Ceph-介绍
Ceph架构简介及使用场景介绍

一、Ceph简介
Ceph是一个统一的分布式存储系统,设计初衷是提供较好的性能、可靠性和可扩展性。
二、Ceph特点
1.高性能
- 采用CRUSH算法,数据分布均衡,并行度高
- 容灾:本地、异地
- 能够支持上千个存储节点的规模,支持TB到PB级的数据
2.高可用
- 副本数可以灵活控制
- 多种故障场景自动进行修复自愈
- 没有单点故障,自动管理
3.高扩展性
随着节点增加,性能线性增长
4.特性丰富
支持三种存储接口:对象存储,块设备存储,文件存储
三、Ceph架构
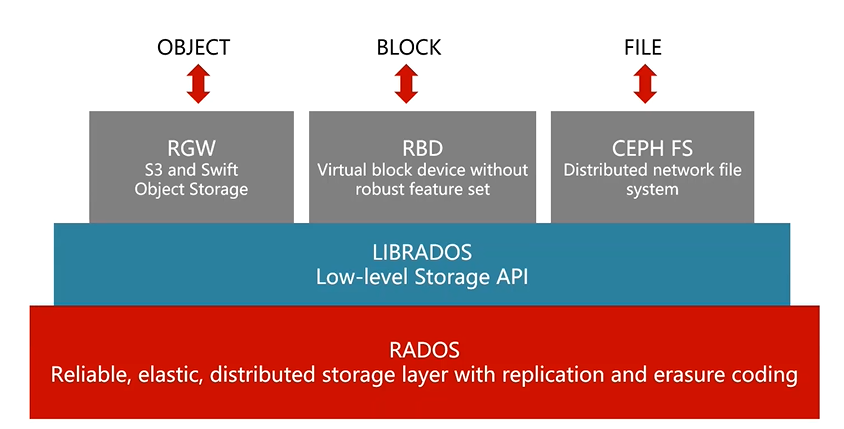
RADOS:对象存储系统(稳定可靠、分布式存储层、复制、支持差错码EC算法)
LIBRDOS:访问RADOS,提供API接口,分别为:RGW、RBD、CEPH FS
RGW:对象存储接口Swift和S3、如:百度网盘、openstack云平台
RBD:块存储接口,如:物理机、虚拟机
CEPH FS:文件系统接口,如:NFS、SMB
四、Ceph组件
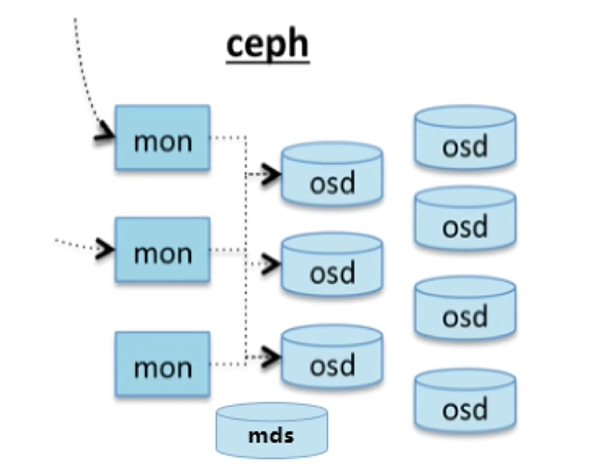
mon:监控整个集群的状态,记录映射表关系,找到文件的存储位置;至少需要3个mon。
osd:用来存放数据,一个硬盘对应一个osd
mds:适用于Cephfs
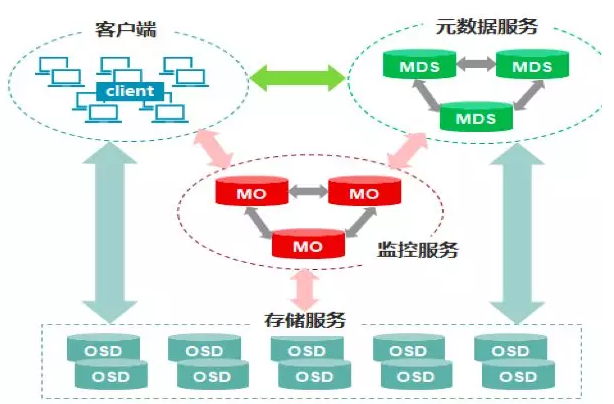
Ceph的核心组件包括Client客户端、MON监控服务、MDS元数据服务、OSD存储服务,各组件功能如下:
Client客户端:负责存储协议的接入,节点负载均衡。
MON监控服务:负责监控整个集群,维护集群的健康状态,维护展示集群状态的各种图表,如OSD Map、Monitor Map、PG Map和CRUSH Map。
MDS元数据服务:负责保存文件系统的元数据,管理目录结构。
OSD存储服务:主要功能是存储数据、复制数据、平衡数据、恢复数据,以及与其它OSD间进行心跳检查等。一般情况下一块硬盘对应一个OSD。
五、Ceph数据的存储过程
Ceph采用crush算法,在大规模集群下,实现数据的快速、准确存放,同时能够在硬件故障或扩展硬件设备时,做到尽可能小的数据迁移,其原理如下:
1.当用户要将数据存储到Ceph集群时,数据先被分割成多个object,(每个object一个object id,大小可设置,默认是4MB),object是Ceph存储的最小存储单元。
2.由于object的数量很多,为了有效减少了Object到OSD的索引表、降低元数据的复杂度,使得写入和读取更加灵活,引入了pg(Placement Group ):PG用来管理object,每个object通过Hash,映射到某个pg中,一个pg可以包含多个object。
3.Pg再通过CRUSH计算,映射到osd中。如果是三副本的,则每个pg都会映射到三个osd,保证了数据的冗余。
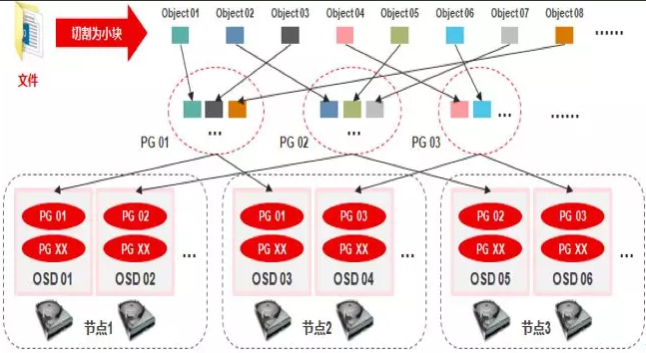
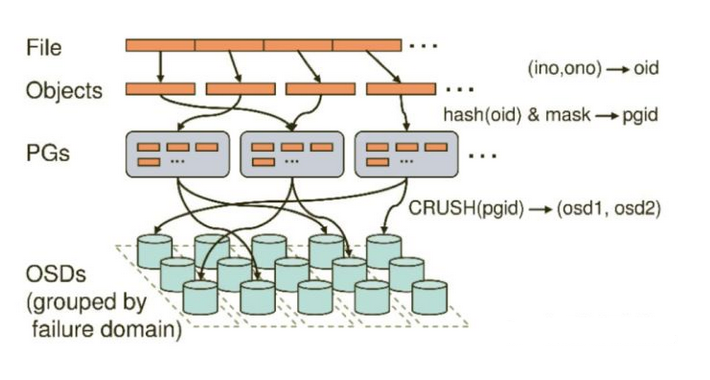
- 首先文件被切片分为多个Objects并以oid标记,通过hash算法和mask掩码得到PGid
- 引入PG逻辑概念(为了防止oid存储时混乱不好搜索,可以理解为文件夹),并用crush算法生成pgid,通过副本的机制把oid均匀分布给OSD中存储。
- 副本数至少2-3个

pg_num计算值为:
注意:
最终pg_num的计算结果取接近计算值的2次幂,以提高CRUSH算法效率,减少CPU、内存的消耗。例如:计算值为200时,取256作为结果。pgp_num的值应设置为与pg_num一致。
参数解释:
Target PGs per OSD:预估每个OSD的PG数,一般取100计算。当预估以后集群OSD数不会增加时,取100计算;当预估以后集群OSD数会增加一倍时,取200计算。
OSD :集群OSD数量。
%Data:预估该pool占该OSD集群总容量的近似百分比。
Size:该pool的副本数。
| OSD数目 | 1-5 | 5-10 | 10-50 | >50 |
|---|---|---|---|---|
| PG数目 | 建议128 | 建议512 | 建议4096 | 使用Pgcalc工具 |
创建pool时需要确定其PG的数目,在pool被创建后也可以调整该数字,PG值有以下影响因素:
数据的持久性:假如pool的size为 3,表明每个PG会将数据存放在3个OSD上。当一个OSD down了后,一定间隔后将开始recovery过程,recovery和需要被恢复的数据的数量有关系,如果该 OSD 上的 PG 过多,则花的时间将越长,风险将越大。
在recovery结束前有部分PG的数据将只有两个副本,如果此时再有一个OSD down了,那么将有一部分PG的数据只有一个副本。recovery 过程继续,如果再出现第三个OSD down了,那么可能会出现部分数据丢失。
可见,每个OSD上的PG数目不宜过大,否则会降低数据的持久性。这也就要求在添加OSD后,PG的数目在需要的时候也需要相应增加。
数据的均匀分布性:CRUSH算法会伪随机地保证PG被选中来存放客户端的数据,它还会尽可能地保证所有的PG均匀分布在所有的OSD上。
比方说,有10个OSD,但是只有一个size为3的pool,它只有一个PG,那么10个 OSD 中将只有三个OSD被用到。但是CURSH算法在计算的时候不会考虑到OSD上已有数据的大小。
比方说,100万个4K对象共4G均匀地分布在10个OSD上的1000个PG内,那么每个OSD上大概有400M 数据。再加进来一个400M的对象,那么有三块OSD上将有400M + 400M = 800M的数据,而其它七块OSD上只有400M数据。
资源消耗:PG作为一个逻辑实体,它需要消耗一定的资源,包括内存、CPU和带宽。太多PG的话,则占用资源会过多。
清理时间:Ceph的清理工作是以PG为单位进行的。如果一个PG内的数据太多,则其清理时间会很长。
Ceph-介绍的更多相关文章
- Ceph介绍
1. 介绍 云硬盘是IaaS云平台的重要组成部分,云硬盘给虚拟机提供了持久的块存储设备.目前的AWS 的EBS(Elastic Block store)给Amazon的EC2实例提供了高可用高可靠的块 ...
- 分布式存储ceph介绍(1)
一.Ceph简介: Ceph是一种为优秀的性能.可靠性和可扩展性而设计的统一的.分布式文件系统.ceph 的统一体现在可以提供文件系统.块存储和对象存储,分布式体现在可以动态扩展.在国内一些公司的云环 ...
- Ceph介绍及原理架构分享
https://www.jianshu.com/p/cc3ece850433 1. Ceph架构简介及使用场景介绍 1.1 Ceph简介 Ceph是一个统一的分布式存储系统,设计初衷是提供较好的性能. ...
- ceph介绍和安装
目录 1.Ceph简介 2.Ceph的特点 3.Ceph的缺点 4.架构与组件 4.1.组件介绍 4.2.存储过程 5.部署 5.1 设置主机名.配置时间同步 5.2 配置添加清华源 5.3 初始化c ...
- 分布式文件系统ceph介绍
ceph哲学思想 1. 每个组件必须支持扩展 2.不存在单点故障 3.解决方案必须是基于软件的.开源的.适应能力强 4.任何可能的一切必须自我管理 存在的意义:帮助企业摆脱昂贵的专属硬件 ceph目标 ...
- Ceph 介绍及原理架构
- Percona 开始尝试基于Ceph做上层感知的分布式 MySQL 集群,使用 Ceph 提供的快照,备份和 HA 功能来解决分布式数据库的底层存储问题
本文由 Ceph 中国社区 -QiYu 翻译 英文出处:Using Ceph with MySQL 欢迎加入CCTG Over the last year, the Ceph world drew m ...
- 海量小文件存储与Ceph实践
海量小文件存储(简称LOSF,lots of small files)出现后,就一直是业界的难题,众多博文(如[1])对此问题进行了阐述与分析,许多互联网公司也针对自己的具体场景研发了自己的存储方案( ...
- Ubuntu CEPH快速安装
一.CEPH简介 不管你是想为云平台提供Ceph 对象存储和/或 Ceph 块设备,还是想部署一个 Ceph 文件系统或者把 Ceph 作为他用,所有 Ceph 存储集群的部署都始于部署一个个 Cep ...
- ceph架构简介
ceph架构简介 在测试OpenStack的后端存储时,看到了ceph作为后端存储时的各种优势 ,于是查询资料,总结了这篇ceph架构的博客,介绍了ceph的架构和ceph的核心组件.ceph整体十分 ...
随机推荐
- 如何通过Java代码将 PDF文档转为 HTML格式
虽然PDF文件适合用于打印和发布,但不适合所有类型的文档.例如,包含复杂图表和图形的文档可能无法在PDF中呈现得很好.但是HTML文件可以在任何可运行浏览器的计算机上进行阅读并显示.并且HTML还具有 ...
- react eject提示This git repository has untracked files or uncommitted changes:
在yarn eject 但时 老是提示This git repository has untracked files or uncommitted changes: Remove untracked ...
- openlayers获取绘制多边形的顶点坐标
虽使用Interaction无数次,进行图形绘制与用户交互等,但当需要获取绘制图形的顶点坐标时还是不晓得咋弄? 都知道在绘制完成后回调中能获取到当前的event对象draw.on('drawend', ...
- # 代码随想录算法训练营Day4|24.两两交换链表中的节点 19.删除链表的倒数第N个节点 面试题02.07.链表相交 142.环形链表Ⅱ
24.两两交换链表中的节点 题目链接:24.两两交换链表中的节点 总体思路: 两两交换链表中的节点使用虚拟头节点可以更方便地进行交换,这样头节点和普通节点可以以同一种方式进行. 虚拟头结点的建设代码: ...
- 商业智能 (BI) 对企业中每个员工的 5 大好处
本文由葡萄城技术团队于博客园原创并首发.葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者. 众所周知,商业智能 (BI) 是探索企业数据价值的强大工具,能够帮助企业做出明智的决策.提高绩效 ...
- [Qt开发]一口气搞懂串口通信
好多小鳄鱼 一.关于串口通信: Qt的确有自己的串口通信类,就是QSerialPort,但是我们在使用过程中因为要更加定制化的使用串口通信类减小开发的难度,所以我们会提供一个串口通信类,也就是这个Se ...
- 稳,从数据库连接池 testOnBorrow 看架构设计
本文从 Commons DBCP testOnBorrow 的作用机制着手,管中窥豹,从一点去分析数据库连接池获取的过程以及架构分层设计. 以下内容会按照每层的作用,贯穿分析整个调用流程. 1️⃣框架 ...
- DataX入门教学
B站学习网址: https://www.bilibili.com/video/BV1H44y1x76X/?p=5&spm_id_from=pageDriver&vd_source=5f ...
- idea专业版和idea社区版整合Tomcat,并将war包部署
目录 一.idea专业版部署 二.idea社区版部署 三.错误案例 开发过程中,由于需要运用云平台,所以从新配置开发环境,其它或多或少有些许问题,但解决起来较为轻松.而对于部署注册中心Eureka时, ...
- 【Azure API Management】实现在API Management服务中使用MI(管理标识 Managed Identity)访问启用防火墙的Storage Account
问题描述 在Azure的同一数据中心,API Management访问启用了防火墙的Storage Account,并且把APIM的公网IP地址设置在白名单.但访问依旧是403 原因是: 存储帐户部署 ...