数据分析day01
数据分析三剑客
- numpy
- pandas(重点)
- matplotlib
numpy模块
NumPy(Numerical Python)是Python语言中做科学计算的基础库。重在于数值计算,也是大部分Python科学计算库的基础,多用于在大型、多维数组上执行的数值运算,
numpy的创建
1.使用np.array()创建
2.s使用plt创建
3.使用np的routines函数创建
- 使用 array()创建一个一维数组
import numpy as np
np.array([1,2,3,4,5])
- 使用array创建一个多维数组
import numpy as np
np.array([[1,2,3],[4,5,6]])
- 数组和列表的区别是什么?
np.array([[1,'two','3'],[2.2,3,5]])
# 结果array([['1', 'two', '3'], ['2.2', '3', '5']], dtype='<U21')
数组中存储的数据元素类型必须是统一类型
优先级:字符串>浮点型>整数,只要有一个字符串,那么返回的数组中的元素全部为字符串,依次类推
- 将外部的一张图片读取加载到numpy数组中,然后尝试改变数组元素的数值查看对原始图片的影响
import matplotlib.pyplot as plt
# imread可以返回一个numpy数组
img_arr = plt.imread('./adv01.jpg') # 返回的是三维数组,看中括号可以看出来
# 将返回的数组的数据进行图像的展示 imshow
plt.imshow(img_arr)

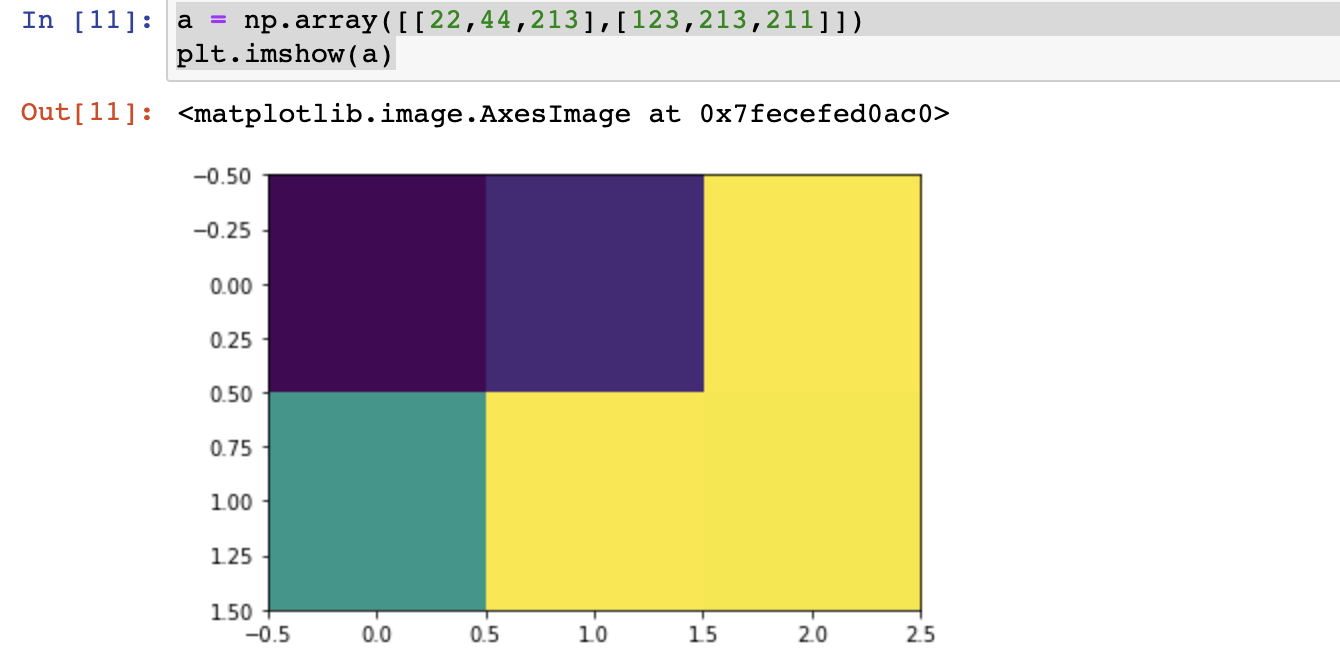
# 随意定义一个二维数组,并让其以图像形式显示
a = np.array([[22,44,213],[123,213,211]])
plt.imshow(a)
# 对原始的图像数据进行减法,让每一个数组中的元素都减去100
plt.imshow(img_arr - 100) # 表示数组中的每个元素都减去100

- ones()
import numpy as np
np.ones(shape=(3,4)) #shape指定形状 ,3行,4列,二维数组
np.ones(shape=(3,4,5)) # 三维数组


- zeros()
# 用法跟ones一样
import numpy as np
np.zeros(shape=(3,4)) #shape指定形状 ,3行,4列,二维数组
np.zeros(shape=(3,4,5)) # 三维数组


- linespace()
np.linspace(0,50,num=10) # 只能返回一维形式的等差数列

- arange()
np.arange(0,50,5) # 从0到50,相隔5,返回一维数组

- random.randint()
np.random.randint(0,100,size=(4,5)) # 返回4行5列的二维随机数组 size指定形状

- random.random()
np.random.random(size=(3,4)) # 随机范围0~1 二维数组

numpy的常用属性
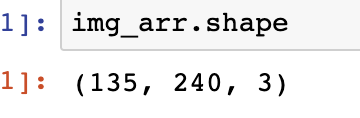
- shape
import matplotlib.pyplot as plt
img_arr = plt.imread('./adv01.jpg')
img_arr.shape # 返回数组的形状
- ndim
img_arr.ndim # 返回数组维度

- size
img_arr.size #返回数组元素总个数

- dtype
img_arr.dtype # 返回的是数组元素的数据类型,uint8无符号数据类型
type(img_arr) #numpy.ndarray指的就是数组

numpy的数据类型
arr = array(dtype='?') # 可以设定数据类型
arr.astype('?') # 可以修改数据类型
# 例子
arr = np.array([1,2,3], dtype="float32")
arr.astype('int')


numpy的数值类型实际上是dtype对象的实例,并对应唯一的字符,包括np.bool,np.int32,np.float32....等
numpy的索引和切片操作(重点)
- 索引操作和列表同理
arr = np.random.randint(0,100,size=(5,6))
arr[1] # 取出二维数组中下标为1的数组


# 切出数组的前两行数组
arr[:2]

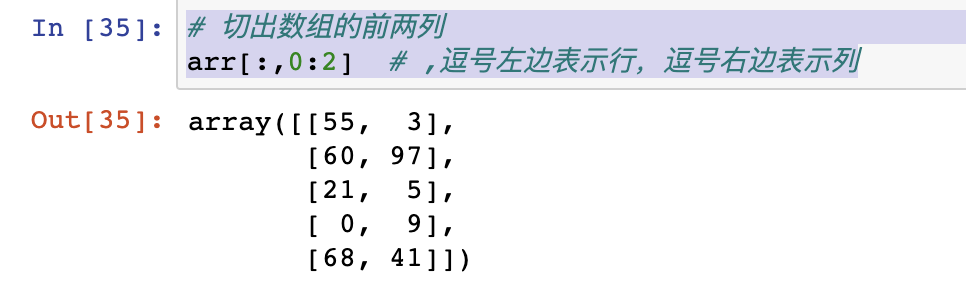
# 切出数组的前两列
arr[:,0:2] # ,逗号左边表示行,逗号右边表示列
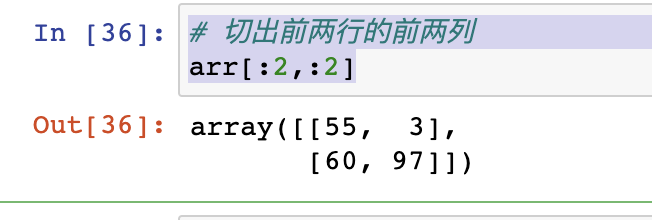
# 切出前两行的前两列
arr[:2,:2]
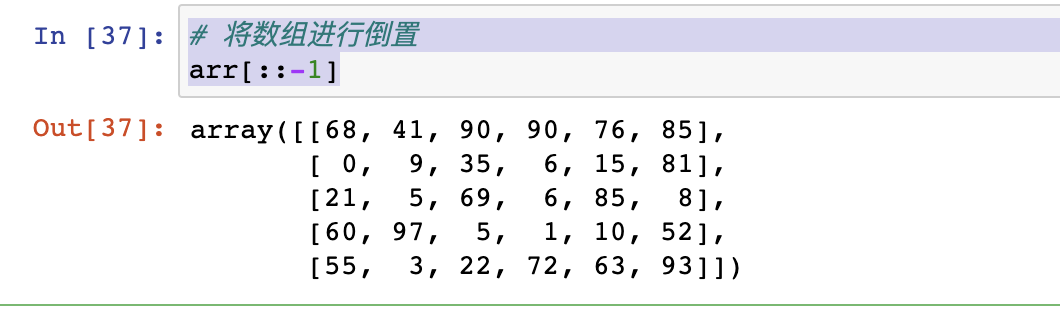
# 将数组进行倒置
arr[::-1]
# 列倒置
arr[:,::-1]

# 将图片进行左右翻转
plt.imshow(img_arr) #三维数组
img = img_arr[:,::-1,:] #因为是三维数组所以中间表示的是列的翻转
plt.imshow(img)

# 上下翻转
plt.imshow(img_arr[::-1])

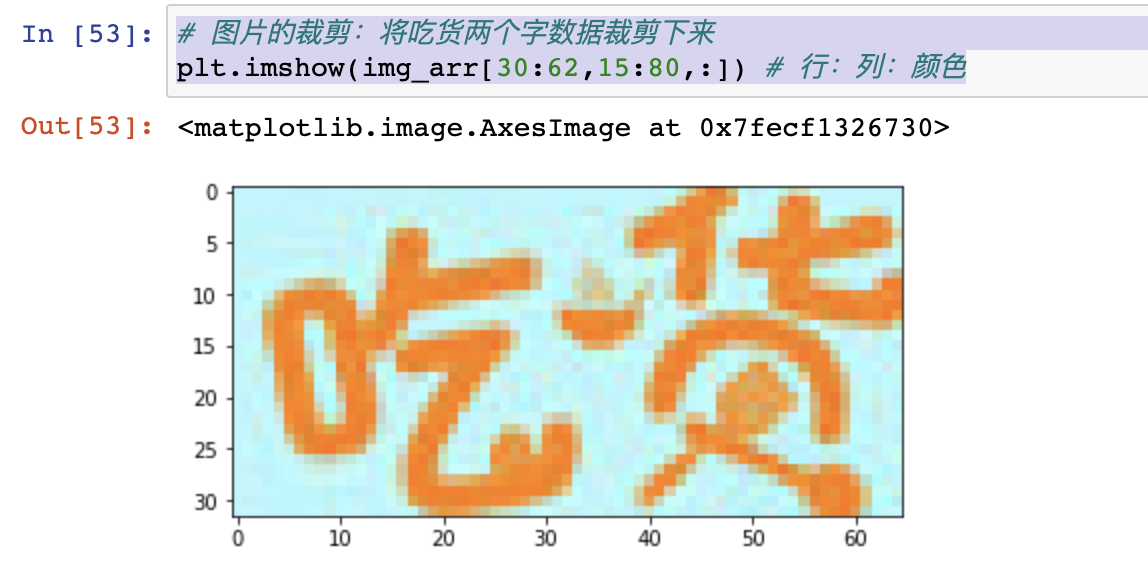
# 图片的裁剪:将吃货两个字数据裁剪下来
plt.imshow(img_arr[30:62,15:80,:]) # 行:列:颜色
变形reshape
# 将二维数组变形为一维数组
#arr.shape #(5,6) 5行6列二维数组,30个容量
arr_1 = arr.reshape((30,)) # 变为一维数组存放容量30,变形的容量数量要和之前的容量数量一致
# 将一维数组变多维
arr_1.reshape((2,15)) # 2行15列,容量一定要保持一致
arr_1.reshape((-1,5)) # 6行5列, -1表示自动计算行数或列数
级联操作
- 将多个numpy数组进行横向或者纵向的拼接
# 列跟列拼接
np.concatenate((arr,arr), axis=0) # 参数axis表示轴向,0:列,1:行
# 行跟行拼接
np.concatenate((arr,arr), axis=1) # 参数axis表示轴向,0:列,1:行
# 注意
当两个数组要进行拼接,必须两个数组的行跟行的数量,列跟列的数量都要一致,不然的话只有行一致,那么只能拼接行,列拼接会报错,反之列一致,行报错。


# 图片的宫九格
img_arr_3 = np.concatenate((img_arr,img_arr,img_arr), axis=1) #横向拼接
img_arr_9 = np.concatenate((img_arr_3,img_arr_3,img_arr_3), axis=0) #把横向 拼接的图片再纵向拼接
plt.imshow(img_arr_9)

常用的聚合操作
- sum,max,min,mean
arr.sum() #计算所有的和
arr.sum(axis=0) # 计算每列的和
arr.sum(axis=1) # 计算每行的和
arr.max() #计算所有数的最大值
arr.max(axis=0) #计算每列的最大值
arr.max(axis=1) #计算每行的最大值
arr.mean() # 求均值
。。。
常用的数学函数
- NumPy提供了标准的三角函数:sin()、cos()、tan()
- numpy.around(a,decimals)函数返回指定数字的四舍五入值。
参数说明:a:数组,decimals:舍入的小数位。默认值为0。如果为负,整数将四舍五入到小数点左侧的位置。
np.around([33.4,51.2,66.8],decimals=0)
np.around([33.4,51.2,66.8],decimals=1) # 小数第一位
np.around([33.4,51.2,66.8],decimals=-1) #-1表示从整数的个位数开始计算四舍五入,33.4按33的个位数3来计算四舍五入,3舍去,即为30



函数的统计函数
- numpy.amin()和numpy.amax(),用于计算数组中的元素沿指定轴的最小 ,最大值
- numpy.ptp():计算数组中元素最大值与最小值的差(最大值-最小值)
- numpy.median() 函数用于计算数组a中元素的中位数(中值)
np.median(arr,axis=0) # 求每列的中位数
- 标准差std():标准差是一组数据平均值分散程度的一种度量。
# 标准差
arr.std(axis=0) #每列的标准差
公式:std=sqrt(mean((x-x.mean())**2))
如果数组是[1,2,3,4],则其平均值为2.5。因此,差的平方是[2.25,0.25,0.25,2.25],并且其平均值的平方根除以4,即sqrt(5/4),结果为1.1180339887498949。
- 方差var():统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数,即mean((x-x.mean())**2).换句话说 ,标准差是方差的平方根。
矩阵相关
- NumPy中包含了一个矩阵库 numpy.matlib,该模块中的函数返回的是一个矩阵,而不是ndarry对象,一个的矩阵是一个由行(row)列(column)元素排列成的矩形阵列
- numpy.matlib.identity()函数返回给定大小的单位矩阵。单位矩阵是个方阵,从左上角到右下角的对角线(称为主对角线)上的元素均为1,除此以外都为0。
转置矩阵
arr = np.random.randint(0,100,size=(5,6))
arr.T #将原始数组的行变成列,列变成行
矩阵相乘
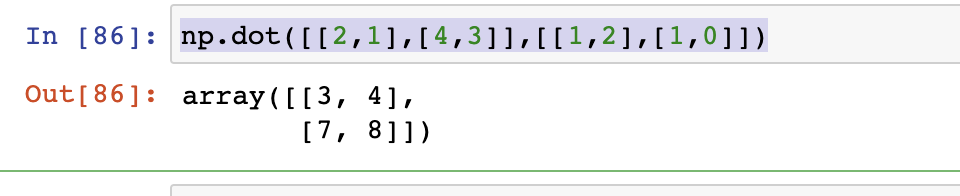
- numpy.dot(a,b,out=None)
np.dot([[2,1],[4,3]],[[1,2],[1,0]])
a:ndarray 数组
b:ndarray 数组


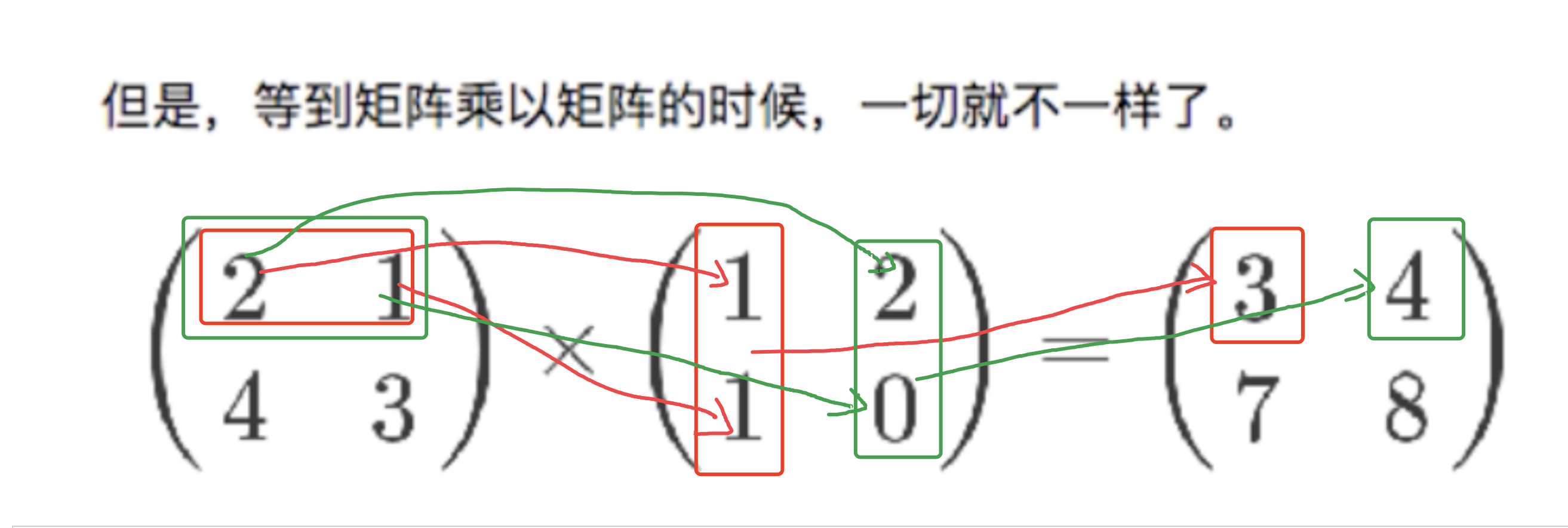
矩阵乘以矩阵:
第一个矩阵第一行的每个数字(2和1),各自乘以第二个矩阵第一列对应位置的数字(1和1),然后将乘积相加(2x1+1x1),得到结果矩阵左上角的那个值3。也就是说,结果矩阵第m行与第n列交叉位置的那个值,等于第一个矩阵第m行与第二个矩阵第n列,对应位置的每个值的乘积之和。
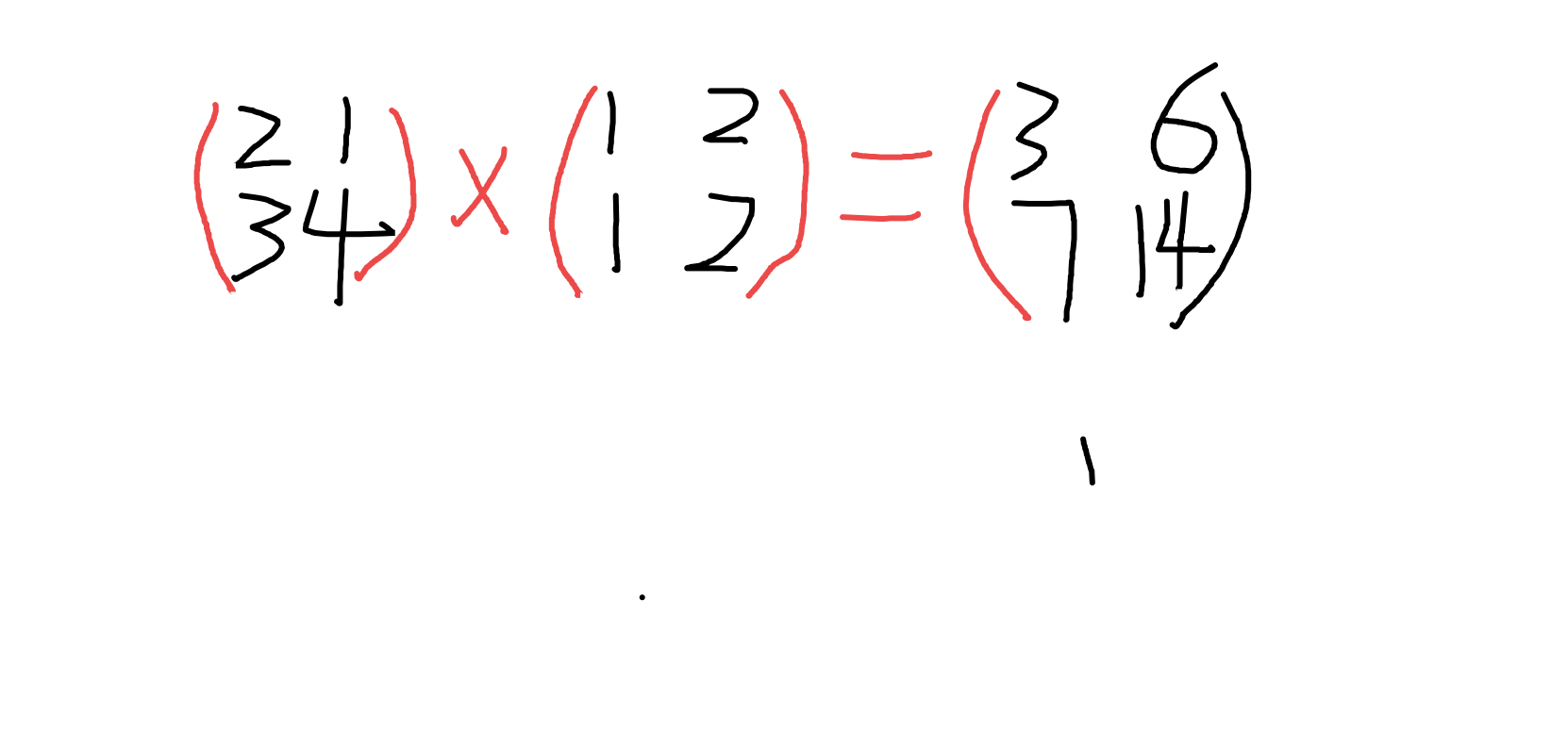

pandas基础操作
为什么学习pandas
numpy已经可以帮助我们进行数据的处理了,那么学习pandas的目的是什么?
numpy能够帮助我们处理的是数值型的 数据,当然在数据分析中除了数值型的数据还有好多其它类型的数据(字符串,时间序列),那么pandas就可以帮我们很好的处理除了数值型的其它数据
什么是pandas
- 首先来认识pandas的两个常用的类
- Series
Series是一种类似与一维数组的对象,由下面两个部分组成:
-values:一组数据(ndarray类型)
-index:相关的数据索引标签
Series的创建
-由列表或numpy数组创建
-由字典创建
import pandas as pd
from pandas import Series,DataFrame
import numpy as np
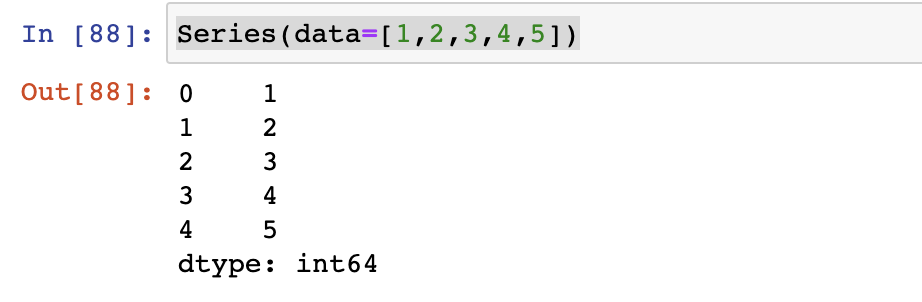
Series(data=[1,2,3,4,5])
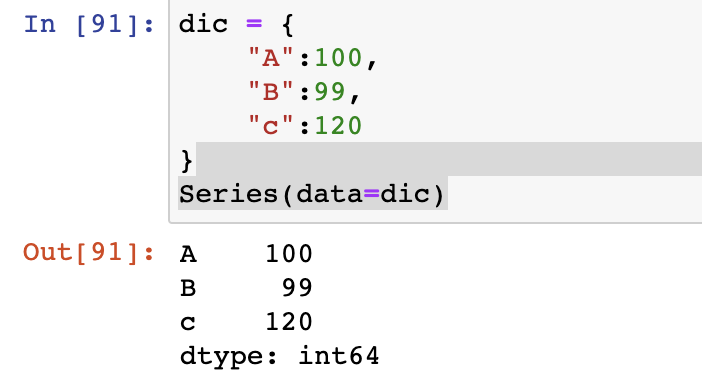
dic = {
"A":100,
"B":99,
"c":120
}
Series(data=dic)
# Series的索引
- 隐式索引:默认形式的索引(0,1,2...),向上面的列表,打印出来的结果就为隐式索引
- 显示索引:自定义的索引,向上面的字典,打印出来的结果就为显示索引
Series(data=np.random.randint(0,100,size=(3,))) #Series类似于一个一维的数组源,所以只能存放一维数组
Series(data=np.random.randint(0,100,size=(3,)),index=['A','B','C']) # 使用index指定使用我们指定的索引
# Series的索引和切片
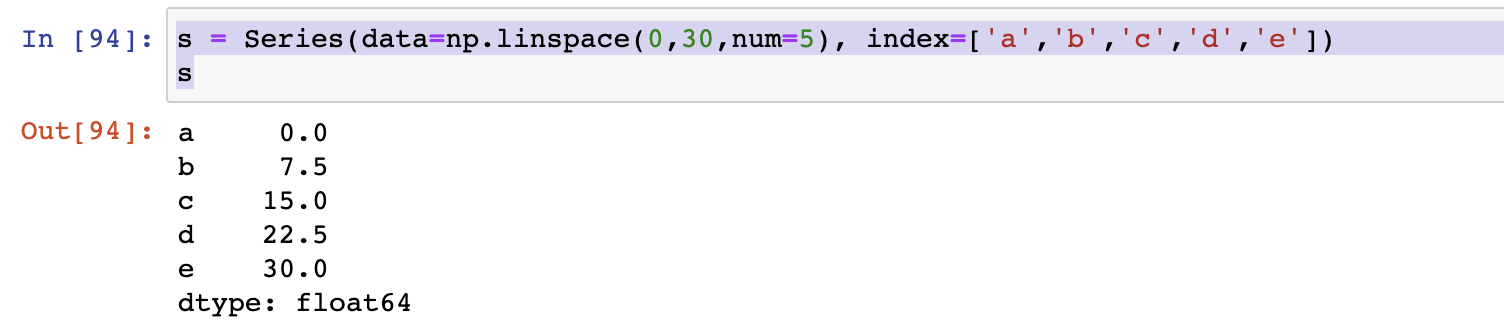
s = Series(data=np.linspace(0,30,num=5), index=['a','b','c','d','e'])
s
s[1] # 取索引下标1 隐式
s['b'] # 显示,也是取索引b的值
s.b #显示,也是取索引b的值
s[0:3] # 切片
s['a':'c'] # 切片
# Series的常用属性
- shape 形状
- size 元素个数
- index 索引
- values 值
# Series的常用方法
- head(),tail()
s.head(3) #只显示前3个
s.tail(2) # 只显示后2个
- unique(),nunique()
s = Series(data=[1,1,2,2,3,3,4,4,5,5,5,6,6,6,6])
s.unique() # 去除重复元素
s.nunique() # 统计去重后的元素个数
- isnull(),notnull()
Series的算术运算:法则:索引一致的元素进行算数运算否则补空
s1 = Series(data=[1,2,3,4,5], index=['a','b','c','d','e'])
s2 = Series(data=[1,2,3,4,5], index=['a','b','f','d','e'])
s = s1+s2
打印结果:s1和s2对应的相同的索引元素值相加,索引不一致的不会相加并赋值为NaN,即c=NaN,f=NaN
s.isnull() # 检测Series哪些元素为空,为空则返回True,否则返回False
s.notnull() # 检测Series哪些元素不为空,不为空返回True,否则返回False
# 想要将s中的非空数据取出
s[[True,True,False,True,True,False]] #打印的结果为True对应的值,False的值则不取
s.[s.notnull()] # 空值过滤,取出结果跟上面的一致
- add(),sub(),mul(),div()



- DataFrame
DataFrame是一个【表格型】的数据结构。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
- 行索引:index
- 列索引:columns
- 值:values
DateFrame的创建
- ndarray创建
- 字典创建
DataFrame(data=np.random.randint(0,100,size=(5,6)),columns=['a','b','c','d','e','f'],index=['a','b','c','d','e']) #columns可以指定列索引,index指定行索引
dic = {
"name":['jay','tom','bobo'],
"salay":[1000,2000,3000]
}
DataFrame(data=dic,index=['a','b','c']) #index设置索引
# DataFrame的属性
# values,columns,index,shape
df.values() # 返回数组,二维数组
df.columns # 返回列索引
df.index # 返回行索引
df.shape # 返回形状(5,6) 5行6列
# DataFrame索引操作
1.对行进行索引
# 索引取行
df.loc['a'] # loc后面跟显示索引
df.iloc[0] #iloc后面跟隐式索引
df.iloc[[1,2,3,4]] # 取多行
2.对列进行索引
# 对列进行索引(如果指定了列索引,只可以使用显示列索引,如果没有指定 ,则可以使用隐式列索引)
df['a']
df[['a','b','c']] # 取出多列
3.对元素进行索引
# 取元素
df.loc['a','d'] # 取a行d列的值
df.iloc[2,3] #取第二行第三列的值
# 取多个元素
df.iloc[[1,2],3] # 取第一行第三列的值和第二行第三列的值
# DataFrame的切片操作
1.对行进行切片
# 切行
df[0:3] # 可以隐式切片,只能取到第二行
df['a':'d'] #可以显示切片,但是可以取到d行的值
2.对列进行切片
df.iloc[:,0:3] # 逗号左边是行,右边是列


练习
1.假设ddd是期中考试成绩,ddd2是期末考试成绩,请由创建ddd2,并将其与ddd相加,求期中期末平均值
dic = {
'张三':[100,90,90,100],
'李四':[0,0,0,0]
}
df = DataFrame(data=dic, index=['语文','数学','英语','理综'])
qizhong = df
qimo = df
(qizhong + qimo) / 2 # 求平均成绩
2.假设张三期中考试数学被发现作弊,要记为0分,如何实现?
qizhong.loc['数学','张三'] = 0
qizhong
3.李四因为举报张三作弊立功,期中考试所有科目加100分,如何实现?
qizhong.loc[:,'李四'] = 100
qizhong
4.后来老师发现有一道题出错了,为了安抚学生情绪,给每位学生每个科目都加10分,如何实现?
qizhong+=10
qizhong
时间数据类型转换
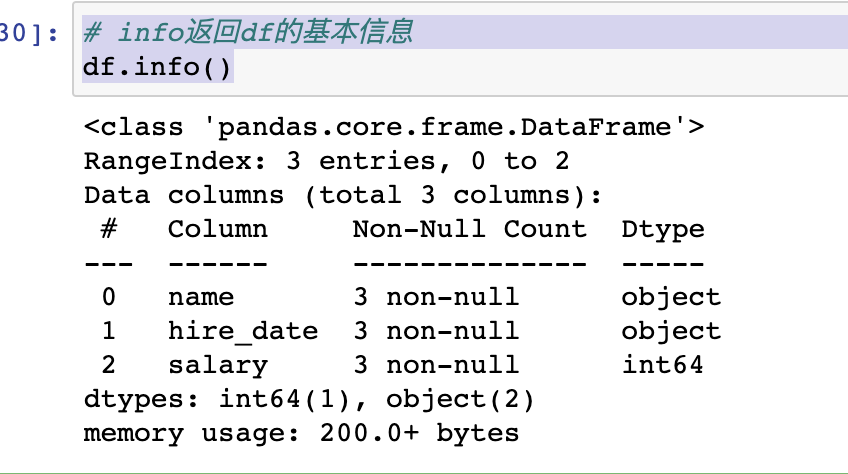
# info返回df的基本信息
df.info()
# 想要将字符串形式的时间数据转换成时间序列类型
df['hire_date'] = pd.to_datetime(df['hire_date'])
df.info()


将某一列设置为行索引
df.set_index()
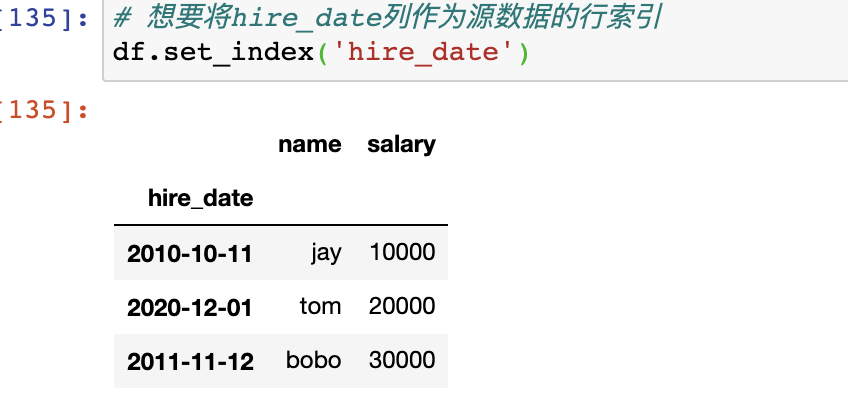
# 想要将hire_date列作为源数据的行索引
df.set_index('hire_date')
案例
需求:股票分析
1.使用tushare包获取某股票的历史行情数据。
df = ts.get_k_data(code="600519", start='1999-01-10') # code是股票代码
# 将df的数据存储到本地:to_xxx()
df.to_csv('./maotai.csv') #to_后面还可以跟很多,excel,sql等等
# 加载外部数据到df中:read_xxx()
df = pd.read_csv('./maotai.csv')
# 将Unnamed: 0列进行删除
# 在drop系列的函数中labels为列索引,axis=0表示的是行,1表示的是列
df.drop(labels='Unnamed: 0',axis=1) #返回的是被删除后的新的数据,原来的df中还是原来的数据
df.drop(labels='Unnamed: 0',axis=1,inplace=True) #inplace=True表示将删除的数据作用到原始数据中,即原数据也会被删除
# 查看df信息
df.info()
# 将date列的字符串类型的时间转换为时间序列类型
pd.to_datetime(df['date'])
# 将date列作为源数据的行索引
df.set_index(keys='date', inplace=True)
2.输出该股票所有收盘比开盘上涨3%以上的日期
# (收盘-开盘)/开盘 > 0.03
(df['close']-df['open']) / df['open'] > 0.03 # 返回bool值
#经验:在df的相关操作中如果一旦返回了布尔值,下一步马上将布尔值作为原始数据的行索引
# 发现布尔值可以作为df的行索引,可以直接取出true对应的行数据
df.loc[[True,True,False,False,True]]
# 将满足需求的行数据获取(收盘比开盘上涨3%以上)
df.loc[(df['close']-df['open']) / df['open'] > 0.03 ] #返回的都是True所对应的所有数据
# 获取满足需求的日期
df.loc[(df['close']-df['open']) / df['open'] > 0.03 ].index
3.输出该股票所有开盘比前日收盘跌幅超过2%的日期
#(开盘-前日收盘) / 前日收盘 < -0.02 # 负数表示跌幅
# 让整体close收盘的数据整体下移
# df['close'].shift(1) 1下移,-1上移
df.loc[(df['open']- df['close'].shift(1)) / df['close'].shift(1) < -0.02].index
4.假如我从2010年1月1日开始,每月第一个交易日买入1手股票,每年最后一个交易日卖出所有股票,到今天为止,我的收益如何?
# 买股票
- 每月的第一个交易日根据开盘价买入一手股票
- 一个完整的年需要买入12次12手1200支股票
# 卖股票
- 每年最后一个交易日(12-31)根据开盘价卖出所有的股票
- 一个完整的年需要卖出1200支股票
- 注意:如果不是年末最后一个月,则如果是2020年7月这个人只能买入700支股票,几个月就买几个月*100支股票,且无法卖出,但是在计算总收益的时候需要将剩余股票的价值也计算在内
- 不是年末最后一个月的话,剩余股票价值如何计算:
- 700(700表示几个月*100支)*买入当日的开盘价
new_df = df['2010':'2020'] # 如果行索引为时间序列类型数据,可以直接用年份切片 ,字符串就不可以了
# 数据的重新取样resample
df_monthly = new_df.resample(rule="M").first() # M表示月份
#每一个第一个交易日对应的行数据
# 计算买入股票一共花了多少钱
cost = df_monthly['open'].sum() * 100
cost # 5494105.100000001
# 求出卖出股票收入
df_yearly = new_df.resample('A').last() # A表示年
#df_yearly # 存储的是每一年最后一个交易日对应的行数据
recv = df_yearly['open'].sum() * 1200
recv # 6612184.8
# 收益,卖出的钱-买入的钱
salay = recv - cost
salay # 1118079.6999999993
---------------------------------------------------------------------------------------------------------------------------
tushare包的介绍
tushare是财经数据接口包
- 使用 pip install tushare
- 作用:提供相关指定的财经数据
数据分析day01的更多相关文章
- Day01——Python简介
一.Python简介 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC ...
- python学习基础—day01
一. python是什么? 优势:简单, 可以跨平台 劣势:执行效率没有C语言那么高 python是解释型语言,逐行编译解释,在不同的系统windows与Linux,需要不同的解释器来编译. 而编译型 ...
- Day01~15 - Python语言基础
Day01 - 初识Python Python简介 - Python的历史 / Python的优缺点 / Python的应用领域 搭建编程环境 - Windows环境 / Linux环境 / MacO ...
- "利用python进行数据分析"学习记录01
"利用python进行数据分析"学习记录 --day01 08/02 与书相关的资料在 http://github.com/wesm/pydata-book pandas 的2名字 ...
- python初略复习(2)及python相关数据分析模块的介绍
常用模块 Python中的模块在使用的时候统一都是采用的句点符(.) # 就是模块名点方法的形式 import time time.time() import datetime datetime.da ...
- 利用Python进行数据分析 基础系列随笔汇总
一共 15 篇随笔,主要是为了记录数据分析过程中的一些小 demo,分享给其他需要的网友,更为了方便以后自己查看,15 篇随笔,每篇内容基本都是以一句说明加一段代码的方式, 保持简单小巧,看起来也清晰 ...
- 利用Python进行数据分析(10) pandas基础: 处理缺失数据
数据不完整在数据分析的过程中很常见. pandas使用浮点值NaN表示浮点和非浮点数组里的缺失数据. pandas使用isnull()和notnull()函数来判断缺失情况. 对于缺失数据一般处理 ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析(5) NumPy基础: ndarray索引和切片
概念理解 索引即通过一个无符号整数值获取数组里的值. 切片即对数组里某个片段的描述. 一维数组 一维数组的索引 一维数组的索引和Python列表的功能类似: 一维数组的切片 一维数组的切片语法格式为a ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
随机推荐
- F5内核参数的简要学习
前言 最近学习了很长时间的Linux内核参数 但是大部分是纸上谈兵. 也没有一个好的系统用于学习和参照 晚上搜索F5资料时发现F5有一些iso和ova文件 就想着下载学习一下. 看看F5系统默认的参数 ...
- SMEE 国内最新光刻机
- Linux 排除某些目录下 重复jar包的方法
Linux 排除某些目录下 取重复jar包的方法 find . -path ./runtime/java -prune -o -name '*.jar' -exec basename {} \;| s ...
- 简单监控Tomcat连接池大小的命令以及其他简单命令
while true ; do date && echo "当前数据库连接池大小为:" $(jmap -histo `jps |grep caf |awk '{pr ...
- js数组修改后会互相影响
// 假设httpServe 是服务器返回来的数据 // 我们这里有一个需求, // 某一个区域需要对这一份数据进行展示 // 另一个区域需要只需要展示前1条数据 let httpServe = [ ...
- windwos使用FRP方式
FRP使用方法 流程图如下 建议查看流程图哦 访问FRP官方项目 https://freefrp.net 下面是windwos演示 进入网站选择客户端下载 客户端版本选择 windwos是adm64 ...
- x86 x64 arm64的区别
我们常说的高通 865,麒麟990 不是 CPU 是 SoC(System On Chip),SoC 除了 CPU 外,还有 GPU,还有可选的浮点数加速器,专用于深度模型的加速器,等等.除此以外,S ...
- 搭建mongo的replica set
搭建mongo的replica set 前言 安装 构建副本集 加入认证 备份数据 备份数据到本地 数据恢复 搭建mongo的replica set 前言 准备三台机器,相互可以访问的.处理思路,先构 ...
- Flask 之SocketIO库实现绘图表
Flask 默认提供了针对WebSocket的支持插件from flask_socketio import SocketIO 直接通过pip命令安装即可导入使用,前端也需要引入socketIO库文件, ...
- webpack重新打包清空dist文件夹的问题
1.5.20.0以上版本才支持output属性里的clean:true 5.20.0+ 5.20以下版本清除dist文件内容一般使用插件 clean-webpack-plugin, 5.20版本以后o ...