python3 TensorFlow训练数据集准备 下载一些百度图片 入门级爬虫示例
从百度图片下载一些图片当做训练集,好久没写爬虫,生疏了。没有任何反爬,随便抓。
网页:
动态加载,往下划会出现更多的图片,一次大概30个。先找到保存每一张图片的json,其对应的url:
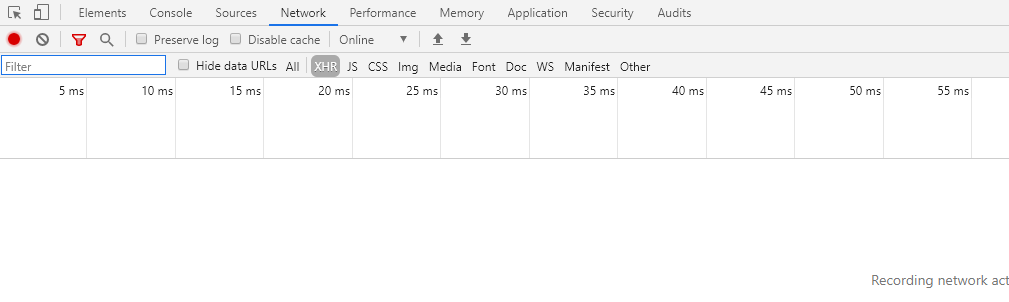
打开调试,清空,然后往下划。然后出现:

点击左侧的链接,出现右边的详细信息,对应的就是URL。对这个url做请求即可。以下是代码:
# -*- coding: utf-8 -*-
# import tensorflow as tf
# import os
# import numpy as np
import requests
import my_fake_useragent as ua
import re
import random # 蓝色背景
def blue_print(*s, end='\n'):
for item in s:
print('\033[46m {} \033[0m'.format(item), end='')
print(end=end) # 高亮,绿色字体,红色背景
def green_print(*s, end='\n'):
# print('\033[1m {} \033[0m'.format(s), end=end)
for item in s:
print('\033[1;32;41m {} \033[0m'.format(item), end='')
print(end=end) class download_data():
def __init__(self):
# 初始化常用参数
# 请求头
self.user_agent = ua.UserAgent()
# 正则用于匹配响应内容中的图片url
self.pattern_url = r'"thumbURL":"(.*?)"' # 爬虫:从网上下载数据集
def get_url_from_internet(self, url):
for i in range(5):
try:
# print(self.user_agent.random())
res = requests.get(url, headers={'User-Agent': self.user_agent.random()}, timeout=5)
# print(res.text)
url_list = re.findall(self.pattern_url, res.text)
# print(url_list)
return url_list
except:
pass # 这里可以将请求失败的url存入数据库,防止数据丢失
return None def write_img(self, url):
for i in range(3):
try:
# 真正下载图片数据的,就这两行代码
res = requests.get(url, headers={'User-Agent': self.user_agent.random()}, timeout=5)
img = res.content
# print(img) # 将响应内容写入本地*.jpg文件中
with open('dataset/monkey{}.jpg'.format(random.randint(10 ** 8, 10 ** 9)), 'wb') as f:
f.write(img)
print('monkey{} 下载完成'.format(random.randint(10 ** 8, 10 ** 9)))
return
except:
pass # 这里可以将请求失败的url存入数据库,防止数据丢失
return None if __name__ == '__main__':
tt = download_data()
for page in range(0, 1000, 30):
# 构造url,设置range的右边界越大,下载的图片就越多
url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result\
&queryWord=%E7%8C%B4%E5%AD%90+%E5%9B%BE%E7%89%87&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=\
&hd=&latest=©right=&word=%E7%8C%B4%E5%AD%90+%E5%9B%BE%E7%89%87&s=&se=&tab=&width=&height=&face=\
&istype=&qc=&nc=&fr=&expermode=&force=&pn={}&rn=30&gsm=&1572502599384='.format(page)
url_list = tt.get_url_from_internet(url)
if url_list:
for each_url in url_list:
tt.write_img(each_url)
什么都不打印看着不舒服,随便打印一些结果出来:
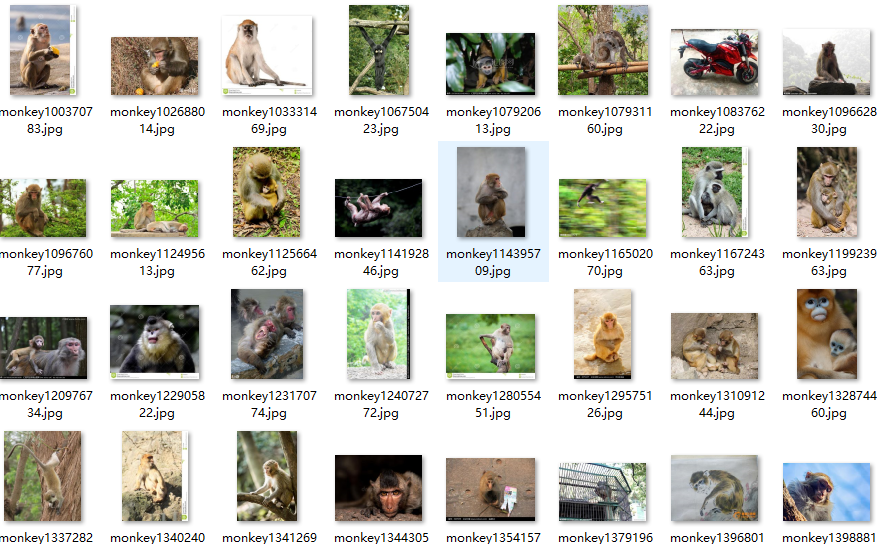
文件夹:
用网上的图片作训练集,而且还是自己抓的,效果估计不会太好。先用着看。自己手动将质量差的图片删一删。
11-19
有时候会遇到一点点反爬,响应码403,在headers中添加 "referer": "https://image.baidu.com"即可
python3 TensorFlow训练数据集准备 下载一些百度图片 入门级爬虫示例的更多相关文章
- 百度图片爬虫-python版-如何爬取百度图片?
上一篇我写了如何爬取百度网盘的爬虫,在这里还是重温一下,把链接附上: http://www.cnblogs.com/huangxie/p/5473273.html 这一篇我想写写如何爬取百度图片的爬虫 ...
- TensorFlow训练MNIST数据集(1) —— softmax 单层神经网络
1.MNIST数据集简介 首先通过下面两行代码获取到TensorFlow内置的MNIST数据集: from tensorflow.examples.tutorials.mnist import inp ...
- Tensorflow 2 flower_photos花卉数据集手动下载、离线安装、本地加载、快速读取
Tensorflow 2 flower_photos花卉数据集手动下载.离线安装.本地加载.快速读取 商务合作,科技咨询,版权转让:向日葵,135-4855__4328,xiexiaokui#qq.c ...
- Tensorflow 2 Cifar10离线数据集手动下载、离线安装、本地加载、快速读取
Tensorflow 2 Cifar10离线数据集手动下载.离线安装.本地加载.快速读取 商务合作,科技咨询,版权转让:向日葵,135-4855__4328,xiexiaokui#qq.com 查 ...
- 利用tensorflow训练简单的生成对抗网络GAN
对抗网络是14年Goodfellow Ian在论文Generative Adversarial Nets中提出来的. 原理方面,对抗网络可以简单归纳为一个生成器(generator)和一个判断器(di ...
- 2、TensorFlow训练MNIST
装载自:http://www.tensorfly.cn/tfdoc/tutorials/mnist_beginners.html TensorFlow训练MNIST 这个教程的目标读者是对机器学习和T ...
- Tensorflow MNIST 数据集测试代码入门
本系列文章由 @yhl_leo 出品,转载请注明出处. 文章链接: http://blog.csdn.net/yhl_leo/article/details/50614444 测试代码已上传至GitH ...
- Tensorflow MNIST 数据集測试代码入门
本系列文章由 @yhl_leo 出品,转载请注明出处. 文章链接: http://blog.csdn.net/yhl_leo/article/details/50614444 測试代码已上传至GitH ...
- TensorFlow.训练_资料(有视频)
ZC:自己训练 的文章 貌似 能度娘出来很多,得 自己弄过才知道哪些个是坑 哪些个好用...(在CSDN文章的右侧 也有列出很多相关的文章链接)(貌似 度娘的关键字是"TensorFlow ...
随机推荐
- 基于Win服务的标签打印(模板套打)
最近做了几个项目,都有在产品贴标的需求 基本就是有个证卡类打印机,然后把产品的信息打印在标签上. 然后通过机器人把标签贴到产品上面 标签信息包括文本,二维码,条形码之类的,要根据对应的数据生成二维码, ...
- 鲲鹏云实验-.NET Core 3.0-开始使用
[摘要] 介绍Ubuntu 18.04环境下.NET Core 3.0的安装配置.初始项目的生成和运行 1. 基础环境 2vCPUs | 4GB | kc1.large.2 Ubuntu 18.04 ...
- 大型情感剧集Selenium:9_selenium配合Pillow完成浏览器局部截图
网页截图 上次提到了selenium的四种截图方法,最终截图了整张网页.但很多时候,我们仅仅需要截图部分的内容.比如截取某个关键信息,或者现在已经不常见的截图验证码(现在都是各种按规则点击-).那么我 ...
- iOS面试的算法相关
转自:https://www.jianshu.com/p/c4820b159159 面试中遇到的这些算法,在平常工作中,基本不会用到. 不过现实的面试中经常喜欢问关于算法的问题 有些还要求写出代码.一 ...
- jQuery中操作页面的文本和值
主要是区分俩种方法: 1.html():可以识别HTML文件,将里面内容全部打印(操作双标签) 2.text():只是将里面的内容打印出来,不能识别HTML格式(操作双标签) <!DOCTYPE ...
- Spring Boot 搭建TCP Server
本示例首选介绍Java原生API实现BIO通信,然后进阶实现NIO通信,最后利用Netty实现NIO通信及Netty主要模块组件介绍. Netty 是一个异步事件驱动的网络应用程序框架,用于快速开发可 ...
- HDU5343 MZL's Circle Zhou(SAM+记忆化搜索)
Problem Description MZL's Circle Zhou is good at solving some counting problems. One day, he comes u ...
- BZOJ 1003[ZJOI2006]物流运输(SPFA+DP)
Problem 1003. -- [ZJOI2006]物流运输 1003: [ZJOI2006]物流运输 Time Limit: 10 Sec Memory Limit: 162 MBSubmit: ...
- 强化学习一:Introduction Of Reinforcement Learning
引言: 最近和实验室的老师做项目要用到强化学习的有关内容,就开始学习强化学习的相关内容了.也不想让自己学习的内容荒废掉,所以想在博客里面记载下来,方便后面复习,也方便和大家交流. 一.强化学习是什么? ...
- (全国多校重现赛一)F-Senior Pan
Senior Pan fails in his discrete math exam again. So he asks Master ZKC to give him graph theory pro ...