Kafka入门实战教程(1)基础概念与术语
0 为何学习Kafka
在之前的项目中也用到过Kafka,但都是别人搭好了我只负责用,也没去深究,也没系统学习过。现在我加入了一个新公司,我们会做一个新系统,这个系统的技术架构中选型了Kafka,虽然生产环境我们会有商业技术支持,但我们需要自己搭建开发和测试环境,以及排查一些基本的问题。因此,根据我的习惯,提前系统学习整理一遍用到的技术,很有必要也很有价值。
本篇会聚焦于Kafka的基础概念部分,带你理解Kafka的基本术语。
1 Kafka是什么?
Apache Kafka是一款开源的消息引擎系统。

根据维基百科的定义,消息引擎系统是一组规范。企业利用这组规范在不同系统之间传递语义准确的消息,实现松耦合的异步式数据传递。通俗来讲,就是系统 A 发送消息给消息引擎系统,系统 B 从消息引擎系统中读取 A 发送的消息。
Kafka支持的消息传输模式
消息引擎系统需要设定具体的传输协议,即用什么方法把消息传输出去。常见的方法有两种:
(1)点对点模型消费者主动拉取数据,消息收到后清除消息。

(2)发布/订阅模型
可以有多个topic主题(例如:浏览、点赞、收藏、评论等)
消费者消费数据之后,不删除数据
每个消费者相互独立,都可以消费到数据
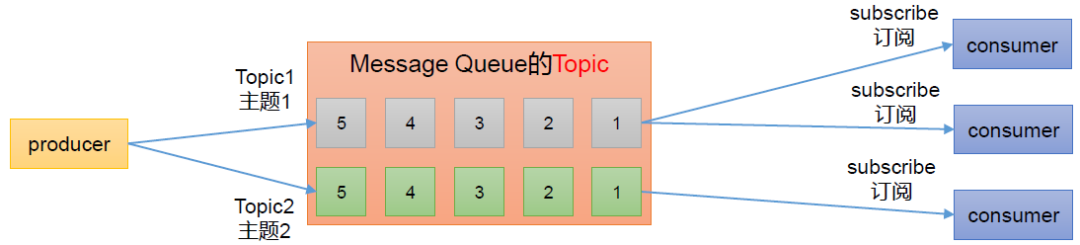
Kafka同时支持这两种消息引擎模型。
Kafka支持的主要应用场景
为什么系统A不能直接发送消息给系统B,还要隔一个消息引擎呢?
答案是:
(1)“削峰填谷”。所谓的“削峰填谷”就是指缓冲上下游瞬时突发流量,使其更平滑。
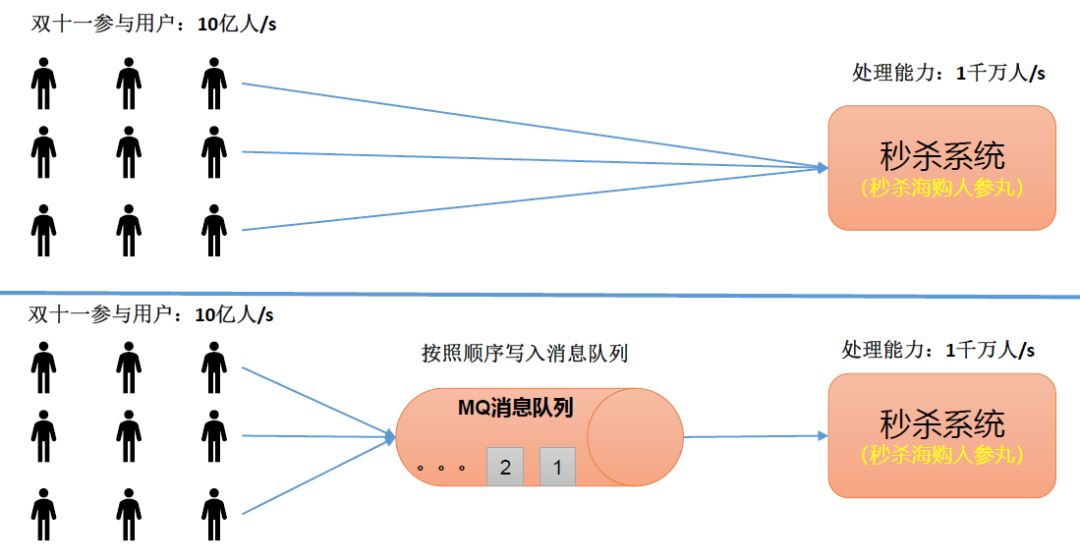
(2)解耦,即允许独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
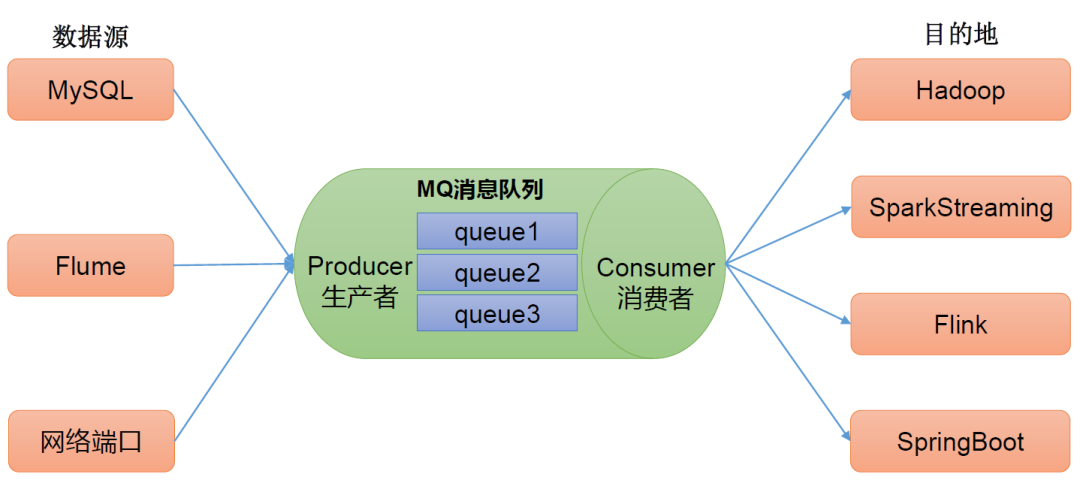
(3)异步通信,即允许把一个消息放入队列,但并不立即处理它们,然后再需要的时候才去处理它们。
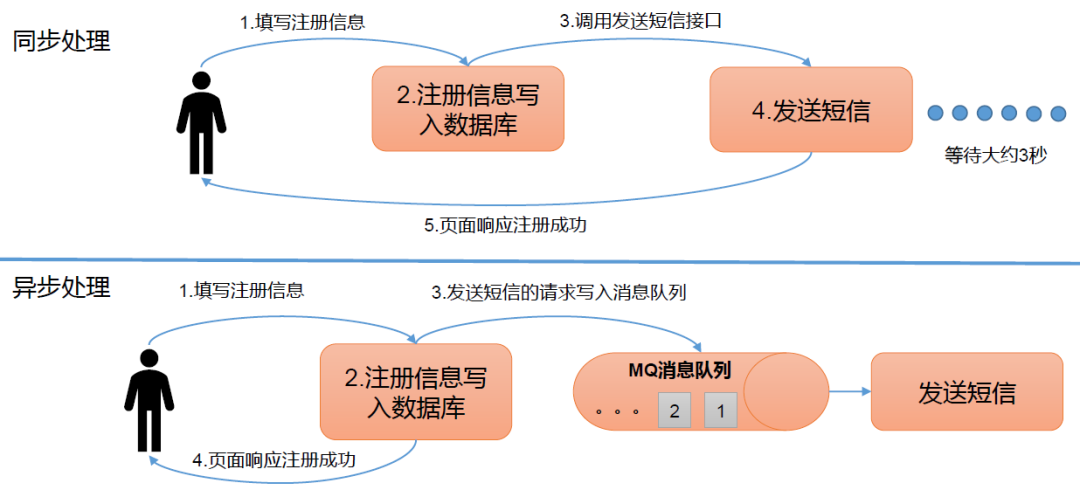
2 Kafka基本术语
一图胜千言,Kafka的基础架构如下图所示:
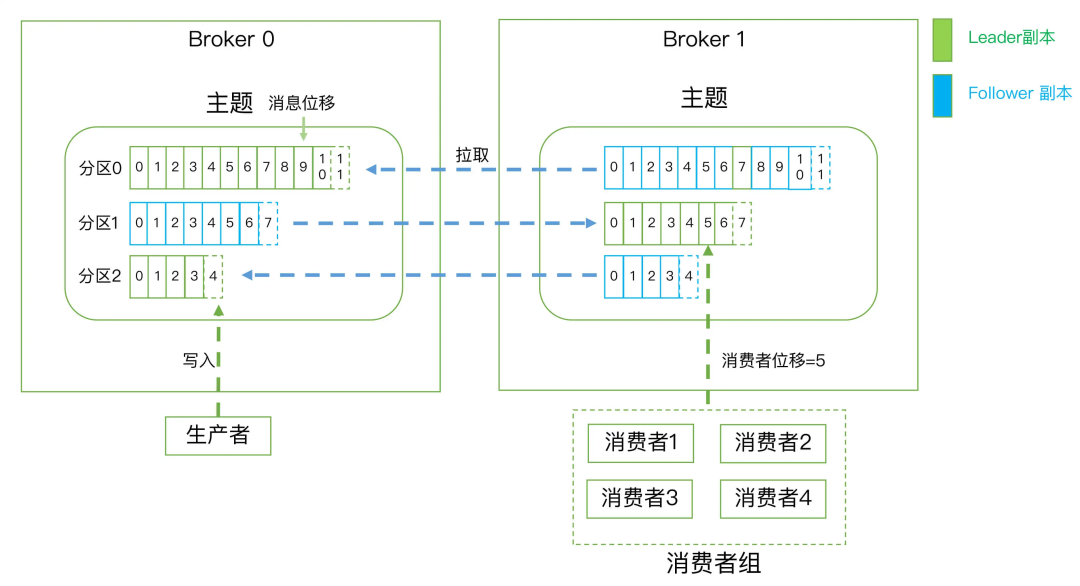
三层消息架构
第一层:主题层
每个主题可以配置M个分区,而每个分区又可以配置多个副本。
第二层:分区层
每个分区的N个副本中只能有一个充当领导者角色,只由领导者对外提供服务;其他N-1个副本是追随者副本,只是提供数据冗余之用。
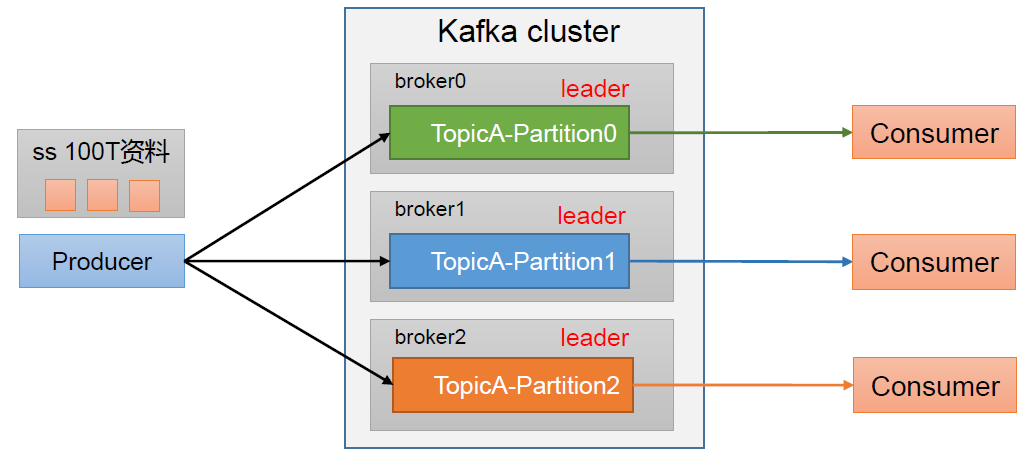
Kafka给topic做partition分区带来的好处:
(1)合理使用存储资源:每个Partition在一个Broker上存储,可以把海量的数据按照分区切割成一块块数据存储在多台Broker上,从而合理控制分区的任务,最终实现负载均衡的效果。
(2)提高并行度:生产者可以按分区为单位发送数据,消费者也可以按分区为单位消费数据。
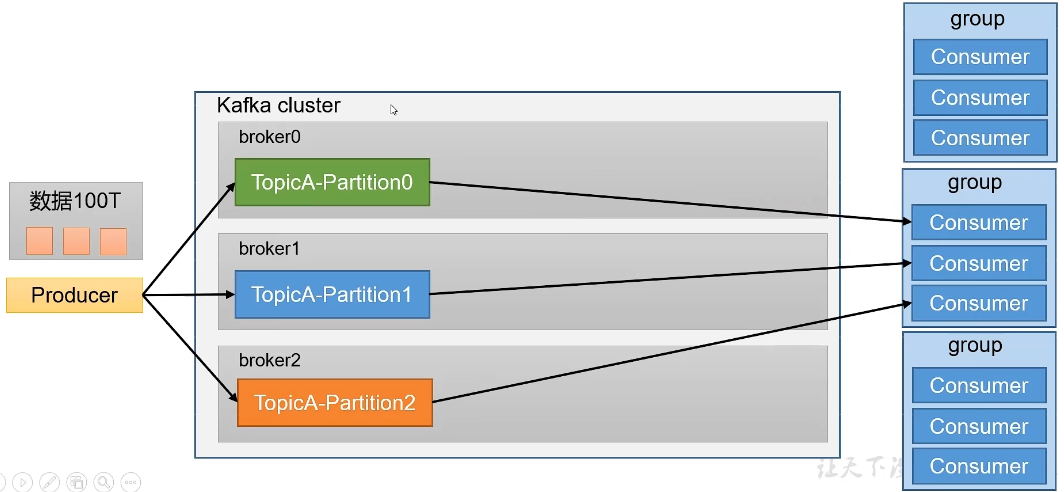
同时,配合partition的设计,Kafka提出了消费组的概念,多个消费者实例共同组成的一个组,组内每个消费者并行消费以实现高吞吐。但需要注意的是,每个partition只会由组内固定的一个消费者进行消费。
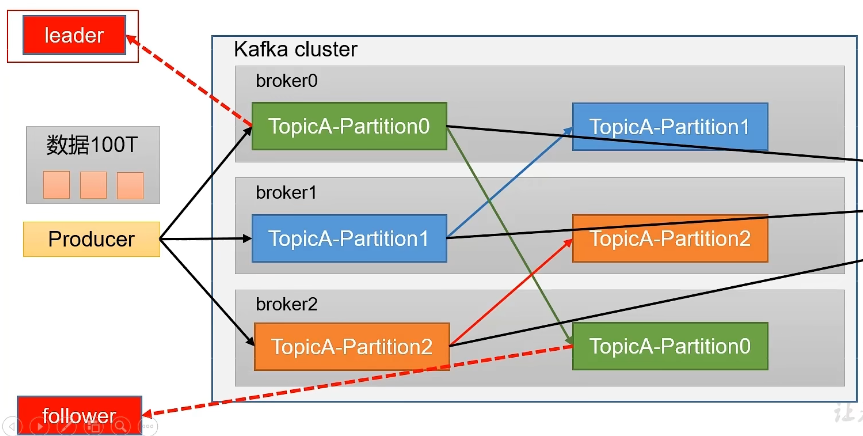
此外,为了提高可用性,Kafka为每个partition增加了若干个副本,类似于MongoDB的复制集Replication,但是和MongoDB不同的就是其副本follower制作冗余,不提供服务。只有等Leader挂掉之后,follower才有机会提供服务。
最后,leader和follower的关系这类元数据存储在了zookeeper中。Kafka 2.8.0以后,也阔以选择配置不采用zookeeper。官方称这项功能为Kafka Raft元数据模式(KRaft)。在KRaft模式,过去由Kafka控制器和ZooKeeper所操作的元数据,将合并到一个新的Quorum控制器,并且在Kafka集群内部执行(拥抱了Raft协议)。
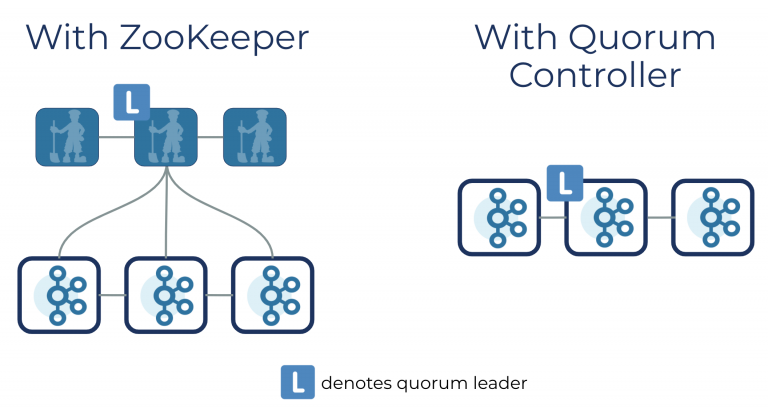
第三层:消息层
分区中包含若干条消息,每条消息的位移从0开始,依次递增。
最后,客户端程序只能与分区的领导者副本进行交互。
具体名词术语
消息:Record。Kafka 是消息引擎嘛,这里的消息就是指 Kafka 处理的主要对象。
主题:Topic。主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。
分区:Partition。一个有序不变的消息序列。每个主题下可以有多个分区。
消息位移:Offset。表示分区中每条消息的位置信息,是一个单调递增且不变的值。
副本:Replica。Kafka 中同一条消息能够被拷贝到多个地方以提供数据冗余,这些地方就是所谓的副本。副本还分为领导者副本和追随者副本,各自有不同的角色划分。副本是在分区层级下的,即每个分区可配置多个副本实现高可用。
生产者:Producer。向主题发布新消息的应用程序。
消费者:Consumer。从主题订阅新消息的应用程序。
消费者位移:Consumer Offset。表征消费者消费进度,每个消费者都有自己的消费者位移。
消费者组:Consumer Group。多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。
重平衡:Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
3 Kafka不只是消息引擎
Apache Kafka 是消息引擎系统,也是一个分布式流处理平台。
Kafka在设计之初就旨在提供三个方面的特性:
(1)提供一套API实现生产者和消费者;
(2)降低网络传输和磁盘存储开销;
(3)实现高伸缩性架构;
开源后的Kafka在承接上下游、串联数据流管道方面发挥了重要的作用,Kafka在0.10.0.0版本正式推出了流处理组件Kafka Streams。今天,Apache Kafka是和 Apache Storm、Apache Spark 和 Apache Flink 同等级的实时流处理平台。
作为流处理平台,Kafka与其他主流大数据流式计算框架相比,其优势在于两点:
(1)更容易实现端到端的正确性
因为所有的数据流转和计算都在 Kafka 内部完成,故 Kafka 可以实现端到端的精确一次处理语义。
(2)它自己对流式计算的定位
Kafka Streams 是一个用于搭建实时流处理的客户端库而非是一个完整的功能系统,适合大量中小企业的业务场景,因为它们并不需要重量级的完整方案。
4 Kafka如何选择
目前市面上Kafka有如下几种:
Apache Kafka
Confluent Kafka
Cloudera/Hortonworks Kafka
Apache Kafka
开发人数最多、版本迭代速度最快的Kafka。如果我们仅仅需要一个消息引擎系统 抑或是 简单的流处理应用场景,同时需要对系统有较大的把控度,那么推荐使用Apache Kafka。
Confluent Kafka
目前分为免费版 和 企业版 两种,企业版提供了很多功能。最有用的当属跨数据中心备份 和 集群监控了。如果我们需要用到Kafka的一些高级特性,那么推荐使用Confluent Kafka。
CDH/HDP Kafka
提供了便捷化的操作界面,友好的监控功能,无需任何配置。如果我们需要快速地搭建消息引擎系统,或者需要搭建的是多框架构成的数据平台 且 Kafka只是其中一个组件,那么推荐使用云公司的Kafka。
5 Kafka的版本号
版本命名

解读kafka_2.11-2.2.1(1)2.11 代表编译 Kafka 源代码的 Scala 编译器版本。(2)2.2.1 是Kafka真正的版本号,它的含义如下:
前面的 2 表示大版本号,即 Major Version;
中间的 2 表示小版本号或次版本号,即 Minor Version;
最后的 1 表示修订版本号,也就是 Patch 号。
Kafka 社区在发布 1.0.0 版本后,宣布 Kafka 版本命名规则正式从 4 位演进到 3 位,比如 0.11.0.0 版本就是 4 位版本号。
版本演进
Kafka 在总共演进了 多 个大版本,分别是 0.7、0.8、0.9、0.10、0.11、1.0、2.x 和 目前的 3.x,其中的小版本和 Patch 版本很多。
Kafka 0.7:只有基础消息队列功能,无副本;
Kafka 0.8:引入了副本机制,Kafka此时成为一个真正意义上完备的分布式高可靠消息队列解决方案;
Kafka 0.9.0.0:增加了基础的安全认证/权限功能;使用Java重写了新版本消费者API;引入了Kafka Connect组件;
Kafka 0.10.0.0:引入了Kafka Streams,正式升级为分布式流处理平台;
Kafka 0.11.0.0:提供了幂等性Producer API以及事务API;对Kafka消息格式做了重构;
Kafka 1.0和2.0:主要还是Kafka Streams的各种改进;
Kafka 2.8:支持不依赖Zookeeper独立运行,基于内嵌的KRaft协议;
Kafka Streams依然在积极的发展,如果要使用Kafka Streams,至少选择2.0.0版本。
每个 Kafka 版本都有它恰当的使用场景和独特的优缺点,切记不要一味追求最新版本,不要成为最新版本的“小白鼠”。
最后建议:不论用的是哪个版本,都尽量保持服务器端版本和客户端版本一致,否则你将损失很多 Kafka 为你提供的性能优化收益。
6 总结
本文总结了Kafka的基本概念和术语,如果只能汇总成一句话,那应该是:Apache Kafka 是消息引擎系统,也是一个分布式流处理平台。
参考资料
极客时间,胡夕《Kafka核心技术与实战》
B站,尚硅谷《Kafka 3.x入门到精通教程》

Kafka入门实战教程(1)基础概念与术语的更多相关文章
- Kafka入门实战教程(7):Kafka Streams
1 关于流处理 流处理平台(Streaming Systems)是处理无限数据集(Unbounded Dataset)的数据处理引擎,而流处理是与批处理(Batch Processing)相对应的.所 ...
- 【Kafka入门】Kafka入门第一篇:基础概念篇
Kafka简介 Kafka是一个消息系统服务框架,它以提交日志的形式存储消息,并且消息的存储是分布式的,为了提供并行性和容错保障,消息的存储是分区冗余形式存在的. Kafka的架构 Kafka中包含以 ...
- 转 Kafka入门经典教程
Kafka入门经典教程 http://www.aboutyun.com/thread-12882-1-1.html 问题导读 1.Kafka独特设计在什么地方?2.Kafka如何搭建及创建topic. ...
- 【UML】NO.70.EBook.9.UML.4.001-【PowerDesigner 16 从入门到精通】- 基础概念
1.0.0 Summary Tittle:[UML]NO.70.EBook.9.UML.4.001-[PowerDesigner 16 从入门到精通]- 基础概念 Style:DesignPatte ...
- 一步步Cobol 400 上手自学入门教程01 - 基础概念
先学习基础概念 1.COBOL字符:包含: User-defined words 用户定义字符 System-names Reserved words 关键字 2.用户定义字符User-defin ...
- excel的宏与VBA入门(一)——基础概念
一.概述 "记录宏"其实就是将工作的一系列操作结果录制下来,并命名存储(相当于VB中一个子程序). 宏其实就是VBA写的,但是可以通过录制的方法制作宏,做好的宏你可以查看相应的VB ...
- Elasticsearch教程之基础概念
基础概念 Elasticsearch有几个核心概念.从一开始理解这些概念会对整个学习过程有莫大的帮助. 1.接近实时(NRT) Elasticsearch是一个接近实时的搜索平台.这意味 ...
- k8s 基础概念和术语
Master k8s里的master指的是集群控制节点,每个k8s集群里需要有一个Master节点来负责整个集群的管理和控制,基本k8s所有控制命令都发给它,它负责整个具体的执行过程,后面执行操作基本 ...
- k8s上的基础概念和术语
kubernetes基本概念和术语 kubeernetes中的大部分概念如Node,Pod,Replication Controller ,Serverce等都可以看作一种“资源对象”,几乎所有的 ...
- ZooKeeper入门实战教程(一)-介绍与核心概念
1.ZooKeeper介绍与核心概念1.1 简介ZooKeeper最为主要的使用场景,是作为分布式系统的分布式协同服务.在学习zookeeper之前,先要对分布式系统的概念有所了解,否则你将完全不知道 ...
随机推荐
- "油猴脚本""篡改猴"领域的一些基本常识
本文简要介绍本人对"油猴脚本","篡改猴"领域的一些见解,内容注定不可能一步到位和事无巨细,欢迎各位仁人志士对我批评指正,提出意见建议.另外转载前请务必注明作者 ...
- 【软件】解决奥林巴斯生物显微镜软件OlyVIA提示“不支持您使用的操作系统”安装中止的问题
[软件]解决奥林巴斯生物显微镜软件OlyVIA提示"不支持您使用的操作系统"安装中止的问题 零.问题 资源在文末 问题如下,从奥林巴斯生物显微镜软件官网下载地址:https://l ...
- vue路由params传参时出现undefined
1.问题: 使用params方式传参时(参数不显示的方式) 获取参数时,参数undefined 2.解决: push时请使用name,不要使用path(路由的params对象使用,必须通过路由名nam ...
- EF Core Day1 ——DbContext初识
------------恢复内容开始------------ EF中的上下文(DbContext)简介 DbContext是实体类和数据库之间的桥梁,DbContext主要负责与数据交互,主要作用 ...
- 『Plotly实战指南』--交互功能基础篇
在数据可视化领域,静态图表早已无法满足用户对深度分析与探索的需求. Plotly作为新一代交互式可视化工具,通过其强大的交互功能重新定义了"数据叙事"的边界. 通过精心设计的交互功 ...
- Rolldown:下一代JavaScript/TypeScript打包工具,基于Rust的JS打包工具-速度贼快
Vue 团队已正式开源 Rolldown 项目,这是一款基于 Rust 的 JavaScript 打包工具. 项目介绍 Rolldown 是使用 Rust 开发的 Rollup.js 编译工具的替代品 ...
- 智表ZCELL产品V2.0发版小感
不知不觉,智表从诞生以来已经两年多了,首先感谢各位用户的支持,没有大家的支持,智表这个产品估计早就已经终止了,正是大家的支持和鼓励,智表才一步一步走到了今天.智表最初是从一个简单不能再简单的table ...
- vue3 基础-Mixin
本篇开始来学习一波 vue 中的一些复用性代码的基础操作, 首先来介绍关于代码 "混入" mixin 的写法. 直观理解这个 mixin 就是一个 js 对象去 "混入& ...
- Python基础 - 多进程(上)
估计很多小伙伴会认为, 类似, 进程, 线程, 协程等这些, 比较专业的词汇, 应该是比较高深的内容, 作为入门基础不太合适. 而, 事实确实如此. 但, 如果不是做研究的, 仅从功能的视角看看待, ...
- 中国科学院计算所:从 NFS 到 JuiceFS,大模型训推平台存储演进之路
中科院计算所在建设大模型训练与推理平台过程中,模型规模与数据集数量呈爆发式增长.最初采用简单的裸机存储方案,但很快面临数据孤岛.重复冗余.管理混乱和资源利用不均等问题,于是升级到了 NFS 系统.然而 ...