MySQL日志(redo log、binlog)刷盘策略
通过上篇文章,我们知道MySQL是采用两段提交策略来保证事务的原子性的,redo log刷盘的时机是在事务提交的commit阶段采取刷盘的,在此之前,redo log都存在于redo log buffer这块指定的内存区域中。
1:write和fsync区别
这里我们首先要明确两个概念和两个参数:
write:刷盘
fsync:持久化到磁盘
write(刷盘)指的是MySQL从buffer pool中将内容写到系统的page cache中,并没有持久化到系统磁盘上。这个速度其实是很快的。
fsync指的是从系统的cache中将数据持久化到系统磁盘上。这个速度可以认为比较慢,而且也是IOPS升高的真正原因。
2:MySQL日志刷盘控制参数
innodb_flush_logs_at_trx_commit(redo log)
取值0:每次提交事务都只把redo log留在redo log buffer中
取值1:每次提交事务都将redo log 持久化到磁盘上,也就是write+fsync
取值2:每次都把redo log写到系统的page cache中,也就是只write,不fsync
sync_binlog(binlog)
取值0:每次提交都将binlog 从binlog cache中 write到磁盘上,而不fsync到磁盘
取值1:每次提交事务都将binlog fsync到磁盘上
取值N:每次提交事务都将binlog write到磁盘上,累计N个事务之后,执行fsync
3:MySQL没动刷盘场景
在某些特定场景下,redo log会在commit这个动作到来之前进行刷盘操作,例如下面的两种情况会让没有提交的事务的redo log写入磁盘:
1、redo log buffer占用的空间即将达到buffer pool的一般的时候,后台线程会主动刷盘,这个时候,由于事务没有提交,所以仅仅是将redo log buffer中的内容通过write的方法写入到系统的cache中,没有进行fsync的持久化动作。
2、并行提交事务的时候,会顺带将上一个事务的部分redo log从redo log buffer中fsync到磁盘上,例如下面的例子:
假设redo log buffer中的内容如下(假设每个事务的redo log有4部分):
redo log B1
redo log A1
redo log B2
此时,事务B发生了commit操作,而设置的innodb_flush_logs_at_trx_commit的值是1,那么会触发事务B的redo log持久化到磁盘。此时事务A的一部分redo log,也就是redo log A1会被顺带着持久化fsync到磁盘中。
这里还需要说明一点,因为MySQL的innodb存储引擎时需要支持崩溃恢复的,依赖prepare阶段的redo log ,所以,如果innodb_flush_logs_at_trx_commit的值是1,MySQL会在redo log的prepare阶段就进行一次持久化redo log的fsync操作。这个fsync的存在,再加上每秒一次的后台刷盘操作,innodb会认为redo log在commit的时候,就不需要fsync了,只write到文件系统的page cache就够了。
所以,真正的两阶段提交,应该是下图所示:
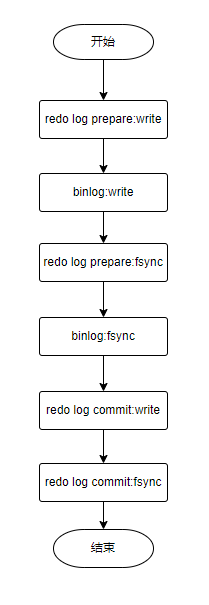
之所以redo log的write和fsync没有连接在一起,其实是考虑到了组提交的功能,分开来进行这两个步骤,在并发的场景下,可以让这一组一次性提交的redo log更多一点,从而一次性fsync更多的组员。
4:MySQL两段提交失败分析
那么两段提交过程中失败会发生什么结果呢?MySQL又是怎样处理的呢?
首先我们先放一下两段提交的图

接下来,我们就一起分析一下在两阶段提交的不同时刻,MySQL 异常重启会出现什么现象。
如果在图中时刻 A 的地方,也就是写入 redo log 处于 prepare 阶段之后、写 binlog 之前,发生了崩溃(crash),由于此时 binlog 还没写,redo log 也还没提交,所以崩溃恢复的时候,这个事务会回滚。这时候,binlog 还没写,所以也不会传到备库。
如果在图中在时刻 B,也就是 binlog 写完,redo log 还没 commit 前发生 crash,那崩溃恢复的时候 MySQL 会怎么处理?
我们先来看一下崩溃恢复时的判断规则。
如果 redo log 里面的事务是完整的,也就是已经有了 commit 标识,则直接提交;
如果 redo log 里面的事务只有完整的 prepare,则判断对应的事务 binlog 是否存在并完整:
a. 如果是,则提交事务;
b. 否则,回滚事务。
这里,时刻 B 发生 crash 对应的就是 2(a) 的情况,崩溃恢复过程中事务会被提交。
那么问题又来了,MySQL是如何判断binlog是不是完整的呢?
我们都知道binlog有三种格式statement、row、mix。其中mix是前两种方式的组合,一个事务的binlog是有完整的格式的,
statement 格式的 binlog,最后会有 COMMIT;
row 格式的 binlog,最后会有一个 XID event。
另外,在 MySQL 5.6 版本以后,还引入了 binlog-checksum 参数,用来验证 binlog 内容的正确性。对于 binlog 日志由于磁盘原因,可能会在日志中间出错的情况,MySQL 可以通过校验 checksum 的结果来发现。所以,MySQL 还是有办法验证事务 binlog 的完整性的。
而且redolog和binlog有一个共同的数据字段,叫 XID。崩溃恢复的时候,会按顺序扫描 redo log:如果碰到既有 prepare、又有 commit 的 redo log,就直接提交; 如果碰到只有 parepare、而没有 commit 的 redo log,就拿着 XID 去 binlog 找对应的事务。这样在两段提交的前提下就能完全保证事务的特性了。
MySQL日志(redo log、binlog)刷盘策略的更多相关文章
- 【Mysql】三大日志 redo log、bin log、undo log
@ 目录 redo log(物理日志\重做日志) binlog(逻辑日志/归档日志) update语句执行流程 Uodolog(回滚日志/重做日志) undo log+redo log保证持久性 re ...
- 【MySQL】redo log --- 刷入磁盘过程
1.redo log基本概念 redo log的相关概念这里就不再过多阐述,网上有非常多的好的资料,可以看下缥缈大神的文章:https://www.cnblogs.com/cuisi/p/652507 ...
- MySQL中redo log、undo log、binlog关系以及区别
MySQL中redo log.undo log.binlog关系以及区别 本文转载自:MySQL中的重做日志(redo log),回滚日志(undo log),以及二进制日志(binlog)的简单总结 ...
- MySQL 中Redo与Binlog顺序一致性问题
首先,我们知道在MySQL中,二进制日志是server层的,主要用来做主从复制和即时点恢复时使用的.而事务日志(redo log)是InnoDB存储引擎层的,用来保证事务安全的.现在我们来讨论一下My ...
- Mysql InnoDB Redo log
一丶什么是redo innodb是以也为单位来管理存储空间的,增删改查的本质都是在访问页面,在innodb真正访问页面之前,需要将其加载到内存中的buffer pool中之后才可以访问,但是在聊事务的 ...
- MySQL中Redo Log相关的重要参数总结
参数介绍 下面介绍.总结一下MySQL的Redo Log相关的几个重要参数:innodb_log_buffer_size.innodb_log_file_size.innodb_log_files ...
- MySQL的redo log结构和SQL Server的log结构对比
MySQL的redo log结构和SQL Server的log结构对比 innodb 存储引擎 mysql技术内幕 log buffer根据一定规则将内存中的log block刷写到磁盘,这个规则是 ...
- MySQL的两种日志类型,redo log,binlog
文章内容学习:极客时间-林晓彬老师-MySQL实战45讲 整理而得 我们知道MySQL数据库在发生意外宕机的情况下,可以将数据恢复到历史的某个时间点,能实现这个功能依靠的是日志,MySQL提供两种类型 ...
- 详细分析MySQL事务日志(redo log和undo log)
innodb事务日志包括redo log和undo log.redo log是重做日志,提供前滚操作,undo log是回滚日志,提供回滚操作. undo log不是redo log的逆向过程,其实它 ...
- 详细分析MySQL事务日志(redo log和undo log) 表明了为何mysql不会丢数据
innodb事务日志包括redo log和undo log.redo log是重做日志,提供前滚操作,undo log是回滚日志,提供回滚操作. undo log不是redo log的逆向过程,其实它 ...
随机推荐
- 优秀的 RocketMQ 可视化管理工具 GUI 客户端
优秀的 RocketMQ 可视化管理工具 GUI 客户端 官网地址:http://www.redisant.cn/rocketmq 快速查看所有 RocketMQ 集群,包括Brokers.Topic ...
- Unlink原理和一些手法
Unlink原理和一些手法 简单介绍一下unlink相关的知识 unlink是利用glibc malloc 的内存回收机制造成攻击的,核心就在于当两个free的堆块在物理上相邻时,会将他们合并,并将原 ...
- Competition Set - AtCoder I
这里记录的是这个账号的比赛情况. ARC172 2024-2-18 Solved:4/6 D(Hard-,2936) 给定所有数对 \((i,j),1\le i\lt j\le n\) 的一个排列 \ ...
- ubuntu_24.04 Noble LTS安装docker desktop启动无窗口及引擎启动失败的解决方法
ubuntu_24.04 LTS安装docker desktop启动无窗口及引擎启动失败的解决方法 1. 安装docker desktop后启动无窗口 现象: 执行sudo apt install . ...
- ansible(6)--ansible的copy和fetch模块
1. copy模块 功能:从 ansible 服务端主控端复制文件到远程主机: copy模块的主要参数如下: 参数 说明 src 复制的源文件路径,若源文件为目录,默认进行递归复制,如果路劲以&quo ...
- JavaScript中对数组.map()、some()、every()、filter()、forEach的区别
1.区别说明 共同点: 不会对原数组发生修改,而是返回新的变量,用变量接收. 不同点: 1.some():返回一个Boolean类型变量,判断是否有元素符合func条件 2.every():返回一个B ...
- Angular快速生成文件基本命令
ng new 作用:创建一个已被初始化的Angular应用 命令选项 参数 说明 --collection -c 指定工程模板 属于高阶操作,暂不知道如何使用 --directory 指定新项目创建的 ...
- PageOffice 6 给SaveFilePage指向的保存地址传参
PageOffice给保存方法传递参数的方式有两种: 通过设置保存地址的url中的?传递参数.例如: poCtrl.setSaveFilePage("/save?p1=1") 通过 ...
- 整理C语言预处理过程语法的实用方法与技巧
预处理 目录 预处理 一.宏定义 数值宏常量 字符串宏常量 用define宏定义注释符号? 程序的编译过程 预处理中宏替换和去注释谁先谁后? 如何写一个不会出现问题的宏函数 do-while-zero ...
- 免费考AI OCP认证,附通关秘籍!
这是一个能让你快速熟悉AI相关技能的考试,由Oracle官方提供,而且限时免费. 它就是OCI Generative AI Professional. 可以看到,目前免费政策正在执行,到今年的7月31 ...