MySQL InnoDB MVCC
MySQL 原理篇
MVCC
MVCC 的定义
MVCC(Multiversion concurrency control):多版本并发控制,并发访问(读或写)数据库时,对正在事务内处理的数据做多版本的管理。以达到用来避免写操作的堵塞,从而引发读操作的并发问题。
MVCC 逻辑流程
插入

MySQL 在每一行数据中都会默认添加一些隐藏列 DB_TRX_ID、DB_ROLL_PT。
上面图中的执行步骤如下:
- 手动开启事务,从 InnoDB 引擎中获取一个全局事务ID(1)
- 然后往 teacher 表中插入两条数据,同时设置数据行的版本号为当前事务ID,删除版本号为 NULL
思考:如果事务是自动提交的(SET AUTOCOMMIT = NO),且未手动开启事务,执行如下两条 SQL,插入的数据会是什么样子的?
INSERT INTO teacher (NAME, age) VALUE ('seven', 18) ;
INSERT INTO teacher (NAME, age) VALUE ('qingshan', 19) ;
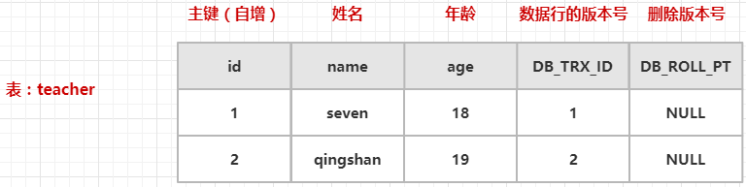
因为事务是自动提交的,所以两条插入语句会分别获取事务ID,所以这里插入的数据行的版本号是1和2。
删除
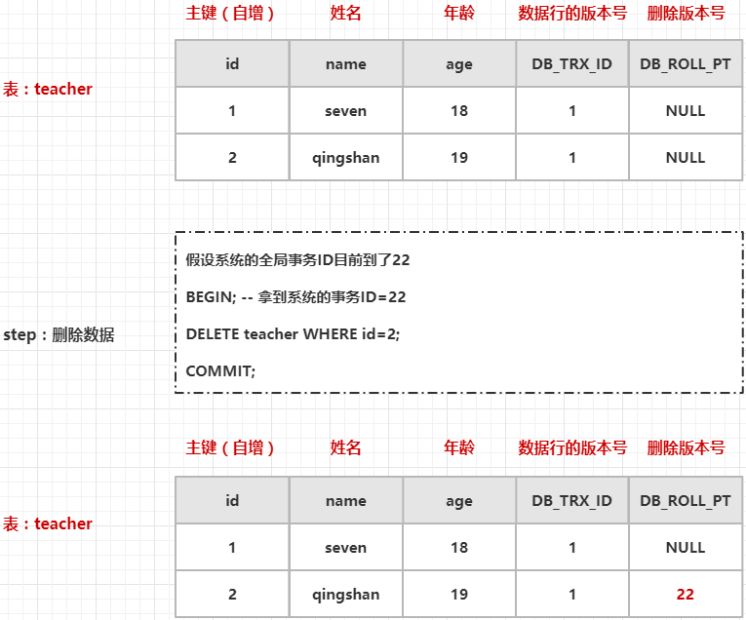
上面图中的执行步骤如下:
- 手动开启事务,从 InnoDB 引擎中获取一个全局事务ID(22)
- 然后执行一条删除语句,InnoDB 会找到这条记录,把它的删除版本号设置为当前事务ID
修改
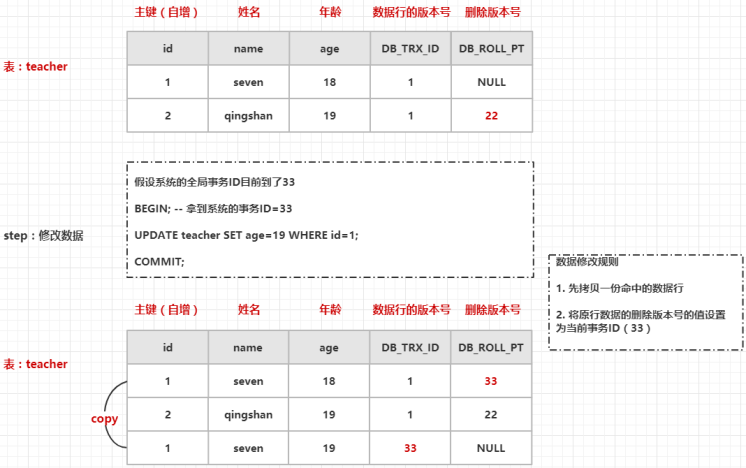
上面图中的执行步骤如下:
- 手动开启事务,从 InnoDB 引擎中获取一个全局事务ID(33)
- 然后执行一条修改语句,InnoDB 会找到这条记录,copy 一份原数据插入到表中,将新行数据的数据行的版本号的值设置为当前事务ID,将原行数据的删除版本号的值设置为当前事务ID
查询
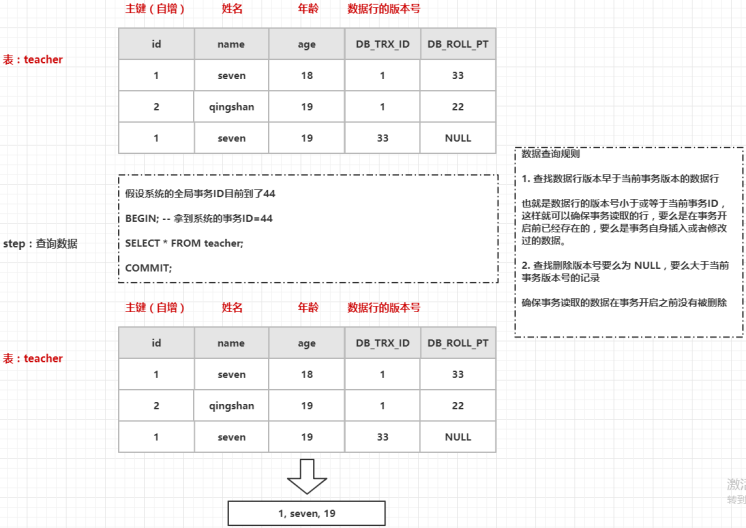
上面图中的执行步骤如下:
- 手动开启事务,从 InnoDB 引擎中获取一个全局事务ID(44)
- 根据数据查询规则的描述
- 查找数据行版本早于当前事务版本的数据行,发现表中三行数据都满足条件
- 查找删除版本号要么为 NULL,要么大于当前事务版本号的记录,发现只有最后一条数据满足条件(1, seven, 19)
案例分析
数据准备:
CREATE TABLE `teacher` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(32) NOT NULL,
`age` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4; INSERT INTO teacher(id,NAME,age) VALUES (1,'seven',18);
INSERT INTO teacher(id,NAME,age) VALUES (2,'qingshan',20);
案例一
-- 事务A执行
BEGIN; --
SELECT * FROM teacher; --
COMMIT; --事务B执行
BEGIN; --
UPDATE teacher SET age =28 WHERE id=1; --
COMMIT;
案例一的执行步骤是:1,2,3,4,2,执行效果如下图所示:

虽然在执行 3,4 步骤的时候更新 id=1 的数据,但是根据 MVCC 的查询逻辑流程,再次执行2,获取到的数据依然和第一次一样。
案例二
-- 事务A执行
BEGIN; --
SELECT * FROM teacher; --
COMMIT; --事务B执行
BEGIN; --
UPDATE teacher SET age =28 WHERE id=1; --
COMMIT;
案例二的执行步骤是:3,4,1,2,执行效果如下图所示:

根据 MVCC 的查询逻辑流程,执行1,2,获取到的数据是事务B未提交的数据,这个是有问题的。
分析了案例一和案例二,发现 MVCC 不能解决案例二的问题,InnoDB 会使用 Undo log 解决案例二的问题。
Undo Log
Undo Log 的定义
Undo:意为取消,以撤销操作为目的,返回指定某个状态的操作。
Undo Log:数据库事务提交之前,会将事务修改数据的镜像(即修改前的旧版本)存放到 undo 日志里,当事务回滚时,或者数据库奔溃时,可以利用 undo 日志,即旧版本数据,撤销未提交事务对数据库产生的影响。。
- 对于 insert 操作,undo 日志记录新数据的 PK(ROW_ID),回滚时直接删除;
- 对于 delete/update 操作,undo 日志记录旧数据 row,回滚时直接恢复;
- 他们分别存放在不同的buffer里。
|
Undo Log 是为了实现事务的原子性而出现的产物。 Undo Log 实现事务原子性:事务处理过程中,如果出现了错误或者用户执行了 ROLLBACK 语句,MySQL 可以利用 Undo Log 中的备份将数据恢复到事务开始之前的状态。 |
InnoDB 发现可以基于 Undo Log 来实现多版本并发控制。
|
Undo Log 在 MySQL InnoDB 存储引擎中用来实现多版本并发控制。 Undo Log 实现多版本并发控制:事务未提交之前,Undo Log 保存了未提交之前的版本数据,Undo Log 中的数据可作为数据旧版本快照供其他并发事务进行快照读。 |
分析下图中 SQL 的执行过程。
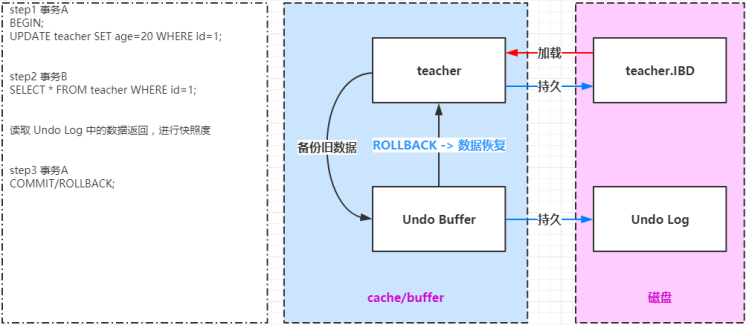
- 事务A手动开启事务,执行更新操作,首先会把更新命中的数据拷贝到 Undo Buffer 中
- 事务B手动开启事务,执行查询操作,会读取 Undo Log 中数据返回,进行快照度
当前读和快照读
快照读
SQL 读取的数据是快照版本,也就是历史版本,普通的 SELECT 就是快照读。
InnoDB 快照读,数据的读取将由 cache(原本数据)+ Undo Log(事务修改过的数据)两部分组成。
当前读
SQL 读取的数据是最新版本,通过锁机制来保证读取的数据无法通过其他事务进行修改。
UPDATE 、DELETE 、INSERT 、SELECT … LOCK IN SHARE MODE 、SELECT … FOR UPDATE 都是当前读,这些操作在《MySQL InnoDB 锁》这篇文章中有过演示,事务A执行这些 SQL,会阻塞事务B的 SQL 执行。
在 InnoDB 引擎里面,快照读通过 MVCC 解决幻读的问题,当前读通过 Next-Key Locks 解决幻读的问题。
Redo Log
Redo Log 的定义
Redo:顾名思义就是重做。以恢复操作为目的,重现操作。
Redo Log:指事务中操作的任何数据,将最新的数据备份到一个地方(Redo Log)。
Redo Log 的持久化:不是随着事务的提交才写入的,而是在事务的执行过程中,便开始写入 Redo Log 中,具体的落盘策略可以进行配置。
Redo Log 是为了实现事务的持久性而出现的产物。
Redo Log 实现事务持久性:防止在发生故障的时间点,尚有脏页未写入表的 IBD 文件中,在重启 MySQL 服务的时候,根据 Redo Log 进行重做,从而达到事务的未入磁盘数据进行持久化这一特性。
根据下图分析 Redo Log 的执行流程
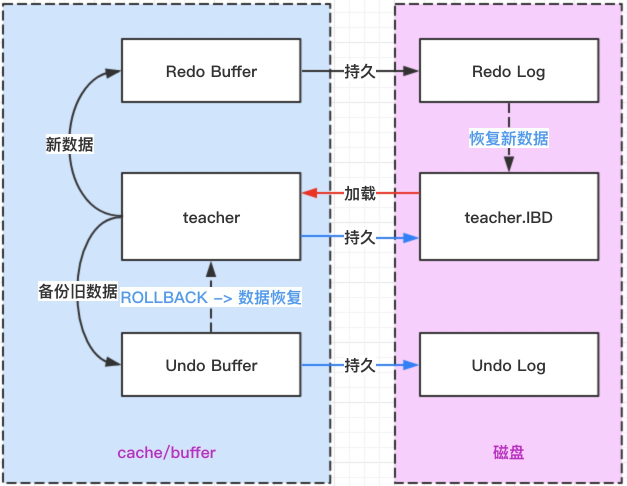
InnoDB 不是每一次提交事务都把数据从缓存区持久化到硬盘的,因为每次提交事务都把数据持久化到硬盘,效率很低,每一次持久化都需要执行 IO 操作。
InnoDB 会把每次数据变化会先进入 Redo Buffer 中,事务提交了,会根据策略把新的数据写入 Redo Log 中,InnoDB 就会认为这次事务提交成功了,数据并不一定马上就进入表的 IBD 文件中。
疑问:持久化到 Redo Log 中和持久化到表的 IBD 文件一样都是 IO 操作,为什么要设计 Redo Log 呢?
其实是因为持久化到 Redo Log 中是顺序 IO 的操作,而持久化到表的 IBD 文件中是一个随机 IO 的操作,比如我们需要更新 id=1 和 id=8 的数据,如果是 Redo Log,就只需要把更新的数据顺序存入 Redo Log 中;但如果是表的 IBD 文件,就需要先找到 id=1 和 id=8 的两个不连续的磁盘文件地址,再做持久化操作,影响数据库服务的并发性能。
Redo Log 的持久化配置
指定 Redo Log 记录在 {datadir}/ib_logfile1 和 ib_logfile2 两个文件中,可以通过 innodb_log_group_home_dir配置指定目录存储。
一旦事务成功提交且数据持久化到表的 IBD 文件中之后,此时 Redo Log 中的对应事务数据记录就失去了意义,所 以 Redo Log 的写入是日志文件循环写入的过程,也就是覆盖写的过程。
- 指定 Redo Log 日志文件组中的数量 innodb_log_files_in_group 默认为2
- 指定 Redo Log 每一个日志文件最大存储量 innodb_log_file_size 默认48M
- 指定 Redo Log 在 cache/buffer 中的 buffer 池大小 innodb_log_buffer_size 默认16M
Redo Buffer 持久化到 Redo Log 的策略,通过设置 Innodb_flush_log_at_trx_commit 的值:
- 取值0:每秒提交 Redo buffer -> Redo Log OS cache -> flush cache to disk,可能丢失一秒内的事务数据。
- 取值1(默认值):每次事务提交执行 Redo Buffer -> Redo Log OS cache -> flush cache to disk,最安全,性能最差的方式
- 取值2:每次事务提交执行 Redo Buffer -> Redo log OS cache 再每一秒执行 -> flush cache to disk 操作
一般建议选择取值2,因为 MySQL 挂了最多损失一次事务提交的数据,整个服务期挂了才会损失一秒的事务提交数据。
MySQL InnoDB MVCC的更多相关文章
- MySQL InnoDB MVCC深度分析
关于MySQL的InnoDB的MVCC原理,很多朋友都能说个大概: 每行记录都含有两个隐藏列,分别是记录的创建时间与删除时间 每次开启事务都会产生一个全局自增ID 在RR隔离级别下 INSERT -& ...
- MySQL InnoDB 实现高并发原理
MySQL 原理篇 MySQL 索引机制 MySQL 体系结构及存储引擎 MySQL 语句执行过程详解 MySQL 执行计划详解 MySQL InnoDB 缓冲池 MySQL InnoDB 事务 My ...
- MySQL InnoDB存储引擎中的锁机制
1.隔离级别 Read Uncommited(RU):这种隔离级别下,事务间完全不隔离,会产生脏读,可以读取未提交的记录,实际情况下不会使用. Read Committed (RC):仅能读取到已提交 ...
- mysql的mvcc(多版本并发控制)
mysql的mvcc(多版本并发控制) 我们知道,mysql的innodb采用的是行锁,而且采用了多版本并发控制来提高读操作的性能. 什么是多版本并发控制呢 ?其实就是在每一行记录的后面增加两个隐藏列 ...
- 搞懂MySQL InnoDB事务ACID实现原理
前言 说到数据库事务,想到的就是要么都做修改,要么都不做.或者是ACID的概念.其实事务的本质就是锁和并发和重做日志的结合体.那么,这一篇主要讲一下InnoDB中的事务到底是如何实现ACID的. 原子 ...
- MySQL InnoDB 存储引擎探秘
在MySQL中InnoDB属于存储引擎层,并以插件的形式集成在数据库中.从MySQL5.5.8开始,InnoDB成为其默认的存储引擎.InnoDB存储引擎支持事务.其设计目标主要是面向OLTP的应用, ...
- 浅析MySQL InnoDB的隔离级别
MySQL InnoDB存储引擎中事务的隔离级别有哪些?对应隔离级别的实现机制是什么? 本文就将对上面这两个问题进行解答,分析事务的隔离级别以及相关锁机制. 隔离性简介 隔离性主要是指数据库系统提供一 ...
- innodb mvcc实现机制
多版本并发控制 大部分的MySQL的存储 引擎,比如InnoDB,Falcon,以及PBXT并不是简简单单的使用行锁机制.它们都使用了行锁结合一种提高并发的技术,被称为MVCC(多版本并 发控制).M ...
- MySQL InnoDB Update和Crash Recovery流程
MySQL InnoDB Update和Crash Recovery流程 概要信息 首先介绍了Redo,Undo,Log Sequence Number (LSN),Checkpoint,Rollba ...
随机推荐
- django-搭建BBS关键点总结
0826自我总结 django-搭建BBS关键点总结 一.关于开口子,直接输入url访问文件内容 django自带开了个口子是static文件可以直接访问到 手动开口子 urs.py from dja ...
- [插件化开发] Poc之后,我选择放弃OSGI
Poc之后,我选择放弃OSGI TIPS: 如贵司允许重构老系统或者允许使用OSGI的第三方框架改造所带来的投入成本,并且评估之后ROI乐观,那么还是可以使用的. Runtime Version 以下 ...
- Codeforces 986B - Petr and Permutations
Description\text{Description}Description Given an array a[], swap random 2 number of them for 3n or ...
- 【Java必修课】ArrayList与HashSet的contains方法性能比较(JMH性能测试)
1 简介 在日常开发中,ArrayList和HashSet都是Java中很常用的集合类. ArrayList是List接口最常用的实现类: HashSet则是保存唯一元素Set的实现. 本文主要对两者 ...
- libevent::日志
LibEvent 能记录内部的错误和警告日志,如果编译进日志支持功能,也会记录调试信息.默认情况下这些消息都是输出 到 stderr,你也可以通过提供自己的日志函数的方法来覆盖这种行为. 为了覆盖 L ...
- cmd 获取当前登录的用户和远程连接的用户
打开cmd 执行 quser 可以看到我有两个 会话 带> 是我当前的会话 rdp 是远程连接的会话 console 是本机操作 可以知道谁在连接你 状态是 唱片 就是未连接的意思 ...
- Python编程系列---使用装饰器传参+字典实现动态路由
# 实现一个空路由表,利用装饰器将url和功能函数的对应关系自动存到这个字典中 router_dict = {} # 定义一个装饰器 # 再给一层函数定义,用来传入一个参数,这个参数就是访问的页面地址 ...
- RIDE-工程、测试套件、测试用例三者关系
理论 type的选择: 一般来说:测试项目(directory)-测试套件(file)-测试用例 本质上,“测试项目”和“测试套件”并没有什么区别,但是testcase只能放在file类型的test ...
- robotframework+ride+python3环境搭建
一.windows下安装python3.6 1.官网下载安装包https://www.python.org/downloads/windows/ 2.进行安装,接下来步骤一直next即可 二.cmd下 ...
- python-json与字典的区别
1.字典的类型是字典dict,是一种数据结构:json的类型是字符串str,json是一种格式: 接口测试是传参数payload时有时候是传的字符串,应该将payload的类型改为json 这点要注 ...