hadoop2.6.4 搭建伪分布式
安装jdk1.7
http://www.cnblogs.com/zhangXingSheng/p/6228432.html
[root@node4 sysconfig]# more /etc/hosts
127.0.0.1 localhost
192.168.177.124 hadoop-node4.com node4
[root@node4 sysconfig]#
修改主机名
[root@node4 sysconfig]# more network
NETWORKING=yes
HOSTNAME=node4
[root@node4 sysconfig]#
配置hadoop环境变量(vi /etc/profile)
###############hadoop################
export HADOOP_HOME=/usr/local/development/hadoop-2.6.
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

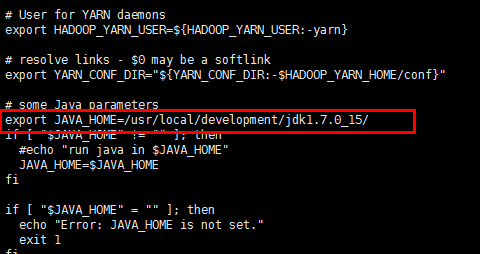
export JAVA_HOME=/usr/local/development/jdk1.7.0_15
[root@node4 hadoop]# more slaves
node4
[root@node4 hadoop]#

<configuration>
<property>
<name>hadoop.tmp.dir</name> //配置hadoop运行时临时文件的目录位置
<value>file:/home/zhangxs/data/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-zhangxs.com:9000</value>//配置nameNode的端口
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>//存储文件的副本数
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/zhangxs/data/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/zhangxs/data/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-zhangxs.com:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-zhangxs.com:19888</value>
</property> </configuration>
<configuration> <!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-zhangxs.com</value>
</property>
<property>
//nodeManager上运行的附属服务,需要配置mapreduce_shuffle才可以运行mapreduce程序
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
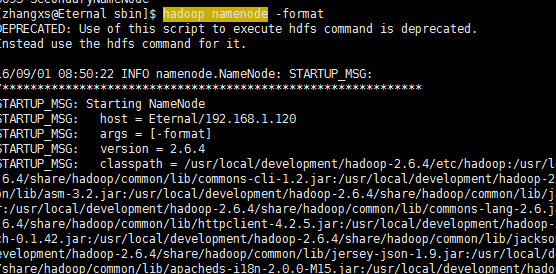
8-1:格式化hdfs文件系统(hadoop namenode -format)
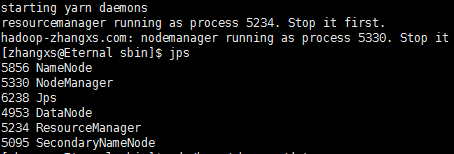
8-2:启动start.dsf.sh start yarn.sh
8-3:输入jps,查看运行进程
8-1 格式化hdfs文件系统(hadoop namenode -format)
8-2 启动start.dsf.sh start yarn.sh
8-3 输入jps,查看运行进程

http://192.168.177.124:50070 hdfs文件管理
http://192.168.177.124:8088 ResourceManager
-----------------------------------------------------------------------
如果页面访问不到,把linux的防火墙关闭
service iptables stop//这个只是暂时关闭,系统重启后失效
hadoop2.6.4 搭建伪分布式的更多相关文章
- hadoop(二)搭建伪分布式集群
前言 前面只是大概介绍了一下Hadoop,现在就开始搭建集群了.我们下尝试一下搭建一个最简单的集群.之后为什么要这样搭建会慢慢的分享,先要看一下效果吧! 一.Hadoop的三种运行模式(启动模式) 1 ...
- hadoop搭建伪分布式集群(centos7+hadoop-3.1.0/2.7.7)
目录: Hadoop三种安装模式 搭建伪分布式集群准备条件 第一部分 安装前部署 1.查看虚拟机版本2.查看IP地址3.修改主机名为hadoop4.修改 /etc/hosts5.关闭防火墙6.关闭SE ...
- centos7搭建伪分布式集群
centos7搭建伪分布式集群 需要 centos7虚拟机一台: jdk-linux安装包一个 hadoop-2.x安装包1个(推荐2.7.x) 一.设置虚拟机网络为静态IP(最好设成静态,为之后编程 ...
- 超详细!CentOS 7 + Hadoop3.0.0 搭建伪分布式集群
超详细!CentOS 7 + Hadoop3.0.0 搭建伪分布式集群 ps:本文的步骤已自实现过一遍,在正文部分避开了旧版教程在新版使用导致出错的内容,因此版本一致的情况下照搬执行基本不会有大错误. ...
- hadoop2.2.0 单机伪分布式(含64位hadoop编译) 及 eclipse hadoop开发环境搭建
hadoop中文镜像地址:http://mirrors.hust.edu.cn/apache/hadoop/core/hadoop-2.2.0/ 第一步,下载 wget 'http://archive ...
- Mac OS X上搭建伪分布式CDH版本Hadoop开发环境
最近在研究数据挖掘相关的东西,在本地 Mac 环境搭建了一套伪分布式的 hadoop 开发环境,采用CDH发行版本,省时省心. 参考来源 How-to: Install CDH on Mac OSX ...
- 搭建伪分布式 hadoop3.1.3 + zookeeper 3.5.7 + hbase 2.2.2
安装包 Hadoop 3.1.3 Zookeeper 3.5.7 Hbase 2.2.2 所需工具链接: 链接:https://pan.baidu.com/s/1jcenv7SeGX1gjPT9RnB ...
- Ubuntu-16.04-Desktop +Hadoop2.7.5+Eclipse-Neon的云计算开发环境的搭建(伪分布式方式)
主控终端 主机名 ubuntuhadoop.smartmap.com IP 192.168.1.60 Subnet mask 255.255.255.0 Gateway 192.168.1.1 DNS ...
- hadoop3.1.0 HDFS快速搭建伪分布式环境
1.环境准备 CenntOS7环境 JDK1.8-并配置好环境变量 下载Hadoop3.1.0二进制包到用户目录下 2.安装Hadoop 1.解压移动 #1.解压tar.gz tar -zxvf ha ...
随机推荐
- 10个常见的Node.js面试题
如果你希望找一份有关Node.js的工作,但又不知道从哪里入手评测自己对Node.js的掌握程度. 本文就为你罗列了10个常见的Node.js面试题,分别考察了Node.js编程相关的几个主要方面. ...
- Python迭代器,可迭代对象,生成器
迭代器 迭代器(iterator)有时又称游标(cursor)是程式设计的软件设计模式,可在容器物件(container,例如链表或阵列)上遍访的界面,设计人员无需关心容器物件的内存分配的实现细节. ...
- JQuery------分页插件下载地址
转载GitHub: https://github.com/pgkk/kkpager
- 矢量图绘制工具Svg-edit调整画布的大小
矢量图绘制工具Svg-edit调整画布的大小 ------------------------------ ------------------------
- 安装cocoapods及相关问题解决
申明:本博客大部分内容转载自简书http://www.jianshu.com/p/b64b4fd08d3c,但还有些问题博主在这里做了补充. Mac系统版本:10.12.1 一.什么是CocoaPod ...
- 使用sublime一键格式化XML文件
1 sublime简介 sublime是一款代码编辑和阅读软件,体积小,运行快,界面非常简洁漂亮.官方地址:https://www.sublimetext.com/ 2 在sublime上安装插件 使 ...
- PHP中Exception异常
异常的基本使用 当异常被抛出时,其后的代码不会继续执行,PHP 会尝试查找匹配的 "catch" 代码块. 如果异常没有被捕获,而且又没用使用 set_exception_hand ...
- Code Snippets 代码片段
Code Snippets 代码片段 1.Title : 代码片段的标题 2.Summary : 代码片段的描述文字 3.Platform : 可以使用代码片段的平台,有IOS/OS X/ ...
- NetBean 8 创建EJB
一. 介绍 百度了一下关于在NetBean开发环境里创建EJB的教程,没有找到好的例子,2天的调试过程,写下来帮助后人. EJB (Enterprise Java Bean) 是一套高扩展性的开发企业 ...
- FFT NNT
算算劳资已经多久没学新算法了,又要重新开始学辣.直接扔板子,跑...话说FFT算法导论里讲的真不错,去看下就懂了. //FFT#include <cstdio> #include < ...