【Java基础专题】编码与乱码(05)---GBK与UTF-8之间的转换
原文出自:http://www.blogjava.net/pengpenglin/archive/2010/02/22/313669.html
在很多论坛、网上经常有网友问“ 为什么我使用 new String(tmp.getBytes("ISO-8859-1"), "UTF-8") 或者 new String(tmp.getBytes("ISO-8859-1"), "GBK")可以得到正确的中文,但是使用
new String(tmp.getBytes("GBK"), "UTF-8") 却不能将GBK转换成UTF-8呢?”
参考前面的【Java基础专题】编码与乱码(03)----String的toCharArray()方法测试一文,我们就知道原因了。因为如果客户端使用GBK、UTF-8编码,编码后的字节经过ISO-8859-1传输,再用原来相同的编码方式进行解码,这个过程是“无损的转换”----
因为原始和最终的编码方式相同。
但是如果客户端使用GBK编码,到了服务器端要转换成UTF-8,或者相反的过程。想一想,字节还是那些字节,但是编码的规则变了。原来GBK编码后的4个字节要用UTF-8的每个字符3个字节的规则编码,怎么能不乱码呢?
所以从现在开始,不要再犯这种错误了。new String(tmp.getBytes("GBK"), "UTF-8") 这个过程,JVM内部是不会帮你自动对字节进行扩展以适应UTF-8的编码的。正确的方法应该是根据UTF-8的编码规则进行字节的扩充,即手动从2个字节变成3个字节,然后再转换成十六进制的UTF-8编码。
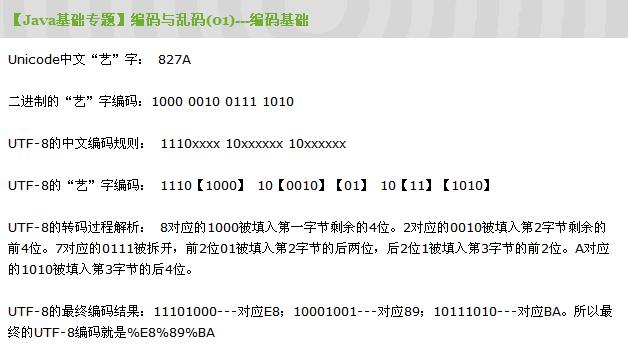
在这个专题的第一篇文章【Java基础专题】编码与乱码(01)---编码基础开头,我们就已经介绍了这个规则:
①得到每个字符的2进制GBK编码
②将该16进制的GBK编码转换成2进制的字符串(2个字节)
③分别在字符串的首位插入110,在第9位插入10,在第17位插入10三个字符串,得到3个字节
④将这3个字节分别转换成16进制编码,得到最终的UTF-8编码。
下面给出一个从网络上得到的Java转码方法,原文链接见:http://jspengxue.javaeye.com/blog/40781。下面的代码做了小小的修改
 package example.encoding;
package example.encoding; /**
/** * The Class CharacterEncodeConverter.
* The Class CharacterEncodeConverter. */public class CharacterEncodeConverter {
*/public class CharacterEncodeConverter { /** * The main method. * * @param args the arguments
/** * The main method. * * @param args the arguments */ public static void main(String[] args) { try { CharacterEncodeConverter convert = new CharacterEncodeConverter(); byte[] fullByte = convert.gbk2utf8("中文"); String fullStr = new String(fullByte, "UTF-8"); System.out.println("string from GBK to UTF-8 byte: " + fullStr); } catch (Exception e) { e.printStackTrace(); } } /** * Gbk2utf8. * * @param chenese the chenese * * @return the byte[] */ public byte[] gbk2utf8(String chenese) { // Step 1: 得到GBK编码下的字符数组,一个中文字符对应这里的一个c[i] char c[] = chenese.toCharArray(); // Step 2: UTF-8使用3个字节存放一个中文字符,所以长度必须为字符的3倍 * c.length]; // Step 3: 循环将字符的GBK编码转换成UTF-8编码; i < c.length; i++) { // Step 3-1:将字符的ASCII编码转换成2进制值 int m = (int) c[i]; String word = Integer.toBinaryString(m); System.out.println(word); // Step 3-2:将2进制值补足16位(2个字节的长度) StringBuffer sb = new StringBuffer(); - word.length(); ; j < len; j++) { sb.append("); } // Step 3-3:得到该字符最终的2进制GBK编码 // 形似:1000 0010 0111 1010 sb.append(word); // Step 3-4:最关键的步骤,根据UTF-8的汉字编码规则,首字节 // 以1110开头,次字节以10开头,第3字节以10开头。在原始的2进制 // 字符串中插入标志位。最终的长度从16--->16+3+2+2=24。"); sb.insert("); sb.insert("); System.out.println(sb.toString()); // Step 3-5:将新的字符串进行分段截取,截为3个字节); String s2 ); String s3 ); // Step 3-6:最后的步骤,把代表3个字节的字符串按2进制的方式 // 进行转换,变成2进制的整数,再转换成16进制值).byteValue(); ).byteValue(); ).byteValue(); // Step 3-7:把转换后的3个字节按顺序存放到字节数组的对应位置]; bf[] = b0; bf[] = b1; bf[] = b2; fullByte[i ]; fullByte[i ]; fullByte[i ]; // Step 3-8:返回继续解析下一个中文字符 } return fullByte; }}
*/ public static void main(String[] args) { try { CharacterEncodeConverter convert = new CharacterEncodeConverter(); byte[] fullByte = convert.gbk2utf8("中文"); String fullStr = new String(fullByte, "UTF-8"); System.out.println("string from GBK to UTF-8 byte: " + fullStr); } catch (Exception e) { e.printStackTrace(); } } /** * Gbk2utf8. * * @param chenese the chenese * * @return the byte[] */ public byte[] gbk2utf8(String chenese) { // Step 1: 得到GBK编码下的字符数组,一个中文字符对应这里的一个c[i] char c[] = chenese.toCharArray(); // Step 2: UTF-8使用3个字节存放一个中文字符,所以长度必须为字符的3倍 * c.length]; // Step 3: 循环将字符的GBK编码转换成UTF-8编码; i < c.length; i++) { // Step 3-1:将字符的ASCII编码转换成2进制值 int m = (int) c[i]; String word = Integer.toBinaryString(m); System.out.println(word); // Step 3-2:将2进制值补足16位(2个字节的长度) StringBuffer sb = new StringBuffer(); - word.length(); ; j < len; j++) { sb.append("); } // Step 3-3:得到该字符最终的2进制GBK编码 // 形似:1000 0010 0111 1010 sb.append(word); // Step 3-4:最关键的步骤,根据UTF-8的汉字编码规则,首字节 // 以1110开头,次字节以10开头,第3字节以10开头。在原始的2进制 // 字符串中插入标志位。最终的长度从16--->16+3+2+2=24。"); sb.insert("); sb.insert("); System.out.println(sb.toString()); // Step 3-5:将新的字符串进行分段截取,截为3个字节); String s2 ); String s3 ); // Step 3-6:最后的步骤,把代表3个字节的字符串按2进制的方式 // 进行转换,变成2进制的整数,再转换成16进制值).byteValue(); ).byteValue(); ).byteValue(); // Step 3-7:把转换后的3个字节按顺序存放到字节数组的对应位置]; bf[] = b0; bf[] = b1; bf[] = b2; fullByte[i ]; fullByte[i ]; fullByte[i ]; // Step 3-8:返回继续解析下一个中文字符 } return fullByte; }}最终的测试结果是正确的:string from GBK to UTF-8 byte: 中文。
但是这个方法并不是完美的!要知道这个规则只对中文起作用,如果传入的字符串中包含有单字节字符,如a+3中文,那么解析的结果就变成:string from GBK to UTF-8 byte: ?????????中文了。为什么呢?道理很简单,这个方法对原本在UTF-8中应该用单字节表示的数字、英文字符、符号都变成3个字节了,所以这里有9个?,代表被转换后的a、+、3字符。
所以要让这个方法更加完美,最好的方法就是加入对字符Unicode区间的判断
| UCS-2编码(16进制) | UTF-8 字节流(二进制) |
| 0000 - 007F | 0xxxxxxx |
| 0080 - 07FF | 110xxxxx 10xxxxxx |
| 0800 - FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
汉字的Unicode编码范围为\u4E00-\u9FA5 \uF900-\uFA2D,如果不在这个范围内就不是汉字了。
【UTF-8转GBK】
道理和上面的相同,只是一个逆转的过程,不多说了
但是最终的建议还是:能够统一编码就统一编码吧!要知道编码的转换是相当的耗时的工作
【Java基础专题】编码与乱码(05)---GBK与UTF-8之间的转换的更多相关文章
- 编码与乱码(05)---GBK与UTF-8之间的转换--转载
原文地址:http://www.blogjava.net/pengpenglin/archive/2010/02/22/313669.html [GBK转UTF-8] 在很多论坛.网上经常有网友问“ ...
- Java基础专题
Java后端知识点汇总——Java基础专题 全套Java知识点汇总目录,见https://www.cnblogs.com/autism-dong/p/11831922.html 1.解释下什么是面向对 ...
- C语言实现GBK/GB2312/五大码之间的转换(转)
源:C语言实现GBK/GB2312/五大码之间的转换 //----------------------------------------------------------------------- ...
- Java基础——字符编码
一.ASII 美国(国家)信息交换标准(代)码. 计算机中只有数字,一切都是用数字表示,屏幕上显示的一个一个的字符也不例外. 一个字节可表示的数字为0-255,足以显示键盘上的所有的字符 例如. a ...
- java基础52 编码与解码
1.解码与编码的含义 编码:把看得懂的字符变成看不懂的码值,这个过程就叫编码 解码:根据码值查到相对应的字符,我们把这个过程就叫解码 注意:编码与解码时,我们一般使用统一的码表,否则非常容易出现 ...
- Java基础知识强化之IO流笔记37:FileReader/FileWriter(转换流的子类)复制文本文件案例
1. 转换流的简化写法: 由于我们常见的操作都是使用本地默认编码,所以,不用指定编码.而转换流的名称有点长,所以,Java就提供了其子类供我们使用:FileReader / FileWriterOut ...
- Java 基础入门随笔(2) JavaSE版——关键字、进制转换、类型转换
1.Java语言-关键字 关键字:被java语言赋予了特殊含义的词,特点是所有的字母都为小写. java涉及到的关键字整理: 用于定义数据类型的关键字 class interface byte sho ...
- java基础面试题:如何把一段逗号分割的字符串转换成一个数组? String s = "a" +"b" + "c" + "d";生成几个对象?
package com.swift; public class Douhao_String_Test { public static void main(String[] args) { /* * 如 ...
- Java中long(Long)与int(Integer)之间的转换(转)
一.将long型转化为int型,这里的long型是基础类型: long a = 10; int b = (int)a; 二.将Long型转换为int型,这里的Long型是包装类型: Long a = ...
随机推荐
- unity脚本生命流程
渲染 OnPreCull: 在相机剔除场景之前调用此函数.相机可见的对象取决于剔除.OnPreCull 函数调用发生在剔除之前. OnBecameVisible/OnBecameInvisible: ...
- Announcing the Release of ASP.NET MVC 5.1, ASP.NET Web API 2.1 and ASP.NET Web Pages 3.1 for VS2012
The NuGet packages for ASP.NET MVC 5.1, ASP.NET Web API 2.1 and ASP.NET Web Pages 3.1 are now live o ...
- 解决:TypeError: 'list' object is not callable
如果list变量和list函数重名,会有什么后果呢?我们可以参考如下代码: list = ['泡芙', '汤圆', '鱼儿', '骆驼'] tup_1 = (1, 2, 3, 4, 5) tupToL ...
- Python爬虫之BeautifulSoup的用法
之前看静觅博客,关于BeautifulSoup的用法不太熟练,所以趁机在网上搜索相关的视频,其中一个讲的还是挺清楚的:python爬虫小白入门之BeautifulSoup库,有空做了一下笔记: 一.爬 ...
- Django-form补充
Django_form补充 问题1: 注册页面输入为空,报错:keyError:找不到password def clean(self): print("---",self.cle ...
- MAMP软件的安装和使用
MAMP Pro软件是一款很好的在MAC下面运行的网站集成环境软件,功能强大,配置简单,十分便于本地调试,其由Apache+MySQL+PHP+动态DNS配置构成,PHP的版本可以动态切换到最新版.无 ...
- Python 3.5 socket OSError: [Errno 101] Network is unreachable
/******************************************************************************** * Python 3.5 socke ...
- 《zero to one》读后感
五一放假,赶上下雨,天气很凉爽,这种天气很舒服,不冷不热,听着滴答的雨声,看看书其实也不错. 约了两个同学吃了顿饭,然后决定窝在实验室了,最近看了彼得.蒂尔的<zero to one>,确 ...
- poj2336
题目大意:一个船要把n个车渡过河 船最多载m辆车 把车运过去需要t的时间 回来也要t的时间 给定n辆车依次到河边的时间 求最短运送时间 还有最短跑几趟 一维dp 可以直接d运送时间 dp[i] ...
- 最终还是选择了markdownpad2
markdownpad2使用 最终 哈哈,最后还是选择了markdownpad2,经过探索才知道这个玩意多么好用. 点击,下载. 碰到的问题 1.win10出现HTML无法渲染得对话框 结果是,官网有 ...