JVM垃圾收集器CMS和G1
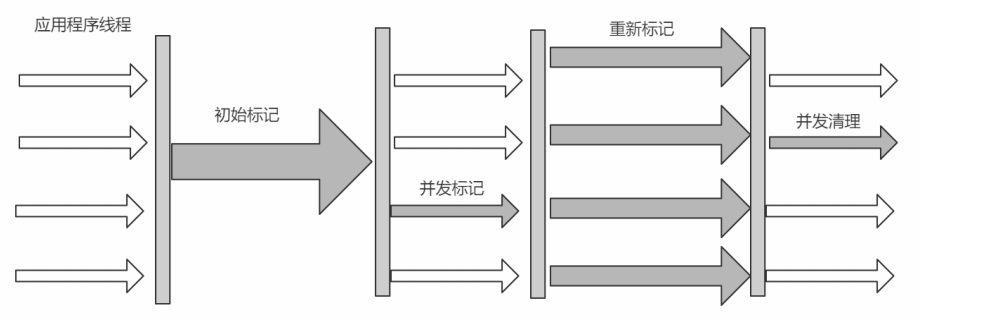
CMS(Concurrent Mark Sweep)收集器是一种以获取 最短回收停顿时间 为目标的收集器。采用的是"标记-清除算法",整个过程分为4步
JVM垃圾收集器CMS和G1的更多相关文章
- 7种JVM垃圾收集器特点,优劣势、及使用场景
今天继续JVM的垃圾回收器详解,如果说垃圾收集算法是JVM内存回收的方法论,那么垃圾收集器就是内存回收的具体实现. 一.常见的垃圾收集器有3类 1.新生代的收集器包括 Serial PraNew Pa ...
- 【006】【JVM——垃圾收集器总结】
Java虚拟机学习总结文件夹 JVM--垃圾收集器总结 垃圾收集器概览 收集算法是内存回收的方法论.垃圾收集据是内存回收的详细实现.Java虚拟机规范中对垃圾收集器应该怎样实现没有规定.不同的厂 ...
- 第五章 JVM垃圾收集器(1)
说明:垃圾回收算法是理论,垃圾收集器是回收算法的实现,关于回收算法,见<第四章 JVM垃圾回收算法> 1.七种垃圾收集器 Serial(串行GC)-- 复制 ParNew(并行GC)-- ...
- 第六章 JVM垃圾收集器(2)
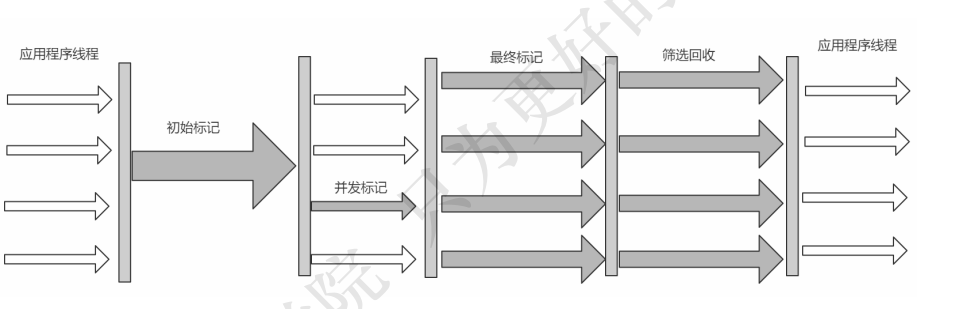
上一章记录了几种常见的垃圾收集器,见<第五章 JVM垃圾收集器(1)> 1.G1 说明: 从上图来看,G1与CMS相比,仅在最后的"筛选回收"部分不同(CMS是并发清除 ...
- JVM垃圾收集器(1)
此文已由作者赵计刚薪授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 说明:垃圾回收算法是理论,垃圾收集器是回收算法的实现,关于回收算法,见<第四章 JVM垃圾回收算法& ...
- 5种JVM垃圾收集器特点和8种JVM内存溢出原因
先来看看5种JVM垃圾收集器特点 一.常见垃圾收集器 现在常见的垃圾收集器有如下几种: 新生代收集器: Serial ParNew Parallel Scavenge 老年代收集器: Serial O ...
- 7种 JVM 垃圾收集器特点、优劣势及使用场景(多图)
7种 JVM 垃圾收集器特点.优劣势及使用场景(多图) mp.weixin.qq.com 点击上方"IT牧场",选择"设为星标"技术干货每日送达! 一.常见垃 ...
- JVM垃圾收集器-Parallel Scavenge收集器
今天我给大家讲讲JVM垃圾收集器-Parallel Scavenge收集器 Parallel Scavenge收集器 Parallel Scavenge收集器也是一个新生代收集器,它也是使用复制算法的 ...
- JVM调优:HotSpot JVM垃圾收集器
HotSpot JVM垃圾收集器 - Snooper - 博客园https://www.cnblogs.com/snooper/p/8718478.html
随机推荐
- Lab8:文件系统
文件系统的概念 文件系统是操作系统中管理持久性数据的子系统,提供数据存储和访问功能 文件是具有符号名,由字节序列构成的数据项集合 文件系统的功能 分配文件磁盘空间 管理文件块(位置和顺序) 管理空闲空 ...
- 优秀的github项目学习
优秀的github项目学习 后期会陆续添加遇到的优秀项目 https://github.com/chaijunkun
- Reverse proxy
Nginx 反向代理配置: upstream dynamic { zone upstream_dynamic 64k; least_conn; ##适用于long connect,即请求处理时间长 # ...
- PostGIS 使用Mysql_fdw同步ArcGIS填坑记录
##实现Mysql_fdw数据同步过程中,出现过很多坑,开此贴记录一下 1.触发器记录 这里insert的时候,采用过insert into f_pressureline select new.*,出 ...
- NN入门,手把手教你用Numpy手撕NN(三)
NN入门,手把手教你用Numpy手撕NN(3) 这是一篇包含极少数学的CNN入门文章 上篇文章中简单介绍了NN的反向传播,并利用反向传播实现了一个简单的NN,在这篇文章中将介绍一下CNN. CNN C ...
- websrom编译器
webstorm less环境配置 备注: 安装node后,在命令行输入npm install -g less 即可安装less,打开webstorm setting-Tools-FileWatche ...
- python核心编程笔记(转)
解释器options: 1.1 –d 提供调试输出 1.2 –O 生成优化的字节码(生成.pyo文件) 1.3 –S 不导入site模块以在启动时查找python路径 1.4 –v 冗 ...
- applicationContext-dao.xml 配置错误
https://www.captainbed.net/ 配置文件报错: 不允许有匹配 "[xX][mM][lL]" 的处理指令目标. 错误原因: 由于大部分都是搬砖,所以格式没注意 ...
- pyspark报错Exception: Java gateway process exited before sending its port number解决方法
1.问题 搭建spark的python环境好后简单使用,源代码如下: 然后就给我丢了一堆错误: 2.解决办法 这里指定一下Java的环境就可以了,添加代码: import os os.environ[ ...
- Nginx服务器部署 负载均衡 反向代理
Nginx服务器部署负载均衡反向代理 LVS Nginx HAProxy的优缺点 三种负载均衡器的优缺点说明如下: LVS的优点: 1.抗负载能力强.工作在第4层仅作分发之用,没有流量的产生,这个特点 ...