5890 亿美元。
DeepSeek 的崛起(高效率,低成本):
- 人工智能行业以算法和模型架构优化为主 | 打破了高算力和高投入是发展人工智能唯一途径;
- 高度重视数据质量与规模、理性提高算力 | 打破了集成电路制度优势 = 人工智能技术霸权;;
全球人工智能龙头企业主动融入 DeepSeek 生态,相继宣布在其 AI 服务平台上部署 DeepSeek V3 和 R1 模型,而 DeepSeek 的 V3 和 R1 在模型算法和系统软件层次都有重大创新,并且证明了推理模型的开发比想象中更为简单。
核心贡献
- 引入强化学习 (RL) ,模型自主学习到推理能力,性能接近 o1 模型;
- 极致的模型架构优化,训练,推理速度更快,远超 o1 类模型;
- 开源模型及其蒸馏子模型;
NLP的第六次范式变迁—推理能力
- 小规模专家知识:1950~1990;
- 浅层机器学习算法:1990~2010;
- 深度学习:2010~2017;
- 预训练语言模型:2018~2023;
- 大模型:2023~2024;
- 推理(Reasoning):2025(DeepSeek);
DeepSeek 发展历程
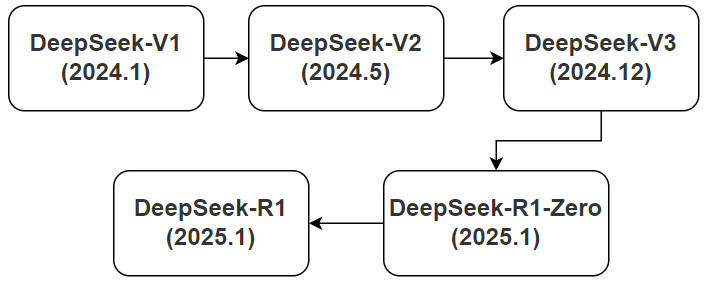
- 引入 GRPO无需价值网络,在提高学习稳定性的同时降低学习开销;
- GRPO 利用当前策略模型进行多次采样,使用平均奖励值近似价值函数;
强化学习(RL)
将 RL 引入模型,使用 RL 学习推理能力;
RL 不需要复杂的算法,简答 GRPO 即够用;
随着 RL 步骤数的增加,模型的性能逐步增强;
RL 需要大量的数据,但训练过程中不需要过程奖励,结果奖励足够;
RL 的 Aha 时刻:随着 RL 步骤数的增加,会在某一步突然涌向出反思/自我评估机制;
DeepSeek-V3
用型 NLP 模型,适合广泛的多任务场景,强调高效性和多模态处理能力。
模型参数量 6710 亿,采用自主研发的混合专家模型(MoE)架构,每一层有 256 个细分领域的路由专家和 1 个共享专家,每次调用只激活约 370 亿个参数,显著降低了训练计算成本;
改进的多头潜在注意力机制(MLA),减少了键值缓存开销,把显存占用降到了其他大模型的 5%~13%,极大提升了模型运行效率;
DeepSeek-R1
- 专精于复杂逻辑推理的优化版本,通过强化学习提升推理能力,适用于科研、金融量化等高复杂度任务。
- 模型摒弃了传统的监督微调(SFT),开创性地提出群组相对策略优化(GRPO),直接通过强化学习从基础模型中激发推理能力,大幅降低了数据标注成本,简化了训练流程。
2. 规模法则(Scaling Law)的尽头
术之尽头
2020 年 1 月,OpenAI 发表论文《神经语言模型的规模法则》(Scaling Laws for Neural Language Models),提出规模法则:“通过增加模型规模、数据量和计算资源,可以显著提升模型性能。
不同于牛顿定律是经过无数次验证的科学定律,规模法则是 OpenAI 等公司在大模型研制过程中的经验归纳:
- 从科学研究的角度看,属于一种对技术发展趋势的猜想;
- 从投资的角度看,属于对某种技术路线的押注;
- 一种信仰或猜想当成科学公理,不是科学的态度;
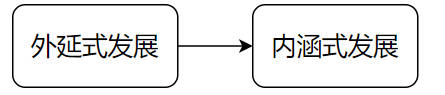
继续投入巨资追求高算力?还是在算法优化上下更多功夫?DeepSeek 的问世标志着人工智能训练模式从“大力出奇迹”的外延式发展阶段,转向集约化系统优化的内涵式发展阶段。
3. 通用人工智能”(AGI)的技术路线
莫拉维克悖论:“复杂的问题是易解的,简单的问题反而是难解的。”
通用人工智能尚未得到准确共识,目前人工智能学术界更关注智能系统持续学习,自我改进的能力。人工智能的通用性不仅表现在对语言的处理上,还包括像人一样基于常识和日常经验与外部客观世界互动的能力。
在科学技术领域,所谓“通用”一定是相对的,有一定的条件或范围。我们要认识人工智能的局限性,不能盲目追求能够解决所有问题的人工智能。 而不同公司走向“通用人工智能”(AGI)的技术路线不同(类比集成电路领域就有“通用”与“专用”10 年交替演化的“牧本周期”):
OpenAI(由通到专)
路线:参考 Scaling Law 扩大模型规模,先做出通用的基础模型,再“蒸馏”出各行业可使用的行业垂直模型;
关键问题:大模型训练成本 | 保持模型泛化的同时提高特定领域的性能和效率
DeepSeek(由专到通)
路线:在模型算法和工程优化方面进行系统级创新,为在受限资源下探索通用人工智能开辟新的道路;
混合专家模型:集小智为大智,集专智为通智。“小而精”的模型将人工智能的重点发展方向从面向企业的 to B 引向更贴近消费者的 to C;
关键问题:整合多个专用模型为通用模型也需要解决诸多技术和工程问题,如模型间的接口、数据格式的统一、训练时的负载平衡等;
4. 高算例 OR 高能效
发展人工智能的初始动机是模拟人脑,自然界进化了数百万年的人脑是一个计算效率和能效极高的计算装置,功耗只有 20W 左右。
- 人脑的极低功耗是因为采取了分布式的模拟计算;
- 目前计算机的高能耗是因为采用软硬件分离的数字计算;
低成本是技术普及的基本要求,蒸汽机、电力和计算机的普及都是其成本降低到大众可以接受时才做到的,人工智能肯定也会走这条路。
5. 开源生态
将 DeepSeek 提供的小而精的模型下载到本地,即使断网也可以“蒸馏”出高效率的垂直模型
真正的 AI 竞争,不仅仅是技术和模型的竞争,更是生态系统、商业模式,以及价值观的竞争。开源模型让每个开发者都能轻松调用强大 AI 工具,不再受大公司的约束,AI 的进化速度将会明显提升。
技术创新
长期以来,中国人工智能领域的高技术企业大多重视应用创新和商业模式创新,追求的目标是快速盈利,很少参与核心技术创新。人工智能不同于资本密集型和经验积累型的集成电路产业,不仅要“烧钱”,更要“烧脑”,本质上是拼人的智力的新兴产业。因此人工智能产业具有明显的不对称性,一个具有 100 多个聪明头脑的小企业就可以挑战市值上万亿的龙头企业。
产业生态
要实现人工智能自立自强,最困难的是构建自主可控的产业生态。英伟达公司的“护城河”不是 GPU 芯片本身,而是统一计算设备架构(CUDA)软件生态。DeepSeek 冲击了 CUDA 生态,但没有完全绕过 CUDA,其生态壁垒仍然存在。从长远来讲,需要开发一套比 CUDA 更优秀的自主可控的 AI 软件工具系统,重构 AI 软件生态。
DeepSeek引发的AI发展路径思考的更多相关文章
- 游戏AI之路径规划(3)
目录 使用路径点(Way Point)作为节点 洪水填充算法创建路径点 使用导航网(Navigation Mesh)作为节点 区域分割 预计算 路径查询表 路径成本查询表 寻路的改进 平均帧运算 路径 ...
- 对EasyDarwin开源项目后续发展的思考:站在巨人的肩膀上再跳上另一个更高的肩膀
2017 EasyDarwin现状 自从2012年EasyDarwin项目创立开始,经过了快5年了,时光飞逝,如今EasyDarwin已经发展成为了不仅仅是一个单纯的开源流媒体服务器项目了,已经是各种 ...
- 由异常:Repeated column in mapping for entity/should be mapped with insert="false" update="false 引发对jpa关联的思考
由异常:Repeated column in mapping for entity/should be mapped with insert="false" update=&quo ...
- 贾扬清谈大数据&AI发展的新挑战和新机遇
摘要:2019云栖大会大数据&AI专场,阿里巴巴高级研究员贾扬清为我们带来<大数据AI发展的新机遇和新挑战>的分享.本文主要从人工智能的概念开始讲起,谈及了深度学习的发展和模型训练 ...
- AI - 学习路径(Learning Path)
初见 机器学习图解 错过了这一篇,你学机器学习可能要走很多弯路 这3张脑图,带你清晰人工智能学习路线 一些课程 Andrew Ng的网络课程 HomePage:http://www.deeplearn ...
- Lattice并购案&我国FPGA发展路径
FPGA作为通信.航天.军工等领域的关键核心器件,是保障国家战略安全的重要支撑基础.近年来,随着数字化.网络化和智能化的发展,FPGA的应用领域得到快速扩张.美国在FPGA领域拥有绝对的垄断优势,已成 ...
- 关于AI本质的思考
前言 最近几天和一位朋友探讨了一下现阶段的人工智能以及未来发展,并且仔细重读了尤瓦尔赫拉利的“简史三部曲”,产生了一些关于AI的新想法,觉得有必要整理出来. 程序.AI的本质 现代的计算机都是基于图灵 ...
- try catch引发的性能优化深度思考
关键代码拆解成如下图所示(无关部分已省略): 起初我认为可能是这个 getRowDataItemNumberFormat 函数里面某些方法执行太慢,从 formatData.replace 到 une ...
- Topk引发的一些简单的思考
软件工程课程的一个题目:写一个程序,分析一个文本文件中各个词出现的频率,并且把频率最高的10个词打印出来.文本文件大约是30KB~300KB大小. 首先说一下这边的具体的实现都是在linux上实现的. ...
- 一个神秘现象引发对beego框架的思考
小强最近在项目中遇到了一个很奇怪的问题:在整改日志规范时,为了避免影响现有的代码结构以及改动尽可能小的前提下,在调用记日志的SDK处将某一个字段值首字母改为大写,代码示例如下: fmt.Println ...
随机推荐
- .NET 9 new features-分布式追踪支持、HTTP/3 改进以及更好的容器镜像支持
.NET 9 针对云原生开发进行了显著优化,重点改进了分布式追踪.HTTP/3 支持和容器镜像优化等方面. 这些特性极大地提升了 .NET 在现代云原生应用中的适配性与开发效率. 1. 设计原理 1. ...
- 密码应用——数字证书与PKI
数字证书与PKI 数字证书 非对称加密体制中,公钥的获取途径非常重要. 验证数字签名.保密通信都需要保证公钥真实性 BOB的网站(假的) BOB的个人简介(盗用来的真实信息) Mallory ...
- SQL统计数据之总结
一.查询SQL SELECT t1.规则编号 AS 编码, t1.规则描述 AS 名称, SUM( CASE WHEN t3.DATA_SOURCES = '00' THEN 1 ELSE 0 END ...
- 数据同步工具-DataX
1.DataX 基本介绍 DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具,致力于实现包括:关系型数据库(MySQL.Oracle等).HDFS.Hive.HBase.ODPS.FTP等各种异 ...
- SM4代码实现
算法过程 更多的原理介绍参考:SM4原理介绍 代码实现 S盒实现 #include <stdio.h> /* SM4-S盒实现: 由三个复合函数组成,S(x)=L(I(L(x))),其中L ...
- 让你看懂dart中静态成员和继承
静态属性和静态方法 在dart中,我们可以通过关键字 static来定义静态属性和静态方法. 需要注意的是: 静态方法不能访问非静态属性[结论1] 非静态方法可以访问静态成员[结论2] 我们通过下面的 ...
- Svelte 最新中文文档翻译(5)—— 基础标记
前言 Svelte,一个非常"有趣".用起来"很爽"的前端框架.从 Svelte 诞生之初,就备受开发者的喜爱,根据统计,从 2019 年到 2024 年,连续 ...
- 在SOUI4中使用非客户区自绘
前段时间用sdl嵌入SOUI做视频播放器,由于SOUI习惯屏蔽系统默认的非客户区,而在窗口自己的客户区分出一块来模拟非客户区,导致窗口在拉伸的时候,SOUI窗口会出现比较严重的闪烁(不光是SOUI这样 ...
- Transaction rolled back because it has been marked as rollback-only问题解决
1.背景 在我们的日常开发中,经常会存在在一个Service层中调用另外一个Service层的方法.比如:我们有一个TaskService,里面有一个execTask方法,且这个方法存在事务,这个方法 ...
- Ubuntu Linux部署DeepSeek
技术背景 DeepSeek是这段时间最热门的话题之一,其蒸馏模型可以实现低成本而高质量的推理,使得我们现在可以在本地小型化的硬件上也用上大模型这一AI利器.本文主要介绍通过Ollama来部署DeepS ...