[Hadoop]浅谈MapReduce原理及执行流程
MapReduce
- MapReduce原理非常重要,hive与spark都是基于MR原理
- MapReduce采用多进程,方便对每个任务资源控制和调配,但是进程消耗更多的启动时间,因此MR时效性不高。适合批量,高吞吐的数据处理。Spark采用的是多线程模型。
MapReduce执行流程
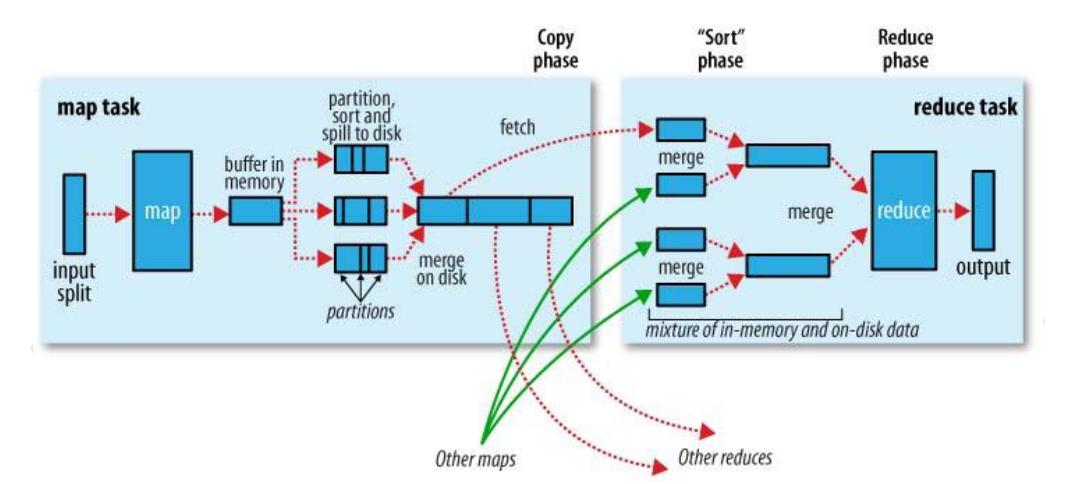
Map过程
- map函数开始产生输出时,并不是直接将数据写到磁盘,它利用缓冲的方式写到内存。每个map任务都有一个环形内存缓冲区用于存储任务输出。在默认情况下,缓冲区大小为100MB。一旦缓冲内容达到阈值(默认80%),便把数据溢出(spill)到磁盘。
Partition过程
- 在map输出数据写入磁盘之前,线程首先根据数据最终要传的reducer把数据划分成相应的分区,这个过程即为partition。
传统hash算法
- hash()%max 括号内随机取数,这样会随机分配到1-max服务器上
一致性hash算法
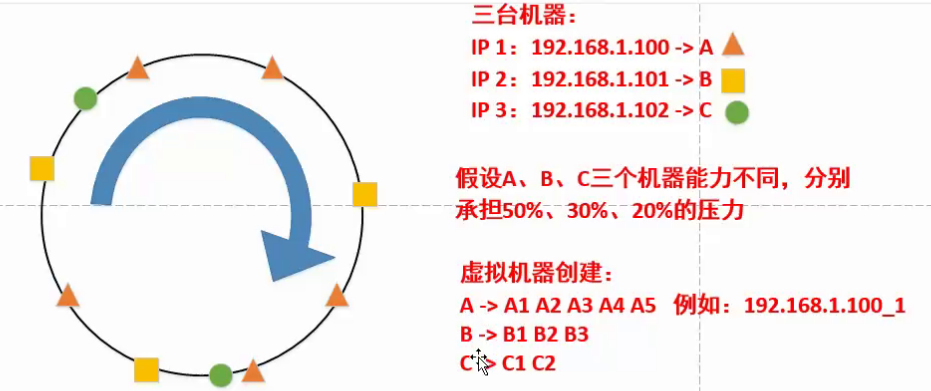
- 一致性哈希算法的优点:形成动态闭环调节,如果有一台服务器出现问题,例如图中B服务器出现问题,A和C可以代替其承担。
Partition的作用
- 对于spill出的数据进行哈希取模,原来数据形式(key, value),取模后变成(partition,key, value)
- reduce有几个partition就有几个
- 在进行MapReduce计算时,有时候需要把最终的输出数据分到不同的文件中,比如按照省份划分的话,需要把同一省份的数据放到一个文件中;按照性别划分的话,需要把同一性别的数据放到一个文件中。我们知道最终的输出数据是来自于Reducer任务。那么,如果要得到多个文件,意味着有同样数量的Reducer任务在运行。Reducer任务的数据来自于Mapper任务,也就说Mapper任务要划分数据,对于不同的数据分配给不同的Reducer任务运行。Mapper任务划分数据的过程就称作Partition。负责实现划分数据的类称作Partitioner。
HDFS中block
- 文件存储在HDFS中,每个文件切分成多个一定大小(默认64M)的block(默认3个备份)存储在多个节点(DataNode)上
- block的修改:hdfs-site.xml配置文件中修改dfs.block.size的值
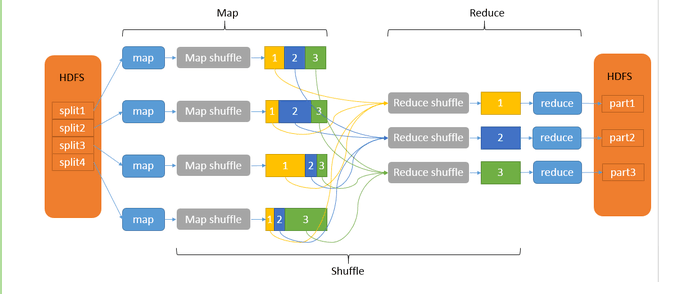
Shuflle
- shuffle是MapReduce的“心脏”,是奇迹发生的地方
- Shuflle包括很多环节:partition sort spill meger combiner copy memery disk
[Hadoop]浅谈MapReduce原理及执行流程的更多相关文章
- MapReduce作业的执行流程
MapReduce任务执行总流程 一个MapReduce作业的执行流程是:代码编写 -> 作业配置 -> 作业提交 -> Map任务的分配和执行 -> 处理中间结果 -> ...
- 浅谈循环中setTimeout执行顺序问题
浅谈循环中setTimeout执行顺序问题 (下面有见解一二) 期望:开始输出一个0,然后每隔一秒依次输出1,2,3,4. for (var i = 0; i < 5; i++) { setTi ...
- SpringBoot项目构建、测试、热部署、配置原理、执行流程
SpringBoot项目构建.测试.热部署.配置原理.执行流程 一.项目构建 二.测试和热部署 三.配置原理 四.执行流程
- 浅谈mapreduce程序部署
尽管我们在虚拟机client上能非常快通过shell命令,进行运行一些已经封装好实例程序,可是在应用中还是是自己敲代码,然后部署到server中去,以下,我通过程序进行浅谈一个程序的部署过程. 在启动 ...
- hadoop学习(七)----mapReduce原理以及操作过程
前面我们使用HDFS进行了相关的操作,也了解了HDFS的原理和机制,有了分布式文件系统我们如何去处理文件呢,这就的提到hadoop的第二个组成部分-MapReduce. MapReduce充分借鉴了分 ...
- 浅谈MapReduce工作机制
1.MapTask工作机制 整个map阶段流程大体如上图所示.简单概述:input File通过getSplits被逻辑切分为多个split文件,通通过RecordReader(默认使用lineRec ...
- 浅谈xss原理
近日,论坛上面XSS满天飞,各处都能够见到XSS的痕迹,前段时间论坛上面也出现了XSS的迹象.然后我等小菜不是太懂啊,怎么办?没办法仅仅有求助度娘跟谷歌这对情侣了. 能够说小菜也算懂了一些.不敢藏私, ...
- MapReduce架构与执行流程
一.MapReduce是用于解决什么问题的? 每一种技术的出现都是用来解决实际问题的,否则必将是昙花一现,那么MapReduce是用来解决什么实际的业务呢? 首先来看一下MapReduce官方定义: ...
- hadoop笔记之MapReduce原理
MapReduce原理 MapReduce原理 简单来说就是,一个大任务分成多个小的子任务(map),并行执行后,合并结果(reduce). 例子: 100GB的网站访问日志文件,找出访问次数最多的I ...
随机推荐
- 关于CSS的书写规范和顺序
关于CSS的书写规范和顺序,是大部分前端er都必须要攻克的一门关卡,如果没有按照良好的CSS书写规范来写CSS代码,会影响代码的阅读体验.这里总结了一个CSS书写规范.CSS书写顺序供大家参考,这些是 ...
- Currying 及应用
Currying,中文多翻译为柯里化,感觉这个音译还没有达到类似 Humor 之于幽默的传神地步,后面直接使用 Currying. 什么是 Currying Currying 是这么一种机制,它将一个 ...
- kettle 利用 HTTP Client 获取猫眼电影API近期上映相关信息,并解析json
前言 Kettle 除了常规的数据处理之外,还可以模拟发送HTTP client/post ,REST client. 实验背景 这周二老师布置了一项实验: 建立一个转换,实现一个猫眼API热映电影的 ...
- 渗透测试-基于白名单执行payload--Odbcconf
复现亮神课程 基于白名单执行payload--Odbcconf 0x01 Odbcconf简介: ODBCCONF.exe是一个命令行工具,允许配置ODBC驱动程序和数据源. 微软官方文档:https ...
- 友价商城SQL注入
友价商城SQL注入 源码出自:https://www.0766city.com/yuanma/9990.html 下载安装好后打开是这样的: 8不说了 ,seay审计一把梭哈 从开始审计 直 ...
- Web安全之CSRF漏洞整理总结
这两天整理和编写了csrf的靶场,顺便也复习了以前学习csrf的点,这里记录下学习的总结点. 0x01 关于CSRF 跨站请求伪造 CSRF(Cross-site request forgery)跨站 ...
- HTTPS 验证访问略记
背景 互联网刚刚兴起的时候,网络安全并没有被很好的重视.HTTP 是明文传输的,这为意图谋不道德之事者提供了诸多的便利.当越来越多的人利益受到侵害的时候,开始重视网络传输的安全问题了. HTTPS 加 ...
- nginx::基于Nginx+nginx-rtmp-module+ffmpeg搭建rtmp、hls流媒体服务器
待续 ffmpeg -re -i "/home/bk/hello.mp4" -vcodec libx264 -vprofile baseline -acodec aac -ar 4 ...
- Python编程系列---使用字典实现路由静态路由
def index(): print('Index Page....') def bbs(): print('BBS Page....') def login(): print('Login Page ...
- CentOS6.6-MySQL报Curses library not found
cmake . -DCMAKE_INSTALL_PREFIX=/application/mysql-5.6.40 \> -DMYSQL_DATADIR=/application/mysql-5. ...