机器学习classification_report方法及precision精确率和recall召回率 说明
classification_report简介
sklearn中的classification_report函数用于显示主要分类指标的文本报告.在报告中显示每个类的精确度,召回率,F1值等信息。
主要参数:
y_true:1维数组,或标签指示器数组/稀疏矩阵,目标值。
y_pred:1维数组,或标签指示器数组/稀疏矩阵,分类器返回的估计值。
labels:array,shape = [n_labels],报表中包含的标签索引的可选列表。
target_names:字符串列表,与标签匹配的可选显示名称(相同顺序)。
sample_weight:类似于shape = [n_samples]的数组,可选项,样本权重。
digits:int,输出浮点值的位数.
classification_report用法示例:
from sklearn.metrics import classification_report
y_true = [0, 1, 2, 2, 2]
y_pred = [0, 0, 2, 2, 1]
target_names = ['class 0', 'class 1', 'class 2']
print(classification_report(y_true, y_pred, target_names=target_names))
输出:
precision recall f1-score support
class 0 0.50 1.00 0.67 1
class 1 0.00 0.00 0.00 1
class 2 1.00 0.67 0.80 3
avg / total 0.70 0.60 0.61 5
其中列表左边的一列为分类的标签名,右边support列为每个标签的出现次数.avg / total行为各列的均值(support列为总和).
precision recall f1-score三列分别为各个类别的精确度/召回率及 F1 F1值.
精确度/召回率/F1值
精确度&召回率
精确度/召回率/F1值在<统计学习方法>和周志华的<机器学习>中都有详细介绍,以下参考维基百科中Precision and recall的说明:
如下图所示,假设有若干张图片,其中12张是狗的图片其余是猫的图片.现在利用程序去识别狗的图片,结果在识别出的8张图片中有5张是狗的图片,3张是猫的图片(属于误报).
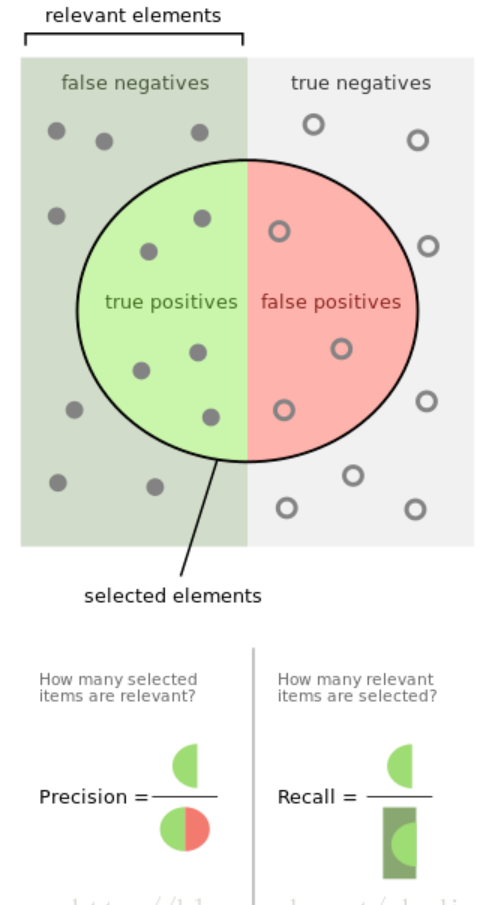
图中,实心小圆代表狗的图片,虚心小圆代表猫的图片,圆形区域代表识别结果.
则该程序的精度precision=5/8,召回率recall=5/12。
当一个搜索引擎返回30个页面时,只有20页是相关的,而没有返回40个额外的相关页面,其精度为20/30 = 2/3,而其召回率为20/60 = 1/3。在这种情况下,精确度是“搜索结果有多大用处”,而召回是“结果如何完整”。
F1 F1值
F1 F1值是精确度和召回率的调和平均值:
2F1=1P+1R 2F1=1P+1R
F1=2P×RP+R F1=2P×RP+R
精确度和召回率都高时, F1 F1值也会高. F1 F1值在1时达到最佳值(完美的精确度和召回率),最差为0.在二元分类中, F1 F1值是测试准确度的量度。
示例说明:
from sklearn.metrics import classification_report
y_true = [0, 1, 2, 2, 2]
y_pred = [0, 0, 2, 2, 1]
print(classification_report(y_true, y_pred))
输出:
precision recall f1-score support
0 0.50 1.00 0.67 1
1 0.00 0.00 0.00 1
2 1.00 0.67 0.80 3
avg / total 0.70 0.60 0.61 5
其中
| 真实值 | 预测值 |
|---|---|
| 0 | 0 |
| 1 | 0 |
| 2 | 2 |
| 2 | 2 |
| 2 | 1 |
对示例程序中的结果:
precision recall f1-score support 0 0.50 1.00 0.67 1
1 0.00 0.00 0.00 1
2 1.00 0.67 0.80 3
第一行的计算:
即0的预测情况:真实值中有1个0,预测值中有2个0,其中1个预测正确,1个预测错误.如图所示:
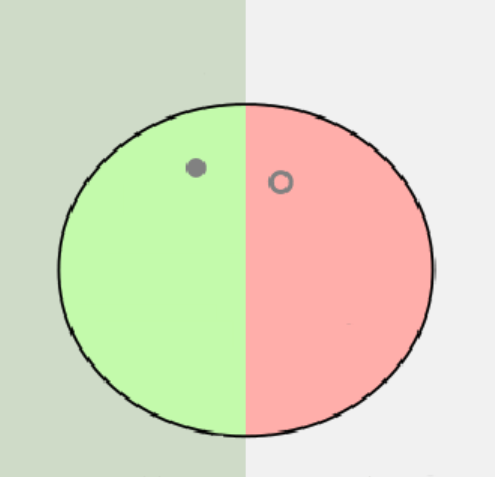
则,
P=12=0.5 P=12=0.5
R=11=1 R=11=1
F1=212×112+1=0.67 F1=212×112+1=0.67
第二行的计算:
即1的预测情况:真实值中有1个1,预测值中有1个1,且预测错误.如图所示:

则,
P=01=0 P=01=0
R=01=0 R=01=0
F1=0 F1=0
第三行的计算:
即2的预测情况:真实值中有3个2,预测值中有2个2,且预测正确.如图所示:
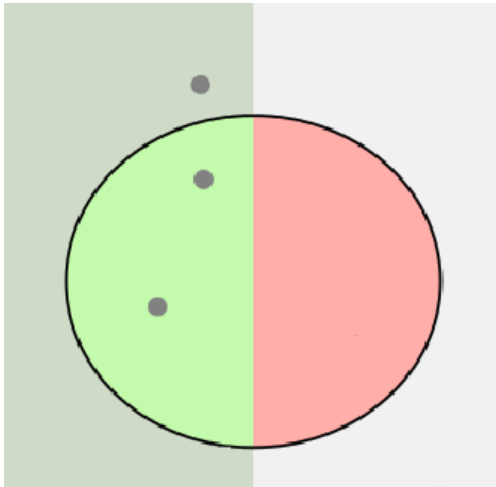
则,
P=22=1 P=22=1
R=23=0.67 R=23=0.67
F1=21×231+23+=0.8
机器学习classification_report方法及precision精确率和recall召回率 说明的更多相关文章
- 分类的性能评估:准确率、精确率、Recall召回率、F1、F2
import numpy as np import pandas as pd from sklearn.feature_extraction.text import TfidfVectorizer f ...
- Recall(召回率);Precision(准确率);F1-Meature(综合评价指标);true positives;false positives;false negatives.
Recall(召回率);Precision(准确率);F1-Meature(综合评价指标);在信息检索(如搜索引擎).自然语言处理和检测分类中经常会使用这些参数. Precision:被检测出来的信息 ...
- Recall(召回率);Precision(准确率);F1-Meature(综合评价指标);true positives;false positives;false negatives..
转自:http://blog.csdn.net/t710smgtwoshima/article/details/8215037 Recall(召回率);Precision(准确率);F1-Meat ...
- 混淆矩阵、准确率、精确率/查准率、召回率/查全率、F1值、ROC曲线的AUC值
准确率.精确率(查准率).召回率(查全率).F1值.ROC曲线的AUC值,都可以作为评价一个机器学习模型好坏的指标(evaluation metrics),而这些评价指标直接或间接都与混淆矩阵有关,前 ...
- 精确率precession和召回率recall
假设有两类样本,A类和B类,我们要衡量分类器分类A的能力. 现在将所有样本输入分类器,分类器从中返回了一堆它认为属于A类的样本. 召回率:分类器认为属于A类的样本里,真正是A类的样本数,占样本集中所有 ...
- 准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure
yu Code 15 Comments 机器学习(ML),自然语言处理(NLP),信息检索(IR)等领域,评估(Evaluation)是一个必要的 工作,而其评价指标往往有如下几点:准确率(Accu ...
- 准确率(accuracy),精确率(Precision),召回率(Recall)和综合评价指标(F1-Measure )----转
原文:http://blog.csdn.net/t710smgtwoshima/article/details/8215037 Recall(召回率);Precision(准确率);F1-Meat ...
- 机器学习 F1-Score 精确率 - P 准确率 -Acc 召回率 - R
准确率 召回率 精确率 : 准确率->accuracy, 精确率->precision. 召回率-> recall. 三者很像,但是并不同,简单来说三者的目的对象并不相同. 大多时候 ...
- 准确率(Accuracy), 精确率(Precision), 召回率(Recall)和F1-Measure(对于二分类问题)
首先我们可以计算准确率(accuracy),其定义是: 对于给定的测试数据集,分类器正确分类的样本数与总样本数之比.也就是损失函数是0-1损失时测试数据集上的准确率. 下面在介绍时使用一下例子: 一个 ...
随机推荐
- CentOS 安装 linux kernel 源码
原文链接:https://blog.csdn.net/qaz1qaz1qaz2/article/details/52825389 1.下载系统包yum install rpm-buildyum ins ...
- 廖雪峰Python学习笔记——类和实例
Class MyList(list): __metaclass__ = ListMetaclass #它表示在创建MyList这个类时,必须通过 ListMetaclass这个元类的LIstMetac ...
- 双向链表的实现——c++
c++实现双向链表 : #ifndef DOUBLE_LINK_HXX #define DOUBLE_LINK_HXX #include <iostream> using namespac ...
- python爬虫2——下载文件(中华网图片库下载)
# -*- coding: utf-8 -*- import requests import re import sys reload(sys) sys.setdefaultencoding('utf ...
- Flask从入门到精通之数据模型之间的关系
关系型数据库使用关系把不同表中的行联系起来.上篇随笔中介绍的用户和角色之间是一种简单的关系.即角色到用户的一对多关系,因为一个角色可属于多个用户,而每个用户都只能有一个角色.这种关系在模型中的表示方法 ...
- 简单HOG+SVM mnist手写数字分类
使用工具 :VS2013 + OpenCV 3.1 数据集:minst 训练数据:60000张 测试数据:10000张 输出模型:HOG_SVM_DATA.xml 数据准备 train-images- ...
- 【bzoj4259】 残缺的字符串 FFT
又是一道FFT套路题 思路可以参考bzoj4503,题解 我们对串S和串T中出现的*处全部赋值为0. 反正最终的差异度式子大概就是 $C[i]=\sum_{j=0}^{|T|-1}S[i+j]T[j] ...
- 【ROS系列】使用QT编写ROS订阅、发布程序
Linux下一直使用QT进行开发,支持cmake使得很容易导入其他工程.学习ROS过程中,很多函数名称难记,使用QT不仅可以提示补全,还为了以后开发GUI方便吧. 1.安装ros_qtc_plugin ...
- js的事件学习笔记
目录 0.参考 1.事件流 冒泡传播 事件捕获 2.事件绑定--onclick接口 onclick类的接口,只能注册一个同类事件 onclick类的接口,使用button.onclick = null ...
- (转)LINUX CENTOS7下安装PYTHON
LINUX CENTOS7下安装PYTHON 原文:http://www.cnblogs.com/lclq/p/5620196.html Posted on 2016-06-27 14:58 南宫羽香 ...