Hadoop系统架构
一、Hadoop系统架构图
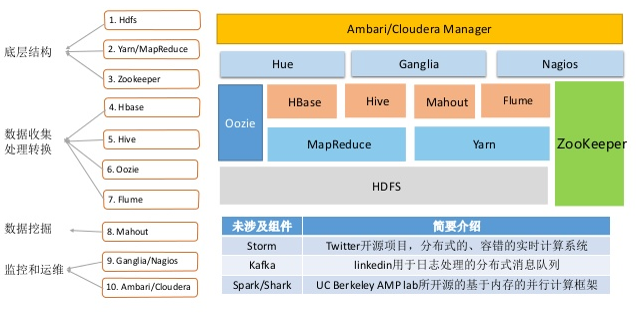
Hadoop1.0与hadoop2.0架构对比图
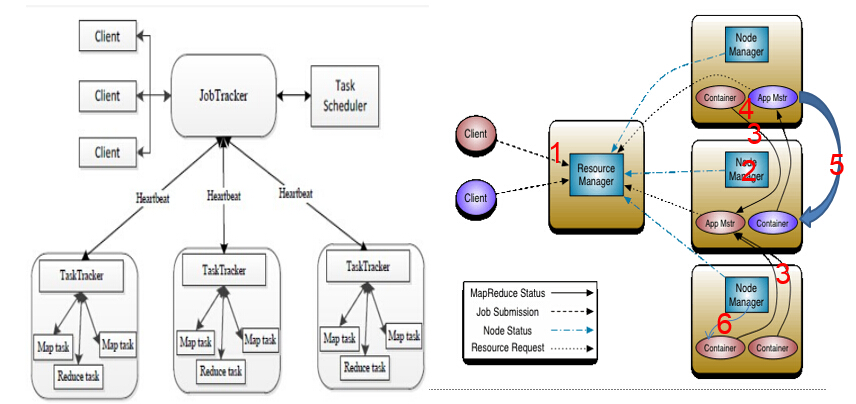
YARN架构:
ResourceManager
NodeManager
ApplicationMaster
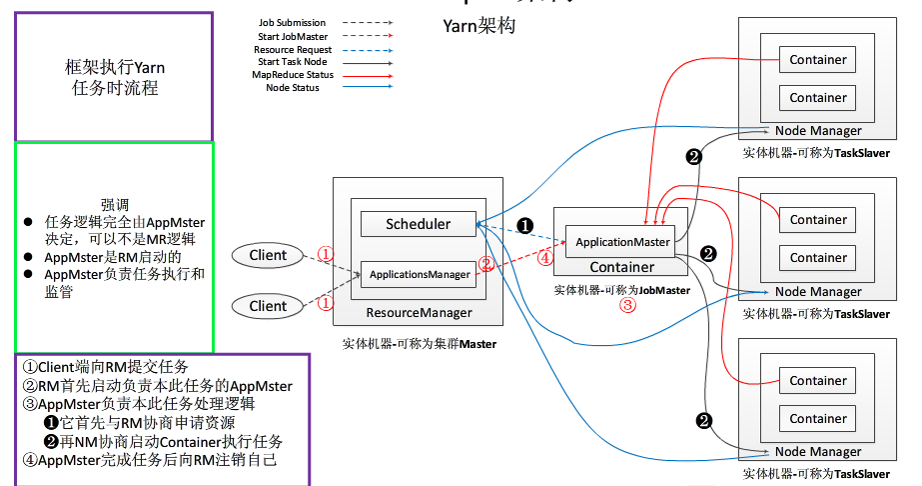
步骤1 用户向YARN 中提交应用程序, 其中包括ApplicationMaster 程序、启动ApplicationMaster 的命令、用户程序等。
步骤2 ResourceManager 为该应用程序分配第一个Container, 并与对应的NodeManager 通信,要求它在这个Container 中启动应用程序的ApplicationMaster。
步骤3 ApplicationMaster 首先向ResourceManager 注册, 这样用户可以直接通过ResourceManage 查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7。
步骤4 ApplicationMaster 采用轮询的方式通过RPC 协议向ResourceManager 申请和领取资源。
步骤5 一旦ApplicationMaster 申请到资源后,便与对应的NodeManager 通信,要求它启动任务。
步骤6 NodeManager 为任务设置好运行环境(包括环境变量、JAR 包、二进制程序
等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
步骤7 各个任务通过某个RPC 协议向ApplicationMaster 汇报自己的状态和进度,以让ApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC 向ApplicationMaster 查询应用程序的当
前运行状态。
步骤8 应用程序运行完成后,ApplicationMaster 向ResourceManager 注销并关闭自己。
运行在YARN上带来的好处 :
利用共享存储在两个NN间同步edits信息,如NFS等中高端存储设备内部的各种RAID以及冗余硬件
DataNode同时向两个NN汇报块信息,让Standby NN保持集群最新状态
用FailoverController watchdog进程监视和控制NN进程,防止因 NN FullGC挂起无法发送heart beat
防止脑裂(brain-split):主备切换时由于切换不彻底等原因导致Slave误以为出现两个active master,通常采用Fencing机制:
-共享存储fencing,确保只有一个NN可以写入edits
-客户端fencing,确保只有一个NN可以响应客户端的请求
- DN fencing,确保只有一个NN可以向DN下发删除等命令
HDFS文件读取:

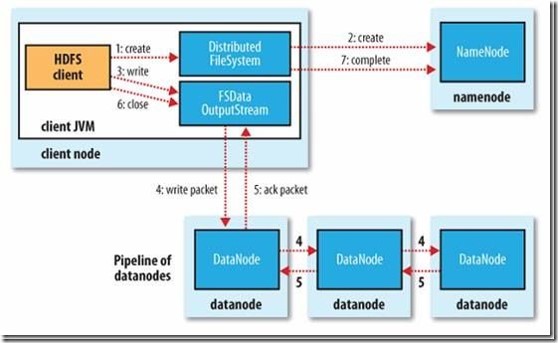
HDFS文件写入:
MapReduce基本流程:

从MapReduce 自身的命名特点可以看出, MapReduce 由两个阶段组成:Map 和Reduce。用户只需编写map() 和 reduce() 两个函数,即可完成简单的分布式程序的设计。
map() 函数以key/value 对作为输入,产生另外一系列 key/value 对作为中间输出写入本地磁盘。 MapReduce 框架会自动将这些中间数据按照 key 值进行聚集,且key 值相同(用户可设定聚集策略,默认情况下是对 key 值进行哈希取模)的数据被统一交给 reduce() 函数处理。
reduce() 函数以key 及对应的value 列表作为输入,经合并 key 相同的value 值后,产生另外一系列 key/value 对作为最终输出写入HDFS
hello world --WordCount
用户编写完MapReduce 程序后,按照一定的规则指定程序的输入和输出目录,并提交到Hadoop 集群中。作业在Hadoop 中的执行过程如图所示。Hadoop 将输入数据切分成若干个输入分片(input split,后面简称split),并将每个split 交给一个Map Task 处理;Map Task 不断地从对应的split 中解析出一个个key/value,并调用map() 函数处理,处理完之后根据Reduce Task 个数将结果分成若干个分片(partition)写到本地磁盘;同时,每个Reduce Task 从每个Map Task 上读取属于自己的那个partition,然后使用基于排序的方法将key 相同的数据聚集在一起,调用reduce() 函数处理,并将结果输出到文件中
Hadoop系统架构的更多相关文章
- 基于Hadoop开发网络云盘系统架构设计方案
基于Hadoop开发网络云盘系统架构设计方案第一稿 引言 云计算技术的发展,各种网络云盘技术如雨后春笋,层出不穷,百度.新浪.网易都推出了自己的云盘系统,本文基于开源框架Hadoop设计实现了一套自己 ...
- 【系统架构】IT职业技能图谱(点开大图查看)
本文地址 1 程序开发语言综述 2 iOS开发工程师必备技能 3 运维工程师必备技能 4 前端工程师必备技能 5 大数据工程师必备技能 6 云计算工程师必备技能 7 安全工程师必备技能 8 移动无线测 ...
- hbase基础-系统架构
HBase 系统架构 HBase是Apache Hadoop的数据库,能够对大型数据提供随机.实时的读写访问.HBase的目标是存储并处理大型的数据.HBase是一个开源的,分布式的,多版本的,面向列 ...
- 【转发】揭秘Facebook 的系统架构
揭底Facebook 的系统架构 www.MyException.Cn 发布于:2012-08-28 12:37:01 浏览:0次 0 揭秘Facebook 的系统架构 www.MyExcep ...
- Hbase系统架构
HBase 系统架构 HBase是Apache Hadoop的数据库,能够对大型数据提供随机.实时的读写访问.HBase的目标是存储并处理大型的数据.HBase是一个开源的,分布式的,多版本的,面向列 ...
- HBase 系统架构
HBase是Apache Hadoop的数据库,能够对大型数据提供随机.实时的读写访问.HBase的目标是存储并处理大型的数据.HBase是一个开源的,分布式的,多版本的,面向列的存储模型.它存储的是 ...
- 系统架构师JD
#################################################################################################### ...
- ONOS系统架构演进,实现高可用性解决方案
上一篇文章<ONOS高可用性和可扩展性实现初探>讲到了ONOS系统架构在高可用.可扩展方面技术概况,提到了系统在分布式集群中怎样保证数据的一致性.在数据终于一致性方面,ONOS採用了Gos ...
- 大数据高并发系统架构实战方案(LVS负载均衡、Nginx、共享存储、海量数据、队列缓存)
课程简介: 随着互联网的发展,高并发.大数据量的网站要求越来越高.而这些高要求都是基础的技术和细节组合而成的.本课程就从实际案例出发给大家原景重现高并发架构常用技术点及详细演练. 通过该课程的学习,普 ...
随机推荐
- bootstrap部分---网格系统;(几天没写博客了,为了潜心研究一下bootstrap)
1工作原理: (1)行必须放置在 .container class 内,以便获得适当的对齐(alignment)和内边距(padding). (2)使用行来创建列的水平组. (3)内容应该放置在列内, ...
- Python简史
Python简史 作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! Python是我喜欢的语言,简洁,优美,容易使用.前两天,我很激 ...
- Codeforces Round #132 (Div. 2)
A. Bicycle Chain 统计\(\frac{b_j}{a_i}\)最大值以及个数. B. Olympic Medal \(\frac{m_{out}=\pi (r_1^2-r_2^2)hp_ ...
- jquery】常用的jquery获取表单对象的属性与值
[jquery]常用的jquery获取表单对象的属性与值 1.JQuery的概念 JQuery是一个JavaScript的类库,这个类库集合了很多功能方法,利用类库你可以用一些简单的代码实现一些复杂的 ...
- Java设计模式之适配器设计模式
1.适配器模式( Adapter)定义将一个类的接口转换成客户希望的另外一个接口.Adapter 模式使得原来由于接口不兼容而不能一起工作的 那些类可以一起工作. 现实案例如下: 墙上电源类(22 ...
- 如何才能将Faster R-CNN训练起来?
如何才能将Faster R-CNN训练起来? 首先进入 Faster RCNN 的官网啦,即:https://github.com/rbgirshick/py-faster-rcnn#installa ...
- tomcat maven book
https://www.amazon.com/gp/aw/d/0596517335/ref=pd_aw_sim_14_3?ie=UTF8&psc=1&refRID=H34H0BX247 ...
- sed详解
1. Sed简介 sed 是一种在线编辑器,它一次处理一行内容.处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后 ...
- vb6中webbrowser控件树转换备忘
Dim doc As HTMLDocument Set doc = WebBrowser1.Document Dim inputs As IHTMLElementCollection Set inpu ...
- Intent的FLAG_ACTIVITY_CLEAR_TOP和FLAG_ACTIVITY_REORDER_TO_FRONT
Activity的两种启动模式:FLAG_ACTIVITY_CLEAR_TOP和FLAG_ACTIVITY_REORDER_TO_FRONT 1. 如果已经启动了四个Activity:A,B,C和D. ...