基于GPT搭建私有知识库聊天机器人(一)实现原理
1、成品演示
- 支持微信聊天
- 支持网页聊天
- 支持微信语音对话
- 支持私有知识文件训练,并针对文件提问
步骤1:准备本地文件a.txt,支持pdf、txt、markdown、ppt等
步骤2:上传a.txt,并选择要保存的在哪个知识库
步骤3:对上传的a.txt文件进行训练
步骤4:进行提问(网页和微信)


2、实现原理
目前很多企业希望将ChatGPT的能力应用到企业内部当中,但ChatGPT是个预训练模型,其所能回答的知识主要来源于互联网上公开的通用知识库,对于部分垂直领域和企业内部的私有知识库的问答无法起到很好的效果,因此,针对这类场景,企业可以基于OpenAI提供的模型服务以及相关生态工具(比如langchain、huggingFace等),构建企业自己特有的知识库问答系统,并在内部知识库问答系统之上,再搭建客服问答系统以及其他的企业助手工具。
总体流程如下:

1、将垂直行业领域的知识库文档进行Embedding向量化处理,并将处理后的语义向量Vectors存入向量数据库Vector Database中(这个步骤中还包括对非结构化数据先转化成文本数据,并对长文本进行Splitter分割处理)
2、将用户的问题进行向量化Embedding处理,转化为Vector search
3、将用户问题Vector search 和向量数据库进行查询匹配,返回相似度最高的TopN条知识文本
4、将匹配出的文本和用户的问题上下文一起提交给 LLM,根据Prompt生成最终的回答
3、Embedding(嵌入)
嵌入(Embedding)是一种将文本或对象转换为向量表示的技术,将词语、句子或其他文本形式转换为固定长度的向量表示。嵌入向量是由一系列浮点数构成的向量。通过计算两个嵌入向量之间的距离,可以衡量它们之间的相关性。距离较小的嵌入向量表示文本之间具有较高的相关性,而距离较大的嵌入向量表示文本之间相关性较低。
Embedding模型在许多应用场景中都有广泛的应用。在OpenAI中,文本嵌入技术主要用于衡量文本字符串之间的相关性。
以下是一些常见的应用场景:
- 搜索(Search):根据与查询字符串的相关性对搜索结果进行排序。
- 聚类(Clustering):将文本字符串按照相似性进行分组。
- 推荐(Recommendations):推荐与给定文本字符串相关的项目。
- 异常检测(Anomaly Detection):识别与其他文本字符串相关性较低的异常值。
- 多样性测量(Diversity Measurement):分析文本字符串之间相似性的分布。
- 分类(Classification):根据文本字符串与各标签的相似性进行分类。
下面是本次的应用场景,将知识数据通过嵌入模型查询出向量,并映射保存,然后在应用时将问题也转换成嵌入式,通过相似度算法(比如余弦相似度)对比前期保存的向量,找出TopN的数据,即得到与问题最关联的内容。

4、Embedding Models(嵌入模型)
OpenAI提供一个第二代嵌入(Embeddings)模型(模型ID中用-002表示),以及16个第一代模型(模型ID中用-001表示)。
建议在几乎所有情况下使用text-embedding-ada-002。它更好、更便宜、更简单易用。
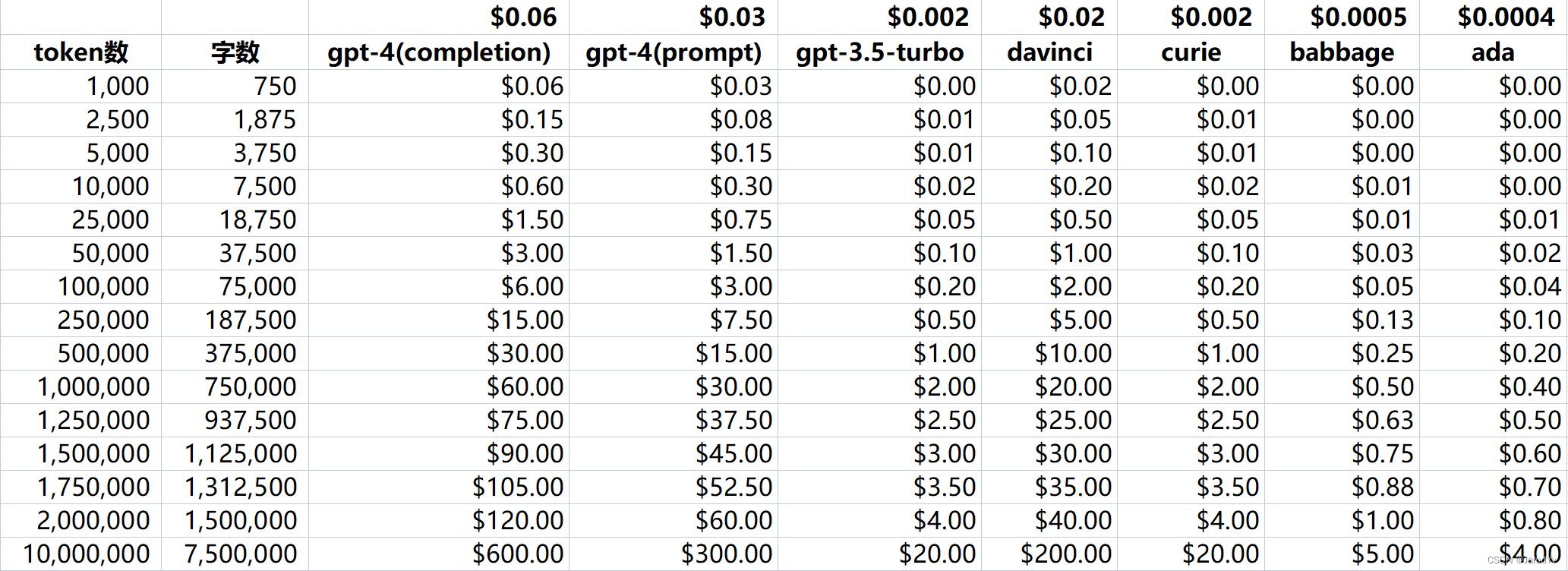
使用价格按输入令牌计价,每1000个token价格为$0.0004,或约为每美元约3,000页(假设每页约有800个token):
| 模型(Model) | 一美元页数(Rough pages per dollar) | BEIR评分 |
|---|---|---|
| text-embedding-ada-002 | 3000 | 53.9 |
| -davinci--001 | 6 | 52.8 |
| -curie--001 | 60 | 50.9 |
| -babbage--001 | 240 | 50.4 |
| -ada--001 | 300 | 49.0 |
5、Completion(补全)
Completions是我们API的核心,提供了一个非常灵活和强大的简单接口。您将一些文本作为提示(Prompt)输入,API将返回一个文本补全(Completion),试图匹配您给它的任何指令或上下文。
Prompt
为一个冰淇淋店写一个标语。
Completion
我们每勺都掌握微笑!
您可以把它想象成一种非常先进的自动完成——模型处理您的文本提示并尝试预测最有可能出现的内容。
6、Temperature(温度)
温度(temperature)是一个介于0和1之间的值,它本质上能让你控制模型在做出这些预测时的信心程度。降低温度(temperature)意味着它将采取更少的风险,补全将更准确和确定性。增加温度(temperature)将产生更多样化的完成度。
即,可以简单理解通过此参数可调整回答的随机性,数值越小随机性越小,反之亦然。
7、Tokens(令牌)
langchain默认模型使用了text-davinci-003。建议使用gpt-3.5-turbo,因为它们会产生更好的结果。目前最好的模型是gpt-4,但需要申请权限。
对于英文文本,1个token约=0.75个单词(token可以短至一个字符或长至一个单词,比如:字符串"ChatGPT is great!"被编码为六个标记:["Chat", "G", "PT", " is", " great", "!"])。
在使用 API 时,您将被计费的 token 数是包括了请求和响应中的所有 token 数量。
8、向量数据库
8.1 向量数据的结构
向量数据的典型结构是一个一维数组,其中的元素是数值(通常是浮点数)。这些数值表示对象或数据点在多维空间中的位置、特征或属性。向量数据的长度取决于所表示的特征维度。下面是一个简单的例子:
假设我们有三个水果:苹果、香蕉和葡萄。我们想用向量数据表示它们的颜色和大小特征。我们可以将颜色分为红、绿、蓝三个通道,将大小分为小、中、大三个类别。因此,我们可以用一个包含 6 个数值的向量表示每个水果的特征。
苹果(红色,中等大小):[1, 0, 0, 0, 1, 0]
香蕉(黄色,大):[0, 1, 0, 0, 0, 1]
葡萄(紫色,小):[0.5, 0, 0.5, 1, 0, 0]
在这个例子中,每个水果都被表示为一个 6 维向量。前三个数值表示颜色信息(红、绿、蓝通道),后三个数值表示大小信息(小、中、大)。
细心的你可能会发现,紫色的向量表示是 [0.5, 0, 0.5],没错,这代表紫色是由红色和蓝色组成。
这种数组结构是典型的向量数据表示。
在推荐系统中,用户和物品可以用向量表示,以捕捉其特征和属性。例如,用户可能对电影类型、导演、演员等方面有偏好,这些偏好可以用一个数值向量表示。通过计算用户向量与物品向量之间的相似度,可以实现个性化的推荐。
在自然语言处理中,词嵌入是一种将文本数据转换为向量数据的方法。例如,使用 Word2Vec 或 GloVe 算法,可以将单词表示为一个包含多个数值的向量。这些数值捕捉了单词的语义特征,使得相似含义的单词在向量空间中彼此靠近。
8.2 向量数据的计算
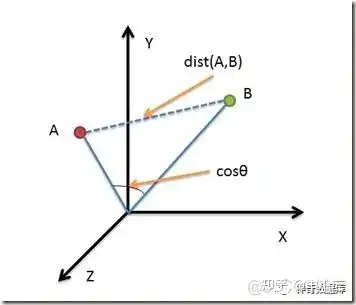
有了向量数据,怎么用呢?这里面有没有一些通用的计算模式?
向量数据的结构非常简单,但针对不同的场景,衍生出了多种计算方法。
比如最常见的有向量相似度计算:衡量两个向量之间的相似程度。常用的相似度度量方法包括余弦相似度(openai推荐)、欧几里得距离、曼哈顿距离等。
基于GPT搭建私有知识库聊天机器人(一)实现原理的更多相关文章
- ChatGirl 一个基于 TensorFlow Seq2Seq 模型的聊天机器人[中文文档]
ChatGirl 一个基于 TensorFlow Seq2Seq 模型的聊天机器人[中文文档] 简介 简单地说就是该有的都有了,但是总体跑起来效果还不好. 还在开发中,它工作的效果还不好.但是你可以直 ...
- 计算机网络课设之基于UDP协议的简易聊天机器人
前言:2017年6月份计算机网络的课设任务,在同学的帮助和自学下基本搞懂了,基于UDP协议的基本聊天的实现方法.实现起来很简单,原理也很简单,主要是由于老师必须要求使用C语言来写,所以特别麻烦,而且C ...
- 版本控制系统之基于httpd搭建私有git仓库
在上一篇博客中,我们主要聊到了git的基本工作原理和一些常用的git命令的使用:回顾请参考https://www.cnblogs.com/qiuhom-1874/p/13787701.html:今天我 ...
- 基于.net搭建热插拔式web框架(实现原理)
第一节:我们为什么需要一个热插拔式的web框架? 模块之间独立开发 假设我们要做一个后台管理系统,其中包括“用户活跃度”.“产品管理”."账单管理"等模块.每个模块中有自己的业务特 ...
- 花了半个小时基于 ChatGPT 搭建了一个微信机器人
相信大家最近被 ChatGPT 刷屏了,其实在差不多一个月前就火过一次,不会那会好像只在程序员的圈子里面火起来了,并没有被大众认知到,不知道最近是因为什么又火起来了,而且这次搞的人尽皆知. 想着这么火 ...
- 基于docer搭建私有gitlab服务器
今天闲着无聊,于是乎想用最近很流行的docker容器搭建一个自己的gitlab的服务器,关于docker和gitlab就不多介绍了,网上查了很多资料,貌似没有一个统一的方法,很乱很杂,而且很容易误导人 ...
- 微信智能机器人助手,基于hook技术,自动聊天机器人
下载地址: 链接:https://pan.baidu.com/s/1N5uQ3gaG2IZu7f6EGUmBxA 提取码:md7z 复制这段内容后打开百度网盘手机App,操作更方便哦 微信智能助手说明 ...
- 基于CentOS搭建私有云服务
系统版本:CentOS 7.2 64 位操作系统 部署 XAMPP 服务 下载 XAMPP(XAMPP 是个集成了多个组件的开发环境,包括 Apache + MariaDB + PHP + Perl. ...
- 智能聊天机器人——基于RASA搭建
前言: 最近了解了一下Rasa,阅读了一下官方文档,初步搭建了一个聊天机器人. 官方文档:https://rasa.com/docs/ 搭建的chatbot项目地址: https://github.c ...
- 0基础搭建基于OpenAI的ChatGPT钉钉聊天机器人
前言:以下文章来源于我去年写的个人公众号.最近chatgpt又开始流行,顺便把原文内容发到博客园上遛一遛. 注意事项和指引: 注册openai账号,需要有梯子进行访问,最好是欧美国家的IP,亚洲国家容 ...
随机推荐
- Kubernetes客户端认证——基于CA证书的双向认证方式
1.Kubernetes 认证方式 Kubernetes集群的访问权限控制由API Server负责,API Server的访问权限控制由身份验证(Authentication).授权(Authori ...
- csv数据集按比例分割训练集、验证集和测试集,即分层抽样的方法
一.一种比较通俗理解的分割方法 1.先读取总的csv文件数据: import pandas as pd data = pd.read_csv('D:\BaiduNetdiskDownload\weib ...
- FBV和CBV的区别(源码分析)
FBV和CBV源码分析 FBV直接调用user方法执行业务代码 CBV相当于在FBV上面封装了一层 from django.contrib import admin from django.urls ...
- 2023成都.NET线下技术沙龙圆满结束
2023年4月15日周六,由MASA技术团队和成都.NET俱乐部共同主办的2023年成都.NET线下技术沙龙活动在成都市世纪城新会展中心知域空间举行,共计报名人数90多人,实际到场60多人,13:30 ...
- 【LeetCode动态规划#07】01背包问题一维写法(状态压缩)实战,其二(目标和、零一和)
目标和(放满背包的方法有几种) 力扣题目链接(opens new window) 难度:中等 给定一个非负整数数组,a1, a2, ..., an, 和一个目标数,S.现在你有两个符号 + 和 -.对 ...
- pytorch在有限的资源下部署大语言模型(以ChatGLM-6B为例)
pytorch在有限的资源下部署大语言模型(以ChatGLM-6B为例) Part1知识准备 在PyTorch中加载预训练的模型时,通常的工作流程是这样的: my_model = ModelClass ...
- 还在玩传统终端,不妨来试试全新 AI 终端 Warp
壹 ❀ 引 最近一段时间,AI领域如同雨后春笋般开始猛烈生长,processon,sentry,一些日常使用的工具都在积极接入AI,那么正好借着AI的风头,今天给大家推荐一款非常不错的智能终端 war ...
- 聊聊开关和CPU之间故事
目录 开关 电报和继电器 门电路 材料学的发展 继电器与哈佛Mark1号 真空管与巨人一号 晶体管与IBM608 计算机2大特性:计算能力和记忆能力 作者:小牛呼噜噜 | https://xiaoni ...
- 2022-03-06:金币路径。 给定一个数组 A(下标从 1 开始)包含 N 个整数:A1,A2,……,AN 和一个整数 B。 你可以从数组 A 中的任何一个位置(下标为 i)跳到下标 i+1,i+
2022-03-06:金币路径. 给定一个数组 A(下标从 1 开始)包含 N 个整数:A1,A2,--,AN 和一个整数 B. 你可以从数组 A 中的任何一个位置(下标为 i)跳到下标 i+1,i+ ...
- 2022-03-05:不相交的线。 在两条独立的水平线上按给定的顺序写下 nums1 和 nums2 中的整数。 现在,可以绘制一些连接两个数字 nums1[i] 和 nums2[j] 的直线,这些直
2022-03-05:不相交的线. 在两条独立的水平线上按给定的顺序写下 nums1 和 nums2 中的整数. 现在,可以绘制一些连接两个数字 nums1[i] 和 nums2[j] 的直线,这些直 ...