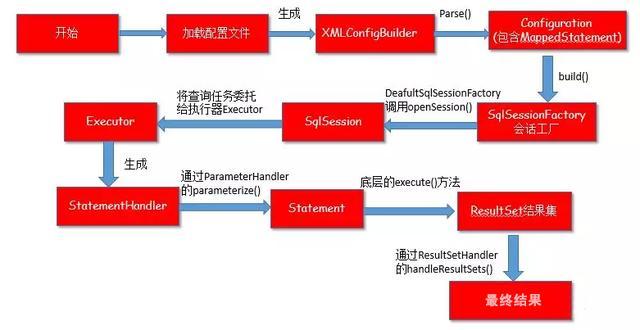
近来想写一个mybatis的分页插件,但是在写插件之前肯定要了解一下mybatis具体的工作原理吧,于是边参考别人的博客,边看源码就开干了。
SqlSession
Executor
StatementHandler
ParameterHandler
ResultSetHandler
TypeHandler
MappedStatement
Configuration
在分析工作原理之前,首先看一下我的mybatis全局配置文件
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <!-- 和spring整合后 environments配置将废除 --> <environments default="development"> <environment id="development"> <!-- 使用jdbc事务管理 --> <transactionManager type="JDBC" /> <!-- 数据库连接池 --> <dataSource type="POOLED"> <property name="driver" value="com.mysql.jdbc.Driver" /> <property name="url" value="jdbc:mysql://localhost:3306/test?characterEncoding=utf-8" /> <property name="username" value="root" /> <property name="password" value="123456" /> </dataSource> </environment> </environments> <mappers> <mapper resource="sqlMapper/userMapper.xml"/> </mappers> </configuration>
第一步:创建一个sqlSessionFactory
在了解如何创建sqlSessionFactory之前,先看一下mybatis是如何加载全局配置文件,解析xml文件生成Configuration的
public Configuration parse() { if (parsed) { throw new BuilderException("Each XMLConfigBuilder can only be used once."); } parsed = true; parseConfiguration(parser.evalNode("/configuration")); return configuration; }
private void parseConfiguration(XNode root) { try { propertiesElement(root.evalNode("properties")); //issue #117 read properties first typeAliasesElement(root.evalNode("typeAliases")); pluginElement(root.evalNode("plugins")); objectFactoryElement(root.evalNode("objectFactory")); objectWrapperFactoryElement(root.evalNode("objectWrapperFactory")); settingsElement(root.evalNode("settings")); environmentsElement(root.evalNode("environments")); // read it after objectFactory and objectWrapperFactory issue #631 databaseIdProviderElement(root.evalNode("databaseIdProvider")); typeHandlerElement(root.evalNode("typeHandlers")); mapperElement(root.evalNode("mappers")); } catch (Exception e) { throw new BuilderException("Error parsing SQL Mapper Configuration. Cause: " + e, e); } }
mapperElement(root.evalNode("mappers"));
刚好我们的全局配置文件中有一个mapper的配置,由此可见,mapperElemet()方法是解析mapper映射文件的,具体代码如下
private void mapperElement(XNode parent) throws Exception { if (parent != null) { for (XNode child : parent.getChildren()) { if ("package".equals(child.getName())) { String mapperPackage = child.getStringAttribute("name"); configuration.addMappers(mapperPackage); } else { String resource = child.getStringAttribute("resource"); String url = child.getStringAttribute("url"); String mapperClass = child.getStringAttribute("class"); if (resource != null && url == null && mapperClass == null) {//进入该判断 ErrorContext.instance().resource(resource); InputStream inputStream = Resources.getResourceAsStream(resource); XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, resource, configuration.getSqlFragments()); mapperParser.parse(); } else if (resource == null && url != null && mapperClass == null) { ErrorContext.instance().resource(url); InputStream inputStream = Resources.getUrlAsStream(url); XMLMapperBuilder mapperParser = new XMLMapperBuilder(inputStream, configuration, url, configuration.getSqlFragments()); mapperParser.parse(); } else if (resource == null && url == null && mapperClass != null) { Class<?> mapperInterface = Resources.classForName(mapperClass); configuration.addMapper(mapperInterface); } else { throw new BuilderException("A mapper element may only specify a url, resource or class, but not more than one."); } } } } }
根据以上代码可以分析,在写mapper映射文件的地址时不仅可以写成resource,还可以写成url和mapperClass的形式,由于我们用的是resource,所以直接进入第一个判断,最后解析mapper映射文件的方法是
private void configurationElement(XNode context) { try { String namespace = context.getStringAttribute("namespace"); if (namespace.equals("")) { throw new BuilderException("Mapper's namespace cannot be empty"); } builderAssistant.setCurrentNamespace(namespace); cacheRefElement(context.evalNode("cache-ref")); cacheElement(context.evalNode("cache")); parameterMapElement(context.evalNodes("/mapper/parameterMap")); resultMapElements(context.evalNodes("/mapper/resultMap")); sqlElement(context.evalNodes("/mapper/sql")); buildStatementFromContext(context.evalNodes("select|insert|update|delete")); } catch (Exception e) { throw new BuilderException("Error parsing Mapper XML. Cause: " + e, e); } }
buildStatementFromContext(context.evalNodes("select|insert|update|delete"));
进入这个方法一层层深究,最后到这里可以知道MappedStatement是由builderAssistant(即MapperBuildAssistant)创建的。
public void parseStatementNode() { ... builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType, fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass, resultSetTypeEnum, flushCache, useCache, resultOrdered, keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets); }
最后进入方法addMappedStatement(),mappedStatement最后以id为键保存在了Configuration中的一个map变量mappedStatements中。
public MappedStatement addMappedStatement( String id, SqlSource sqlSource, StatementType statementType, SqlCommandType sqlCommandType, Integer fetchSize, Integer timeout, String parameterMap, Class<?> parameterType, String resultMap, Class<?> resultType, ResultSetType resultSetType, boolean flushCache, boolean useCache, boolean resultOrdered, KeyGenerator keyGenerator, String keyProperty, String keyColumn, String databaseId, LanguageDriver lang, String resultSets) { if (unresolvedCacheRef) throw new IncompleteElementException("Cache-ref not yet resolved"); id = applyCurrentNamespace(id, false); boolean isSelect = sqlCommandType == SqlCommandType.SELECT; MappedStatement.Builder statementBuilder = new MappedStatement.Builder(configuration, id, sqlSource, sqlCommandType); statementBuilder.resource(resource); statementBuilder.fetchSize(fetchSize); statementBuilder.statementType(statementType); statementBuilder.keyGenerator(keyGenerator); statementBuilder.keyProperty(keyProperty); statementBuilder.keyColumn(keyColumn); statementBuilder.databaseId(databaseId); statementBuilder.lang(lang); statementBuilder.resultOrdered(resultOrdered); statementBuilder.resulSets(resultSets); setStatementTimeout(timeout, statementBuilder); setStatementParameterMap(parameterMap, parameterType, statementBuilder); setStatementResultMap(resultMap, resultType, resultSetType, statementBuilder); setStatementCache(isSelect, flushCache, useCache, currentCache, statementBuilder); MappedStatement statement = statementBuilder.build(); configuration.addMappedStatement(statement); return statement; }
最后回到我们的创建sqlSessionFactory上,之前的一切都是为了生成一个sqlSessionFactory服务的
public SqlSessionFactory build(InputStream inputStream, String environment, Properties properties) { try { XMLConfigBuilder parser = new XMLConfigBuilder(inputStream, environment, properties); return build(parser.parse()); } catch (Exception e) { throw ExceptionFactory.wrapException("Error building SqlSession.", e); } finally { ErrorContext.instance().reset(); try { inputStream.close(); } catch (IOException e) { // Intentionally ignore. Prefer previous error. } } } public SqlSessionFactory build(Configuration config) { return new DefaultSqlSessionFactory(config); }
从上面的代码可以看出最后是通过以Configuration为参数build()方法生成DefautSqlSessionFactory。
第二步:创建sqlSession
public SqlSession openSession() { return openSessionFromDataSource(configuration.getDefaultExecutorType(), null, false); } private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) { Transaction tx = null; try { final Environment environment = configuration.getEnvironment(); final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment); tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit); final Executor executor = configuration.newExecutor(tx, execType); return new DefaultSqlSession(configuration, executor, autoCommit); } catch (Exception e) { closeTransaction(tx); // may have fetched a connection so lets call close() throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e); } finally { ErrorContext.instance().reset(); } } //返回一个SqlSession,默认使用DefaultSqlSession public DefaultSqlSession(Configuration configuration, Executor executor, boolean autoCommit) { this.configuration = configuration; this.executor = executor; this.dirty = false; this.autoCommit = autoCommit; }
executor在这一步得到创建,具体的使用在下一步。
第三步:执行具体的sql请求
User user = sqlSession.selectOne("test.findUserById", 1);
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) { try { //1.根据Statement Id,在mybatis 配置对象Configuration中查找和配置文件相对应的MappedStatement MappedStatement ms = configuration.getMappedStatement(statement); //2. 将查询任务委托给MyBatis 的执行器 Executor List<E> result = executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER); return result; } catch (Exception e) { throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e); } finally { ErrorContext.instance().reset(); } }
在这里通过statementId拿到了我们在第一步存在map里面的MappedStatement。在这里引用参考博客的一句话:
SqlSession根据Statement ID, 在mybatis配置对象Configuration中获取到对应的MappedStatement对象,然后调用mybatis执行器来执行具体的操作。
再继续看query()和queryFromDatabase()这两个方法
@SuppressWarnings("unchecked") public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId()); if (closed) throw new ExecutorException("Executor was closed."); if (queryStack == 0 && ms.isFlushCacheRequired()) { clearLocalCache(); } List<E> list; try { queryStack++; list = resultHandler == null ? (List<E>) localCache.getObject(key) : null; if (list != null) { handleLocallyCachedOutputParameters(ms, key, parameter, boundSql); } else { list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); } } finally { queryStack--; } if (queryStack == 0) { for (DeferredLoad deferredLoad : deferredLoads) { deferredLoad.load(); } deferredLoads.clear(); // issue #601 if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) { clearLocalCache(); // issue #482 } } return list; }
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { List<E> list; localCache.putObject(key, EXECUTION_PLACEHOLDER); try { list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql); } finally { localCache.removeObject(key); } localCache.putObject(key, list); if (ms.getStatementType() == StatementType.CALLABLE) { localOutputParameterCache.putObject(key, parameter); } return list; }
在这两个方法里面会为当前的查询创建一个缓存key,如果缓存中没有值,直接从数据库中读取,执行查询后将得到的list结果放入缓存之中。
紧接着看doQuery()在SimpleExecutor类中重写的方法
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException { Statement stmt = null; try { Configuration configuration = ms.getConfiguration(); StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql); stmt = prepareStatement(handler, ms.getStatementLog()); return handler.<E>query(stmt, resultHandler); } finally { closeStatement(stmt); } }
Statement连接对象就是在这里创建的,因此Executor的作用之一就是创建Statement了,创建完后又把Statement丢给StatementHandler返回List查询结果。
接下来再看一下这里的两个方法prepareStatement()和query()的具体实现
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException { Statement stmt; Connection connection = getConnection(statementLog); stmt = handler.prepare(connection); handler.parameterize(stmt); return stmt; }
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException { PreparedStatement ps = (PreparedStatement) statement; ps.execute(); return resultSetHandler.<E> handleResultSets(ps); }
prepareStatement()是创建Statement的具体实现方法,调用parameterize()对创建的Statement对象设置参数,即为我们设为占位符的地方赋上指定的参数,parameterize()方法再深入进去就是调用ParameterHandler的setParameters()方法具体赋值了。
这里的query()是调用了ResultSetHandler的handleResultSets(Statement) 方法。作用就是把ResultSet结果集对象转换成List类型的集合。
根据具体传入的参数,动态地生成需要执行的SQL语句,用BoundSql对象表示
为当前的查询创建一个缓存Key
缓存中没有值,直接从数据库中读取数据
执行查询,返回List 结果,然后 将查询的结果放入缓存之中
根据既有的参数,创建StatementHandler对象来执行查询操作
将创建Statement传递给StatementHandler对象,调用parameterize()方法赋值
调用StatementHandler.query()方法,返回List结果集
总结
最后
欢迎大家关注我的公众号【程序员追风】,文章都会在里面更新,整理的资料也会放在里面。
- mybatis——mybatis打印sql 接口工作原理
https://blog.csdn.net/Lxinccode/article/details/79218566 接口工作原理: Dao接口即Mapper接口.接口的全限名,就是映射文件中的names ...
- MyBatis工作原理
Mybatis工作原理: 我们的应用程序通过mybatis提供的api,增删改查方法来访问数据库,api底层调用了jdbc ,只不过mybatis对jdbc的封装是不完全封装,里面的sql语句需要我们 ...
- 面试官:你分析过mybatis工作原理吗?
Mybatis工作原理也是面试的一大考点,必须要对其非常清晰,这样才能怼回去.本文建立在Spring+SpringMVC+Mybatis整合的项目之上. 我将其工作原理分为六个部分: 读取核心配置文件 ...
- Hibernate和Mybatis的工作原理以及区别
一.Mybatis的工作流程图 (1).原理详见: MyBatis应用程序根据XML配置文件创建SqlSessionFactory,SqlSessionFactory在根据配置,配置来源于两个地方,一 ...
- 从源码角度分析 MyBatis 工作原理
一.MyBatis 完整示例 这里,我将以一个入门级的示例来演示 MyBatis 是如何工作的. 注:本文后面章节中的原理.源码部分也将基于这个示例来进行讲解.完整示例源码地址 1.1. 数据库准备 ...
- MyBatis 源码分析 - 缓存原理
1.简介 在 Web 应用中,缓存是必不可少的组件.通常我们都会用 Redis 或 memcached 等缓存中间件,拦截大量奔向数据库的请求,减轻数据库压力.作为一个重要的组件,MyBatis 自然 ...
- 【转】MyBatis接口的简单实现原理
MyBatis接口的简单实现原理 用过MyBatis3的人可能会觉得为什么MyBatis的Mapper接口没有实现类,但是可以直接用? 那是因为MyBatis使用Java动态代理实现的接口. 这里仅仅 ...
- MyBatis接口的简单实现原理
MyBatis接口的简单实现原理 用过MyBatis3的人可能会觉得为什么MyBatis的Mapper接口没有实现类,但是可以直接用? 那是因为MyBatis使用Java动态代理实现的接口. 这里仅仅 ...
- 互联网轻量级框架SSM-查缺补漏第七天(MyBatis的解析和运行原理)
第七章MyBatis的解析和运行原理 SqlSessionFactory是MyBatis的核心类之一,其最重要的功能就是提供创建MyBatis的核心借口SqlSession,所以要先创建SqlSess ...
随机推荐
- python:模块1——标准库简介
一.文档 windows系统:IDLE中打开帮助文档 Tutorial:简单入门 Library Reference:python内置函数和标准库(看不完的,当做字典来查)(此外还有pypi(拍派社区 ...
- SpringBoot系列教程Web篇之开启GZIP数据压缩
本篇可以归纳在性能调优篇,虽然内容非常简单,但效果可能出乎预料的好: 分享一个真实案例,我们的服务部署在海外,国内访问时访问服务时,响应有点夸张:某些返回数据比较大的接口,耗时在 600ms+上,然而 ...
- Alibaba Nacos 学习(一):Nacos介绍与安装
Alibaba Nacos 学习(一):Nacos介绍与安装 Alibaba Nacos 学习(二):Spring Cloud Nacos Config Alibaba Nacos 学习(三):Spr ...
- 扛把子组Scrum立会报告+燃尽图 07
此作业要求参见https://edu.cnblogs.com/campus/nenu/2019fall/homework/8684 一.小组情况组长:迟俊文组员:宋晓丽 梁梦瑶 韩昊 刘信鹏队名:扛把 ...
- python3 pip报错 TypeError: 'module' object is not callable
使用命令:python -m pip install xx即可,需要在pip前加python -m
- 2019-9-25:渗透测试,基础学习,初识Hydra,BP爆破密码
一,使用Hydra爆破ubuntu的SSH服务 输入命令,hydra -l root -P password.txt 192.168.20.128 ssh Hydra工具,基本参数说明 -l:指定用户 ...
- ASP.NET Core MVC+EF Core项目实战
项目背景 本项目参考于<Pro Entity Framework Core 2 for ASP.NET Core MVC>一书,项目内容为party邀请答复. 新建项目 本项目开发工具为V ...
- 基于 HTML5 WebGL + VR 的 3D 机房数据中心可视化
前言 在 3D 机房数据中心可视化应用中,随着视频监控联网系统的不断普及和发展, 网络摄像机更多的应用于监控系统中,尤其是高清时代的来临,更加快了网络摄像机的发展和应用. 在监控摄像机数量的不断庞大的 ...
- python接口设计中的__all__和del
最近在实现python接口中遇到了一些小问题,解决后总结如下. 目的:在设计接口时,只暴露某个文件的特定方法. 例如: t.py import os import sys def a(): pass ...
- NTP服务编译安装报错:/usr/bin/ld: cannot find –lcap
[root@localhost local]# find / -name "*libcap.so*" [root@localhost ntp-4.2.8p13]# cd /usr/ ...