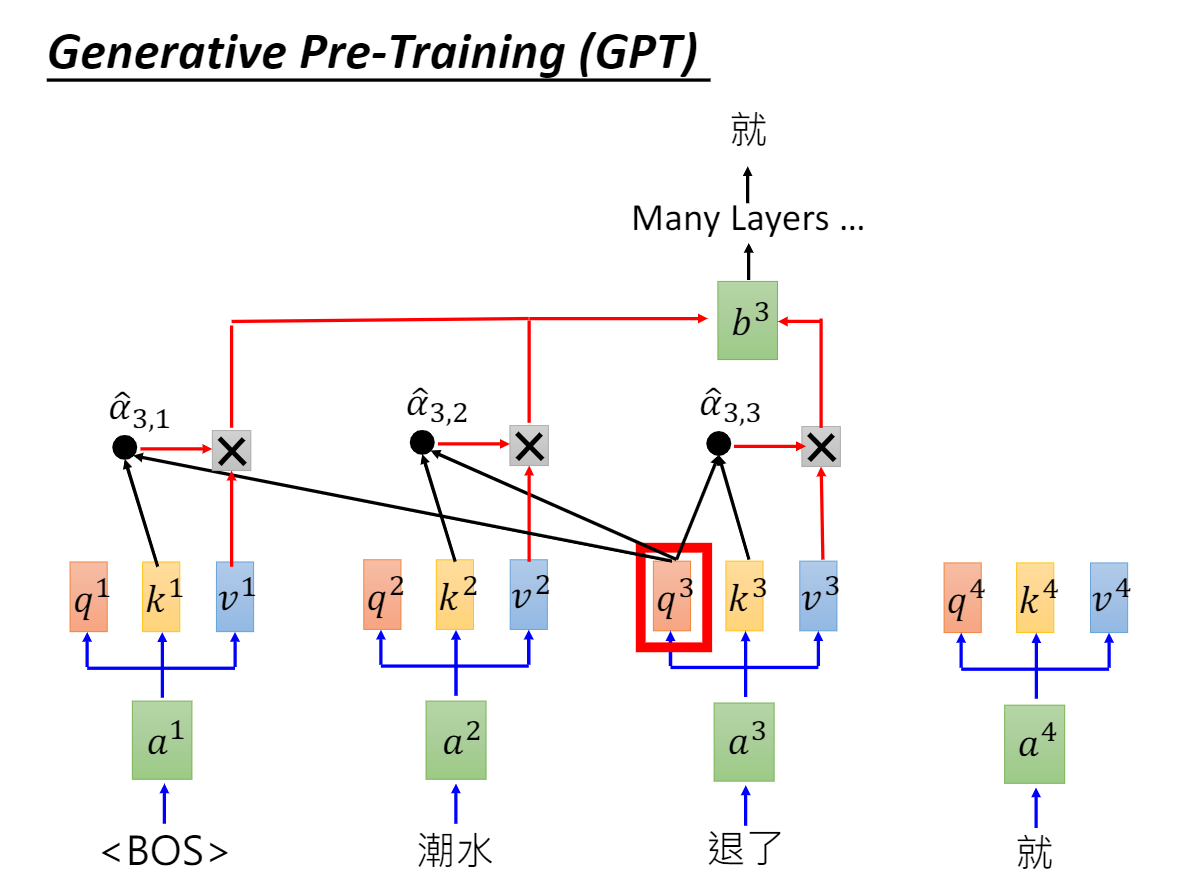
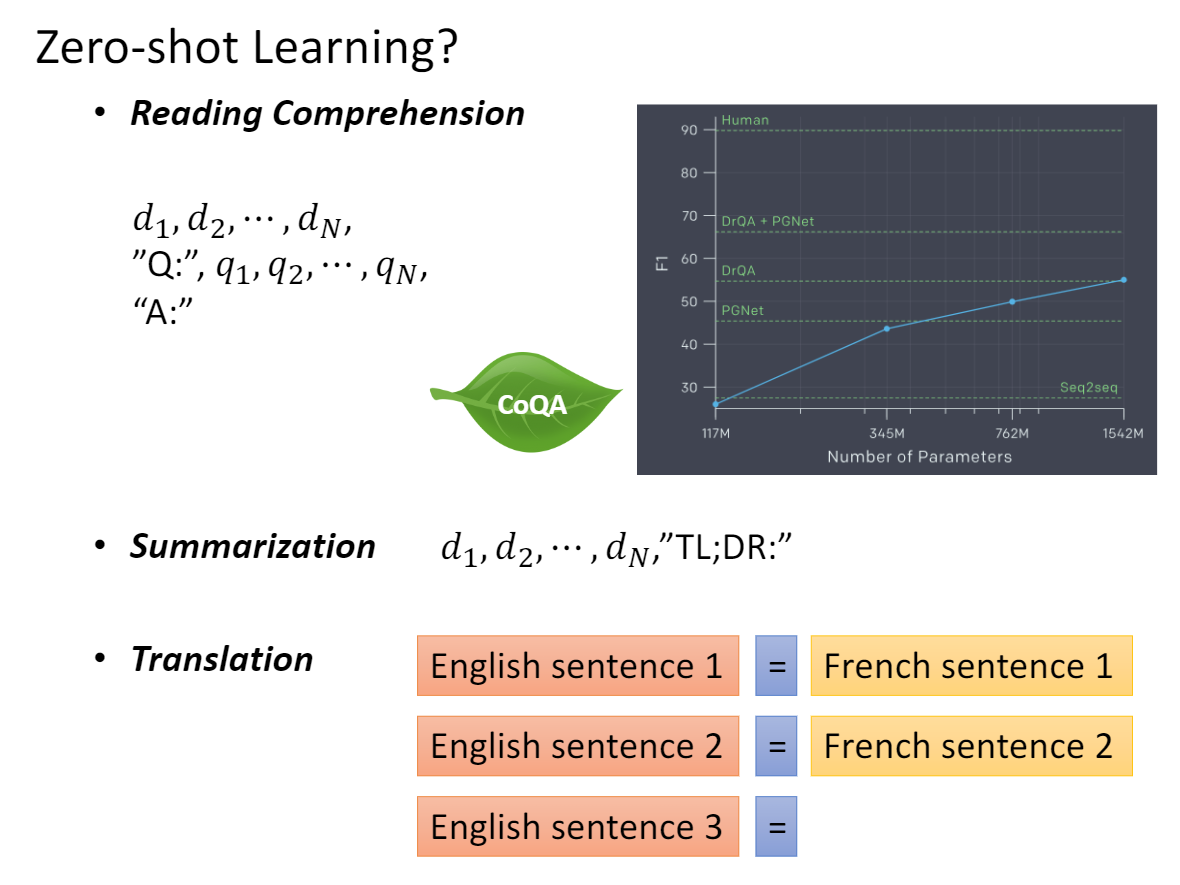
【大语言模型基础】GPT(Generative Pre-training )生成式无监督预训练模型原理


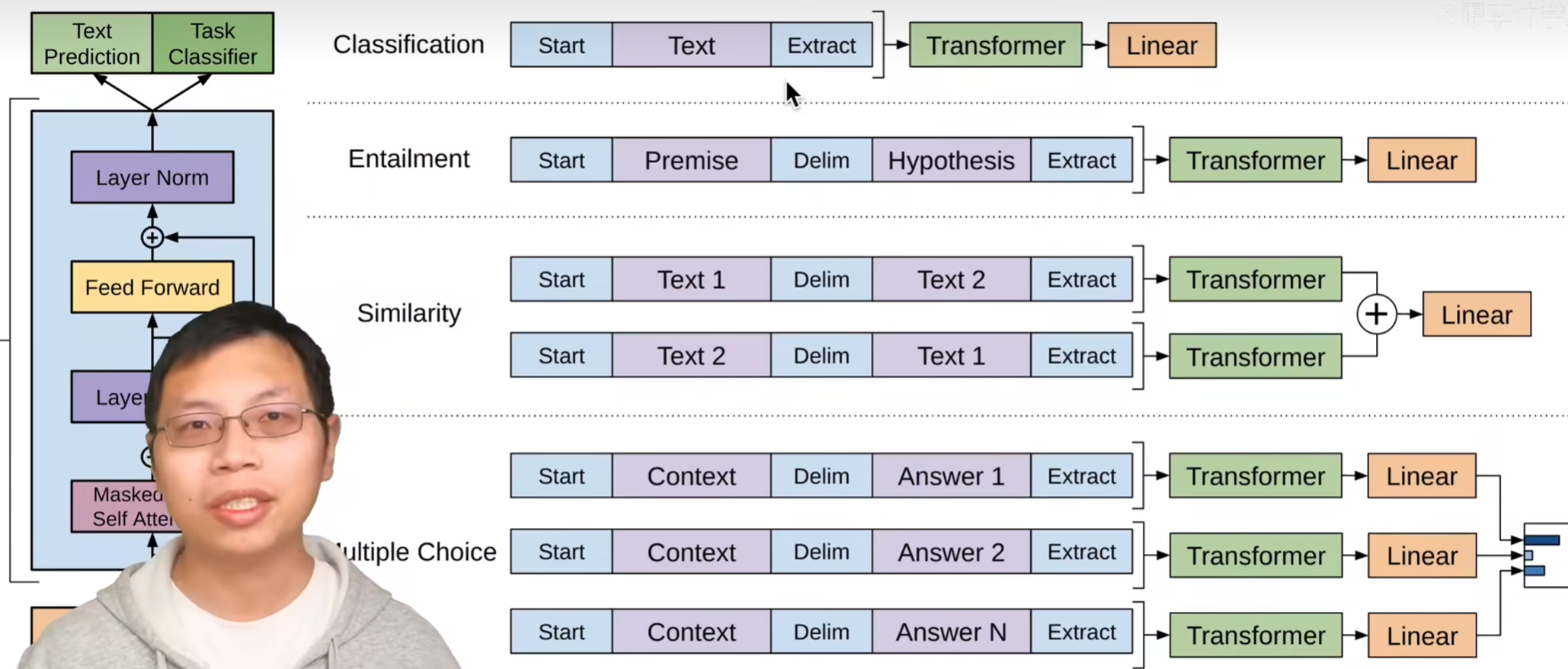
- 分类:句子A
- 蕴含:句子A, 句子B假设, True, False, None, 3分类
- 相似性: Text1,Text2, 相不似相似True/False; 交换顺序Text2,Text1, 相不似相似True/False(单向的,交换顺序不一样,有必要)。抽取特征相加,线性,分类
- 多选择(QA, 摘要): 一个上下文,多个答案, 分别用Transformer编码,多分类
【大语言模型基础】GPT(Generative Pre-training )生成式无监督预训练模型原理的更多相关文章
- 【原创】大数据基础之Spark(6)Spark Rdd Sort实现原理
spark 2.1.1 spark中可以通过RDD.sortBy来对分布式数据进行排序,具体是如何实现的?来看代码: org.apache.spark.rdd.RDD /** * Return thi ...
- 【原创】大数据基础之Spark(8)Spark中Join实现原理
spark中join有两种,一种是RDD的join,一种是sql中的join,分别来看: 1 RDD join org.apache.spark.rdd.PairRDDFunctions /** * ...
- 使用 LoRA 和 Hugging Face 高效训练大语言模型
在本文中,我们将展示如何使用 大语言模型低秩适配 (Low-Rank Adaptation of Large Language Models,LoRA) 技术在单 GPU 上微调 110 亿参数的 F ...
- LLM(大语言模型)解码时是怎么生成文本的?
Part1配置及参数 transformers==4.28.1 源码地址:transformers/configuration_utils.py at v4.28.1 · huggingface/tr ...
- Coursera台大机器学习基础课程1
Coursera台大机器学习基础课程学习笔记 -- 1 最近在跟台大的这个课程,觉得不错,想把学习笔记发出来跟大家分享下,有错误希望大家指正. 一 机器学习是什么? 感觉和 Tom M. Mitche ...
- 本地推理,单机运行,MacM1芯片系统基于大语言模型C++版本LLaMA部署“本地版”的ChatGPT
OpenAI公司基于GPT模型的ChatGPT风光无两,眼看它起朱楼,眼看它宴宾客,FaceBook终于坐不住了,发布了同样基于LLM的人工智能大语言模型LLaMA,号称包含70亿.130亿.330亿 ...
- pytorch在有限的资源下部署大语言模型(以ChatGLM-6B为例)
pytorch在有限的资源下部署大语言模型(以ChatGLM-6B为例) Part1知识准备 在PyTorch中加载预训练的模型时,通常的工作流程是这样的: my_model = ModelClass ...
- 【原创】大数据基础之Zookeeper(2)源代码解析
核心枚举 public enum ServerState { LOOKING, FOLLOWING, LEADING, OBSERVING; } zookeeper服务器状态:刚启动LOOKING,f ...
- Hugging News #0324: 🤖️ 黑客松结果揭晓、一键部署谷歌最新大语言模型、Gradio 新版发布,更新超多!
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新.社区活动.学习资源和内容更新.开源库和模型更新等,我们将其称之为「Hugging Ne ...
- 保姆级教程:用GPU云主机搭建AI大语言模型并用Flask封装成API,实现用户与模型对话
导读 在当今的人工智能时代,大型AI模型已成为获得人工智能应用程序的关键.但是,这些巨大的模型需要庞大的计算资源和存储空间,因此搭建这些模型并对它们进行交互需要强大的计算能力,这通常需要使用云计算服务 ...
随机推荐
- 如何控制Tomcat的catalina.out的大小
catalina.out文件,数据主要来源为:System.out 和 System.err 在控制台上直接输出的信息. 编码时应避免使用System.out.println()和e.printSta ...
- iOS 17.4 测试版包含大模型相关代码
外界普遍预计苹果将在 6 月份通过 iOS 18 推出主要的新人工智能功能.不过根据 9to5Mac 的报道,他们在 iOS 17.4 第一个测试版中发现的代码表明,苹果正在开发由大语言模型技术支持的 ...
- Linux反空闲的设置和关闭
有一定工作经验的运维人基本都会遇到这样的场景,某个窗口自动断开了,提示超时: [oracle@jystdrac1 ~]$ timed out waiting for input: auto-logou ...
- mybatis SQL in() 为什么要在 mapper.xml里 用 foreach
结论: 若存在 in () 语句,要使用 #{} 预编译入参的方式,需要在 mapper.xml里 使用 foreach ======================================= ...
- SP9494 ZSUM - Just Add It 题解
题目传送门 前置知识 快速幂 解法 推式子: \(\begin{aligned} Z_n+Z_{n-1}-2Z_{n-2}&=(Z_n-Z_{n-2})+(Z_{n-1}-Z_{n-2}) \ ...
- 使用 lspci 和 setpci 调试 PCIe 问题
lspci 命令和 setpci 命令均为 Linux 发行版中原生可用的命令. 这 2 条命令均可提供多级输出,适合在不同时间点用于查看 PCI 总线上训练的不同组件的功能和状态.其中大部分功能均可 ...
- python定义类模块之attr
# attr可以简单理解为namedtuple的增强版 import attr @attr.s class Point(object): x = attr.ib(default=1) # 定义默认参数 ...
- 简单看下最近的Spring Secrurity、Spring漏洞(CVE-2024-22234、CVE-2024-22243)
最近的这两个cve我看国内很多情报将其评为高危,所以想着去看看原理,看完发现都比较简单,利用要求的场景也相对有限(特别是第一个),所以就随便看下就行了 Spring Security 用户认证绕过(C ...
- 一次生产环境OOM排查
一.背景 前几天下午飞书告警群里报起了java.lang.OutOfMemoryError: unable to create new native thread告警,看见后艾特了对应的项目负责人但是 ...
- Hibernate-Validator扩展之自定义注解
一.Hibernate-Validator介绍 Hibernate-Validator框架提供了一系列的注解去校验字段是否符合预期,如@NotNull注解可以校验字段是否为null,如果为null ...