hadoop2.6.4 搭建伪分布式
安装jdk1.7
http://www.cnblogs.com/zhangXingSheng/p/6228432.html
[root@node4 sysconfig]# more /etc/hosts
127.0.0.1 localhost
192.168.177.124 hadoop-node4.com node4
[root@node4 sysconfig]#
修改主机名
[root@node4 sysconfig]# more network
NETWORKING=yes
HOSTNAME=node4
[root@node4 sysconfig]#
配置hadoop环境变量(vi /etc/profile)
###############hadoop################
export HADOOP_HOME=/usr/local/development/hadoop-2.6.
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

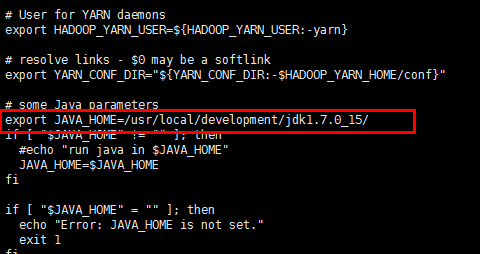
export JAVA_HOME=/usr/local/development/jdk1.7.0_15
[root@node4 hadoop]# more slaves
node4
[root@node4 hadoop]#

<configuration>
<property>
<name>hadoop.tmp.dir</name> //配置hadoop运行时临时文件的目录位置
<value>file:/home/zhangxs/data/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-zhangxs.com:9000</value>//配置nameNode的端口
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>//存储文件的副本数
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/zhangxs/data/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/zhangxs/data/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-zhangxs.com:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-zhangxs.com:19888</value>
</property> </configuration>
<configuration> <!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop-zhangxs.com</value>
</property>
<property>
//nodeManager上运行的附属服务,需要配置mapreduce_shuffle才可以运行mapreduce程序
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
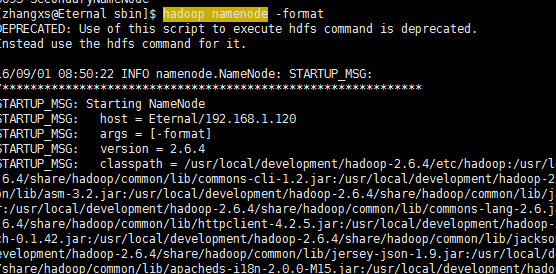
8-1:格式化hdfs文件系统(hadoop namenode -format)
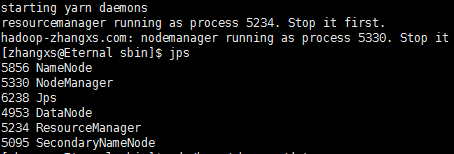
8-2:启动start.dsf.sh start yarn.sh
8-3:输入jps,查看运行进程
8-1 格式化hdfs文件系统(hadoop namenode -format)
8-2 启动start.dsf.sh start yarn.sh
8-3 输入jps,查看运行进程

http://192.168.177.124:50070 hdfs文件管理
http://192.168.177.124:8088 ResourceManager
-----------------------------------------------------------------------
如果页面访问不到,把linux的防火墙关闭
service iptables stop//这个只是暂时关闭,系统重启后失效
hadoop2.6.4 搭建伪分布式的更多相关文章
- hadoop(二)搭建伪分布式集群
前言 前面只是大概介绍了一下Hadoop,现在就开始搭建集群了.我们下尝试一下搭建一个最简单的集群.之后为什么要这样搭建会慢慢的分享,先要看一下效果吧! 一.Hadoop的三种运行模式(启动模式) 1 ...
- hadoop搭建伪分布式集群(centos7+hadoop-3.1.0/2.7.7)
目录: Hadoop三种安装模式 搭建伪分布式集群准备条件 第一部分 安装前部署 1.查看虚拟机版本2.查看IP地址3.修改主机名为hadoop4.修改 /etc/hosts5.关闭防火墙6.关闭SE ...
- centos7搭建伪分布式集群
centos7搭建伪分布式集群 需要 centos7虚拟机一台: jdk-linux安装包一个 hadoop-2.x安装包1个(推荐2.7.x) 一.设置虚拟机网络为静态IP(最好设成静态,为之后编程 ...
- 超详细!CentOS 7 + Hadoop3.0.0 搭建伪分布式集群
超详细!CentOS 7 + Hadoop3.0.0 搭建伪分布式集群 ps:本文的步骤已自实现过一遍,在正文部分避开了旧版教程在新版使用导致出错的内容,因此版本一致的情况下照搬执行基本不会有大错误. ...
- hadoop2.2.0 单机伪分布式(含64位hadoop编译) 及 eclipse hadoop开发环境搭建
hadoop中文镜像地址:http://mirrors.hust.edu.cn/apache/hadoop/core/hadoop-2.2.0/ 第一步,下载 wget 'http://archive ...
- Mac OS X上搭建伪分布式CDH版本Hadoop开发环境
最近在研究数据挖掘相关的东西,在本地 Mac 环境搭建了一套伪分布式的 hadoop 开发环境,采用CDH发行版本,省时省心. 参考来源 How-to: Install CDH on Mac OSX ...
- 搭建伪分布式 hadoop3.1.3 + zookeeper 3.5.7 + hbase 2.2.2
安装包 Hadoop 3.1.3 Zookeeper 3.5.7 Hbase 2.2.2 所需工具链接: 链接:https://pan.baidu.com/s/1jcenv7SeGX1gjPT9RnB ...
- Ubuntu-16.04-Desktop +Hadoop2.7.5+Eclipse-Neon的云计算开发环境的搭建(伪分布式方式)
主控终端 主机名 ubuntuhadoop.smartmap.com IP 192.168.1.60 Subnet mask 255.255.255.0 Gateway 192.168.1.1 DNS ...
- hadoop3.1.0 HDFS快速搭建伪分布式环境
1.环境准备 CenntOS7环境 JDK1.8-并配置好环境变量 下载Hadoop3.1.0二进制包到用户目录下 2.安装Hadoop 1.解压移动 #1.解压tar.gz tar -zxvf ha ...
随机推荐
- RocketMQ原理解析-NameServer
Namesrv名称服务,是没有状态可集群横向扩展. 1. 每个broker启动的时候会向namesrv注册 2. Producer发送消息的时候根据topic获取路由到broker的信息 3. Con ...
- 【JavaScript】ArtTemplate个人的使用体验。
据说ArtTemplate是腾讯的,感觉这东西真不错,使用方便,用起来很简单,哈哈.腾讯也不完全只是坑爹啊. ArtTemplate 使用是,正常引入js,这个自然不用说.这东西啥时候使用呢?我觉得这 ...
- IndexedDB(本地存储)
var students = [{ id: 1001, name: "Byron", age: 24 }, { id: 1002, name: "Frank", ...
- 命令行提交本地项目到github上
1.github账号要有. 2.配置ssh key ① defaults write com.apple.finder AppleShowAllFiles -bool true 终端 显示隐 ...
- 常用HTTP状态码和CURL 000问题
最近在测试CDN服务质量问题,测试过程中返回了一些不同的状态码,当然有一些常用的,也有一些不常用的.最奇葩的是在使用curl命令的时候出现000状态码,问了很多同事,对这个000的反应跟新事物是的 ...
- thinkphp疑难解决4
关于文件上传所涉及到的php.ini 中的一些配置: (以当前要设置的关键字开头...) 是每个上传文件所允许的大小, 默认的 upload_max_filesize = 2M, 如果超过了2M,_P ...
- leetcode笔记
82. Remove Duplicates from Sorted List II https://leetcode.com/problems/remove-duplicates-from-sorte ...
- Wrong list
1.背包dp[i][j]无论当前物品是否不大于j都可以转移dp[i-1][j] 2.循环从0开始还是1开始的问题 3.无向图边集数组开两倍 4.(3*987654321) > maxint 4. ...
- 弹框控件 UIAlertView UIActionSheet
// 创建弹框 从底部弹出,一般用于危险操作 UIActionSheet *sheet = [[UIActionSheet alloc] initWithTitle:@"恭喜通关" ...
- 前端构建工具之gulp(一)「图片压缩」
前端构建工具之gulp(一)「图片压缩」 已经很久没有写过博客了,现下终于事情少了,开始写博吧 今天网站要做一些优化:图片压缩,资源合并等 以前一直使用百度的FIS工具,但是FIS还没有提供图片压缩的 ...