python接口自动化4-绕过验证码登录(cookie)【转载】
本篇转自博客:上海-悠悠
原文地址:http://www.cnblogs.com/yoyoketang/tag/python%E6%8E%A5%E5%8F%A3%E8%87%AA%E5%8A%A8%E5%8C%96/
前言
有些登录的接口会有验证码:短信验证码,图形验证码等,这种登录的话验证码参数可以从后台获取的(或者查数据库最直接)。
获取不到也没关系,可以通过添加cookie的方式绕过验证码。
一、抓登录cookie
1.登录后会生成一个已登录状态的cookie,那么只需要直接把这个值添加到cookies里面就可以了。
2.可以先手动登录一次,然后抓取这个cookie,这里就需要用抓包工具fiddler了
3.先打开博客园登录界面,手动输入账号和密码(勾选下次自动登录)
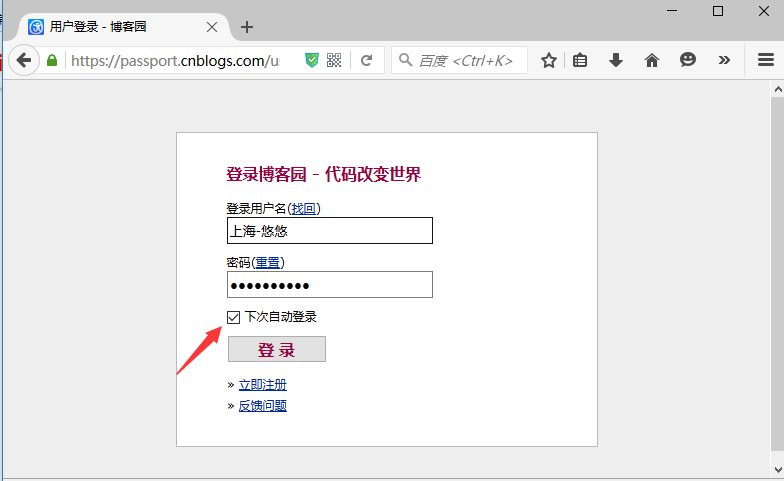
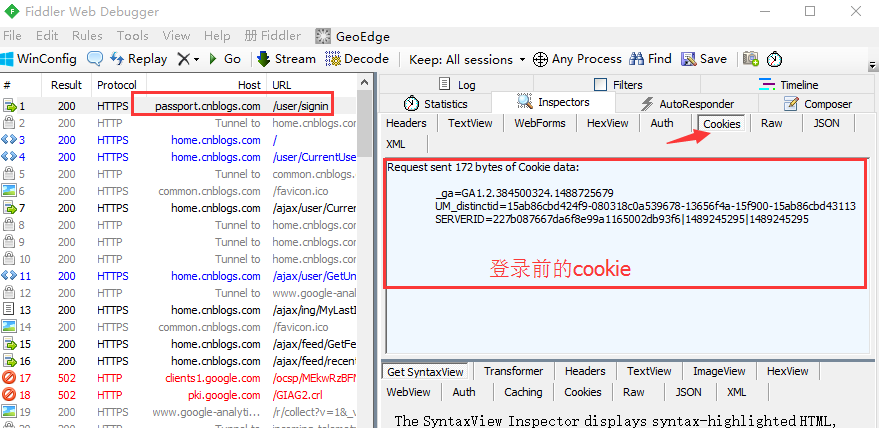
4.打开fiddler抓包工具,刷新下登录首页,就是登录前的cookie了
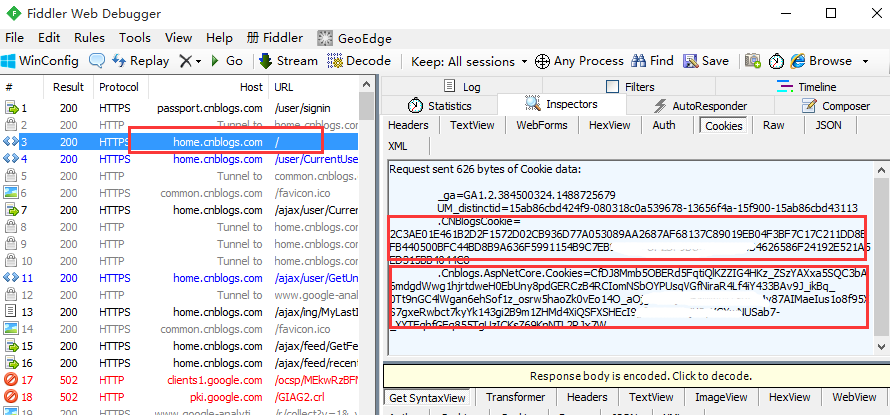
5.登录成功后,再查看cookie变化,发现多了两组参数,多的这两组参数就是我们想要的,copy出来,一会有用
二、cookie组成结构
1.用抓包工具fidller只能看到cookie的name和value两个参数,实际上cookie还有其它参数
2.以下是一个完整的cookie组成结构
cookie ={u'domain': u'.cnblogs.com',
u'name': u'.CNBlogsCookie',
u'value': u'xxxx',
u'expiry': 1491887887,
u'path': u'/',
u'httpOnly': True,
u'secure': False}
name:cookie的名称
value:cookie对应的值,动态生成的
domain:服务器域名
expiry:Cookie有效终止日期
path:Path属性定义了Web服务器上哪些路径下的页面可获取服务器设置的Cookie
httpOnly:防脚本攻击
secure:在Cookie中标记该变量,表明只有当浏览器和Web Server之间的通信协议为加密认证协议时,
浏览器才向服务器提交相应的Cookie。当前这种协议只有一种,即为HTTPS。
三、添加cookie
1.往session里面添加cookie可以用以下方式
2.set里面参数按括号里面的参数格式
coo = requests.cookies.RequestsCookieJar()
coo.set('cookie-name', 'cookie-value', path='/', domain='.xxx.com')
s.cookies.update(c)
3.于是添加登录的cookie,把第一步fiddler抓到的内容填进去就可以了
c = requests.cookies.RequestsCookieJar()
c.set('.CNBlogsCookie', 'xxx')
c.set('.Cnblogs.AspNetCore.Cookies','xxx')
s.cookies.update(c)
print(s.cookies)
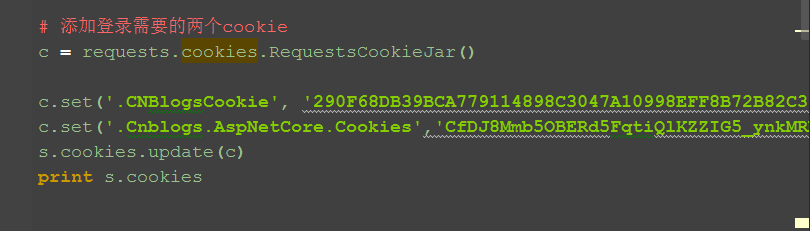
4.(敲黑板!!!)由于近期博客园的登录机制变了,这里需要多加2个cookie参数
c.set('AlwaysCreateItemsAsActive',"True")
c.set('AdminCookieAlwaysExpandAdvanced',"True")
四、参考代码
1.由于登录时候是多加2个cookie,我们可以先用get方法打开登录首页,获取部分cookie
2.再把登录需要的cookie添加到session里
3.添加成功后,随便编辑正文和标题保存到草稿箱
# coding:utf-8
import requests
# 先打开登录首页,获取部分cookie
url = "https://passport.cnblogs.com/user/signin"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0"
} # get方法其它加个ser-Agent就可以了
s = requests.session()
r = s.get(url, headers=headers,verify=False)
print s.cookies
# 添加登录需要的两个cookie
c = requests.cookies.RequestsCookieJar()
c.set('.CNBlogsCookie', '这里是抓到的') # 填上面抓包内容
c.set('.Cnblogs.AspNetCore.Cookies','这里是抓到的') # 填上面抓包内容
c.set('AlwaysCreateItemsAsActive',"True")
c.set('AdminCookieAlwaysExpandAdvanced',"True")
s.cookies.update(c)
print s.cookies
# 登录成功后保存编辑内容
r1 = s.get("https://i.cnblogs.com/EditPosts.aspx?opt=1", headers=headers, verify=False)
# 保存草稿箱
url2= "https://i.cnblogs.com/EditPosts.aspx?opt=1"
body = {"__VIEWSTATE": "",
"__VIEWSTATEGENERATOR":"FE27D343",
"Editor$Edit$txbTitle":"这是3111",
"Editor$Edit$EditorBody":"<p>这里111:http://www.cnblogs.com/yoyoketang/</p>",
"Editor$Edit$Advanced$ckbPublished":"on",
"Editor$Edit$Advanced$chkDisplayHomePage":"on",
"Editor$Edit$Advanced$chkComments":"on",
"Editor$Edit$Advanced$chkMainSyndication":"on",
"Editor$Edit$Advanced$txbEntryName":"",
"Editor$Edit$Advanced$txbExcerpt":"",
"Editor$Edit$Advanced$tbEnryPassword":"",
"Editor$Edit$lkbDraft":"存为草稿",
}
r2 = s.post(url2, data=body, verify=False)
print r.content
python接口自动化4-绕过验证码登录(cookie)【转载】的更多相关文章
- python接口自动化-Cookie_绕过验证码登录
前言 有些登录的接口会有验证码,例如:短信验证码,图形验证码等,这种登录的验证码参数可以从后台获取(或者最直接的可查数据库) 获取不到也没关系,可以通过添加Cookie的方式绕过验证码 前面在“pyt ...
- python接口自动化:绕过验证码登录
上线产品的登录接口会有验证码,一般可以通过添加cookie的方式绕过验证码. 一.抓登录的cookie 1. 先手动登录一次,然后用fiddler抓取这个cookie,再直接把这个值添加到cookie ...
- python接口自动化4-绕过验证码登录(cookie)
前言 有些登录的接口会有验证码:短信验证码,图形验证码等,这种登录的话验证码参数可以从后台获取的(或者查数据库最直接). 获取不到也没关系,可以通过添加cookie的方式绕过验证码. 一.抓登录coo ...
- python接口自动化4-绕过验证码登录(cookie) (转载)
前言 有些登录的接口会有验证码:短信验证码,图形验证码等,这种登录的话验证码参数可以从后台获取的(或者查数据库最直接). 获取不到也没关系,可以通过添加cookie的方式绕过验证码. 一.抓登录coo ...
- python接口自动化23-token参数关联登录(登录拉勾网)
前言 登录网站的时候,经常会遇到传token参数,token关联并不难,难的是找出服务器第一次返回token的值所在的位置,取出来后就可以动态关联了 登录拉勾网 1.先找到登录首页https://pa ...
- python接口自动化26-发xml格式post请求《转载》
python接口自动化26-发xml格式post请求 https://cloud.tencent.com/developer/article/1164987
- python接口自动化12-案例分析(csrfToken)【转载】
前言: 有些网站的登录方式跟前面讲的博客园和token登录会不一样,把csrfToken放到cookie里,登录前后cookie是没有任何变化的,这种情况下如何绕过前端的验证码登录呢? 一.登录前后对 ...
- python接口自动化-token参数关联登录(二)
原文地址https://www.cnblogs.com/yoyoketang/p/9098096.html 原文地址https://www.cnblogs.com/yoyoketang/p/68866 ...
- python接口自动化-token参数关联登录(登录拉勾网)
前言 登录网站的时候,经常会遇到传token参数,token关联并不难,难的是找出服务器第一次返回token的值所在的位置,取出来后就可以动态关联了 登录拉勾网 1.先找到登录首页https://pa ...
随机推荐
- linux centos7--linux和window共享文件(samba)
这里以VMWARE与主控真机来做实现实现 由于SMB在centos中自带,所以,无需像网上说的样子,要这删除,那卸载,直接搜索是否存在SAMBA的安装文件 一 查询包是否存在 [root@localh ...
- JSONP解决跨域完整例子
1.这个案例是仿照百度搜索,输入关键词,会出现下拉菜单的过程. 效果: 2.具体做法: (1)利用百度的数据库做script标签的src. 复制之后的地址是这样的 https://sp0.baidu. ...
- 后端接口迁移(从 webapi 到 openapi)前端经验总结
此文已由作者张磊授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 前情提要 以前用的是 webapi 现在统一切成 openapi,字段结构统统都变了 接入接口 20+,涉及模 ...
- codility
// you can also use imports, for example: // import java.util.*; // you can write to stdout for debu ...
- 《Cracking the Coding Interview》——第11章:排序和搜索——题目6
2014-03-21 21:50 题目:给定一个MxN的二位数组,如果每一行每一列都是升序排列(不代表全展开成一个一维数组仍是升序排列的).请设计一个算法在其中查找元素. 解法:对于这么一个数组,有两 ...
- PC端网站转换为webApp工具
百度开发云site App:http://siteapp.baidu.com/
- node express 登录拦截器 request接口请求
1.拦截器 拦截器可以根据需要 做权限拦截 登录只是权限的一种, 思路是req.session.user判断用户session是否存在,是否是需要拦截的地址, 如果是就跳转登录页,或其他页, 如果非需 ...
- Centos/linux开放端口
在linux上部署tomcat发现外部无法访问可以通过两种方式解决: 1.关闭防火墙 service iptables stop(不推荐) 2.修改相关文件,开放需要开放的端口 (1)通过命令vi / ...
- 一个初学者的辛酸路程-依旧Django
回顾: 1.Django的请求声明周期? 请求过来,先到URL,URL这里写了一大堆路由关系映射,如果匹配成功,执行对应的函数,或者执行类里面对应的方法,FBV和CBV,本质上返回的内容都是字符串 ...
- 1020 Tree Traversals (25 分)(二叉树的遍历)
给出一个棵二叉树的后序遍历和中序遍历,求二叉树的层序遍历 #include<bits/stdc++.h> using namespace std; ; int in[N]; int pos ...