[转载]NoSQL by Martin Flower
URL1 nosql
In 2006, my colleague Neal Ford coined the term Polyglot Programming, to express the idea that applications should be written in a mix of languages to take advantage of the fact that different languages are suitable for tackling different problems. Complex applications combine different types of problems, so picking the right language for the job may be more productive than trying to fit all aspects into a single language.
Over the last few years there's been an explosion of interest in new languages, particularly functional languages, and I'm often tempted to spend some time delving into Clojure, Scala, Erlang, or the like. But my time is limited and I'm giving a higher priority to another, more significant shift, that of the DatabaseThaw. The first drips have been coming through from clients and other contacts and the prospects are enticing. I'm confident to say that if you starting a new strategic enterprise application you should no longer be assuming that your persistence should be relational. The relational option might be the right one - but you should seriously look at other alternatives.
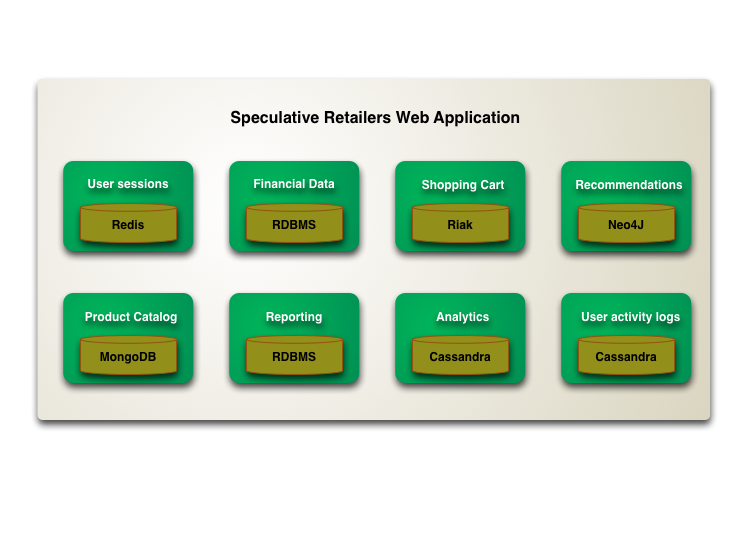
One of the interesting consequences of this is that we are gearing up for a shift to polyglot persistence [1] - where any decent sized enterprise will have a variety of different data storage technologies for different kinds of data. There will still be large amounts of it managed in relational stores, but increasingly we'll be first asking how we want to manipulate the data and only then figuring out what technology is the best bet for it.
This polyglot affect will be apparent even within a single application[2]. A complex enterprise application uses different kinds of data, and already usually integrates information from different sources. Increasingly we'll see such applications manage their own data using different technologies depending on how the data is used. This trend will be complementary to the trend of breaking up application code into separate components integrating through web services. A component boundary is a good way to wrap a particular storage technology chosen for the way its data in manipulated.
This will come at a cost in complexity. Each data storage mechanism introduces a new interface to be learned. Furthermore data storage is usually a performance bottleneck, so you have to understand a lot about how the technology works to get decent speed. Using the right persistence technology will make this easier, but the challenge won't go away.
Many of these NoSQL option involve running on large clusters. This introduces not just a different data model, but a whole range of new questions about consistency and availability. The transactional single point of truth will no longer hold sway (although its role as such has often been illusory).
So polyglot persistence will come at a cost - but it will come because the benefits are worth it. When relational databases are used inappropriately, they exert a significant drag on application development. I was recently talking to a team whose application was essentially composing and serving web pages. They only looked up page elements by ID, they had no need for transactions, and no need to share their database. A problem like this is much better suited to a key-value store than the corporate relational hammer they had to use. A good public example of using the right NoSQL choice for the job is The Guardian - who have felt a definite productivity gain from using MongoDB over their previous relational option.
Another benefit comes in running over a cluster. Scaling to lots of traffic gets harder and harder to do with vertical scaling - a fact we've known for a long time. Many NoSQL databases are designed to operate over clusters and can tackle larger volumes of traffic and data than is realistic with single server. As enterprises look to use data more, this kind of scaling will become increasingly important. The Danish medication system described at gotoAarhus2011 was a good example of this.
All of this leads to a big change, but it won't be rapid one - companies are naturally conservative when it comes to their data storage.
The more immediate question is which types of projects should consider an alternative persistence model? My thinking is that firstly you should only consider projects that are at the strategic end of the UtilityVsStrategicDichotomy. That's because utility projects don't have enough benefit to be worth a new technology.
Given a strategic project, you then have two drivers that raise alternatives: either reducing development drag or dealing with intensive data needs. Even here I suspect many projects, probably a majority, are better off sticking with the relational orthodoxy. But the minority that shouldn't is a significant one.
One factor that is perhaps less important is whether the project is new, or already established. The Guardian's shift to MongoDB has been happening over the last year or so on a code base developed several years ago. Polyglot persistence is something you can introduce on an existing code base.
What all of this means is that if you're working in the enterprise application world, now is the time to start familiarizing yourself with alternative data storage options. This won't be a fast revolution, but I do believe the next decade will see the database thaw progress rapidly.
Notes
1: As far as I can tell, Scott Leberknight was the first person to start using the term "polyglot persistence".
2: Don't take the example in the diagram too seriously. I'm not making any recommendations about which database technology to use for what kind of service. But I do think that people should consider these kinds of technologies as part of application architecture.
1 Why NoSQL?
- Relational databases have been a successful technology for twenty years, providing persistence, concurrency control, and an integration mechanism.
- Application developers have been frustrated with the impedance mismatch between the relational model and the in-memory data structures.
- There is a movement away from using databases as integration points towards encapsulating databases within applications and integrating through services.
- The vital factor for a change in data storage was the need to support large volumes of data by running on clusters. Relational databases are not designed to run efficiently on clusters.
- NoSQL is an accidental neologism. There is no prescriptive definition—all you can make is an observation of common characteristics.
The common characteristics of NoSQL databases are
- Not using the relational model
- Running well on clusters
- Open-source
- Built for the 21st century web estates
- Schemaless
- The most important result of the rise of NoSQL is Polyglot Persistence.
数据存储方式需要随支持运行在集群上的大量数据的需求而有所改变。关系型数据库不是为高效运行在集群上而设计的。
2 Aggregate Data Models
- An aggregate is a collection of data that we interact with as a unit. Aggregates form the boundaries for ACID operations with the database.
- Key-value, document, and column-family databases can all be seen as forms of aggregate-oriented database.
- Aggregates make it easier for the database to manage data storage over clusters.
- Aggregate-oriented databases work best when most data interaction is done with the same aggregate; aggregate-ignorant databases are better when interactions use data organized in many different formations.
聚合的数据模型
3 More Details on Data Models
- Aggregate-oriented databases make inter-aggregate relationships more difficult to handle than intra-aggregate relationships.
- Graph databases organize data into node and edge graphs; they work best for data that has complex relationship structures.
- Schemaless databases allow you to freely add fields to records, but there is usually an implicit schema expected by users of the data.
- Aggregate-oriented databases often compute materialized views to provide data organized differently from their primary aggregates. This is often done with map-reduce computations.
数据模型更多细节
4 Distribution Models
There are two styles of distributing data:
- Sharding distributes different data across multiple servers, so each server acts as the single source for a subset of data.
- Replication copies data across multiple servers, so each bit of data can be found in multiple places.
A system may use either or both techniques.
Replication comes in two forms:
- Master-slave replication makes one node the authoritative copy that handles writes while slaves synchronize with the master and may handle reads.
- Peer-to-peer replication allows writes to any node; the nodes coordinate to synchronize their copies of the data.
Master-slave replication reduces the chance of update conflicts but peer-to-peer replication avoids loading all writes onto a single point of failure.
分布式模型
5 Consistency
- Write-write conflicts occur when two clients try to write the same data at the same time. Read-write conflicts occur when one client reads inconsistent data in the middle of another client's write.
- Pessimistic approaches lock data records to prevent conflicts. Optimistic approaches detect conflicts and fix them.
- Distributed systems see read-write conflicts due to some nodes having received updates while other nodes have not. Eventual consistency means that at some point the system will become consistent once all the writes have propagated to all the nodes.
- Clients usually want read-your-writes consistency, which means a client can write and then immediately read the new value. This can be difficult if the read and the write happen on different nodes.
- To get good consistency, you need to involve many nodes in data operations, but this increases latency. So you often have to trade off consistency versus latency.
- The CAP theorem states that if you get a network partition, you have to trade off availability of data versus consistency.
- Durability can also be traded off against latency, particularly if you want to survive failures with replicated data.
- You do not need to contact all replicants to preserve strong consistency with replication; you just need a large enough quorum.
6 Version Stamps
- Version stamps help you detect concurrency conflicts. When you read data, then update it, you can check the version stamp to ensure nobody updated the data between your read and write.
- Version stamps can be implemented using counters, GUIDs, content hashes, timestamps, or a combination of these.
- With distributed systems, a vector of version stamps allows you to detect when different nodes have conflicting updates.
版本戳
7 Map-Reduce
- Map-reduce is a pattern to allow computations to be parallelized over a cluster.
- The map task reads data from an aggregate and boils it down to relevant key-value pairs. Maps only read a single record at a time and can thus be parallelized and run on the node that stores the record.
- Reduce tasks take many values for a single key output from map tasks and summarize them into a single output. Each reducer operates on the result of a single key, so it can be parallelized by key.
- Reducers that have the same form for input and output can be combined into pipelines. This improves parallelism and reduces the amount of data to be transferred.
- Map-reduce operations can be composed into pipelines where the output of one reduce is the input to another operation's map.
- If the result of a map-reduce computation is widely used, it can be stored as a materialized view.
- Materialized views can be updated through incremental map-reduce operations that only compute changes to the view instead of recomputing everything from scratch.
MapReduce
12 Schema Migrations
- Databases with strong schemas, such as relational databases, can be migrated by saving each schema change, plus its data migration, in a version-controlled sequence.
- Schemaless databases still need careful migration due to the implicit schema in any code that accesses the data.
- Schemaless databases can use the same migration techniques as databases with strong schemas.
- Schemaless databases can also read data in a way that's tolerant to changes in the data's implicit schema and use incremental migration to update data.
13 Polyglot Persistence
- Polyglot persistence is about using different data storage technologies to handle varying data storage needs.
- Polyglot persistence can apply across an enterprise or within a single application.
- Encapsulating data access into services reduces the impact of data storage choices on other parts of a system.
- Adding more data storage technologies increases complexity in programming and operations, so the advantages of a good data storage fit need to be weighed against this complexity.
多种持久化存储方式
14 Beyond NoSQL
- NoSQL is just one set of data storage technologies. As they increase comfort with polyglot persistence, we should consider other data storage technologies whether or not they bear the NoSQL label.
NoNoSQL?
15 Choosing Your Database
The two main reasons to use NoSQL technology are:
- To improve programmer productivity by using a database that better matches an application's needs.
- To improve data access performance via some combination of handling larger data volumes, reducing latency, and improving throughput.
- It's essential to test your expectations about programmer productivity and/or performance before committing to using a NoSQL technology.
- Service encapsulation supports changing data storage technologies as needs and technology evolve. Separating parts of applications into services also allows you to introduce NoSQL into an existing application.
- Most applications, particularly nonstrategic ones, should stick with relational technology—at least until the NoSQL ecosystem becomes more mature.
Pramod Sadalage & Martin Fowler: 12 Sep 2012
There are no key points for Chapters 8-11 since these are examples of database use
[转载]NoSQL by Martin Flower的更多相关文章
- 微服务(Microservices)——Martin Flower【翻译】
原文是 Martin Flower 于 2014 年 3 月 25 日写的<Microservices>. 本文内容 微服务 微服务风格的特性 组件化(Componentization ) ...
- 微服务(Microservices)——Martin Flower
原文是 Martin Flower 于 2014 年 3 月 25 日写的<Microservices>. 迁移到:http://www.bdata-cap.com/newsinfo/17 ...
- 微服务架构(Microservices) ——Martin Flower
不知不觉到达了Sring Boot的学习中了,在学习之前,了解微服务架构是很有必要的,对于自己提升今后面试的软实力有很大帮助,在此写下. 让我们接下来看下Martin Flower 如何解释微服务架构 ...
- [转载] nosql 数据库的分布式算法
原文: http://juliashine.com/distributed-algorithms-in-nosql-databases/ NoSQL数据库的分布式算法 On 2012年11月9日 in ...
- [转载]NoSQL数据库的基础知识
关系型数据库和NoSQL数据库 什么是NoSQL 大家有没有听说过“NoSQL”呢?近年,这个词极受关注.看到“NoSQL”这个词,大家可能会误以为是“No!SQL”的缩写,并深感愤怒:“SQL怎么会 ...
- [转载] NoSQL简介
摘自“百度百科”. NoSQL,泛指非关系型的数据库.随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从 ...
- 转载 NoSQL | Redis、Memcache、MongoDB特点、区别以及应用场景
NoSQL | Redis.Memcache.MongoDB特点.区别以及应用场景 2017-12-12 康哥 码神联盟 本篇文章主要介绍Nosql的一些东西,以及Nosql中比较火的三个数据库Red ...
- 《NoSQL精粹》读后感
<NoSQL精粹>作者Pramod J. Sadalaga.Martin Flower著,译者爱飞翔. 本书以关系型数据库开头,讲解了关系型数据库的优缺点,然后引入了NoSQL数据库,并且 ...
- 福勒(Martin Fowler)
福勒(Martin Fowler),在面向对象分析设计.UML.模式.软件开发方法学.XP.重构等方面,都是世界顶级的专家,现为Thought Works公司的首席科学家.Thought Works是 ...
随机推荐
- 转: Oracle中的物化视图
物化视图创建语法:CREATE MATERIALIZED VIEW <schema.name>PCTFREE <integer>--存储参数PCTUSED <intege ...
- Memcached 及 Redis 架构分析和比较
Memcached和Redis作为两种Inmemory的key-value数据库,在设计和思想方面有着很多共通的地方,功能和应用方面在很多场合下(作为分布式缓存服务器使用等) 也很相似,在这里把两者放 ...
- ARM安装ROS- indigo
Ubuntu ARM install of ROS Indigo 溪西创客小屋 There are currently builds of ROS for Ubuntu Trusty armhf. T ...
- centos=>gsutil,iptables
sudo apt-get remove --purge gsutil sudo easy_install -U pip sudo pip2 install gsutil gsutil ls gs:/ ...
- ImageLoder配置以及使用(个人阅读使用)
http://blog.csdn.net/vipzjyno1/article/details/23206387 在gradle添加: compile 'com.nostra13.universalim ...
- 多动手试试,其实List类型的变量在页面上取到的值可以直接赋值给一个js的Array数组变量
多动手试试,其实List类型的变量在页面上取到的值可以直接赋值给一个js的Array数组变量,并且数组变量可以直接取到每一个元素var array1 = '<%=yearList =>'; ...
- (spring-第4回【IoC基础篇】)spring基于注解的配置
基于XML的bean属性配置:bean的定义信息与bean的实现类是分离的. 基于注解的配置:bean的定义信息是通过在bean实现类上标注注解实现. 也就是说,加了注解,相当于在XML中配置了,一样 ...
- Android 编译Settings、Mms等模块,并Push到手机中安装失败
问题描述:在编译完Settings等相关模块后,并push到手机中安装失败(在手机中无法找到该应用),但是使用adb shell命令进入到手机中在System/app或者System/priv-app ...
- __toString()与__call()
__toString()适用于直接输出类,用此方法,可以避免出错:__call()适用于使用类当中没有定义的函数(方法) <!DOCTYPE html> <html> < ...
- ACE - 代码层次及Socket封装
原文出自http://www.cnblogs.com/binchen-china,禁止转载. ACE源码约10万行,是c++中非常大的一个网络编程代码库,包含了网络编程的边边角角.在实际使用时,并不是 ...