netty解决粘包半包问题
前言:开发者用到TCP/IP交互时,偶尔会遇到粘包或者半包的数据,这种情况有时会对我们的程序造成严重的影响,netty框架为解决这种问题提供了若干框架
1. LineBasedFrameDecoder:通过在包尾添加回车换行符 \r\n 来区分整包消息。
说明:LineBasedFrameDecoder 是从 ByteBuf 的可读字节中找到 \n 或者 \r\n,找到之后就以此为结束,然后将当前读取到的数据组成一行。
使用方法:ch.pipline().addLast(new LineBasedFrameDecoder(1024));//1024是设置每一行的最大长度,如果读到最大长度还没有结束符,会抛出异常,结束当前读取到的数据
2. DelimiterBasedFrameDecoder:通过特殊字符作为分隔符来区分整包消息
说明:客户端和服务端协议中有一致的特殊字符,来代表每一包的结束
如:客户端发送3条消息:"你好你好你好$_"
"hellohellohello$_"
"赞赞$_"
服务端为了防止分包粘包,使用方法如下:
ByteBuf delimiter = Unpooled.copiedBuffer("$_".getBytes());
ch.pipline().addLast(new DelimiterBasedFrameDecoder(1024, delimiter));//1024设置每一行的最大长度ch.pipline().addLast(new FixedLengthFrameDecoder(1024));那就介绍一种科一解决不定长协议的分包粘包方法:LengthFieldBasedFrameDecoder
先看一下LengthFieldBasedFrameDecoder源码中一个构造函数:
public LengthFieldBasedFrameDecoder(
int maxFrameLength,
int lengthFieldOffset, int lengthFieldLength,
int lengthAdjustment, int initialBytesToStrip) {
this(
maxFrameLength,
lengthFieldOffset, lengthFieldLength, lengthAdjustment,
initialBytesToStrip, true);
}
其中有5个参数的定义我用一个协议数据举例

maxFrameLength:单个包的最大长度,根据实际环境定义
lengthFieldOffset:表示数据长度字段开始的偏移量,上图中,表示数据长度的字段前边还有协议头、版本号、日期等字段,一共占了12字节,所以按照这个协议,这个参数填写12 lengthFieldOffset:数据长度字段所占的字节数,上图中协议长度占用2个字节,这个参数写2
lengthAdjustment:lengthAdjustment +数据长度取值 = 数据长度字段之后剩下包的字节数,上图中,除了协议长度和数据内容,后边还有协议尾和CRC认证,占用6个字节,这个参数写6
initialBytesToStrip:从整个包开始,向后忽略的字节数(我写成0)
按照以上协议,我的使用方法就是:ch.pipeline().addLast(new LengthFieldBasedFrameDecoder(1024,12,2,6,0));
这句代码加在自定义Hander的前边,否则无效。这样就解决了粘包和分包的问题
但是我现在遇见的问题是:我的协议数据长度字段和数据内容实际长度可能是不对应的
我的协议是如果长度字段不是8的倍数,要在数据后补0 ,例如:
协议长度字段是0046 46不是8的倍数 要补两个0 所以导致以上所有方法都不适合我,因为我不知道长度究竟会是几,究竟会补几个0,于是我自定义LengthFieldBasedFrameDecoder解决这个问题
源码中LengthFieldBasedFrameDecoder继承的是ByteToMessageDecoder(以上所有方法都是继承这个类)
解决方案:自己创建一个类,继承ByteToMessageDecoder,将LengthFieldBasedFrameDecoder
public class SelfDefineEncodeHandler extends ByteToMessageDecoder {
private final ByteOrder byteOrder;
private final int maxFrameLength;
private final int lengthFieldOffset;
private final int lengthFieldLength;
private final int lengthFieldEndOffset;
private final int lengthAdjustment;
private final int initialBytesToStrip;
private final boolean failFast;
private boolean discardingTooLongFrame;
private long tooLongFrameLength;
private long bytesToDiscard;
/**
* Creates a new instance.
*
* @param maxFrameLength
* the maximum length of the frame. If the length of the frame is
* greater than this value, {@link TooLongFrameException} will be
* thrown.
* @param lengthFieldOffset
* the offset of the length field
* @param lengthFieldLength
* the length of the length field
*/
public SelfDefineEncodeHandler(
int maxFrameLength,
int lengthFieldOffset, int lengthFieldLength) {
this(maxFrameLength, lengthFieldOffset, lengthFieldLength, 0, 0);
}
/**
* Creates a new instance.
*
* @param maxFrameLength
* the maximum length of the frame. If the length of the frame is
* greater than this value, {@link TooLongFrameException} will be
* thrown.
* @param lengthFieldOffset
* the offset of the length field
* @param lengthFieldLength
* the length of the length field
* @param lengthAdjustment
* the compensation value to add to the value of the length field
* @param initialBytesToStrip
* the number of first bytes to strip out from the decoded frame
*/
public SelfDefineEncodeHandler(
int maxFrameLength,
int lengthFieldOffset, int lengthFieldLength,
int lengthAdjustment, int initialBytesToStrip) {
this(
maxFrameLength,
lengthFieldOffset, lengthFieldLength, lengthAdjustment,
initialBytesToStrip, true);
}
/**
* Creates a new instance.
*
* @param maxFrameLength
* the maximum length of the frame. If the length of the frame is
* greater than this value, {@link TooLongFrameException} will be
* thrown.
* @param lengthFieldOffset
* the offset of the length field
* @param lengthFieldLength
* the length of the length field
* @param lengthAdjustment
* the compensation value to add to the value of the length field
* @param initialBytesToStrip
* the number of first bytes to strip out from the decoded frame
* @param failFast
* If <tt>true</tt>, a {@link TooLongFrameException} is thrown as
* soon as the decoder notices the length of the frame will exceed
* <tt>maxFrameLength</tt> regardless of whether the entire frame
* has been read. If <tt>false</tt>, a {@link TooLongFrameException}
* is thrown after the entire frame that exceeds <tt>maxFrameLength</tt>
* has been read.
*/
public SelfDefineEncodeHandler(
int maxFrameLength, int lengthFieldOffset, int lengthFieldLength,
int lengthAdjustment, int initialBytesToStrip, boolean failFast) {
this(
ByteOrder.BIG_ENDIAN, maxFrameLength, lengthFieldOffset, lengthFieldLength,
lengthAdjustment, initialBytesToStrip, failFast);
}
/**
* Creates a new instance.
*
* @param byteOrder
* the {@link ByteOrder} of the length field
* @param maxFrameLength
* the maximum length of the frame. If the length of the frame is
* greater than this value, {@link TooLongFrameException} will be
* thrown.
* @param lengthFieldOffset
* the offset of the length field
* @param lengthFieldLength
* the length of the length field
* @param lengthAdjustment
* the compensation value to add to the value of the length field
* @param initialBytesToStrip
* the number of first bytes to strip out from the decoded frame
* @param failFast
* If <tt>true</tt>, a {@link TooLongFrameException} is thrown as
* soon as the decoder notices the length of the frame will exceed
* <tt>maxFrameLength</tt> regardless of whether the entire frame
* has been read. If <tt>false</tt>, a {@link TooLongFrameException}
* is thrown after the entire frame that exceeds <tt>maxFrameLength</tt>
* has been read.
*/
public SelfDefineEncodeHandler(
ByteOrder byteOrder, int maxFrameLength, int lengthFieldOffset, int lengthFieldLength,
int lengthAdjustment, int initialBytesToStrip, boolean failFast) {
if (byteOrder == null) {
throw new NullPointerException("byteOrder");
}
if (maxFrameLength <= 0) {
throw new IllegalArgumentException(
"maxFrameLength must be a positive integer: " +
maxFrameLength);
}
if (lengthFieldOffset < 0) {
throw new IllegalArgumentException(
"lengthFieldOffset must be a non-negative integer: " +
lengthFieldOffset);
}
if (initialBytesToStrip < 0) {
throw new IllegalArgumentException(
"initialBytesToStrip must be a non-negative integer: " +
initialBytesToStrip);
}
if (lengthFieldOffset > maxFrameLength - lengthFieldLength) {
throw new IllegalArgumentException(
"maxFrameLength (" + maxFrameLength + ") " +
"must be equal to or greater than " +
"lengthFieldOffset (" + lengthFieldOffset + ") + " +
"lengthFieldLength (" + lengthFieldLength + ").");
}
this.byteOrder = byteOrder;
this.maxFrameLength = maxFrameLength;
this.lengthFieldOffset = lengthFieldOffset;
this.lengthFieldLength = lengthFieldLength;
this.lengthAdjustment = lengthAdjustment;
lengthFieldEndOffset = lengthFieldOffset + lengthFieldLength;
this.initialBytesToStrip = initialBytesToStrip;
this.failFast = failFast;
}
@Override
protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
Object decoded = decode(ctx, in);
if (decoded != null) {
out.add(decoded);
}
}
/**
* Create a frame out of the {@link ByteBuf} and return it.
*
* @param ctx the {@link ChannelHandlerContext} which this {@link ByteToMessageDecoder} belongs to
* @param in the {@link ByteBuf} from which to read data
* @return frame the {@link ByteBuf} which represent the frame or {@code null} if no frame could
* be created.
*/
protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception {
if (discardingTooLongFrame) {
long bytesToDiscard = this.bytesToDiscard;
int localBytesToDiscard = (int) Math.min(bytesToDiscard, in.readableBytes());
in.skipBytes(localBytesToDiscard);
bytesToDiscard -= localBytesToDiscard;
this.bytesToDiscard = bytesToDiscard;
failIfNecessary(false);
}
if (in.readableBytes() < lengthFieldEndOffset) {
return null;
}
int actualLengthFieldOffset = in.readerIndex() + lengthFieldOffset;
long frameLength = getUnadjustedFrameLength(in, actualLengthFieldOffset, lengthFieldLength, byteOrder);
System.out.println("---------------"+frameLength);
if (frameLength < 0) {
in.skipBytes(lengthFieldEndOffset);
throw new CorruptedFrameException(
"negative pre-adjustment length field: " + frameLength);
}
frameLength += lengthAdjustment + lengthFieldEndOffset;
if (frameLength < lengthFieldEndOffset) {
in.skipBytes(lengthFieldEndOffset);
throw new CorruptedFrameException(
"Adjusted frame length (" + frameLength + ") is less " +
"than lengthFieldEndOffset: " + lengthFieldEndOffset);
}
if (frameLength > maxFrameLength) {
long discard = frameLength - in.readableBytes();
tooLongFrameLength = frameLength;
if (discard < 0) {
// buffer contains more bytes then the frameLength so we can discard all now
in.skipBytes((int) frameLength);
} else {
// Enter the discard mode and discard everything received so far.
discardingTooLongFrame = true;
bytesToDiscard = discard;
in.skipBytes(in.readableBytes());
}
failIfNecessary(true);
return null;
}
// never overflows because it's less than maxFrameLength
int frameLengthInt = (int) frameLength;
if (in.readableBytes() < frameLengthInt) {
return null;
}
if (initialBytesToStrip > frameLengthInt) {
in.skipBytes(frameLengthInt);
throw new CorruptedFrameException(
"Adjusted frame length (" + frameLength + ") is less " +
"than initialBytesToStrip: " + initialBytesToStrip);
}
in.skipBytes(initialBytesToStrip);
// extract frame
int readerIndex = in.readerIndex();
int actualFrameLength = frameLengthInt - initialBytesToStrip;
ByteBuf frame = extractFrame(ctx, in, readerIndex, actualFrameLength);
in.readerIndex(readerIndex + actualFrameLength);
return frame;
}
/**
* Decodes the specified region of the buffer into an unadjusted frame length. The default implementation is
* capable of decoding the specified region into an unsigned 8/16/24/32/64 bit integer. Override this method to
* decode the length field encoded differently. Note that this method must not modify the state of the specified
* buffer (e.g. {@code readerIndex}, {@code writerIndex}, and the content of the buffer.)
*
* @throws DecoderException if failed to decode the specified region
*/
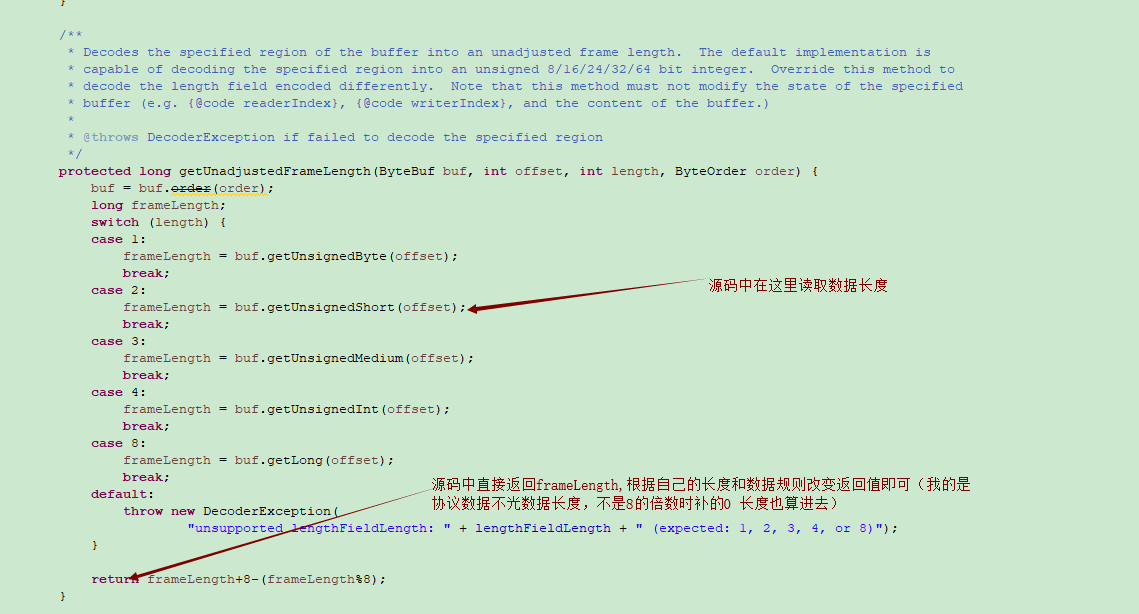
protected long getUnadjustedFrameLength(ByteBuf buf, int offset, int length, ByteOrder order) {
buf = buf.order(order);
long frameLength;
switch (length) {
case 1:
frameLength = buf.getUnsignedByte(offset);
break;
case 2:
frameLength = buf.getUnsignedShort(offset);
break;
case 3:
frameLength = buf.getUnsignedMedium(offset);
break;
case 4:
frameLength = buf.getUnsignedInt(offset);
break;
case 8:
frameLength = buf.getLong(offset);
break;
default:
throw new DecoderException(
"unsupported lengthFieldLength: " + lengthFieldLength + " (expected: 1, 2, 3, 4, or 8)");
}
return frameLength+8-(frameLength%8);
}
private void failIfNecessary(boolean firstDetectionOfTooLongFrame) {
if (bytesToDiscard == 0) {
// Reset to the initial state and tell the handlers that
// the frame was too large.
long tooLongFrameLength = this.tooLongFrameLength;
this.tooLongFrameLength = 0;
discardingTooLongFrame = false;
if (!failFast ||
failFast && firstDetectionOfTooLongFrame) {
fail(tooLongFrameLength);
}
} else {
// Keep discarding and notify handlers if necessary.
if (failFast && firstDetectionOfTooLongFrame) {
fail(tooLongFrameLength);
}
}
}
/**
* Extract the sub-region of the specified buffer.
* <p>
* If you are sure that the frame and its content are not accessed after
* the current {@link #decode(ChannelHandlerContext, ByteBuf)}
* call returns, you can even avoid memory copy by returning the sliced
* sub-region (i.e. <tt>return buffer.slice(index, length)</tt>).
* It's often useful when you convert the extracted frame into an object.
* Refer to the source code of {@link ObjectDecoder} to see how this method
* is overridden to avoid memory copy.
*/
protected ByteBuf extractFrame(ChannelHandlerContext ctx, ByteBuf buffer, int index, int length) {
return buffer.retainedSlice(index, length);
}
private void fail(long frameLength) {
if (frameLength > 0) {
throw new TooLongFrameException(
"Adjusted frame length exceeds " + maxFrameLength +
": " + frameLength + " - discarded");
} else {
throw new TooLongFrameException(
"Adjusted frame length exceeds " + maxFrameLength +
" - discarding");
}
}
}
备忘,参考文章:http://linkedkeeper.com/detail/blog.action?bid=105 里面介绍了更多netty解决粘包分包的方法
netty解决粘包半包问题的更多相关文章
- Netty 粘包/半包原理与拆包实战
Java NIO 粘包 拆包 (实战) - 史上最全解读 - 疯狂创客圈 - 博客园 https://www.cnblogs.com/crazymakercircle/p/9941658.html 本 ...
- Netty入门系列(2) --使用Netty解决粘包和拆包问题
前言 上一篇我们介绍了如果使用Netty来开发一个简单的服务端和客户端,接下来我们来讨论如何使用解码器来解决TCP的粘包和拆包问题 TCP为什么会粘包/拆包 我们知道,TCP是以一种流的方式来进行网络 ...
- Http 调用netty 服务,服务调用客户端,伪同步响应.ProtoBuf 解决粘包,半包问题.
实际情况是: 公司需要开发一个接口给新产品使用,需求如下 1.有一款硬件设备,客户用usb接上电脑就可以,但是此设备功能比较单一,所以开发一个服务器程序,辅助此设备业务功能 2.解决方案,使用Sock ...
- Netty解决粘包和拆包问题的四种方案
在RPC框架中,粘包和拆包问题是必须解决一个问题,因为RPC框架中,各个微服务相互之间都是维系了一个TCP长连接,比如dubbo就是一个全双工的长连接.由于微服务往对方发送信息的时候,所有的请求都是使 ...
- netty 解决粘包拆包问题
netty server TimeServer package com.zhaowb.netty.ch4_3; import io.netty.bootstrap.ServerBootstrap; i ...
- netty: 解决粘包拆包: 分隔符DelimiterBasedFrameDecoder,定长消息FixedLengthFrameDecoder
DelimiterBasedFrameDecoder 自定义分隔符 给Server发送多条信息,但是server会讲多条信息合并为一条.这时候我们需要对发生的消息指定分割,让client和server ...
- socket编程 TCP 粘包和半包 的问题及解决办法
一般在socket处理大数据量传输的时候会产生粘包和半包问题,有的时候tcp为了提高效率会缓冲N个包后再一起发出去,这个与缓存和网络有关系. 粘包 为x.5个包 半包 为0.5个包 由于网络原因 一次 ...
- Netty - 粘包和半包(上)
在网络传输中,粘包和半包应该是最常出现的问题,作为 Java 中最常使用的 NIO 网络框架 Netty,它又是如何解决的呢?今天就让我们来看看. 定义 TCP 传输中,客户端发送数据,实际是把数据写 ...
- c# socket 解决粘包,半包
处理原理: 半包:即一条消息底层分几次发送,先有个头包读取整条消息的长度,当不满足长度时,将消息临时缓存起来,直到满足长度再解码 粘包:两条完整/不完整消息粘在一起,一般是解码完上一条消息,然后再判断 ...
随机推荐
- flutter最简单轻量便捷的路由管理方案NavRouter
大家好,我是CrazyQ1,今天给大家推荐一个路由管理方案,用的非常不错的,叫nav_router. 项目地址是:https://github.com/fluttercandies/nav_route ...
- centos使用yum存储快速安装MySQL
RHEL/CentOS 7.x MySQL yum库 https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm RHEL ...
- Spring Cloud第五篇 | 服务熔断Hystrix
本文是Spring Cloud专栏的第五篇文章,了解前四篇文章内容有助于更好的理解本文: Spring Cloud第一篇 | Spring Cloud前言及其常用组件介绍概览 Spring Clo ...
- javascript类数组
一.类数组定义: 而对于一个普通的对象来说,如果它的所有property名均为正整数,同时也有相应的length属性,那么虽然该对象并不是由Array构造函数所创建的,它依然呈现出数组的行为,在这种情 ...
- [TimLinux] Python 修改进程显示出的标题
1. 安装依赖 https://github.com/timscm/py-setproctitle/archive/version-1.1.10.tar.gz 2. 启动进程 import timei ...
- 2017 CCPC秦皇岛 G题 Numbers
DreamGrid has a nonnegative integer . He would like to divide into nonnegative integers and minimi ...
- Vue中使用iconfont
学习博客:https://www.imooc.com/article/33597?block_id=tuijian_wz
- java面试题干货51-95
51.类ExampleA继承Exception,类ExampleB继承ExampleA. 有如下代码片断: try { throw new ExampleB("b") } catc ...
- 自建邮件服务器域名解析设置(A与MX记录)
自建邮件服务器域名解析设置(A与MX记录) 前言 如果域名没有做解析,只能用于内网收发邮件.要想实现与外网邮箱的收发,需要做域名解析.是在"域名解析后台"进行设置(域名提供商提供& ...
- 如何下载Vimeo视频
MediaHuman YouTube Downloader是应用在Mac上的一款非常优秀的YouTube视频下载工具,YouTube Downloader破解版将帮助你快速完成视频下载,而不会挂断.您 ...