在Azure云上实现postgres主备切换
以下是工作上实现postgres主备切换功能所用到的代码和步骤,中间走了不少弯路,在此记录下。所用到的操作系统为centos 7.5,安装了两台服务器,hostname为VM7的为Master,VM8则为Slave。
1、安装pg10
vm7(Mater),vm8(Slave)均需安装:
[root@springcloud-vm7 ~]# yum install –y https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm
[root@springcloud-vm7 ~]# yum install postgresql10 -y
[root@springcloud-vm7 ~]# yum install postgresql10-server -y
[root@springcloud-vm7 ~]# systemctl enable postgresql-
[root@springcloud-vm7 ~]# /usr/pgsql-/bin/postgresql--setup initdb
[root@springcloud-vm7 ~]# systemctl start postgresql-
[root@springcloud-vm7 ~]# systemctl status postgresql-
其他环境设置
vm7(Mater),vm8(Slave)均需安装:
# hosts
[root@springcloud-vm7 ~]# vi /etc/hosts
...
10.0.0.14 springcloud-vm7 vm7
10.0.0.15 springcloud-vm8 vm8 # disable selinux
[root@springcloud-vm7 ~]# sed -i '7s/=.*$/=disabled/' /etc/selinux/config
[root@springcloud-vm7 ~]# setenforce # set timezone
[root@springcloud-vm7 ~]# timedatectl set-timezone Asia/Shanghai
# postgres⽤用户环境
[root@springcloud-vm7 ~]# su - postgres
-bash-4.2$ vi ~/.bash_profile
。。。
PATH=$PATH:/usr/pgsql-/bin;export PATH
-bash-4.2$ . ~/.bash_profile #注意:~/.bash_profile改后为:
PGDATA=/usr/local/pgsql/data
PATH=/usr/local/pgsql/bin:$PATH
export PGDATA PATH
安装nginx充当给azure做探测的服务(probe):
[root@springcloud-vm7 ~]# yum install -y epel-release
[root@springcloud-vm7 ~]# yum install -y nginx
[root@springcloud-vm7 ~]# vi /etc/nginx/nginx.conf
...
listen default_server; #修改监听端口在5999上
由于Azure上LB的floatingIP限制,它会将流量量导向probe成功的后端机器器,并且只能有⼀一台probe成功。
参考官⽅方例例⼦子,它是⽤用iptable来阻⽌止probe:https://github.com/Azure/azure-quickstart-templates/tree/master/haproxy-redundant-floatingip-ubuntu
azure的LSB设置:
注意:负载均衡的probe端⼝口设置成5999,floatingIP设置启⽤用
2、配置master
[root@springcloud-vm7 ~]# su – postgres # 创建复制⽤用户
-bash-4.2$ psql -c "create role repl replication login password 'postgres'" # 创建⼀一个slot
-bash-4.2$ psql -c "select pg_create_physical_replication_slot('slot_vm7')" pg_create_physical_replication_slot
-------------------------------------
(slot_vm7,)
( row) # 配置参数
-bash-4.2$ cd $PGDATA
-bash-4.2$ vi postgresql.conf
。。。
listen_addresses = '*'
archive_mode = on
archive_command = 'cp -n %p $PGDATA/arch/%f'
log_timezone = 'Asia/Shanghai'
timezone = 'Asia/Shanghai'
。。。
# 创建arch⽬目录
-bash-4.2$ mkdir $PGDATA/arch/ # 配置pg_hba.conf
-bash-4.2$ vi pg_hba.conf
。。。
host replication repl 10.0.0.0/ md5 # 重启
-bash-4.2$ pg_ctl restart 注意:如果是首次安装,需要在防火墙中开放5432端口
#查看各端口网络连接情况
[root@springcloud-vm7 ~]# netstat –na #安装iptables防火墙
[root@springcloud-vm7 ~]# yum install iptables-services #编辑iptables防火墙配置
[root@springcloud-vm7 ~]# vi /etc/sysconfig/iptables
。。。
-A INPUT -m state --state NEW -m tcp -p tcp --dport -j ACCEPT
3、配置slave
[root@springcloud-vm8 ~]# su – postgres # 直接⽤用repl⽤用户备份到$PGDATA⽬目录
-bash-4.2$ rm -rf /var/lib/pgsql//data
-bash-4.2$ /usr/pgsql-/bin/pg_basebackup -R -Pv -h vm7 -U repl -D $PGDATA
Password: #postgres pg_basebackup: initiating base backup, waiting for checkpoint to complete
pg_basebackup: checkpoint completed
pg_basebackup: write-ahead log start point: / on timeline
pg_basebackup: starting background WAL receiver
/ kB (%), / tablespace
pg_basebackup: write-ahead log end point: /20000F8
pg_basebackup: waiting for background process to finish streaming ...
pg_basebackup: base backup completed # 修改recovery.conf⽂文件
-bash-4.2$ vi $PGDATA/recovery.conf standby_mode = 'on'
primary_conninfo = 'user=repl password=postgres host=vm7 port=5432 sslmode=prefer sslcompression=1 krbsrvname=postgres target_session_attrs=any'
primary_slot_name = 'slot_vm7'
restore_command = 'cp $PGDATA/arch/%f %p'
archive_cleanup_command = 'pg_archivecleanup $PGDATA/arch %r'
recovery_target_timeline = 'latest' # 重启
-bash-4.2$ pg_ctl restart
4、检查
#主库上检查下:
-bash-4.2$ psql -xc "select * from pg_stat_replication"
-[ RECORD ]----+------------------------------
pid |
usesysid |
usename | repl
application_name | walreceiver
client_addr | 10.0.0.11
client_hostname |
client_port |
backend_start | -- ::25.005202+
backend_xmin |
state | streaming
sent_lsn | /F0004A0
write_lsn | /F0004A0
flush_lsn | /F0004A0
replay_lsn | /F0004A0
write_lag |
flush_lag |
replay_lag |
sync_priority |
sync_state | async
-bash-4.2$ pg_controldata
...
-bash-4.2$ psql -xc "select * from pg_replication_slots"
... #被库上检查:
-bash-4.2$ psql -xc "select * from pg_stat_wal_receiver"
...
-bash-4.2$ /usr/pgsql-/bin/pg_controldata
...
-bash-4.2$ psql -xc "select pg_is_in_recovery()"
-[ RECORD ]-----+--
pg_is_in_recovery | t
5、安装keepalived
vm7(Mater),vm8(Slave)均需安装:
[root@springcloud-vm7 data]# yum install keepalived -y
[root@springcloud-vm7 data]# systemctl enable keepalived
[root@springcloud-vm7 data]# systemctl start keepalived
[root@springcloud-vm7 data]# cd /etc/keepalived/
[root@springcloud-vm7 ~]# vi /etc/keepalived/keepalived.conf ! Configuration File for keepalived
global_defs {
notification_email {
admin@example.com
}
notification_email_from pg@example.com
smtp_server 127.0.0.1
smtp_connect_timeout
router_id PG_HA #主备库需要一致
} vrrp_script chk_pg_alived {
script "/sbin/ss -ntlp4 | grep :5432 > /dev/null" # 探测端⼝口判断数据库存活,1分钟失败则认为失败
interval
weight
fall
} vrrp_instance VI_1 {
state MASTER # 主库上填MASTER, 备库上为BACKUP
interface eth0 # 填写当前网卡名称,可以用IP Ad命令查看
virtual_router_id
priority #备库的优先级设为90
advert_int
!nopreempt
preempt_delay
unicast_src_ip 10.0.0.14 # 云主机只能使⽤用单播⽅方式,这⾥里里填本机ip
unicast_peer {
10.0.0.15 #另⼀台ip
} authentication {
auth_type PASS
auth_pass
} virtual_ipaddress {
139.217.92.247 #虚拟ip
} track_script {
chk_pg_alived
} notify_master "/etc/keepalived/master.sh"
notify_backup "/etc/keepalived/backup.sh"
} # 切换成master时会执⾏行行的脚本,通过判断数据库状态决定是否promote
[root@springcloud-vm7 keepalived]# vi master.sh #!/bin/bash
export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin # allow probe from azure
systemctl restart nginx
dbstate=`su - postgres -c "psql -Atc 'select pg_is_in_recovery()'"`
if [ $dbstate != "t" ]; then
exit
fi # promote the slave to master
su - postgres -c "/usr/pgsql-10/bin/pg_ctl promote"
sleep echo "select pg_create_physical_replication_slot('slot_vm7')" | su – postgres -c "psql" #注意slot的名字主备库要相应修改⼀⼀对应(Slave中改为slot_vm8) #保存后修改脚本文件权限
[root@springcloud-vm7 keepalived]# chmod master.sh #切换成slave时会执⾏行行的脚本
[root@springcloud-vm7 keepalived]# vi backup.sh #!/bin/bash
export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin
# block probe from azure
systemctl stop nginx
# check pg state
dbstate=`su - postgres -c "psql -Atc 'select pg_is_in_recovery()'"`
if [ $dbstate = "t" ]; then
exit
fi
# change master to slave
if [ ! -f /var/lib/pgsql//data/recovery.conf ] ; then
cat > /var/lib/pgsql//data/recovery.conf << EOF
standby_mode = 'on'
primary_conninfo = 'user=repl password=postgres host=vm8 port=5432 sslmode=prefer sslcompression=1 krbsrvname=postgres target_session_attrs=any' #注意slot的名字主备库要相应修改⼀⼀对应(Slave中改为vm7)
primary_slot_name = 'slot_vm8' #注意slot的名字主备库要相应修改⼀⼀对应(Slave中改为slot_vm7)
restore_command = 'cp $PGDATA/arch/%f %p'
archive_cleanup_command = 'pg_archivecleanup $PGDATA/arch %r'
recovery_target_timeline = 'latest'
EOF
fi
sleep
su - postgres -c "/usr/pgsql-10/bin/pg_ctl stop"
systemctl start postgresql- #注意slot的名字主备库要相应修改⼀⼀对应 #保存后修改脚本文件权限
[root@springcloud-vm7 keepalived]# chmod backup.sh
6、测试
6.1、 关闭Master服务器

6.2、 在Slave服务器中监控keepalived: journalctl -f -u keepalived
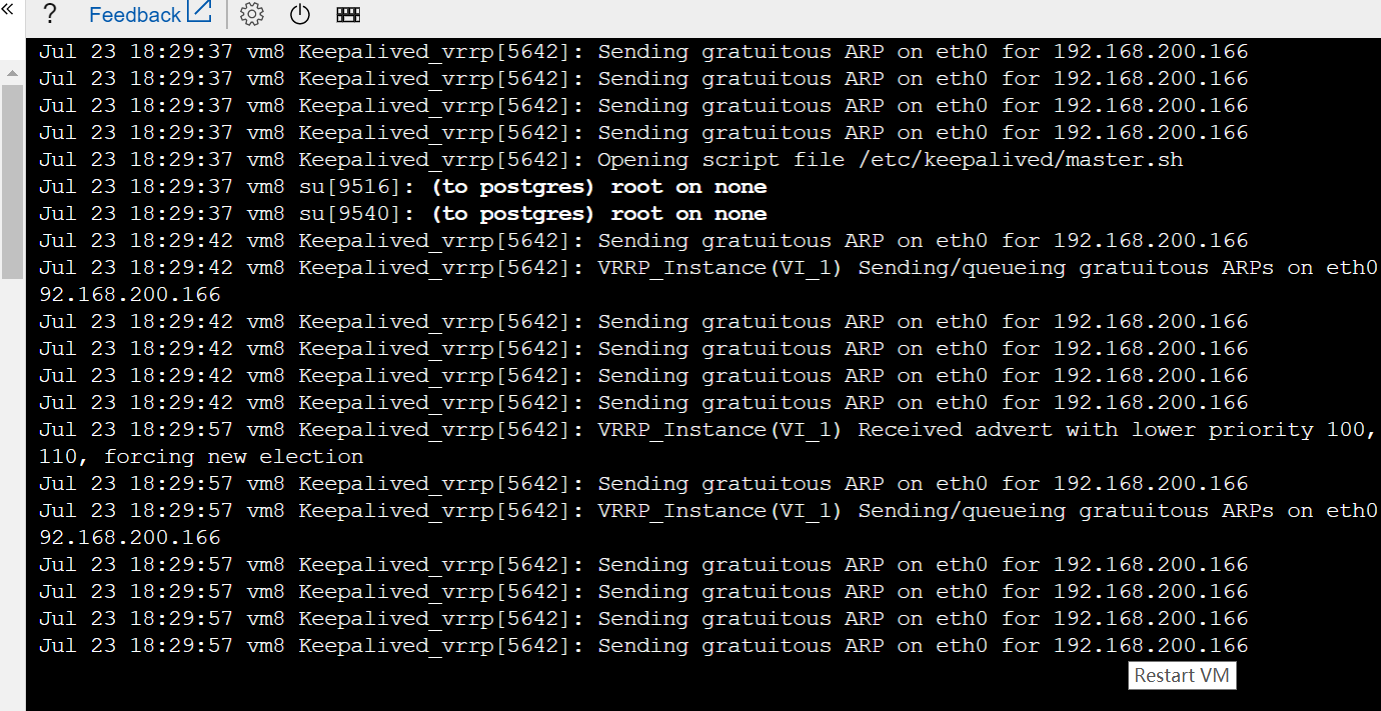
6.3、 在Slave服务器中查询postgres日志:tail -fn20 /var/lib/pgsql/10/data/log/postgresql-Tue.log
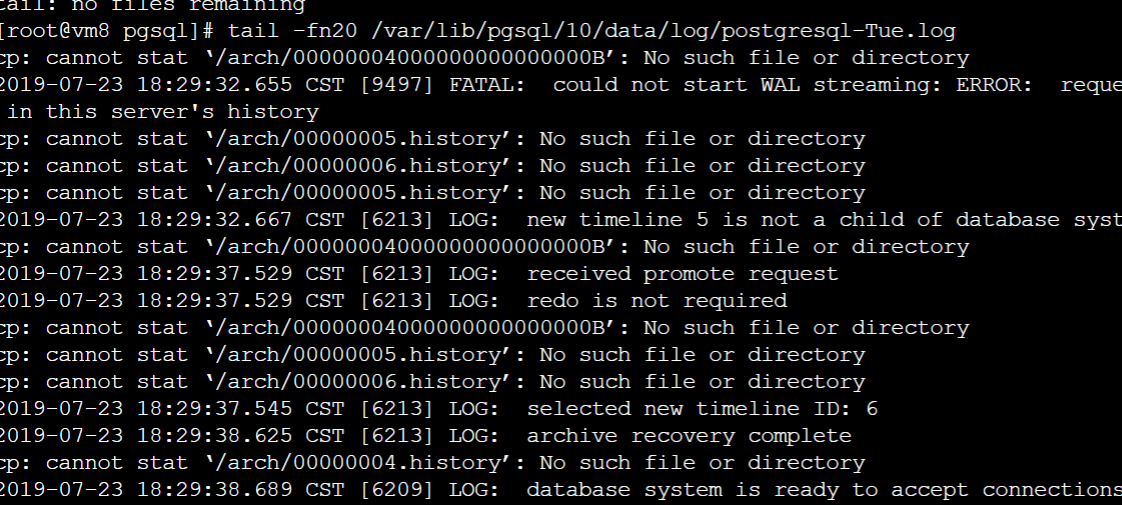
6.4、 在Slave服务器中监控IP是否发生了漂移: ip a
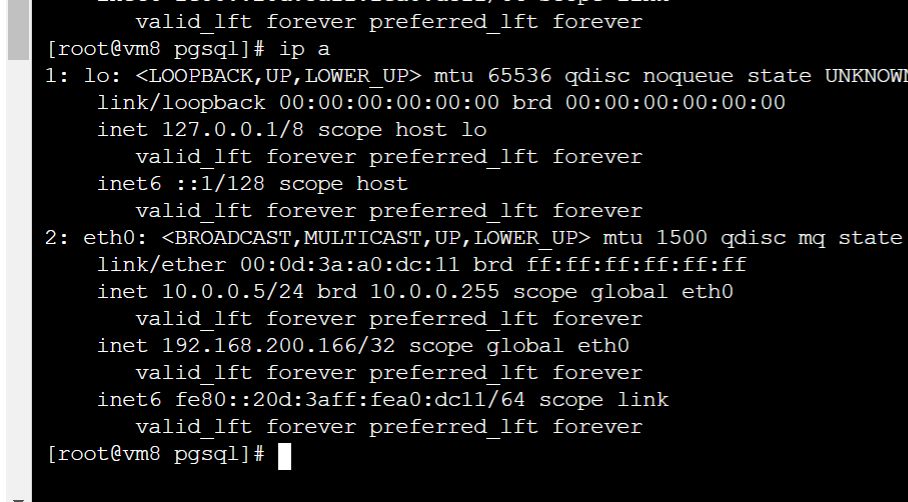
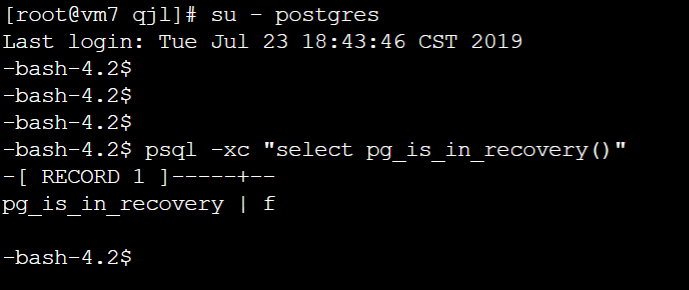
6.5、 在Slave服务器中查看主备状态: psql -xc "select pg_is_in_recovery()"
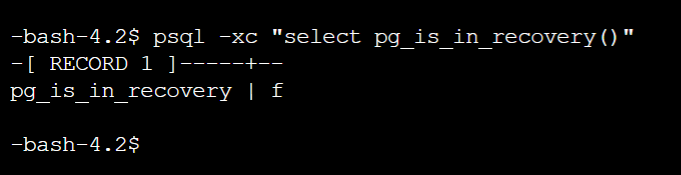
6.6、在Slave服务器中创建新表:psql -c 'create table t2 (id integer)'
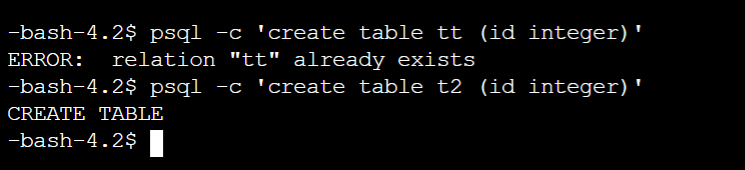
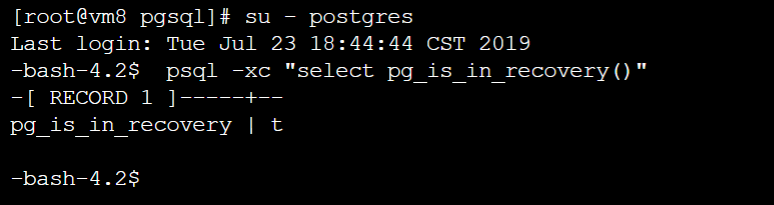
6.7、 Master服务器启动后再看主备状态:psql -xc "select pg_is_in_recovery()"
在Azure云上实现postgres主备切换的更多相关文章
- 在Windows Azure上配置VM主备切换(1)——Linux篇
对任何一个上线系统来说,高可用设计是不可或缺的一个环节,这样才可以确保应用可以持续.稳定的运行,而不是频繁的掉线.停机.高可用设计的核心思路很简单,就是消除一切单点故障,将单点链路或者节点升级为多点. ...
- Postgres主备切换
主备查询 主备不会自动切换(即需要实现线上环境主数据库宕掉之后,从数据库能够自动切换为主数据库,需要借用第三方软件,例如heartbeat等) (1)如何查看是primary还是standby 方法1 ...
- .NET Core2使用Azure云上的Iot-Hub服务
基于工业4.0大背景下的工业物联网是近几年内热门的话题,依靠信息化技术企业可以实现数字化转型,生产可以实现智能化制造,设备可以实现自动化运作.然而,海量的数据采集是整个建设过程的基础环节,如何处理与利 ...
- Spark系列(五)Master主备切换机制
Spark Master主备切换主要有两种机制,之中是基于文件系统,一种是基于Zookeeper.基于文件系统的主备切换机制需要在Active Master挂掉后手动切换到Standby Master ...
- (摘)DataGuard物理standby管理 - 主备切换
DataGuard物理standby管理 - 主备切换 Dataguard的切换分为两种,switchover和failover. switchover一般用于数据库或硬件升级,这时只需要较短时间中断 ...
- 测试redis+keepalived实现简单的主备切换【转载】
转自: 测试redis+keepalived实现简单的主备切换 - Try My Best 尽力而为 - ITeye技术网站http://raising.iteye.com/blog/2311757 ...
- MySQL 复制 - 性能与扩展性的基石 4:主备切换
一旦使用 MySQL 的复制功能,就很大可能会碰到主备切换的情况.也许是为了迭代升级服务器,或者是主库出现问题时,将一台备库转换成主库,或者只是希望重新分配容量.不过出于什么原因,都需要将新主库的信息 ...
- 使用broker进行Datagurd主备切换报ORA-12514异常
在使用Datagurd broker进行Datagurd主备切换时报ORA-12514监听异常, 详细信息如下: DGMGRL> switchover to xiaohe; Performing ...
- Oracle DataGuard主备切换(switchover)
Oracle DataGuard主备切换可以使用传统的手动命令切换,也可以使用dgmgr切换,本文记录手动切换. (一)将主库切换为物理备库 STEP1:查看主库状态 SQL> SELECT O ...
随机推荐
- 【Demo 1】基于object_detection API的行人检测 2:数据制作
项目文件结构 因为目录太多又太杂,而且数据格式对路径有要求,先把文件目录放出来.(博主目录结构并不规范) 1.根目录下的models为克隆下来的项目.2.pedestrian_data目录下的路径以及 ...
- Linux学习笔记07之shell
shell从广义上分为两类: GUI:GNOME KDE XFACE等 CLI:sh csh bash shell启动:当用户登录完成后,系统会自动启动shelll程序 进程:应用程序的副本,用PID ...
- 【有容云】PPT | 容器落地之二三事儿
编者注: 本文为10月29日有容云联合创始人兼研发副总裁江松在 Docker Live时代线下系列-广州站中演讲的PPT,本次线下沙龙为有容云倾力打造Docker Live时代系列主题线下沙龙,每月一 ...
- JAVA开始(基础篇)
数据类型 Boolean 1位Byte 1个字节(8位)Short 2个字节Char 2个字节Int ...
- Spring Cloud 之 Stream.
一.简介 Spring Cloud Stream 是一个用来为微服务应用构建消息驱动能力的框架. Spring Cloud Stream 为一些供应商的消息中间件产品(目前集成了 RabbitMQ 和 ...
- 论文阅读 | Falcon: Balancing Interactive Latency and Resolution Sensitivity for Scalable Linked Visualizations
作者: Dominik Moritz, Bill Howe, Jeffrey Heer 发表于CHI 2019, 三位作者都来自于University of Washington Interactiv ...
- leetcode 29 两数相除
问题描述 给定两个整数,被除数 dividend 和除数 divisor.将两数相除,要求不使用乘法.除法和 mod 运算符. 返回被除数 dividend 除以除数 divisor 得到的商. 示例 ...
- 100天搞定机器学习|Day16 通过内核技巧实现SVM
前情回顾 机器学习100天|Day1数据预处理100天搞定机器学习|Day2简单线性回归分析100天搞定机器学习|Day3多元线性回归100天搞定机器学习|Day4-6 逻辑回归100天搞定机器学习| ...
- Appium+python自动化(三十)- 实现代码与数据分离 - 数据配置-yaml(超详解)
简介 本篇文章主要介绍了python中yaml配置文件模块的使用让其完成数据和代码的分离,宏哥觉得挺不错的,于是就义无反顾地分享给大家,也给大家做个参考.一起跟随宏哥过来看看吧. 思考问题 前面我们配 ...
- Node.js爬虫实战 - 爬你喜欢的
前言 今天没有什么前言,就是想分享些关于爬虫的技术,任性.来吧,各位客官,里边请... 开篇第一问:爬虫是什么嘞? 首先咱们说哈,爬虫不是"虫子",姑凉们不要害怕. 爬虫 - 一种 ...