Hadoop简述
Haddop是什么?
Hadoop是一个由Apache基金会所开发的分布式系统基础架构
主要解决,海量数据的存储和海量数据的分析计算问题。
Hadoop三大发行版本
Apache版本最原始(最基础)的版本,对于入门学习最好。
Cloudera在大型互联网企业中用的较多。
Hortonworks文档较好。
Hadoop的优势
1)高可靠性:因为Hadoop假设计算元素和存储会出现故障,因为它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理。
2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
3) 高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
4)高容错性:自动保存多份副本数据,并且能够自动将失败的任务重新分配。
Hadoop组成
1)Hadoop HDFS:一个高可靠、高吞吐量的分布式文件系统。
2)Hadoop MapReduce:一个分布式的离线并行计算框架。
3)Hadoop YARN:作业调度与集群资源管理的框架。
4)Hadoop Common:支持其他模块的工具模块。
HDFS架构概述
1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
3)Secondary NameNode(2nn):用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
YARN架构概述
1)ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
2)NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令;
3)ApplicationMaster:数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
4)Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
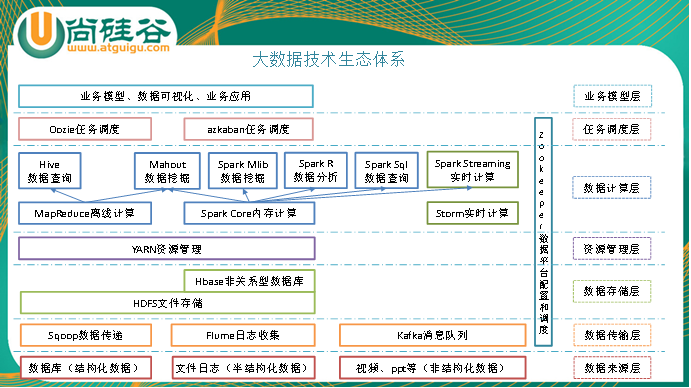
1)Sqoop:sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
2)Flume:Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
3)Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
(1)通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
(2)高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息
(3)支持通过Kafka服务器和消费机集群来分区消息。
(4)支持Hadoop并行数据加载。
4)Storm:Storm为分布式实时计算提供了一组通用原语,可被用于“流处理”之中,实时处理消息并更新数据库。这是管理队列及工作者集群的另一种方式。 Storm也可被用于“连续计算”(continuous computation),对数据流做连续查询,在计算时就将结果以流的形式输出给用户。
5)Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
6)Oozie:Oozie是一个管理Hdoop作业(job)的工作流程调度管理系统。Oozie协调作业就是通过时间(频率)和有效数据触发当前的Oozie工作流程。
7)Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
8)Hive:hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
10)R语言:R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
11)Mahout:
Apache Mahout是个可扩展的机器学习和数据挖掘库,当前Mahout支持主要的4个用例:
推荐挖掘:搜集用户动作并以此给用户推荐可能喜欢的事物。
聚集:收集文件并进行相关文件分组。
分类:从现有的分类文档中学习,寻找文档中的相似特征,并为无标签的文档进行正确的归类。
频繁项集挖掘:将一组项分组,并识别哪些个别项会经常一起出现。
12)ZooKeeper:Zookeeper是Google的Chubby一个开源的实现。它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、 分布式同步、组服务等。ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
Hadoop简述的更多相关文章
- Hadoop YARN学习之组件功能简述(3)
Hadoop YARN学习之组件功能简述(3) 1. YARN的三大组件功能简述: ResourceManager(RM)是集群的资源的仲裁者, 它有两部分:一个可插拔的调度器和一个Applicati ...
- Hadoop YARN学习之Hadoop框架演进历史简述
Hadoop YARN学习之Hadoop框架演进历史简述(1) 1. Hadoop在其发展的过程中经历了多个阶段: 阶段0:Ad Hoc集群时代 标志着Hadoop的起源,集群以Ad Hoc.单用户方 ...
- 简述hadoop安装步骤
简述hadoop安装步骤 安装步骤: 1.安装虚拟机系统,并进行准备工作(可安装- 一个然后克隆) 2.修改各个虚拟机的hostname和host 3.创建用户组和用户 4.配置虚拟机网络,使虚拟机系 ...
- [hadoop]mapreduce原理简述
1.用于map的输入,先将输入数据切分成相等的分片,为每一个分片创建一个map worker,这里的切片大小不是随意订的,一般是与HDFS块大小一致,默认是64MB,一个节点上存储输入数据切片的最大s ...
- hadoop 2.0安装及HA配置简述
一.单机模式 a.配置本机到本机的免密登录 b.解压hadoop压缩包,修改hadoop.env.sh中的JAVA_HOME c.修改core-site.xml <configuration&g ...
- Hadoop YARN 的工作流程简述
1.Client 向 YARN 提交应用程序,其中包括 ApplicationMaster 程序及启动 ApplicationMaster 命令2.ResourceManager 为该 Applica ...
- hadoop+tachyon+spark的zybo cluster集群综合配置
1.zybo cluster 架构简述: 1.1 zybo cluster 包含5块zybo 开发板组成一个集群,zybo的boot文件为digilent zybo reference design提 ...
- HADOOP安装指南-Ubuntu15.10和hadoop2.7.2
Ubuntu15.10中安装hadoop2.7.2安装手册 太初 目录 1. Hadoop单点模式... 2 1.1 安装步骤... 2 0.环境和版本... 2 1.在ubu ...
- Hadoop 之 MapReduce 框架演变详解
经典版的MapReduce 所谓的经典版本的MapReduce框架,也是Hadoop第一版成熟的商用框架,简单易用是它的特点,来看一幅图架构图: 上面的这幅图我们暂且可以称谓Hadoop的V1.0版本 ...
随机推荐
- Beetlex服务框架之Webapi版本访问控制
在应用服务中API更新是很普遍的事情,为了服务良好地运作很多时候需要新旧版本同时兼容:为了应对这一系列的需求FastHttpApi在新版中强化了Url重写机制来支持API访问版本控制,由原来固定的重写 ...
- 整理了适合新手的20个Python练手小程序
100个Python练手小程序,学习python的很好的资料,覆盖了python中的每一部分,可以边学习边练习,更容易掌握python. 本文附带基础视频教程:私信回复[基础]就可以获取的 [程序1] ...
- vue 开发插件流程
UI demo UI 插件汇总 我的github iSAM2016 在练习写UI组件的,用到全局的插件,网上看了些资料.看到些的挺好的,我也顺便总结一下写插件的流程: 声明插件-> 写插件-&g ...
- Java设计模式_七大原则
简介 单一职责原则.对类来说,即一个类应该只负责一项职责. 开闭原则.对扩展开放,对修改关闭.在程序需要进行扩展的时候,不能去修改原有代码,使用接口和抽象类实现一个热插拔的效果. 里氏替换原则.任何基 ...
- Java基础学习框架总结
内容:Java基础知识全面复习 时间:2019.9.3-2019.9.26 代码:D:/ProgramFiles/IDEA/hello_sort 一.基础知识 learning1 case分支 Inp ...
- Dubbo 全链路追踪日志的实现
微服务架构的项目,一次请求可能会调用多个微服务,这样就会产生多个微服务的请求日志,当我们想要查看整个请求链路的日志时,就会变得困难,所幸的是我们有一些集中日志收集工具,比如很热门的ELK,我们需要把这 ...
- CSPS模拟 74
T1 贪心,如果用set考虑一下multi. T2 难道是我的疑问都太过sb? 从来没人愿意认真思考一下我的问题. 更好,思考量这东西本该我自己来补. 设$dp[i][j]$为i个点的森林,j个点在特 ...
- csps模拟测试92反思
连着挂了三天T1了. 89: SPFA$vst$数组没清空 90:调试的时候多删了一句代码 91:没开$long long$ 我真是废物. 希望以后不要犯SB错误了
- NOIP原题 斗地主(20190804)
题目描述 牛牛最近迷上了一种叫斗地主的扑克游戏.斗地主是一种使用黑桃.红心.梅花.方片的A到K加上大小王的共54张牌来进行的扑克牌游戏.在斗地主中,牌的大小关 系根据牌的数码表示如下:3<4&l ...
- ssm整合的登录
新建一个web工程,主要结构如下: 数据库创建如下: 控制层的代码FormController 类 package codeRose.controller; import org.springfram ...