【Python】爬虫下载视频
Python爬虫下载视频
前言
这两天我一时兴起想学习 PS ,于是去我的软件宝库中翻出陈年已久的 PhotoshopCS6 安装,结果发现很真流畅诶!
然后去搜索学习视频,网上的视频大多浮躁,收费,突然想到了我入门编程时学习的网站, 我要自学网 ,寻找当时非常喜欢的易语言编程视频,很可惜,没有了。而且发现网站似乎不那么好用了QAQ。
找啊找,找啊找,找到了一个同类型,界面很古老的学习网站, 51视频学院(禁不住好奇,似乎很多那个时候的网站都喜欢51开头,比如吾爱论坛,51巅峰阁...) ,发现上面的ps视频还可以,但是我家的网速是不是老卡,所以想一下子都下载完,然后就慢慢本地看啦!不再受网络的影响。 想到这种事情,就立马想到了Python。

Python搞起!
分析
寻找视频地址
右键网页点击检查,先刷新一下网页,然后点击网络选项卡。
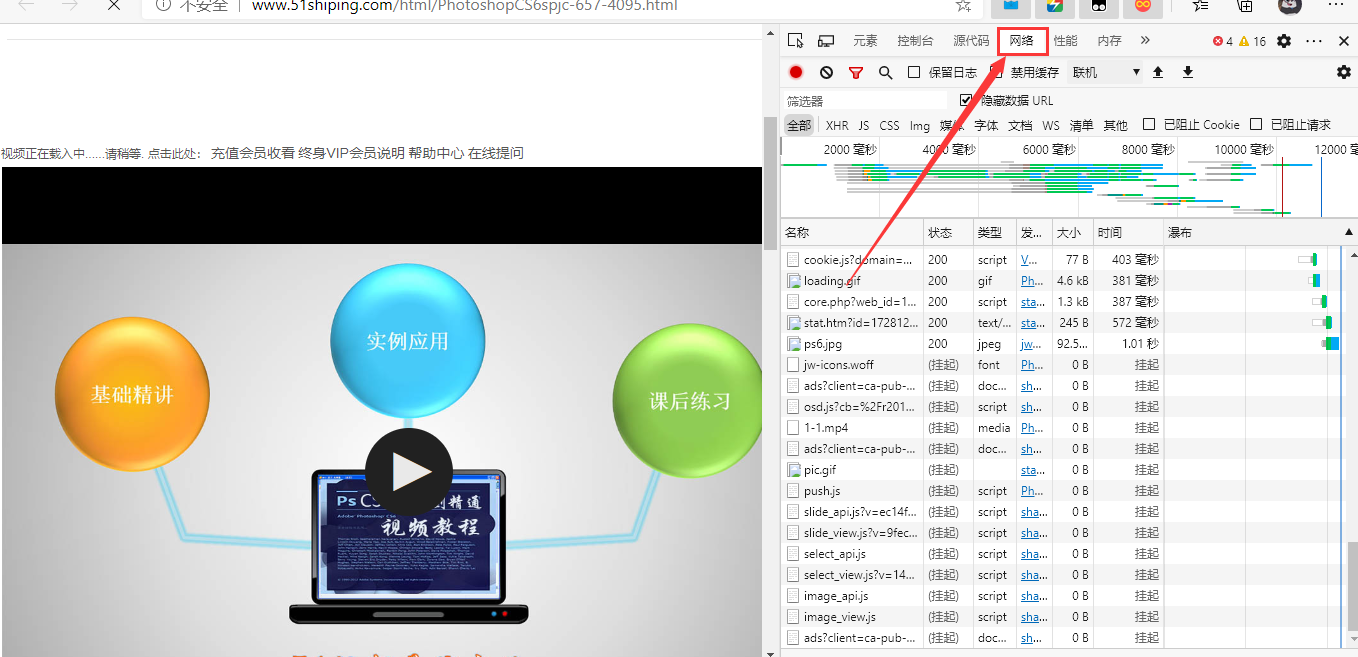 这个网站属于比较老啦,哈哈,我这样的爬虫小白白都能爬,直接点击媒体,我们就能发现视频的请求地址啦,也就是下载地址。
这个网站属于比较老啦,哈哈,我这样的爬虫小白白都能爬,直接点击媒体,我们就能发现视频的请求地址啦,也就是下载地址。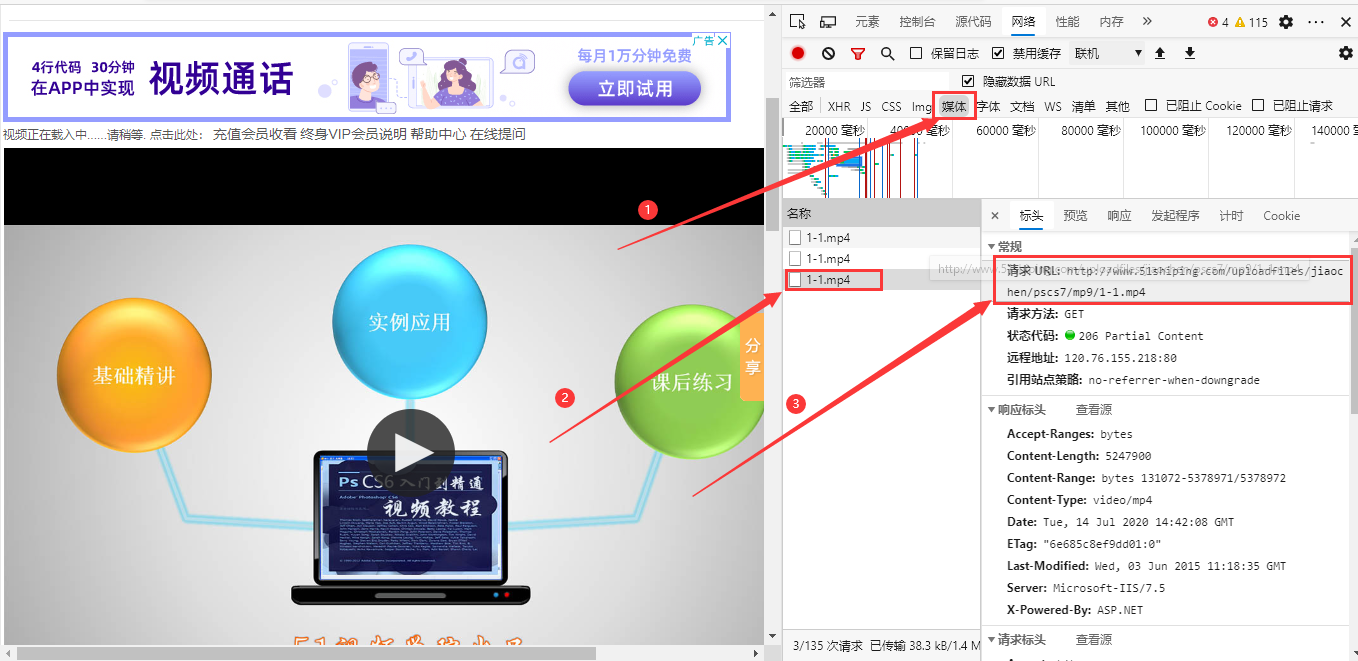 啊哈,果不其然,复制链接后打开就可以下载视频了!
啊哈,果不其然,复制链接后打开就可以下载视频了!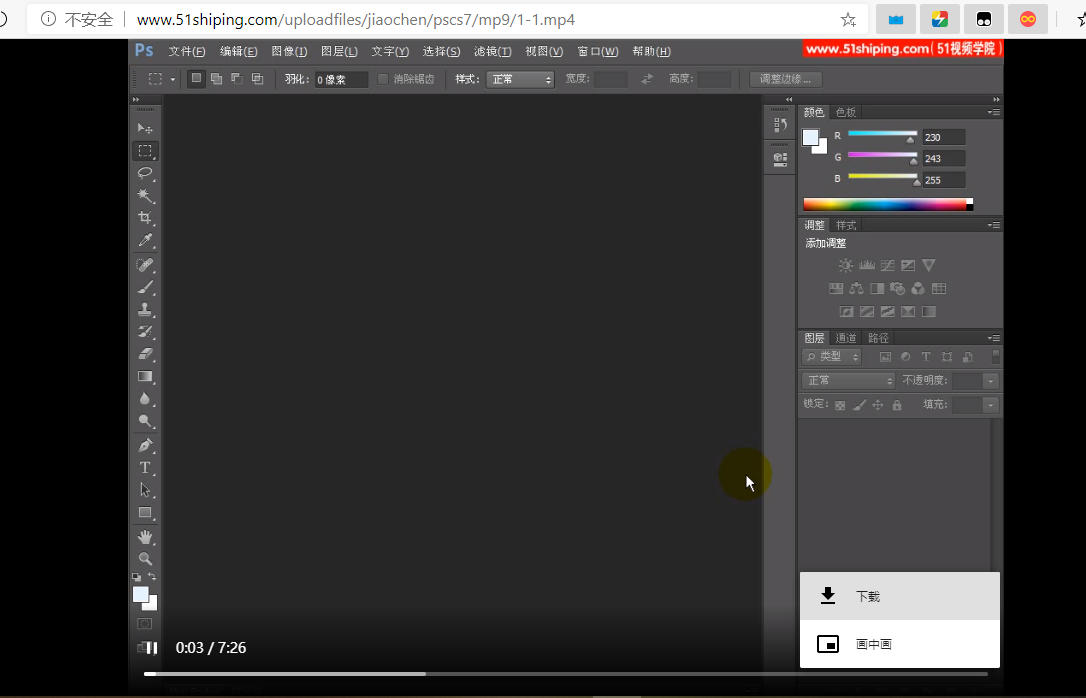
获取视频地址
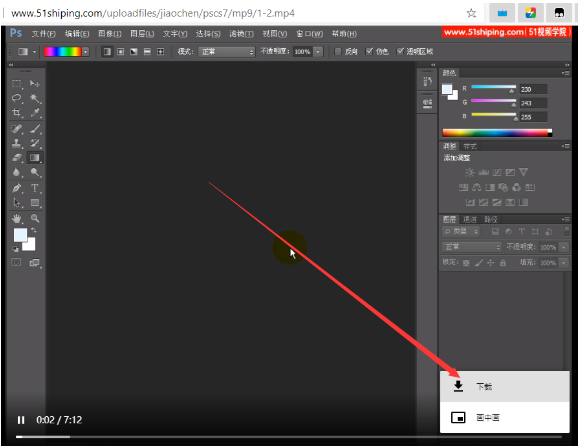
这就是我们寻找到的视频地址啦,但是怎么知道其他视频的地址呢?注意看红色方框的内容

这个时候,让我们回到这个课程的目录页看看
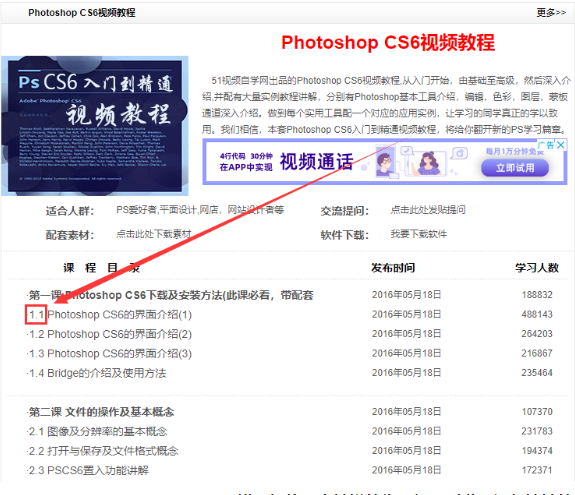 欸欸欸?是不是看到了点东西?没错,相信眼光敏锐的你已经看到啦,视频地址的后面的1-1就是课程的章节序号啦!
欸欸欸?是不是看到了点东西?没错,相信眼光敏锐的你已经看到啦,视频地址的后面的1-1就是课程的章节序号啦!那我们去试几个,发现也是可行的!
 所以我们从目录网页上获取那个章节序号就好啦,顺便把后面的文字也获取了,当成文件名。不然都不知道视频的内容是什么。
所以我们从目录网页上获取那个章节序号就好啦,顺便把后面的文字也获取了,当成文件名。不然都不知道视频的内容是什么。总而言之,流程大致为从目录获取章节序号->下载视频->保存到本地。
写代码!
获取章节序号及内容
这里用到了XPath,不会的 点我看看, 很简单的。
代码:
import requests
from lxml import etree list_url = "http://www.51shiping.com/list-657-1.html"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"}
response = requests.get(list_url,headers=headers)
text = response.text
# 解析
html = etree.HTML(text)
titles = html.xpath("//div[@align='left']/a/text()")
for title in titles:
print(title)
结果:
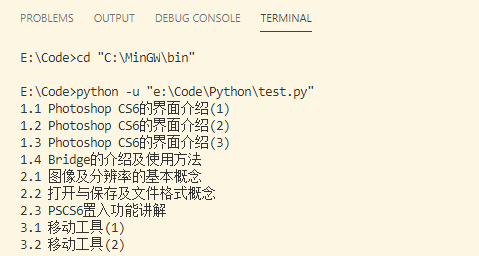
完美!第一步大功告成
但是,在编写下面是发现一个隐藏的坑点,那就是 空格是'\ax0',你输出titles就知道我说的什么意思了 ,下图是titles数组实际存的内容:

所以下面分割字符串时候要以\ax0分割。
试下载一页的视频
import requests
from lxml import etree list_url = "http://www.51shiping.com/list-657-1.html"
v_url = "http://www.51shiping.com/uploadfiles/jiaochen/pscs7/mp9/" # 视频地址,用于拼接
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"}
response = requests.get(list_url,headers=headers)
text = response.text
# 解析
html = etree.HTML(text)
titles = html.xpath("//div[@align='left']/a/text()")
# 下载
for title in titles:
#unicodedata.normalize('NFKC', titles[i]) # 去掉\xa0这样的空白字符
file_dir = 'E:/PSVideo/{}.mp4'.format(title) # 保存的路径和文件名
order = title.split('\xa0')[0] # 每节的编号
video_url = v_url+order.split('.')[0]+'-'+order.split('.')[1]+'.mp4' # 拼接视频下载地址
print(title+'正在下载中...请耐心等待');
# 下载视频
with open(file_dir,'wb') as f:
f.write(requests.get(video_url,headers=headers).content)
f.flush()
print(video_url)
print(file_dir+' 已经下载成功!');
结果:
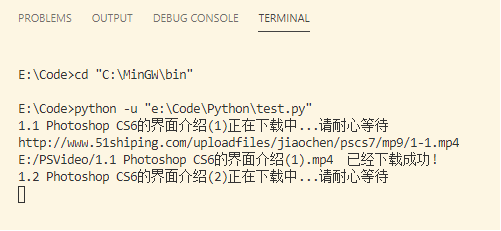
我这里网速可能还是有点慢,(同时我也怀疑是它的服务器太老啊哈哈)。
下载所有页的视频
import requests
from lxml import etree def getVideo(n):
# 访问目录网页,n为目录的页数
list_url = "http://www.51shiping.com/list-657-{}.html".format(n)
v_url = "http://www.51shiping.com/uploadfiles/jiaochen/pscs7/mp9/" # 视频地址,用于拼接
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"}
response = requests.get(list_url,headers=headers)
text = response.text
# 解析
html = etree.HTML(text)
titles = html.xpath("//div[@align='left']/a/text()")
# 下载
for title in titles:
#unicodedata.normalize('NFKC', titles[i]) # 去掉\xa0这样的空白字符
file_dir = 'E:/PSVideo/{}.mp4'.format(title) # 保存的路径和文件名
order = title.split('\xa0')[0] # 每节的编号
video_url = v_url+order.split('.')[0]+'-'+order.split('.')[1]+'.mp4' # 拼接视频下载地址
print(title+'正在下载中...请耐心等待');
# 下载视频
with open(file_dir,'wb') as f:
f.write(requests.get(video_url,headers=headers).content)
f.flush()
print(video_url)
print(file_dir+' 已经下载成功!'); if __name__ == "__main__":
for n in range(1,7):
getVideo(1)
这个结果我就不再演示啦,(网速慢的我)
总结
该项目利用了requests+XPath知识实现,不是很难,我是一个初学爬虫的小白,都能实现,更何况你呢~
如果能给你正在写的项目一点启发,那更是好啦!哈哈,如果觉得还可以,记得给我点个赞哦~你的赞就是对我最大的鼓励!

【Python】爬虫下载视频的更多相关文章
- python爬虫下载文件
python爬虫下载文件 下载东西和访问网页差不多,这里以下载我以前做的一个安卓小游戏为例 地址为:http://hjwachhy.site/game/only_v1.1.1.apk 首先下载到内存 ...
- Python爬虫下载Bilibili番剧弹幕
本文绍如何利用python爬虫下载bilibili番剧弹幕. 准备: python3环境 需要安装BeautifulSoup,selenium包 phantomjs 原理: 通过aid下载bilibi ...
- python爬虫下载小视频和小说(基础)
下载视频: 1 from bs4 import BeautifulSoup 2 import requests 3 import re 4 import urllib 5 6 7 def callba ...
- python爬虫学习视频资料免费送,用起来非常666
当我们浏览网页的时候,经常会看到像下面这些好看的图片,你是否想把这些图片保存下载下来. 我们最常规的做法就是通过鼠标右键,选择另存为.但有些图片点击鼠标右键的时候并没有另存为选项,或者你可以通过截图工 ...
- python you-get 下载视频
python使用you-get模块下载视频 pip install you-get # 安装先 怎么用 进入命令行: you-get url 暂停下载:ctrl + c ,继续下载重复 y ...
- 用python you-get下载视频
安装python3后 安装you-get包: pip3 install you-get 下载视频: 打开windows终端:运行 you-get url 查看视频信息: you-get -i url ...
- Python 爬虫 Vimeo视频下载链接
python vimeo_d.py https://vimeo.com/228013581 在https://vimeo.com/上看到稀罕的视频 按照上面加上视频的观看地址运行即可获得视频下载链接 ...
- python爬虫下载youtube单个视频
__author__ = 'Sentinel'import requestsimport reimport jsonimport sysimport shutilimport urlparse &qu ...
- Python爬虫下载美女图片(不同网站不同方法)
声明:以下代码,Python版本3.6完美运行 一.思路介绍 不同的图片网站设有不同的反爬虫机制,根据具体网站采取对应的方法 1. 浏览器浏览分析地址变化规律 2. Python测试类获取网页内容,从 ...
- Python爬虫下载酷狗音乐
目录 1.Python下载酷狗音乐 1.1.前期准备 1.2.分析 1.2.1.第一步 1.2.2.第二步 1.2.3.第三步 1.2.4.第四步 1.3.代码实现 1.4.运行结果 1.Python ...
随机推荐
- MyBatisPlus 自动填充演示
一.数据库 表中新增"添加时间"和"修改时间"字段:
- 小知识:IN和EXISTS的用法及效率验证
环境: Oracle 19.16 多租户架构 经常会在网上看到有人写exists和in的效率区别,其实在新版本的数据库中,是不存在这个问题的,优化器会自己判断选择最优的执行计划. 为了直观的说明,我在 ...
- NEFU高级程序设计-期末复习习题组
1. 用链表实现单词序列倒序输出 题目 用链表实现单词序列倒序输出.与以往不同,请考虑采用一种完全的动态分配方式! 为降低难度,"仁慈"的我已经给出了输出和释放的代码,你只要写出创 ...
- Docker容器内不能联网的6种解决方案
Docker容器内不能联网的6种解决方案 注:下面的方法是在容器内能ping通公网IP的解决方案,如果连公网IP都ping不通,那主机可能也上不了网(尝试ping 8.8.8.8) 1.使用–net: ...
- KubeSphere 升级 && 安装后启用插件
KubeSphere 升级 root@master1:~# export KKZONE=cn root@master1:~# kk upgrade --with-kubernetes v1.22.1 ...
- 浏览器层面优化前端性能(1):Chrom组件与进程/线程模型分析
现阶段的浏览器运行在一个单用户,多合作,多任务的操作系统中.一个糟糕的网页同样可以让一个现代的浏览器崩溃.其原因可能是一个插件出现bug,最终的结果是整个浏览器以及其他正在运行的标签被销毁. 现代操作 ...
- xtrabackup8.0.27备份失败
问题描述:mysql8.0.27备份出现中断,重新备份发现xtrabackup备份失败,xtrabackup与mysql版本不匹配,后来想起来时mysql进行了升级,8.0.27->8.0.29 ...
- 数据泵:导入导出dblink
环境介绍:12c->19c [oracle@enmoedu1 dpdump]$ expdp system/oracle directory=DATA_PUMP_DIR dumpfile=STAT ...
- 【实践篇】基于CAS的单点登录实践之路
作者:京东物流 赵勇萍 前言 上个月我负责的系统SSO升级,对接京东ERP系统,这也让我想起了之前我做过一个单点登录的项目.想来单点登录有很多实现方案,不过最主流的还是基于CAS的方案,所以我也就分享 ...
- 【谷粒商城】(一)docker搭建以及项目的创建
网络地址转换-端口转发 VmWare网络配置可以参考这篇:VMWare虚拟机网络连接设置_santirenpc的博客-CSDN博客_vmware 上网设置,真的是被折磨到了.. Docker 虚拟化容 ...