SQL Server 基础 之 GROUP BY子句
GROUP BY 子句用于聚合信息
先看个实例,没有使用 GROUP BY 子句
SELECT SalesOrderID,OrderQty
FROM Sales.SalesOrderDetail
WHERE SalesOrderID IN (43660,43670)
结果: 结果可以得知,有很多重复的列(SalesOrderID)
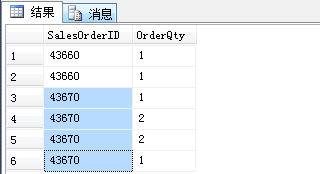
为什么会出现这种结果了?
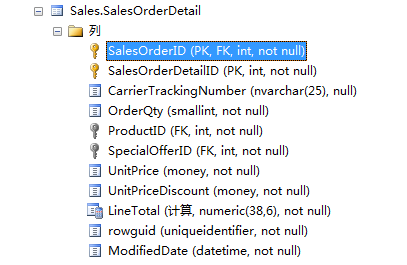
查看一下表结构可知,这张表 的主键是个组合主键, 分别有 SalesOrderID 和 SalesOrderDetailID 组成,当我们在 select中只选择SalesOrderID 时,所以会出现上图的结果
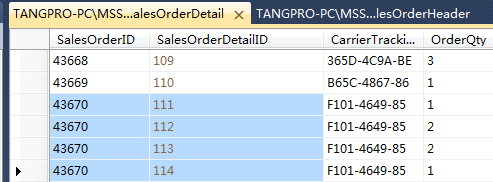
再来看使用了 GROUP BY 子句的结果:
SELECT SalesOrderID,OrderQty
FROM Sales.SalesOrderDetail
WHERE SalesOrderID IN (43660,43670)
GROUP BY SalesOrderID
此时会报错: 显示 OrderQty 列没有包含在 聚合函数 或 GROUP BY 子句中
说明: 当我们在使用 group by 子句的时候, select 中选取的列 要么要包含在 group by 子句中,要么要包含在 聚合函数中

此时我们修改代码:
SELECT SalesOrderID,OrderQty
FROM Sales.SalesOrderDetail
WHERE SalesOrderID IN (43660,43670)
GROUP BY SalesOrderID,OrderQty
结果: 这个实例包含了 group by 子句,但是没有 聚合函数
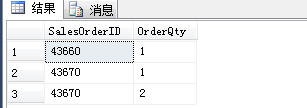
再来看看包含聚合函数的实例,通常有四个聚合函数
- SUM()
- MAX()
- MIN()
- COUNT()
在看一下:
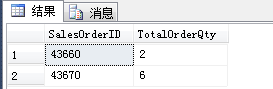
SELECT SalesOrderID,SUM(OrderQty) AS TotalOrderQty
FROM Sales.SalesOrderDetail
WHERE SalesOrderID IN (43660,43670)
GROUP BY SalesOrderID
结果: 这个才算真正的分组了, 把每个 SalesOrderID 对应的 总OrderQty 显示出来了
先说说 GROUP BY 子句的作用:
它的作用是通过一定的规则将一个数据集划分成若干个小的区域,然后针对若干个小区域进行数据处理。
通过一个实例说明:
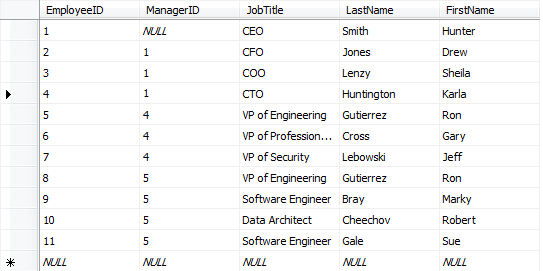
假设数据库中有张表结果如下:
由表中可分析出:
- ManagerID 为 1 的经理 有 3 名员工,其EmployeeID 分别为 2,3,4
- ManagerID 为 4 的经理 有 3 名员工,其EmployeeID 分别为 5,6,7
- ManagerID 为 5 的经理 有 4 名员工,其EmployeeID 分别为 8,9,10,11
- 员工号 EmployeeID 为 1 的员工 对应的 经理 ManagerID 为 NULL, 这点说明这名员工没有与之对应的经理, 可能是公司的总裁之类。
然后使用SQL 进行分析:
SELECT ManagerID, COUNT(*) --选出每个ManagerID,并且该MangerID所对应的数据条数
FROM HumanResources.Employee2
GROUP BY ManagerID --以 ManagerID 分组
结果如下:
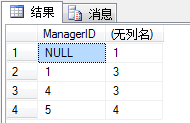
说明: ManagerID 为1 有3条数据与之对应
ManagerID 为4 有3条数据与之对应
ManagerID为5 有4条数据与之对应
其中ManagerID 为NULL 的有一条数据与之对应, 假设为 总裁
- 添加HAVING 子句
HAVING 与 Where 语句类似,Where 是在分类之前过滤,而 HAVING 是在分类之后过滤。
如果想对以上返回结果,进行相应条件的搜索,则可以添加HAVING子句,假设这里需要返回 ManagerID 对应数据量 大于 3 的结果,则SQL如下:
SELECT COUNT(*) AS Reposrts
FROM HumanResources.Employee2
GROUP BY ManagerID
HAVING COUNT(*) > 3
结果:

SQL Server 基础 之 GROUP BY子句的更多相关文章
- Sql Server 基础语法
来自:http://www.cnblogs.com/AaronYang/archive/2012/04/24/2468093.html Sql Server 基础语法 -- 查看数据表 select ...
- SQL server基础知识(表操作、数据约束、多表链接查询)
SQL server基础知识 一.基础知识 (1).存储结构:数据库->表->数据 (2).管理数据库 增加:create database 数据库名称 删除:drop database ...
- 【SQL Server】SQL Server基础之存储过程
SQL Server基础之存储过程 阅读目录 一:存储过程概述 二:存储过程分类 三:创建存储过程 1.创建无参存储过程 2.修改存储过程 3.删除存储过程 4.重命名存储过程 5.创建带参数的存储 ...
- SQL Server 2012 中 Update FROM子句
首先说明一下需求以及环境 创建Table1以及Table2两张表,并插入一下数据 USE AdventureWorks2012; GO IF OBJECT_ID ('dbo.Table1', 'U') ...
- 《SQL Server基础——SQL语句》
SQL Server基础--SQL语句 一.创建和删除数据库: 1.创建数据库(默认化初始值) 格式: CREATE DATABASE 数据库名称 例如: CREATE DATABASE ...
- 数据库开发基础-SQl Server 基础
SQL Server 基础 1.什么是SQL Server SQL:Structured Query Language 结构化查询语言 SQL Server是一个以客户/服务器(c/s)模式访问.使 ...
- Sql Server 基础知识
Sql Server 基础知识: http://blog.csdn.net/t6786780/article/details/4525652 Sql Server 语句大全: http://www.c ...
- SQL Server基础之索引
索引用于快速找出在某个列中有某一特定值的行,不使用索引,数据库必须从第一条记录开始读完整个表,直到找出相关的行.表越大,查询数据所花费的时间越多,如果表中查询的列有一个索引,数据库能快速到达一个位置 ...
- 【SQL server】SQL server基础(二)
一.一些重要的SQL命令 SELECT - 从数据库中提取数据 UPDATE - 更新数据库中的数据 DELETE - 从数据库中删除数据 INSERT INTO - 向数据库中插入新数据 CREAT ...
随机推荐
- WIndows7 多版本
Windows7 安装U盘 删除source\ei.cfg 以后开机安装会提示安装的版本
- Tutorial: Analyzing sales data from Excel and an OData feed
With Power BI Desktop, you can connect to all sorts of different data sources, then combine and shap ...
- ASP.NET MVC4 View层_Razor操作Html元素
1 常用 Html 标签 1.1 Label Html 语法 :<label for="UserName">用户名</label> Razor语法:@Htm ...
- Linux 进程(一):环境及其控制
进程环境 main启动 当内核执行C程序时,在调用main前先调用一个特殊的启动例程.可执行程序将此启动例程指定为程序的起始地址,接着启动例程从内核中取出命令行参数和环境变量值,然后执行main函数. ...
- 条款9:不要在构造和析构过程中调用virtual函数
如下是一个股票交易的例子: class Transaction // 交易的基类 { public: Transaction(); ; // 用于记录交易日志 }; Transaction::Tran ...
- Android HttpClient GET或者POST请求基本使用方法(转)
在Android开发中我们经常会用到网络连接功能与服务器进行数据的交互,为此Android的SDK提供了Apache的HttpClient来方便我们使用各种Http服务.这里只介绍如何使用HttpCl ...
- verilog中级别到底是什么?级别的分类是什么???
1.级别到底是什么? 答:所谓的系统级,算法级,RTL级,门级,开关级,就是在不同的层次上来描述某个电路模块.当然行为级和结构级就是在行为上和结构上来描述电路模块. 模块可以用不同级别语言来描述,当然 ...
- C Primer Plus学习笔记
1.汇编语言是特地的Cpu设计所采用的一组内部指令的助记符,不同的Cpu类型使用不同的Cpu C给予你更多的自由,也让你承担更多的风险 自由的代价是永远的警惕 2.目标代码文件.可执行文件和库 3.可 ...
- mui开发
http://blog.csdn.net/sunhuaqiang1/article/details/46848005
- Android:apk文件结构
Android apk文件,即Android application package文件. 每个要安装到Android平台的应用都要被编译打包为一个单独的文件,后缀名为.apk,其中包含了应用的二进制 ...