关于普通程序员该如何参与AI学习的三个建议以及自己的实践
大部分程序员在学习大语言模型的时候都比较痛苦,感觉AI是如此之近又如此之远,仿佛能搞明白一点,又好像什么也没明白。就像我们在很远的地方看珠穆拉玛峰,感觉它就像一个不大的山包,感觉只要自己做足准备咬咬牙还是能登顶的。但当你越走越近,试图接近它并翻越它时就会发现它的庞大和自己的渺小,以至于你每走一步都无法呼吸、都会大脑缺氧。学习大模型的过程也是如此。那么对于大部分程序员来说该如何参与AI的学习呢?下面就是我的个人建议(仅个人想法):
1、关于大语言模型的学习
网上很多关于AI大语言模型(或神经网络)的课程,都是号称能帮你入门。如果你的数学基础比较差,比如忘了高中时学的向量和矩阵、忘了大学时学的线性代数和微积分,那么基本上就是从入门到放弃。比如当你看到Transformer的注意力计算公式:
\[
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V
\]
当然如果你的数学底子比较好,也未必能学好大模型,因为只有实践才能验证算法,但这个实践成本是非常高的,也就是下面的大力出奇迹。
2、关于大力出奇迹
目前所有的AI大模型都是大力出奇迹的结果,没有算力的支撑,Transformer模型中各层的数学公式都是可疑的,它只具备理论上的可行性。GPT验证了Trannformer模型是成功的,同时证明了多头Antention机制,证明了残差网络(ResNet)以及FNN存在的意义,最终证明了神经网络各层的数学公式确实可以组合在一起并拟合神经网络。
如果没有成功呢?现在大部分文章都是站在上帝的视角解释Transformer模型,解释每层数学公式的合理性和必然性,解释Q、K、V设计的巧妙。比如形象的比喻Q是查询、K是关键字、V是查询后的值,这种解释仿佛能让你恍然大悟,实际上相当的扯淡。为什么是8头Attention而不是6、7头或者10头,为何FNN中将x从512维升维4倍从而能捕捉更多的语义特征,为何不升到6倍、8倍呢?
所有这些都是基于大力出奇迹的结果,就是通过不断的测试发现8头最合理,升维4倍的特征捕获更好泛化能力更强。否则谁都不敢保证初始设计的合理性。
不是每个人都有机会接触到庞大的计算资源,不是每家公司都有能力建造计算中心让你可劲的验证“想法”、可劲的造。毕竟验证一次可能就需要成百上千万的人民币。这可不是程序员跑一次Demo然后debug一下那么简单的事。
那么程序员该如何参与这轮AI竞赛呢?关于Deepseek和Manus。
3、关于Deepseek和Manus
Deepseek代表大脑,体现的是数学能力;Manus代表四肢,体现的是工程能力。
有很强的大脑,但四肢不行,那就等于半身不遂;大脑很弱,但四肢发达,也没用,因为可能方向都会搞错。你让数学家写代码肯定不行,让程序员搞数学研究大模型算法肯定也不合适。让合适的人做合适的事才是正确的方法。所以,对于大部分程序员来说,如果你真的看不懂大语言模型的算法,也没什么关系。因为程序员最强的是工程能力,就是开发各类agent工具帮助Deepseek这个大脑发挥它的现实作用。这个大脑加到机器人上,就是真正的智能机器人;加到家电上就是真正的智能家电。
同样,如果和各种软件结合一起工作就是“Manus”,就是综合智能体。这块是我们程序员擅长的,就是让AI不至于全身不遂。
正因如此,我觉的自己是爬不上去了,数学也越看越头痛,甚至产生了AI是一门玄学的幻觉,那就回归本行开发agent,写一个属于自己的Deepseek助手吧
2025年02月06号,大年初九,春节假期结束第二天,DeepSeek开放注册,也就是可以申请API Key,仅1天之后Deepseek即关闭了注册通道,直到2月25号重新开放注册。比较幸运的是我在2月6号那天申请到了API Key,前提是支付了300元。我认为这个钱非常值得,不是因为deepseek的token费用相对比较低。而是因为:对于国产AI大模型来说能够做到开源开放就值得你去支持他。
在此前四天,也就是2025年2月2号,大年初五迎财神那天,我迎来了deepseek,在自己8G内存笔记本上勉强部署了deepseek r1-7b。网上有很多提供免费接入满血的Deepseek方法,但大部分都是基于第三方的间接接入。即使自己部署的deepseek也是通过第三方工具进行接入,比如本地知识库(RAG)的建立或者进行联网搜索。
对于普通用户来说没有问题,但对于程序员来说既然申请到了API Key,就可以不再需要通过第三方而是直接写一个agent接入自己本地部署的deepseek或者满血的deepseek。问题是,我不会Python,只会C/C++。使用python调用API接口非常简单,但用C++开发难度比较大,比如网络通信这块。
大模型(特指Transformer模型)按照一个一个token进行输出,站在TCP传输的角度就是按流(stream)输出。这种按流输出的方式对用户的体验非常好,用户可以直观的看到大模型在不断“说话”。
如果不是按流输出,用户可能会等待很长时间才能看到全部会话结果。其后果是用户不知道在此期间发生了什么,是模型还在“思考”,还是思考后的“补全”,或是因为“太忙”而无法处理请求。站在程序开发的角度,就是你要设置一个较大的“超时”来处理这种等待。
但如何设置超时,2分钟、5分钟、还是10分钟?如果用户的问题确实比较复杂,比如自己的老婆和丈母娘同时掉入水中到底该救谁?对于这类棘手问题,正常人也会考虑一会,对大模型而言就是进行深度“思考”并推理,这个时间不是因为AI服务器太忙造成的,而是因为你的问题值得他去思考这么长时间,毕竟现实当中如果脱口而出先救谁可能后果是灾难性的。
此外当你使用RAG和联网搜索时,AI模型还要额外的思考你提供的上下文信息,如果你的上下文信息(Prompt)组织的不好,也会让AI多“思考”。这里存在一个隐性的时间开销就是,RAG的搜索向量数据库或者联网搜索的时间,对于上层用户而言,这些时间都会算在AI的头上。
说了这么多就是想表达一点:如果考虑用户体验,你只能选择按流(stream)的方式调用API接口。
就客户端编程而言,处理流式输出比较困难,如果这个流式输出又按照chunk(块)的组织方式进行那就比较棘手,如果这些块又是经过压缩的(gzip、deflate),那么还要考虑进行解压操作。
显性表现就是web服务器在响应头中包含了如下两项:
Transfer-Encoding: chunked
Content-Encoding: gizp
按chunk块的方式接收解析数据的难点在于,你可能一次接收到多个块,或者不完整的块。而不是你想象的那样恰好接收一个完整的块。即使web服务器确实按照一块一块这么发送数据。
说了这么多就是想表达,相较于Python,使用C/C++开发的难度比较大,哪怕只是调用一个简单的API接口。言归正传,介绍一下DeepseekUser。
该工具特点
1、支持满血版Deepseek的联网访问;
2、支持本地部署Deepseek的联网访问;
3、支持深度搜索和联网搜索(本程序使用博查搜索接口);
4、支持多轮回话;
5、支持历史会话记录的轻量化存储;
6、支持历史会话记录的查看;
7、可查看自己token的使用情况;
如何使用DeepseekUser工具
1、下载解压DeepseekUser.zip,双击运行DeepseekUser.exe
2、申请Deepseek的API Key,申请网址
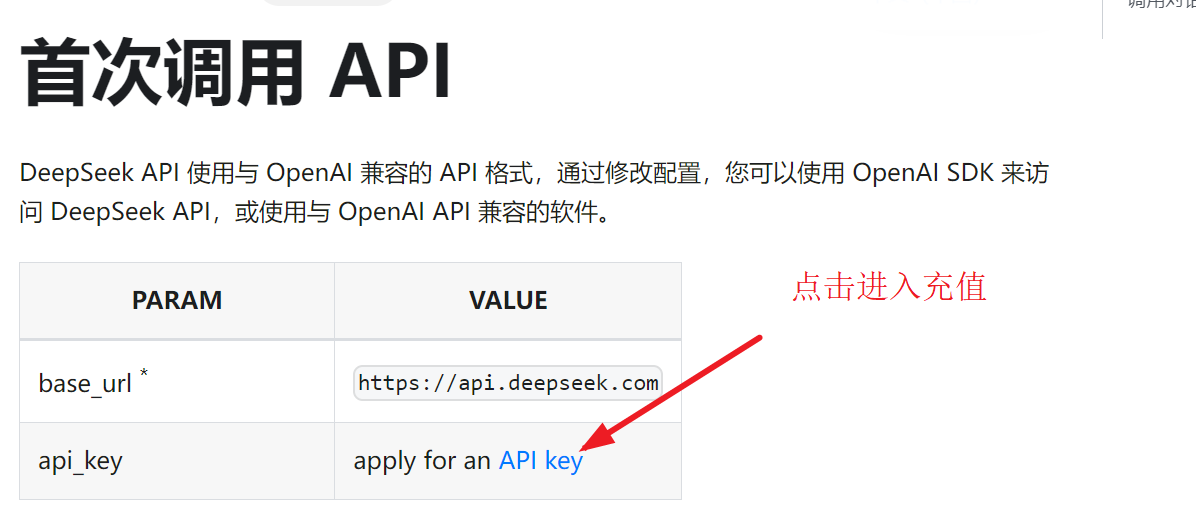
3、将申请到的APIKey填入“设置”的如下对话框中
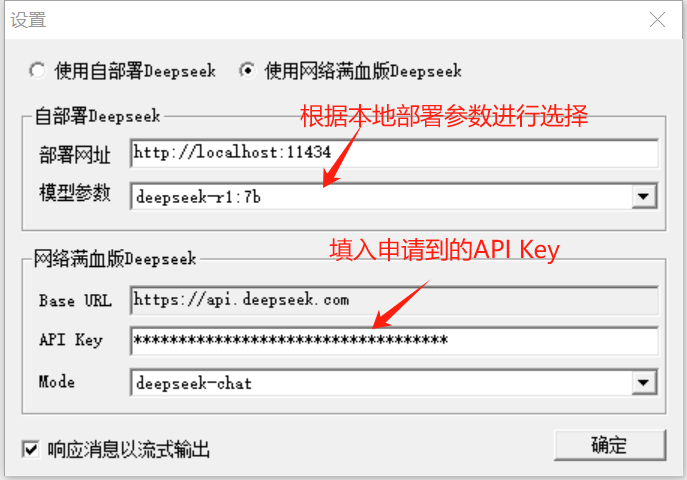
注意事项
- 关于“多轮会话”:
开启此功能比较耗费token,由于Deepseek不记录每次会话的历史信息,因此需要将历史会话记录作为上下文发送给后端,从而让Deepseek知道你们之前聊了什么。官网上的说法:“API 是一个“无状态” API,即服务端不记录用户请求的上下文,用户在每次请求时,需将之前所有对话历史拼接好后,传递给对话 API。”
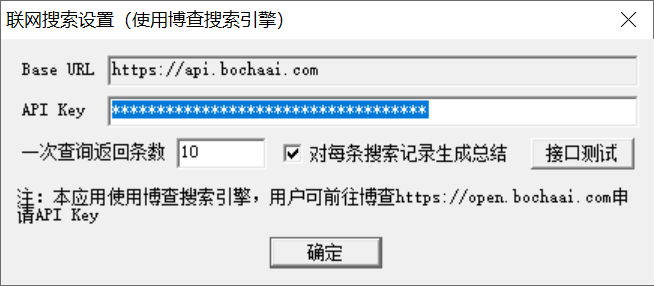
由于该工具使用的是自己的API Key,因此费用需要自己承担(土豪随意)。 - 关于“联网搜索”
由于本助手只集成了博查的搜索功能,因此需要用户自行申请博查的的API Key,申请完成后填入配置中即可。
关于普通程序员该如何参与AI学习的三个建议以及自己的实践的更多相关文章
- 普通程序员如何转向AI方向
眼下,人工智能已经成为越来越火的一个方向.普通程序员,如何转向人工智能方向,是知乎上的一个问题.本文是我对此问题的一个回答的归档版.相比原回答有所内容增加. 一. 目的 本文的目的是给出一个简单的,平 ...
- 普通程序员如何转向AI方向(转)
普通程序员如何转向AI方向 眼下,人工智能已经成为越来越火的一个方向.普通程序员,如何转向人工智能方向,是知乎上的一个问题.本文是我对此问题的一个回答的归档版.相比原回答有所内容增加. 一. 目的 ...
- 分享 - 普通程序员如何转向AI方向
原作者:计算机的潜意识 原文链接,内容稍有改动,侵删 1. 目的2. AI领域简介3. 学习方法4. 学习路线 0) 领域了解1) 知识准备2) 机器学习3) 实践做项目4) 深度学习5) 继续机器学 ...
- 【转帖】普通程序员如何转向AI方向
普通程序员如何转向AI方向 https://www.cnblogs.com/subconscious/p/6240151.html 眼下,人工智能已经成为越来越火的一个方向.普通程序员,如何转向人工智 ...
- 普通程序员转型AI免费教程整合,零基础也可自学
普通程序员转型AI免费教程整合,零基础也可自学 本文告诉通过什么样的顺序进行学习以及在哪儿可以找到他们.可以通过自学的方式掌握机器学习科学家的基础技能,并在论文.工作甚至日常生活中快速应用. 可以先看 ...
- 普通程序员如何入门AI
毫无疑问,人工智能是目前整个互联网领域最火的行业,随着AlphaGo战胜世界围棋冠军,以及各种无人驾驶.智能家居项目的布道,人们已经意识到了AI就是下一个风口.当然,程序员是我见过对于新技术最敏感的一 ...
- [置顶]
普通程序员如何入门AI
毫无疑问,人工智能是目前整个互联网领域最火的行业,随着AlphaGo战胜世界围棋冠军,以及各种无人驾驶.智能家居项目的布道,人们已经意识到了AI就是下一个风口.当然,程序员是我见过对于新技术最敏感的一 ...
- 《死磕 Elasticsearch 方法论》:普通程序员高效精进的 10 大狠招!(完整版)
原文:<死磕 Elasticsearch 方法论>:普通程序员高效精进的 10 大狠招!(完整版) 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链 ...
- 如何从普通程序员晋升为架构师 面向过程编程OP和面向编程OO
引言 计算机科学是一门应用科学,它的知识体系是典型的倒三角结构,所用的基础知识并不多,只是随着应用领域和方向的不同,产生了很多的分支,所以说编程并不是一件很困难的事情,一个高中生经过特定的训练就可以做 ...
- 一位资深程序员给予Java初学者的学习路线建议
一位资深程序员给予Java初学者的学习路线建议 java学习这一部分其实也算是今天的重点,这一部分用来回答很多群里的朋友所问过的问题,那就是我你是如何学习Java的,能不能给点建议?今天我是打算来点干 ...
随机推荐
- Idea中@Autowired 黄色波浪线问题以及注入类显示红色波浪线问题解决
解决办法: 点开路径:File--->Settings--->Editor--->Inspections--->Spring--->Spring core--->C ...
- 即时通讯技术文集(第13期):Web端即时通讯技术精华合集 [共15篇]
为了更好地分类阅读52im.net 总计1000多篇精编文章,我将在每周三推送新的一期技术文集,本次是第13 期. [- 1 -] 新手入门贴:史上最全Web端即时通讯技术原理详解 [链接] http ...
- IM全文检索技术专题(四):微信iOS端的最新全文检索技术优化实践
本文由微信开发团队工程师" qiuwenchen"分享,原题"iOS微信全文搜索技术优化",有修订. 1.引言 全文搜索是使用倒排索引进行搜索的一种搜索方式.倒 ...
- 基于源码分析 SHOW GLOBAL STATUS 的实现原理
问题 在 MySQL 中,查询全局状态变量的方式一般有两种:SHOW GLOBAL STATUS和performance_schema.global_status. 但不知道大家注意到没有,perfo ...
- 配置Ubuntu上的NFS
$sudo apt-get install nfs-kernel-server nfs-common 配置 $sudo vim /etc/exports#添加#/home/pi/project/roo ...
- 日志数据采集-Flume
1. 前言 在一个完整的离线大数据处理系统中,除了hdfs+mapreduce+hive组成分析系统的核心之外,还需要数据采集.结果数据导出.任务调度等不可或缺的辅助系统,而这些辅助工具在hadoop ...
- Java技术栈总结-基础
- - -计算机技术演化- - -1 编程语言演化1.1 写在最前 此文用于个人总结,串接知识点 1.2 汇编 举例:mov .add 特点:程序量很大,几百行.几千行乃至几万行 1.3 VB- ...
- Superset 筛选器理解
免于被筛选器筛选,dashboard中,编辑,高级,"__time_range": {"scope": ["ROOT_ID"], " ...
- GDAL矢量数据集相关接口的资源控制问题
1. 引言 笔者在<使用GDAL读写矢量文件>这篇文章中总结了通过GDAL读写矢量的具体实现.不过这篇文章中并没有谈到涉及到矢量数据集相关接口的资源控制问题.具体来说,GDAL/OGR诞生 ...
- VMware常用操作
VMware常用操作 VMware作为一款功能强大的虚拟化软件,为用户提供了一个灵活.高效的虚拟环境.在日常使用中,掌握VMware的常用操作对于提高工作效率.优化资源配置至关重要.以下将详细介绍VM ...