数据治理核心保障数据质量监控开源项目Apache Griffin分享
@
概述
定义
Apache Griffin 官网地址 https://griffin.apache.org/ 源码release最新版本0.6.0
Apache Griffin 官网文档地址 https://griffin.apache.org/docs/quickstart.html
Apache Griffin 源码地址 https://github.com/apache/griffin
Apache Griffin是一个开源的大数据数据质量解决方案,它支持批处理和流模式两种数据质量检测方式,可以从不同维度(比如离线任务执行完毕后检查源端和目标端的数据数量是否一致、源表的数据空值数量等)度量数据资产,从而提升数据的准确度、可信度。
Apache Griffin提供了一套定义良好的数据质量领域模型,涵盖了一般情况下的大多数数据质量问题。它还定义了一组数据质量DSL来帮助用户定义他们的质量标准。通过扩展DSL甚至可以在Apache Griffin中实现自定义的特定特性/功能。
数据质量(DQ)是物联网、机器学习等许多数据消费者的关键标准,但如何确定“好”数据没有标准协议。Apache Griffin是一个模型驱动的数据质量服务平台,可以在其中按需检查数据。它提供了一个标准流程来定义数据质量度量、执行和报告,允许跨多个数据系统进行这些检查;当不信任自己的数据或者担心数据会对关键决策产生负面影响时则可以使用Apache Griffin来确保数据质量。
Apache Griffin支持两种类型的数据源:
- batch数据:通过数据连接器从Hadoop平台收集数据。
- streaming数据:可以连接到诸如Kafka之类的消息系统来做近似实时数据分析。
为何要做数据质量监控
- 当数据从不同的数据源流向不同的应用系统的时候,缺少端到端的统一视图来追踪数据沿袭(Data Lineage)。这也就导致了在识别和解决数据质量问题上要花费许多不必要的时间。
- 缺少一个实时的数据质量检测系统。从数据资产(Data Asset)注册,数据质量模型定义,数据质量结果可视化、可监控,当检测到问题时,可以及时发出警报。
- 缺乏一个共享平台和API服务,让每个项目组无需维护自己的软硬件环境就能解决常见的数据质量问题。
基本概念
DQC:Data Quality Control,数据质量检测/数据质量控制,一般称为数据质量监控。
SLA:Service Level Agreement,也就是服务等级协议,指的是系统服务提供者(Provider)对客户(Costomer)的一个服务承诺,通常称为数据产出分级运维服务。
由定义可知,DQC关注数据口径,负责数据准不准的监测,而SLA关注产出及时性和稳定性,这两者有机结合共同保障了数据质量。在需求场景上DQC主要负责对数据资产质量和波动的监控,SLA主要负责对数据产出和任务调度结果和时长的监控。
特性
- 度量:精确度、完整性、及时性、唯一性、有效性、一致性。
- 异常监测:利用预先设定的规则,检测出不符合预期的数据,提供不符合规则数据的下载。
- 异常告警:通过邮件或门户报告数据质量问题。
- 可视化监测:利用控制面板来展现数据质量的状态。
- 实时性:可以实时进行数据质量检测,能够及时发现问题。
- 可扩展性:可用于多个数据系统仓库的数据校验。
- 自助服务:Griffin提供了一个简洁易用的用户界面,可以管理数据资产和数据质量规则;同时用户可以通过控制面板查看数据质量结果和自定义显示内容。
架构
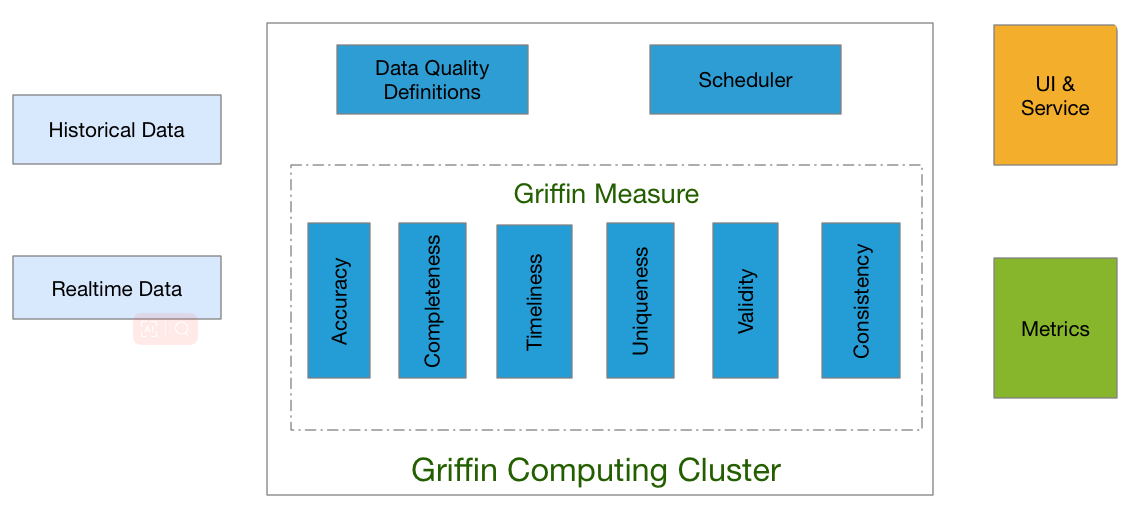
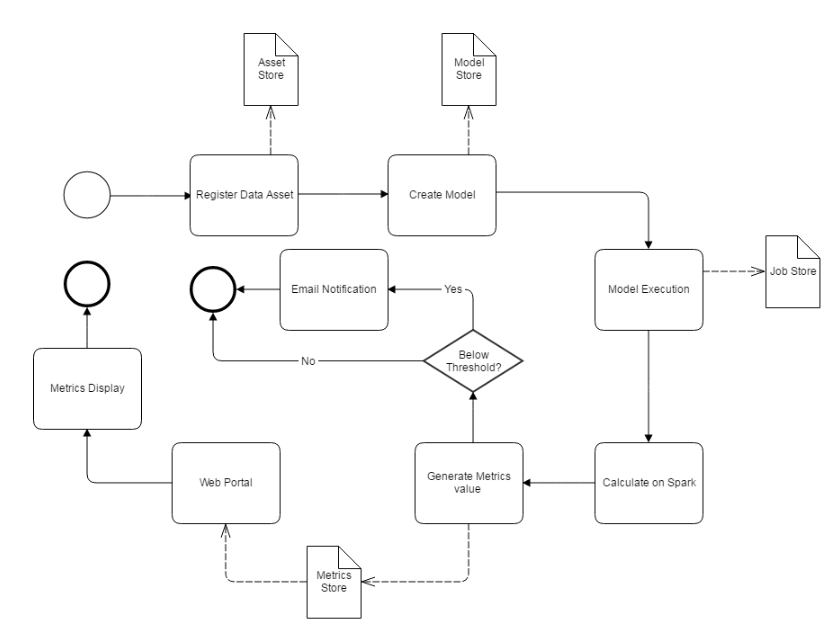
Apache Griffin通过3个步骤来处理数据质量问题,步骤如下:
- 定义数据质量:数据科学家/分析师定义他们的数据质量要求,如准确性、完整性、及时性、唯一性、有效性、一致性和分析等。
- 测量数据质量:源数据将被摄取到Apache Griffin计算集群中,Apache Griffin将根据数据质量需求启动数据质量测量。
- 度量结果:作为度量的数据质量报告将被发送到指定的地方。
此外Apache Griffin还为用户提供了一个前端层,用户可以轻松地将任何新的数据质量需求装载到Apache Griffin平台中,并编写全面的逻辑来定义他们的数据质量。
在Griffin的架构中,主要分为Define、Measure和Analyze三个部分
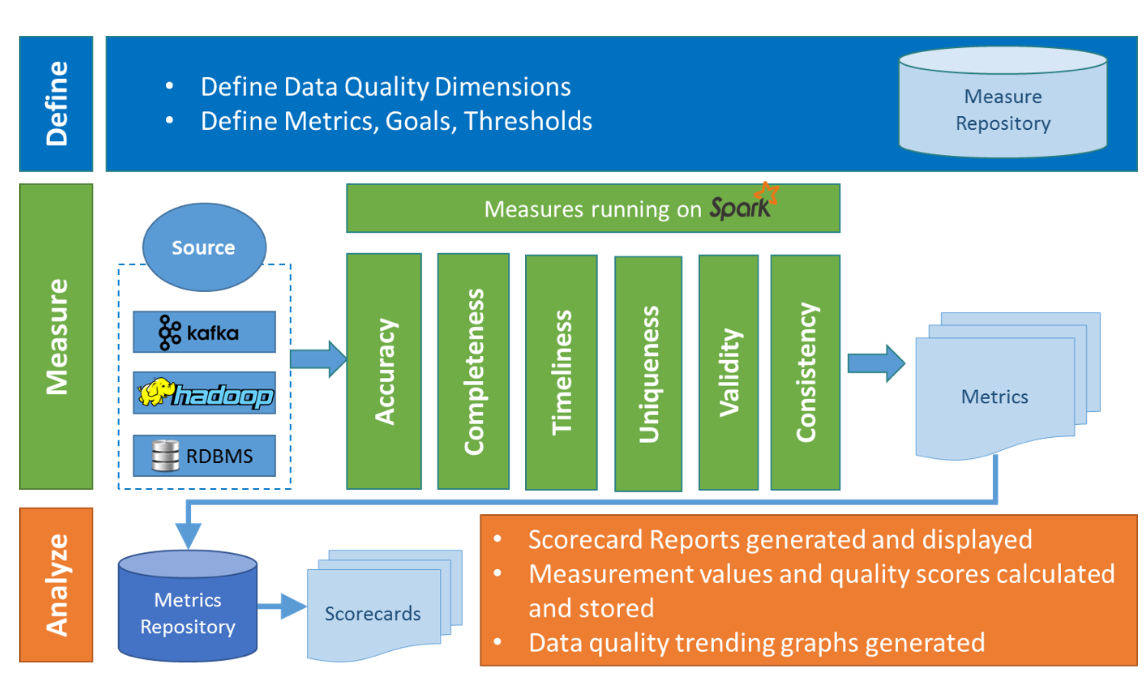
各部分的职责如下:
- Define:主要负责定义数据质量统计的维度,比如数据质量统计的时间跨度、统计的目标(源端和目标端的数据数量是否一致,数据源里某一字段的非空的数量、不重复值的数量、最大值、最小值、top5的值数量等)。
- Measure:主要负责执行统计任务,生成统计结果。
- Analyze:主要负责保存与展示统计结果。
安装
Docker部署
Griffin docker镜像是预先构建在docker hub上的,可以通过docker方式试用体验Apache Griffin。
# 国外地址镜像下载安装
docker pull apachegriffin/griffin_spark2:0.3.0
docker pull apachegriffin/elasticsearch
docker pull apachegriffin/kafka
docker pull zookeeper:3.5
# 中国地址镜像下载安装
docker pull registry.docker-cn.com/apachegriffin/griffin_spark2:0.3.0
docker pull registry.docker-cn.com/apachegriffin/elasticsearch
docker pull registry.docker-cn.com/apachegriffin/kafka
docker pull zookeeper:3.5
docker映像是Apache Griffin环境映像,各镜像包含内容如下:
- apachegriffin/griffin_spark2:该镜像包含mysql、hadoop、 hive、 spark、 livy、Apache Griffin服务、Apache Griffin度量,以及一些准备好的demo数据,它作为一个单节点spark集群,提供spark引擎和Apache Griffin服务。
- apachegriffin/elasticsearch:此镜像基于官方的elasticsearch,添加了一些配置以启用cors请求,为指标持久化提供elasticsearch服务。
- apachegriffin/kafka:此镜像包含kafka 0.8,以及一些演示流数据,以流模式提供流数据源。
- zookeeper:3.5:此镜像为官方zookeeper,以流媒体模式提供zookeeper服务。
Docker 镜像批处理使用
- 下载获取源码中docker/compose/docker-compose-batch.yml文件,Griffin源码目录主要包括griffin-doc、measure、service和ui四个模块
- griffin-doc负责存放Griffin的文档
- measure采用scala语言编写,负责与spark交互,执行统计任务
- service采用java的SpringBoot作为服务实现,负责给ui模块提供交互所需的restful api,保存统计任务,展示统计结果。
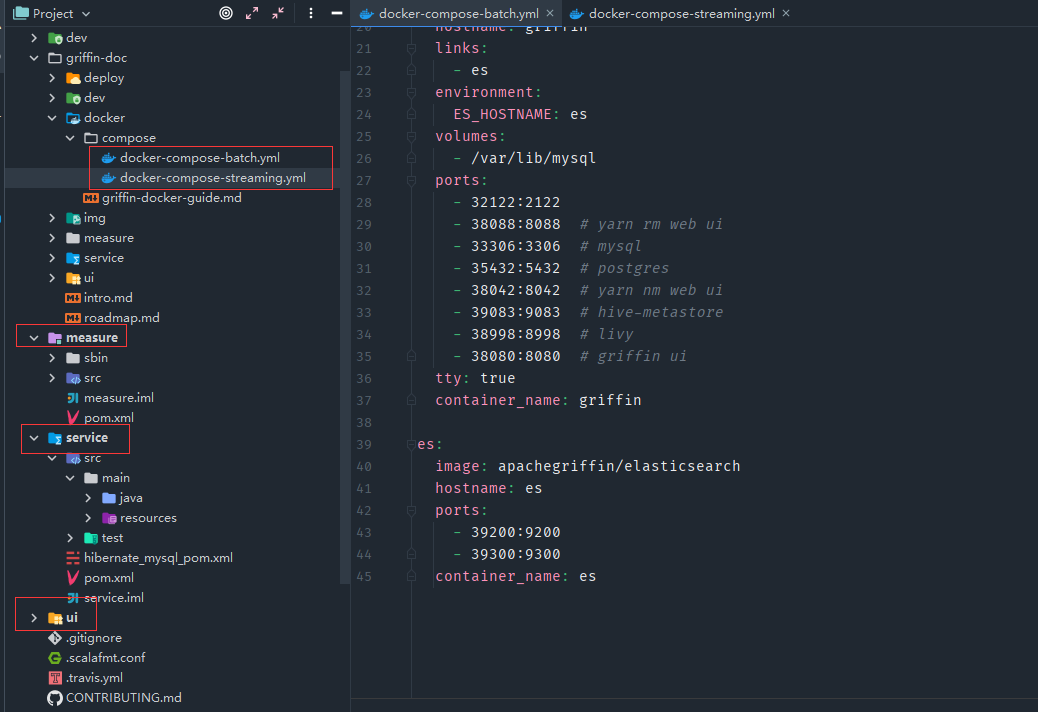
- 通过docker-compose启动
# 启动
docker-compose -f docker-compose-batch.yml up -d
# 查看容器
docker container ls

- 可以通过使用任何http客户端来尝试Apache Griffin api,这里以postman为例,官方源码中准备了两个postman的json配置文件。
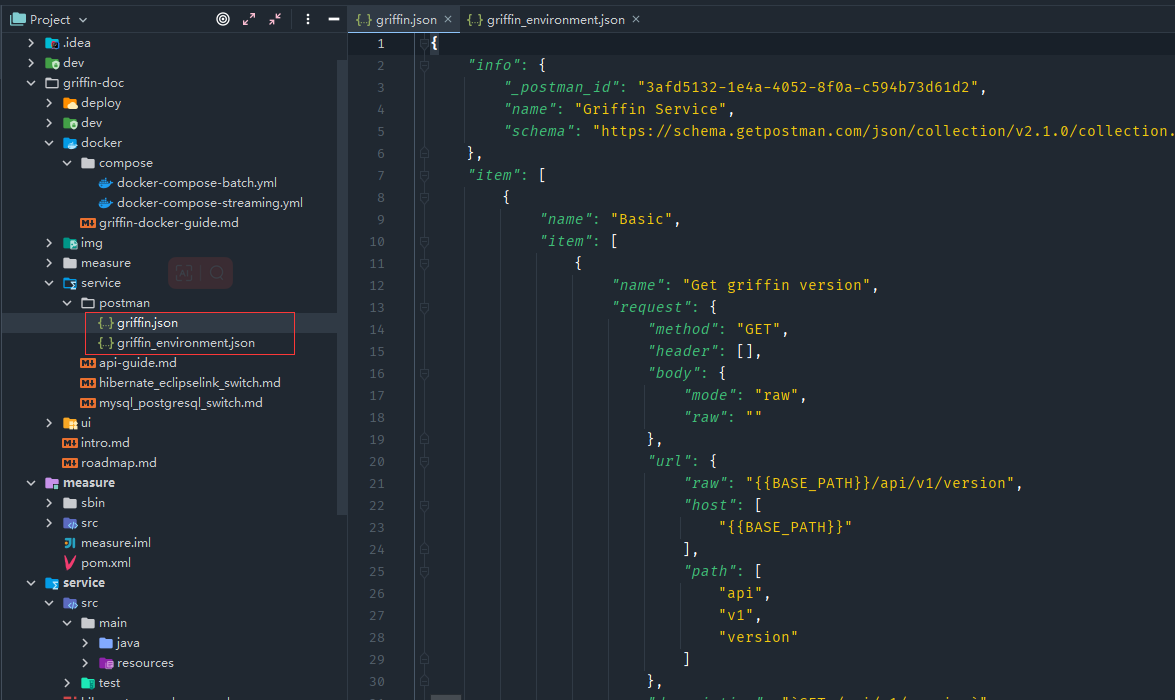
在postman以文件导入上面两个json配置文件,在Griffin Environment配置BASE_PATH环境变量,端口为上面docker容器暴露的38080
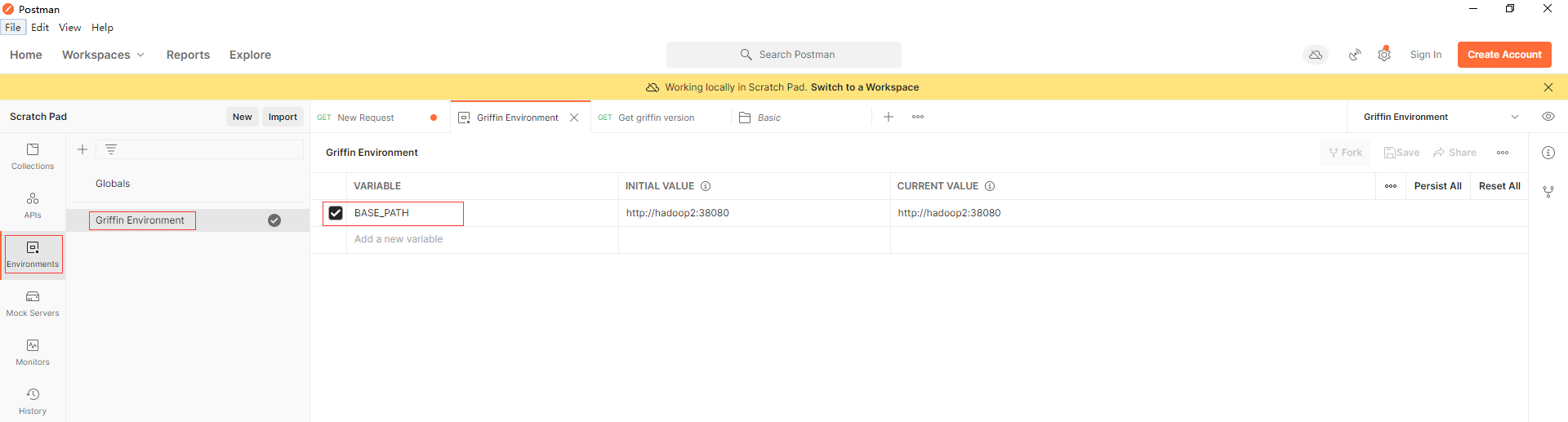
先通过调用api (Basic -> Get griffin version)以确保Apache Griffin服务已经启动。
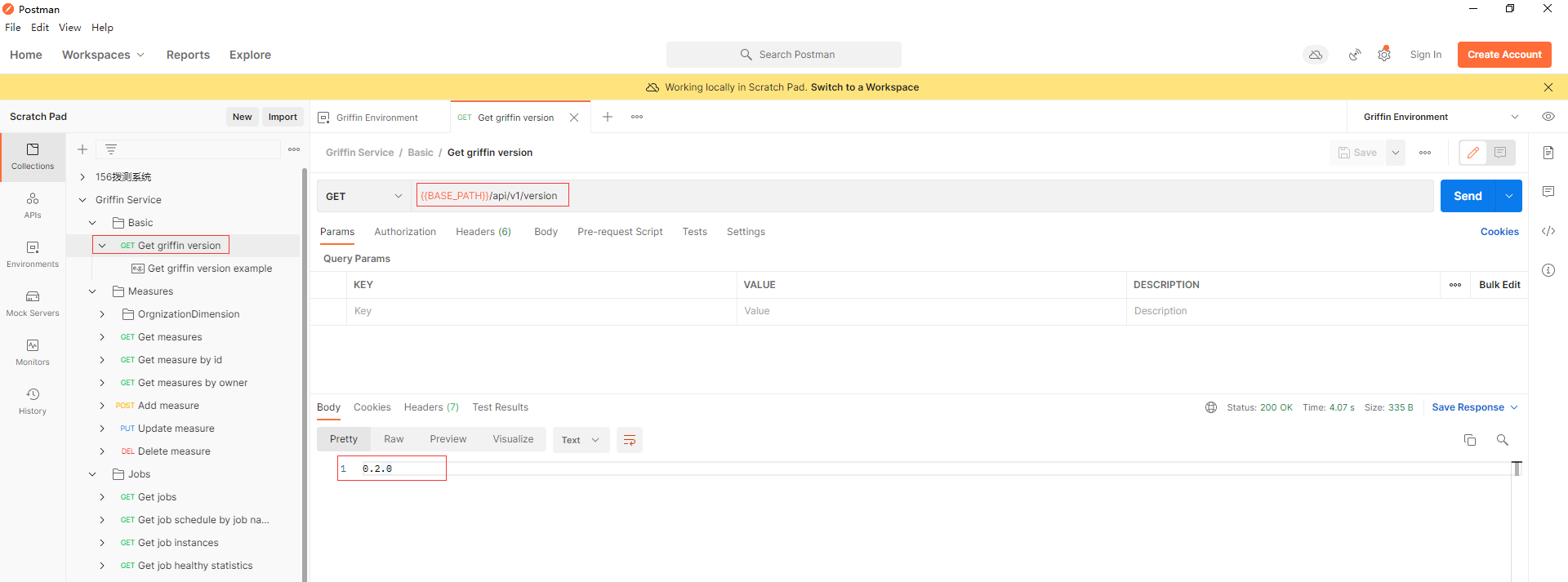
- 通过api Measures -> Add measure添加一个精度度量,在Apache Griffin中创建一个度量。
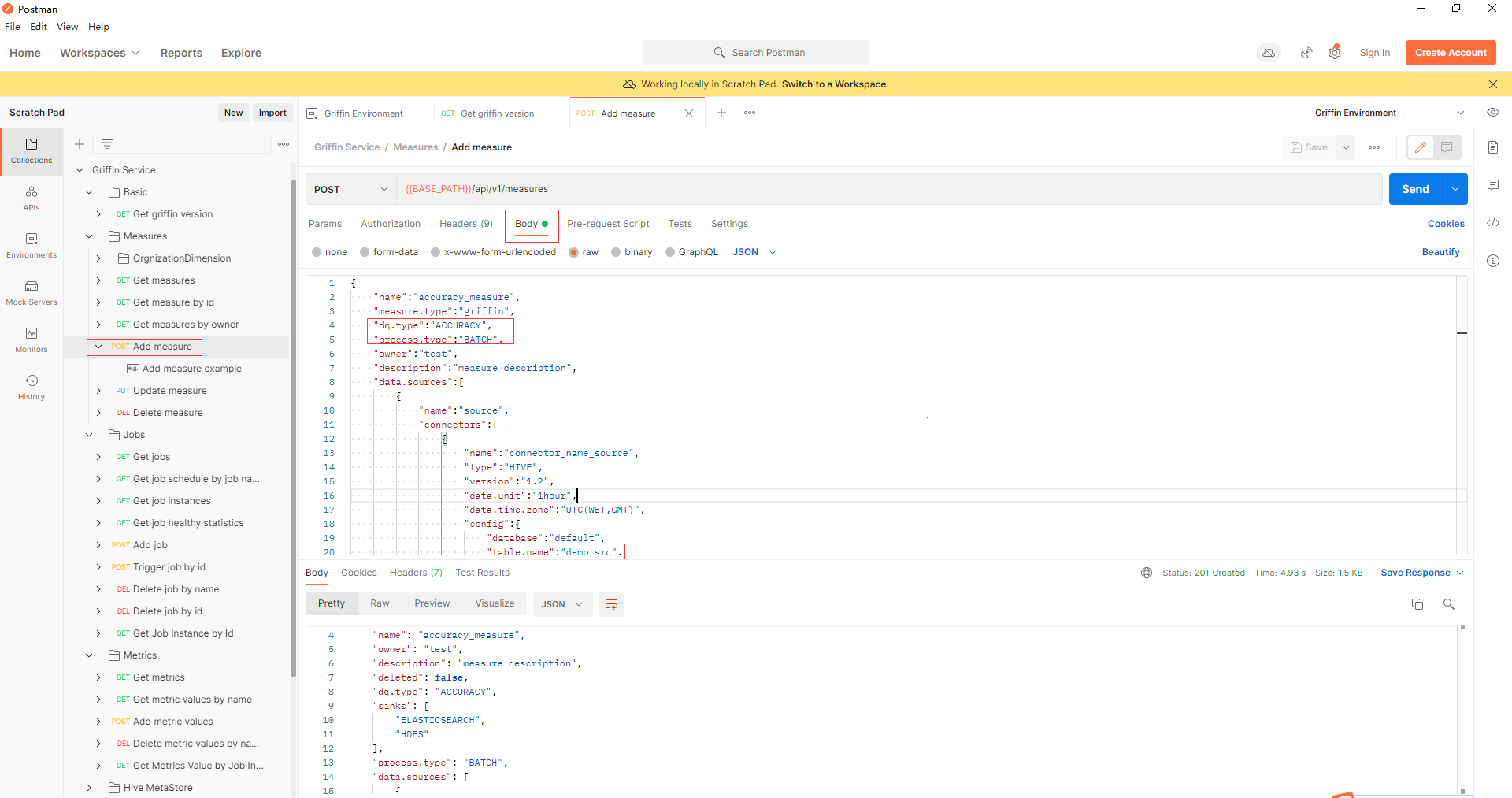
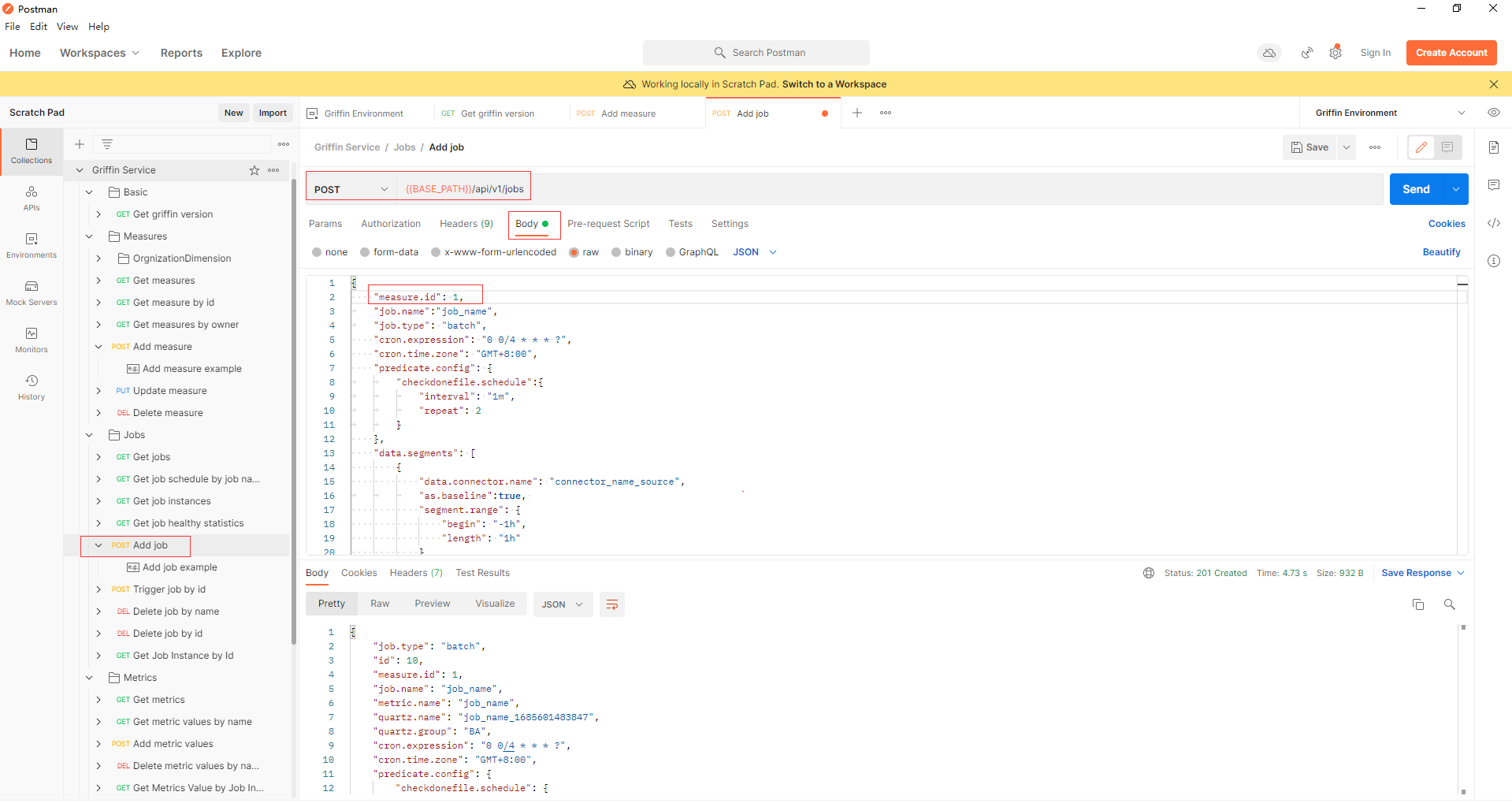
- 通过api jobs -> Add job添加一个作业来调度一个作业来执行度量。在本例中,调度间隔为4分钟,measure.id填写为上一步返回的id值。
- 几分钟后,可以从elasticsearch获得度量
curl -XGET 'hadoop2:39200/griffin/accuracy/_search?pretty&filter_path=hits.hits._source' -d '{"query":{"match_all":{}}, "sort": [{"tmst": {"order": "asc"}}]}'
{
"hits" : {
"hits" : [
{
"_source" : {
"name" : "metricName",
"tmst" : 1509599811123,
"value" : {
"__tmst" : 1509599811123,
"miss" : 11,
"total" : 125000,
"matched" : 124989
}
}
},
{
"_source" : {
"name" : "metricName",
"tmst" : 1509599811123,
"value" : {
"__tmst" : 1509599811123,
"miss" : 11,
"total" : 125000,
"matched" : 124989
}
}
}
]
}
}
Docker 镜像流处理使用
- 下载获取源码中docker/compose/docker-compose-streaming.yml文件。
- 通过docker-compose启动
# 启动
docker-compose -f docker-compose-streaming.yml up -d
# 查看容器
docker container ls
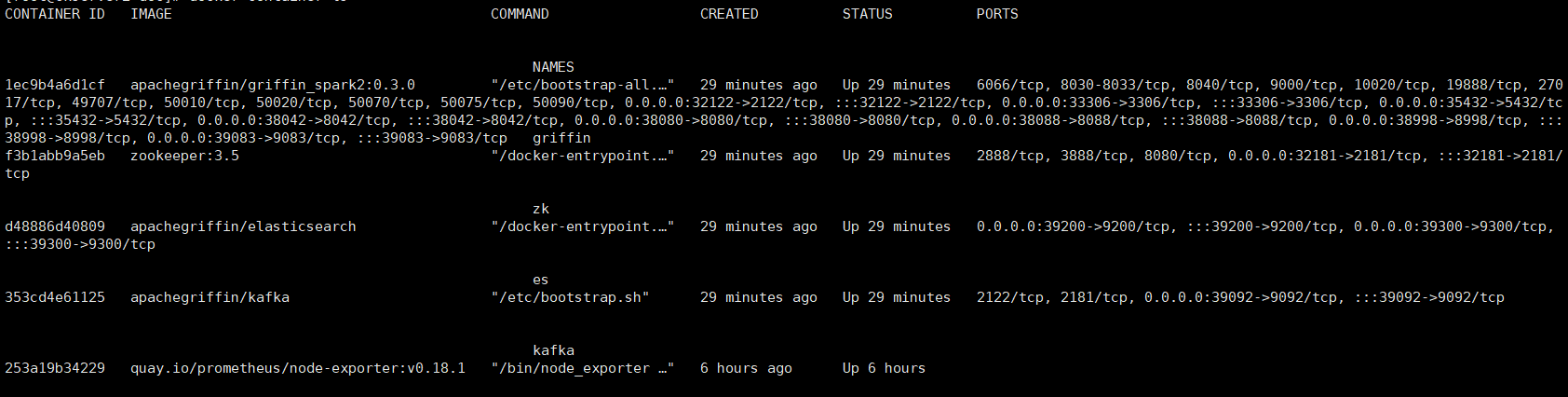
- 执行流测试
# 进入griffin容器
docker exec -it griffin bash
# 切换到measure目录
cd ~/measure
# 执行脚本进行流精度测量
./streaming-accu.sh
# 跟踪日志
tail -f streaming-accu.log
- 执行流分析测量
# 先杀死上面进行进程
kill -9 `ps -ef | awk '/griffin-measure/{print $2}'`
# 然后清除上次流作业的检查点目录和其他相关目录
./clear.sh
# 执行脚本进行流分析度量
./streaming-prof.sh
# 跟踪日志
tail -f streaming-prof.log
UI界面操作
- 访问UI http://hadoop2:38080,默认用户密码为griffin/griffin

- 总体业务流程
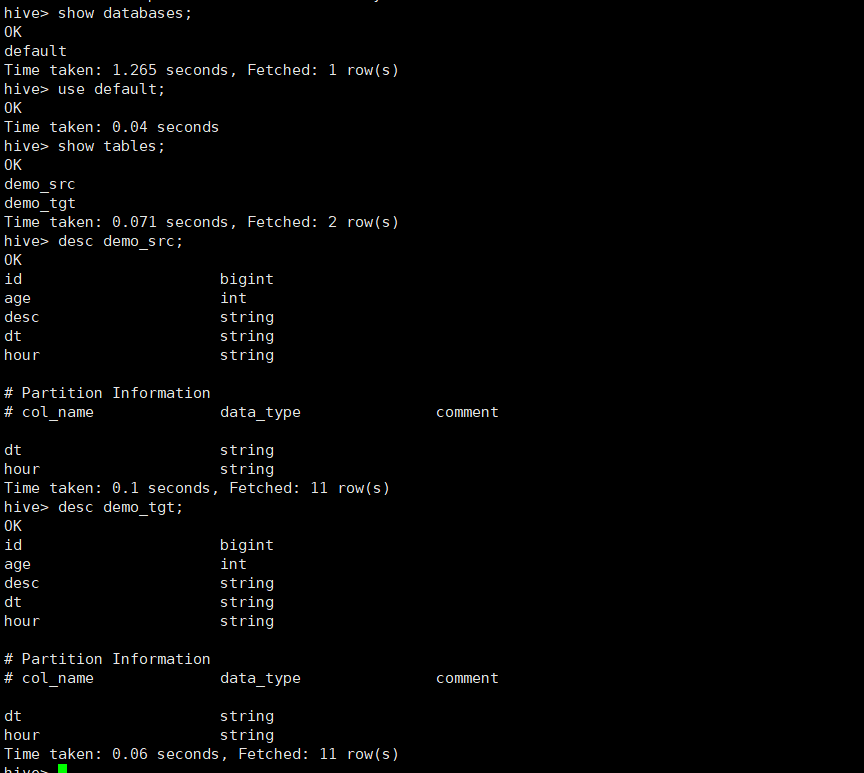
- 当前docker镜像中默认有创建两个数据资产demo_src和demo_tgt可供测试。
# 进入griffin容器
docker exec -it griffin bash
# 进入hive命令行
hive
创建度量标准
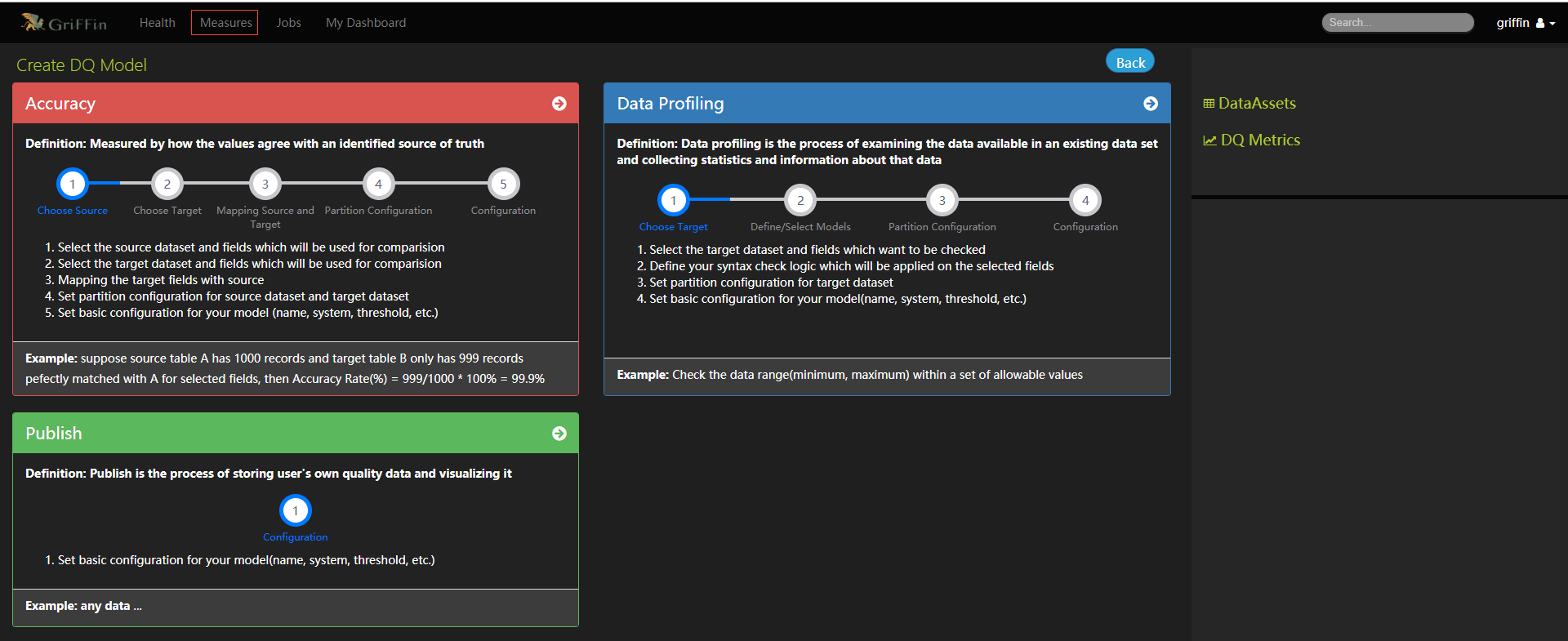
- 选择数据源,单一的真实来源与目标进行数据质量比较,目前只能从一个模式中选择属性。
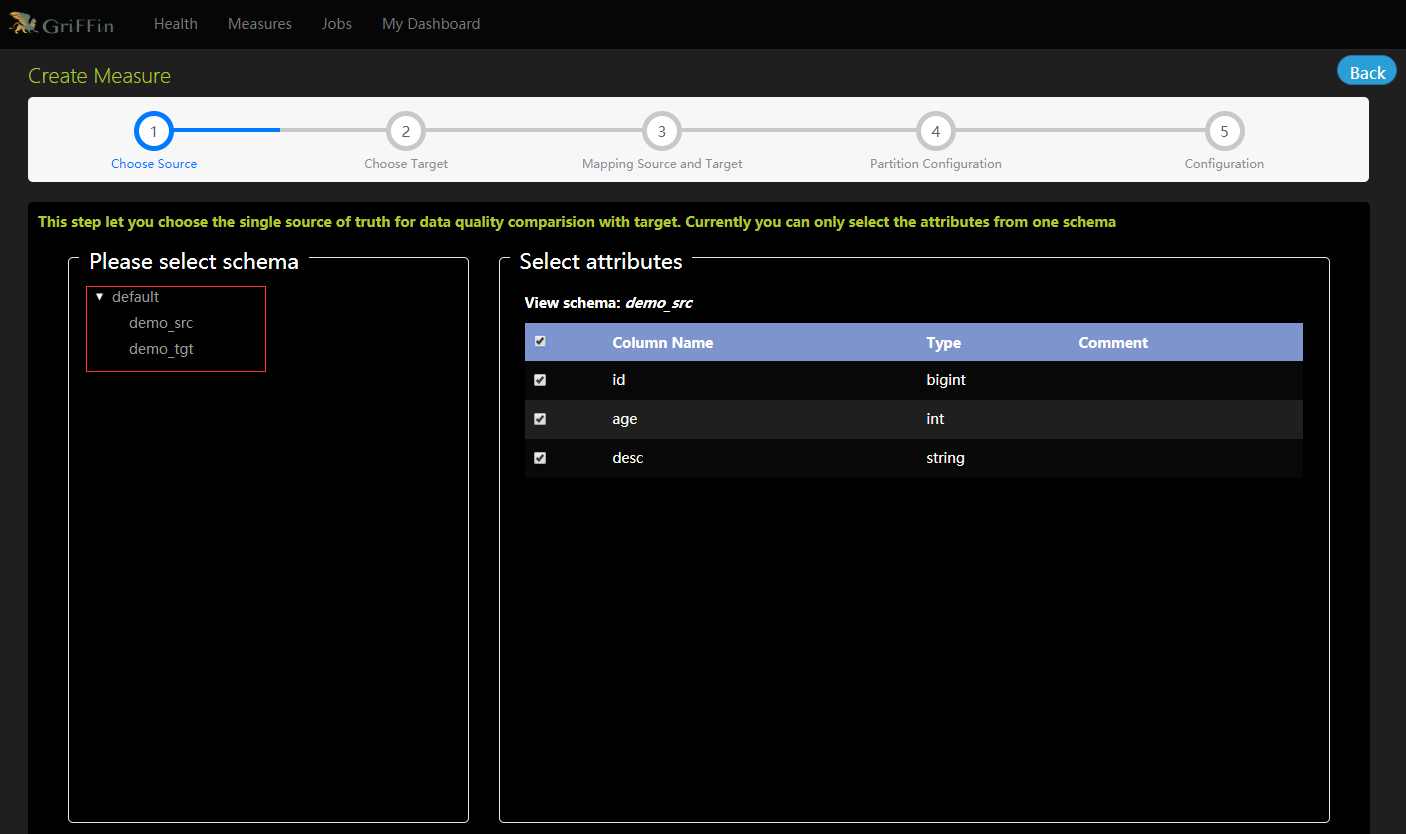
- 选择目标,以便与源进行数据质量比较。
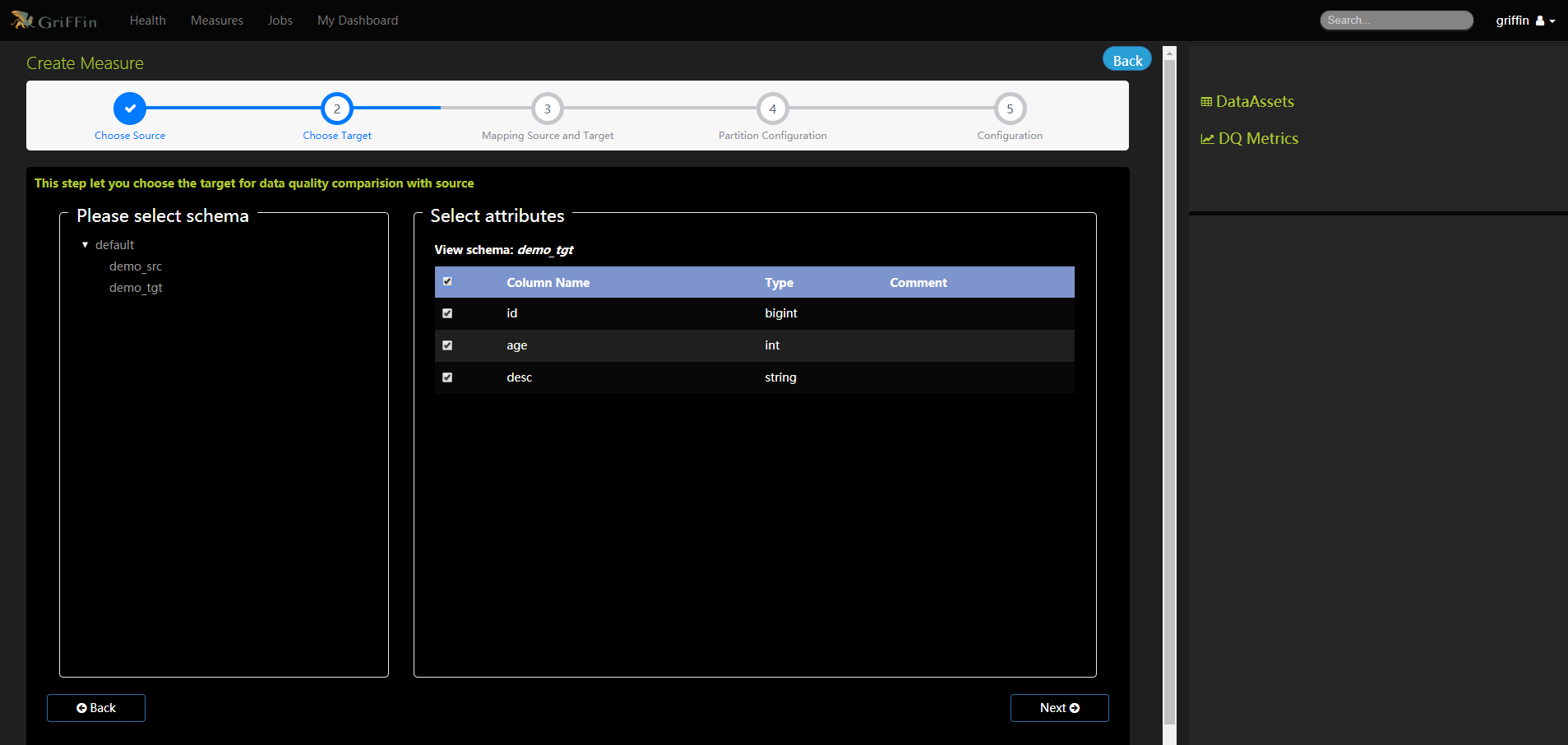
- 将目标数据字段映射到源字段
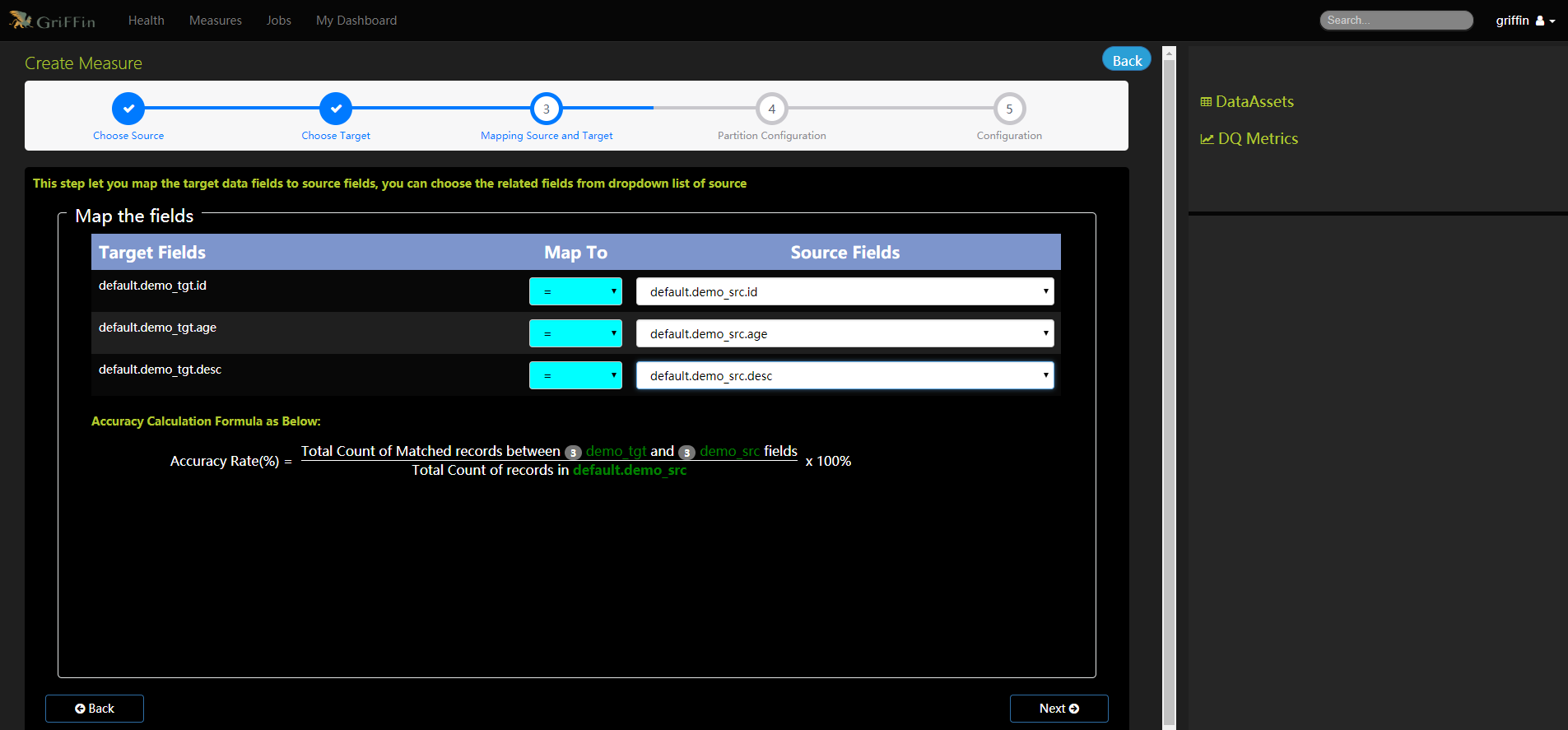
- 完成demo_src和demo_tgt的分区配置
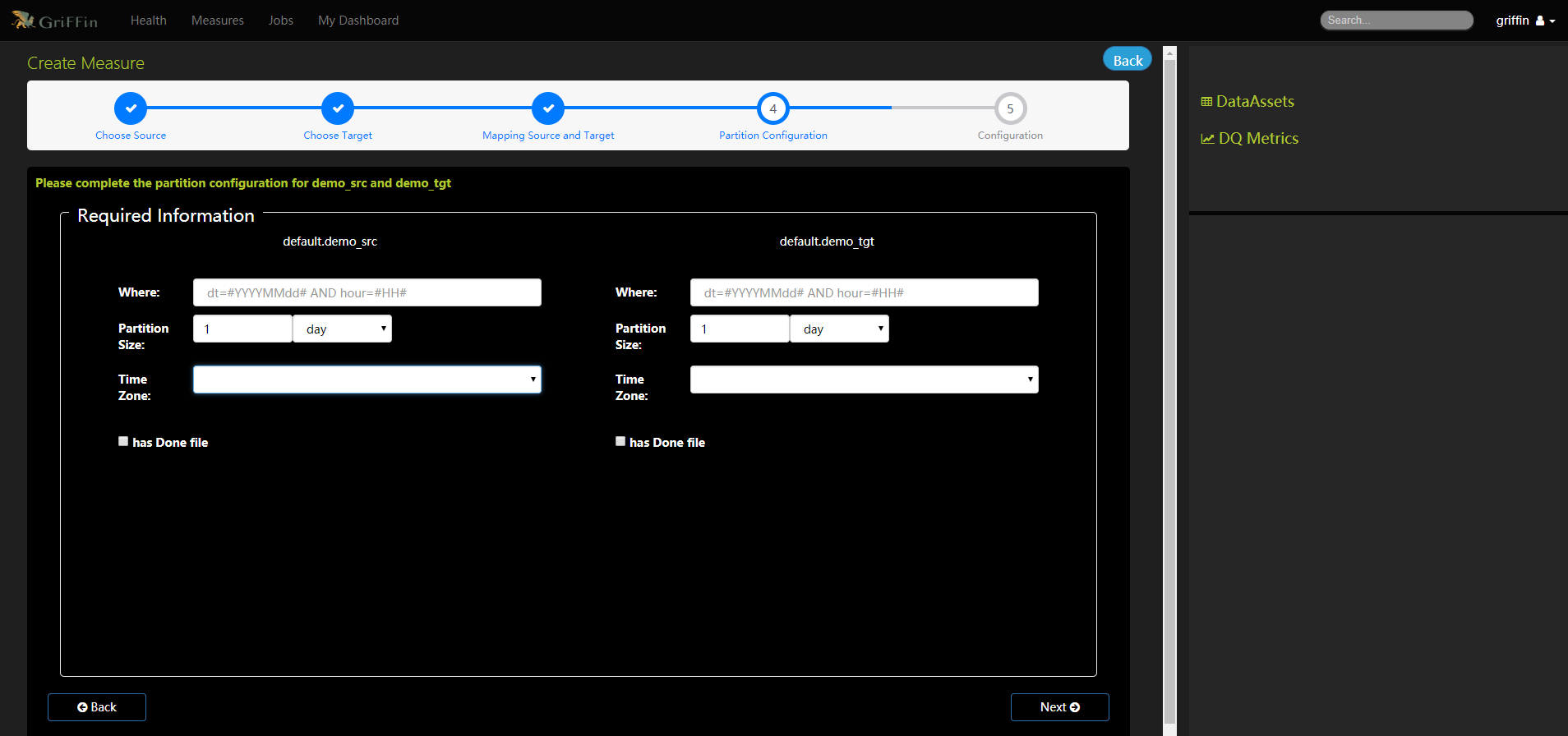
- 填写度量的必要信息
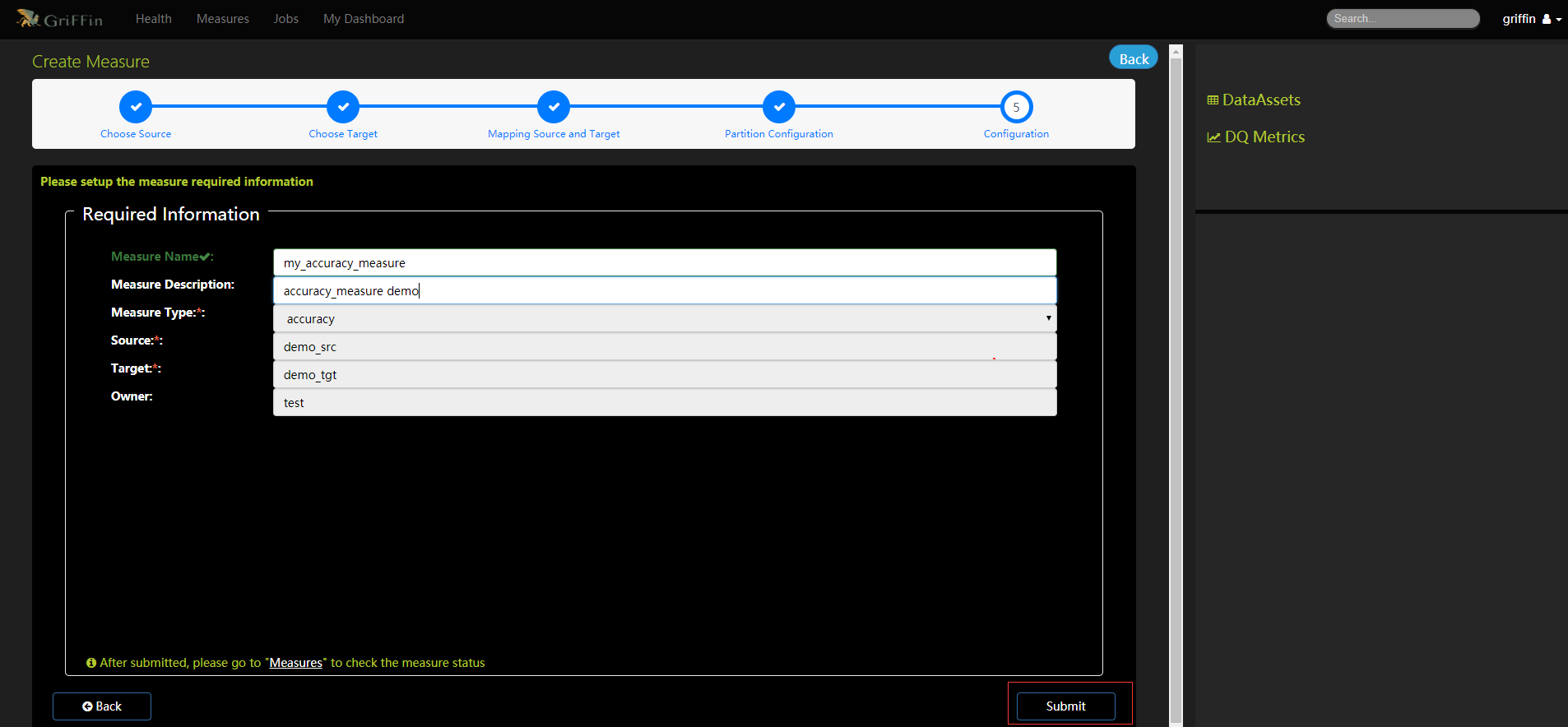
- 确保度量配置并保存
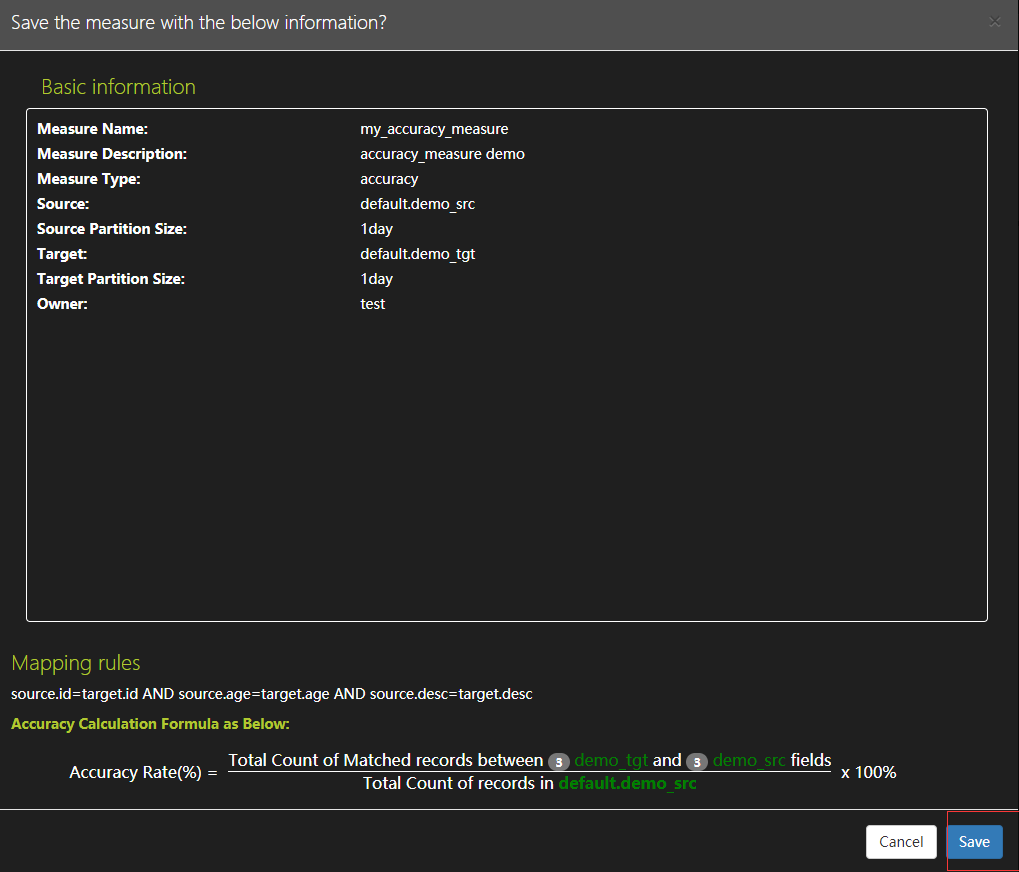
创建作业来定期处理度量,度量名称选择上面my_accuracy_measure,设置每五分钟执行任务,点击提交按钮确认信息再点击保存按钮
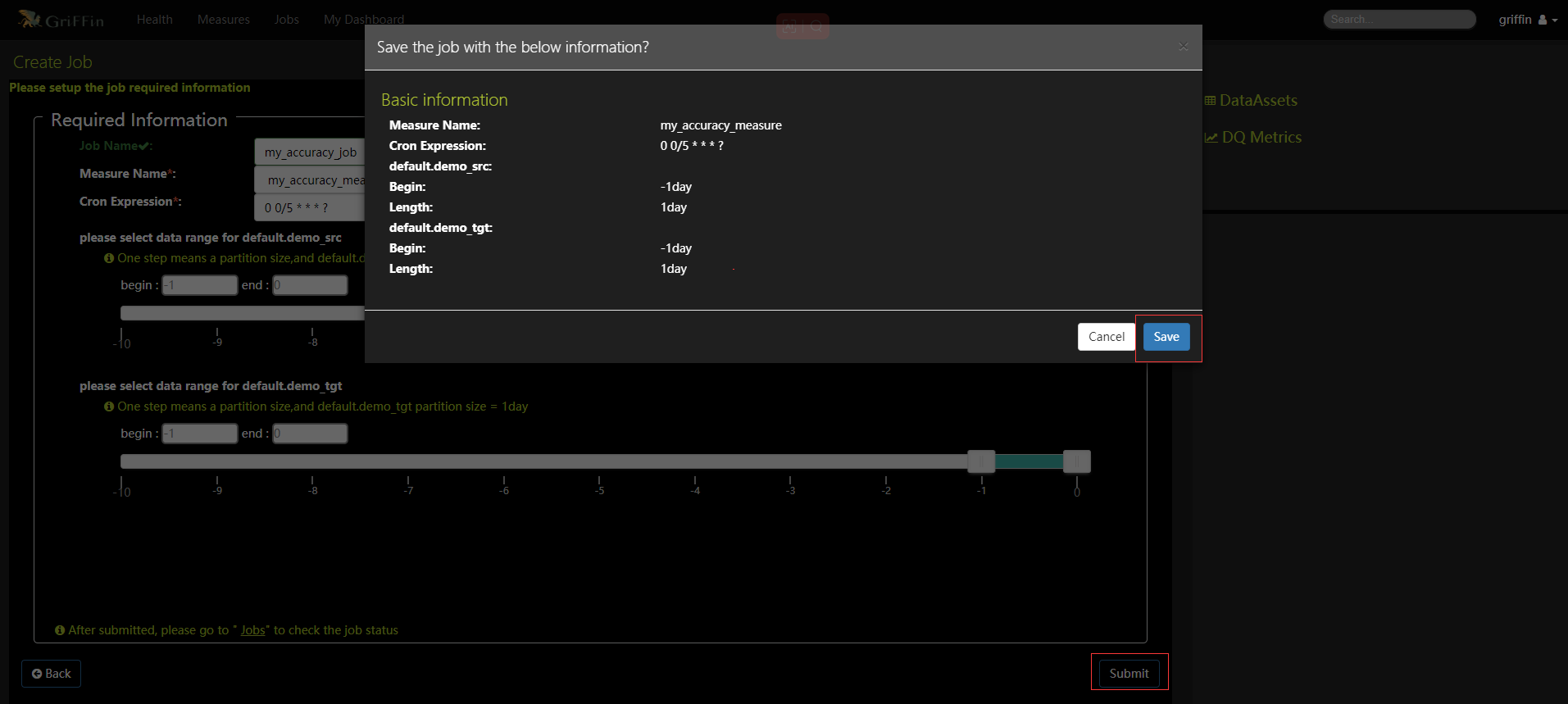
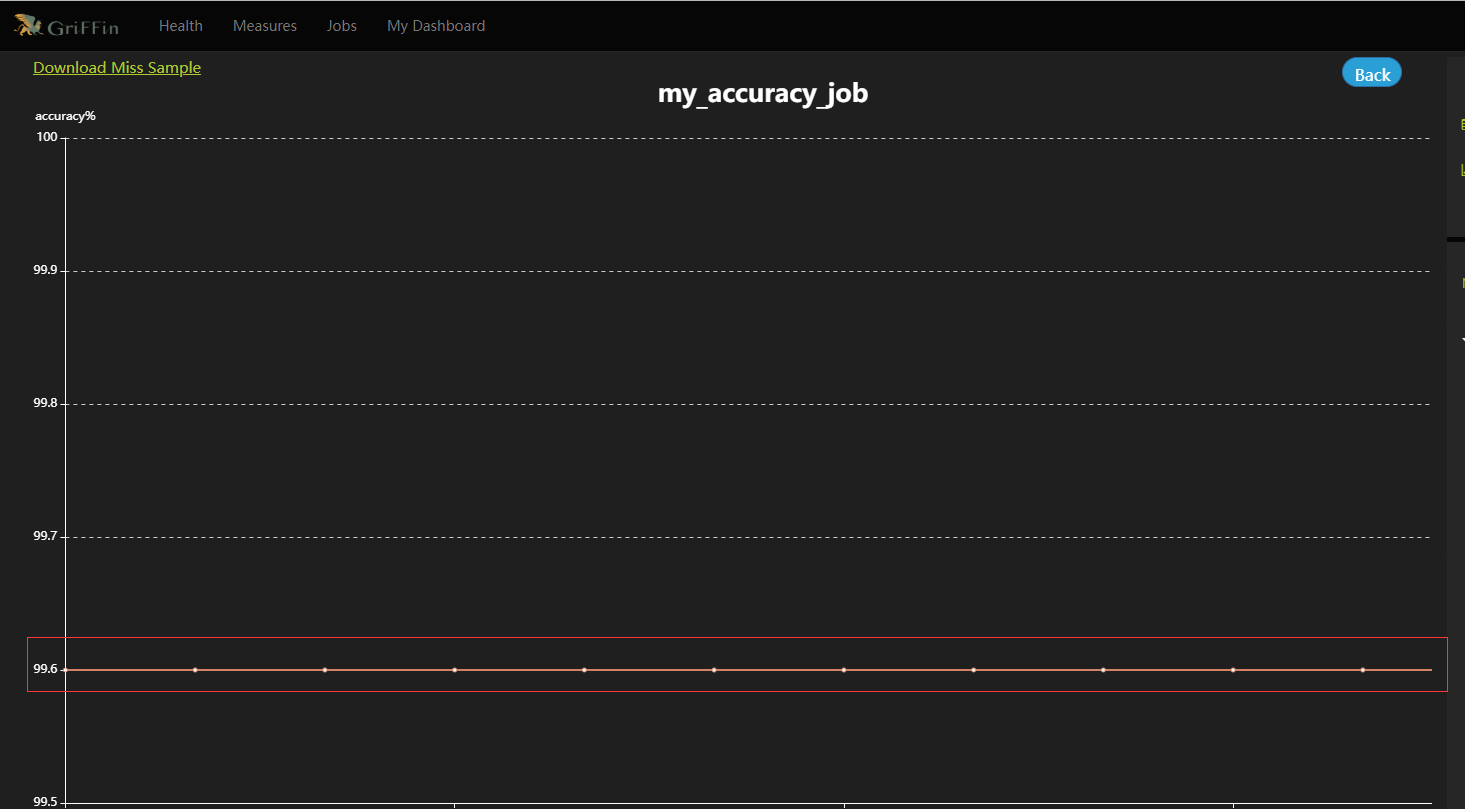
- 热图和仪表板将显示度量的数据图。数据验证度量和分析任务都已配置完成,还可根据指标设置邮件告警等监控信息,等过一段时间后就可以在控制面板上监控的数据质量了。可以在Jobs中查看某个job的Metric可视化展示,也可以直接查看DQ Metrics和My Dashboard。
- 本人博客网站IT小神 www.itxiaoshen.com
数据治理核心保障数据质量监控开源项目Apache Griffin分享的更多相关文章
- 大数据分析中数据治理的重要性,从一个BI项目的失败来分析
很多企业在做BI项目时,一开始的目标都是想通过梳理管理逻辑,帮助企业搭建可视化管理模型与深化管理的精细度,及时发现企业经营管理中的问题. 但在项目实施和验收时,BI却变成了报表开发项目,而报表的需求往 ...
- apache开源项目--Apache Drill
为了帮助企业用户寻找更为有效.加快Hadoop数据查询的方法,Apache 软件基金会发起了一项名为“Drill”的开源项目.Apache Drill 实现了 Google's Dremel. Apa ...
- webfunny前端监控开源项目
前言介绍 如果你是一位前端工程师,那你一定不止一次去解决一些顽固的线上问题,你也曾想方设法复现用户的bug,结果可能都不太理想. 怎样定位前端线上问题,一直以来,都是很头疼的问题,因为它发生于用户的一 ...
- apache开源项目--Apache POI
Apache POI是一个开源的Java读写Excel.WORD等微软OLE2组件文档的项目.目前POI已经有了Ruby版本. 结构: HSSF - 提供读写Microsoft Excel XLS格式 ...
- apache开源项目--Apache Commons Imaging
Apache Commons Imaging 前身是 Apache Commons Sanselan ,这是一个用来读写各种图像格式的 Java 类库,包括快速解析图片的基本信息(大小.色彩空间.IC ...
- 开源数据质量解决方案——Apache Griffin入门宝典
提到格里芬-Griffin,大家想到更多的是篮球明星或者战队名,但在大数据领域Apache Griffin(以下简称Griffin)可是数据质量领域响当当的一哥.先说一句:Griffin是大数据质量监 ...
- DataHub——实时数据治理平台
DataHub 首先,阿里云也有一款名为DataHub的产品,是一个流式处理平台,本文所述DataHub与其无关. 数据治理是大佬们最近谈的一个火热的话题.不管国家层面,还是企业层面现在对这个问题是越 ...
- Nebula Graph 在微众银行数据治理业务的实践
本文为微众银行大数据平台:周可在 nMeetup 深圳场的演讲这里文字稿,演讲视频参见:B站 自我介绍下,我是微众银行大数据平台的工程师:周可,今天给大家分享一下 Nebula Graph 在微众银行 ...
- 使用 Apache Atlas 进行数据治理
本文由 网易云发布. 作者:网易/刘勋(本篇文章仅限知乎内部分享,如需转载,请取得作者同意授权.) 面对海量且持续增加的各式各样的数据对象,你是否有信心知道哪些数据从哪里来以及它如何随时间而变化?采 ...
- 企业级数据治理工作怎么开展?Datahub这样做
大数据发展到今天,扮演了越来越重要的作用.数据可以为各种组织和企业提供关键决策的支持,也可以通过数据分析帮助发现更多的有价值的东西,如商机.风险等等. 在数据治理工作开展的时候,往往会有一个专门负责数 ...
随机推荐
- 卡特兰路径和q,t-enumeration 学一半的笔记
目录 卡特兰 The1st q-analogue of \(C_n\) The 2nd q-analogue of \(C_n\) /定义\(C_n(q)\) The q-Vandermonde co ...
- 太坑了,我竟然从RocketMQ源码中扒出了7种导致消息重复消费的原因
大家好,我是三友~~ 在众多关于MQ的面试八股文中有这么一道题,"如何保证MQ消息消费的幂等性". 为什么需要保证幂等性呢?是因为消息会重复消费. 为什么消息会重复消费? 明明已经 ...
- Linux理论知识
Linux理论知识 理论知识 1.1文件名后缀 1 作用是说明和注释一个文件的性质. 2 与文件类型无关. 1.2常见的压缩文件后缀名 1.gz 2.bz2 3.xz 4.zip 5.tar 6. ...
- PHP 微信三方平台代公众号发起网页授权 获取用户信息
1.获取code 2.通过授权回调地址的code获取用户access_token和open_id 3.通过access_token和open_id 获取用户基本信息 class wx_user { p ...
- Hugging Face 社区中蓬勃发展的计算机视觉
在 Hugging Face 上,我们为与社区一起推动人工智能领域的民主化而感到自豪.作为这个使命的一部分,我们从去年开始专注于计算机视觉.开始只是 Transformers 中 Vision Tra ...
- 深入理解 python 虚拟机:令人拍案叫绝的字节码设计
深入理解 python 虚拟机:令人拍案叫绝的字节码设计 在本篇文章当中主要给大家介绍 cpython 虚拟机对于字节码的设计以及在调试过程当中一个比较重要的字段 co_lnotab 的设计原理! p ...
- 开源不到 48 小时获 35k star 的推荐算法「GitHub 热点速览」
本周的热点除了 GPT 各类衍生品之外,还多了一个被马斯克预告过.在愚人节开源出来的推特推荐算法,开源不到 2 天就有了 35k+ 的 star,有意思的是,除了推荐算法本身之外,阅读源码的工程师们甚 ...
- 通俗易懂的spring事务的传播机制讲解!
spring事务理解 前提两个都是事务的方法,并且两个方法会进行调用,调用方统一使用required 举例有两个方法: required 如果当前上下文存在事务,被调用方则加入该调用方的事务,没有的话 ...
- NetCore 使用 Swashbuckle 搭建 SwaggerHub
什么是SwaggerHub? Hub 谓之 中心, 所以 SwaggerHub即swagger中心. 什么时候需要它? 通常, 公司都拥有多个服务, 例如商品服务, 订单服务, 用户服务, 等等, 每 ...
- 存储论——经济订货批量的R实现
存储论又称库存理论,是运筹学中发展较早的分支.早在 1915 年,哈李斯(F.Harris)针对银行货币的储备问题进行了详细的研究,建立了一个确定性的存贮费用模型,并求得了最佳批量公式.1934 年威 ...