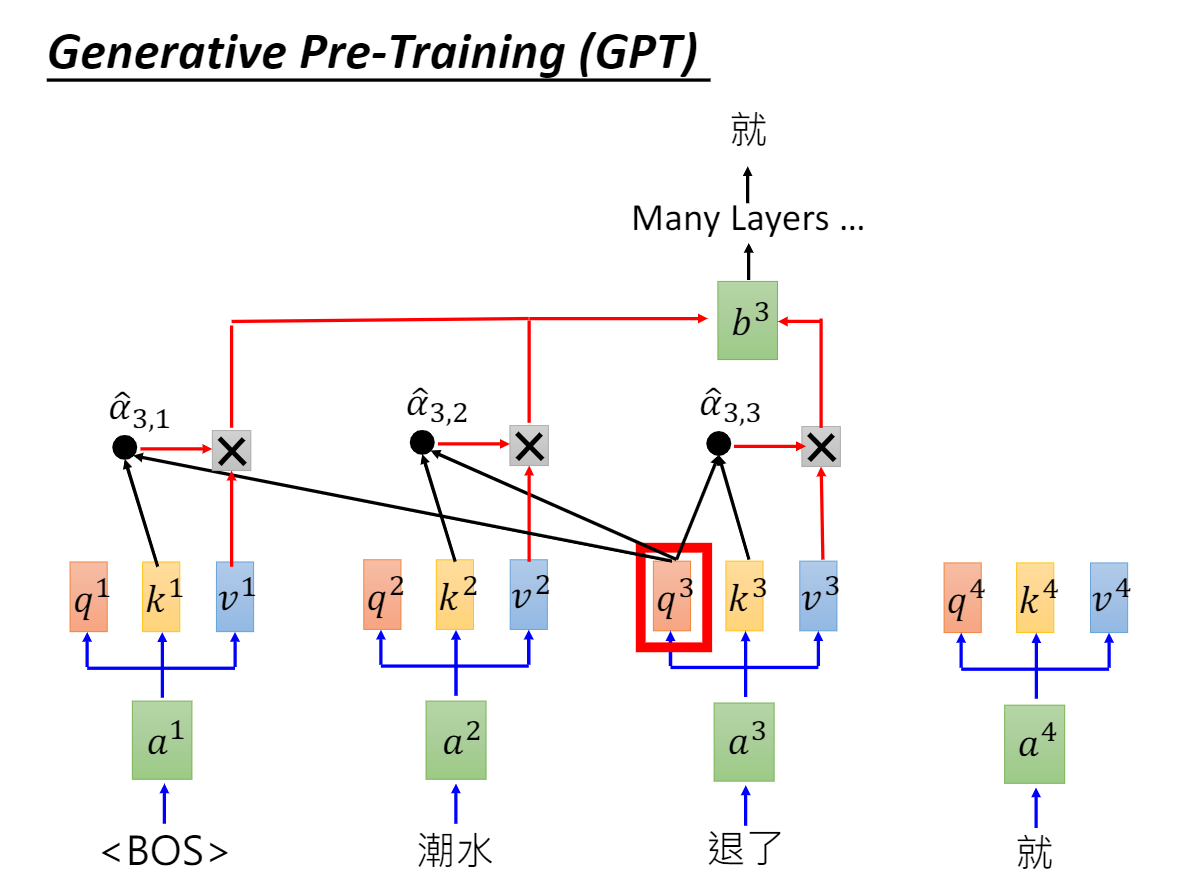
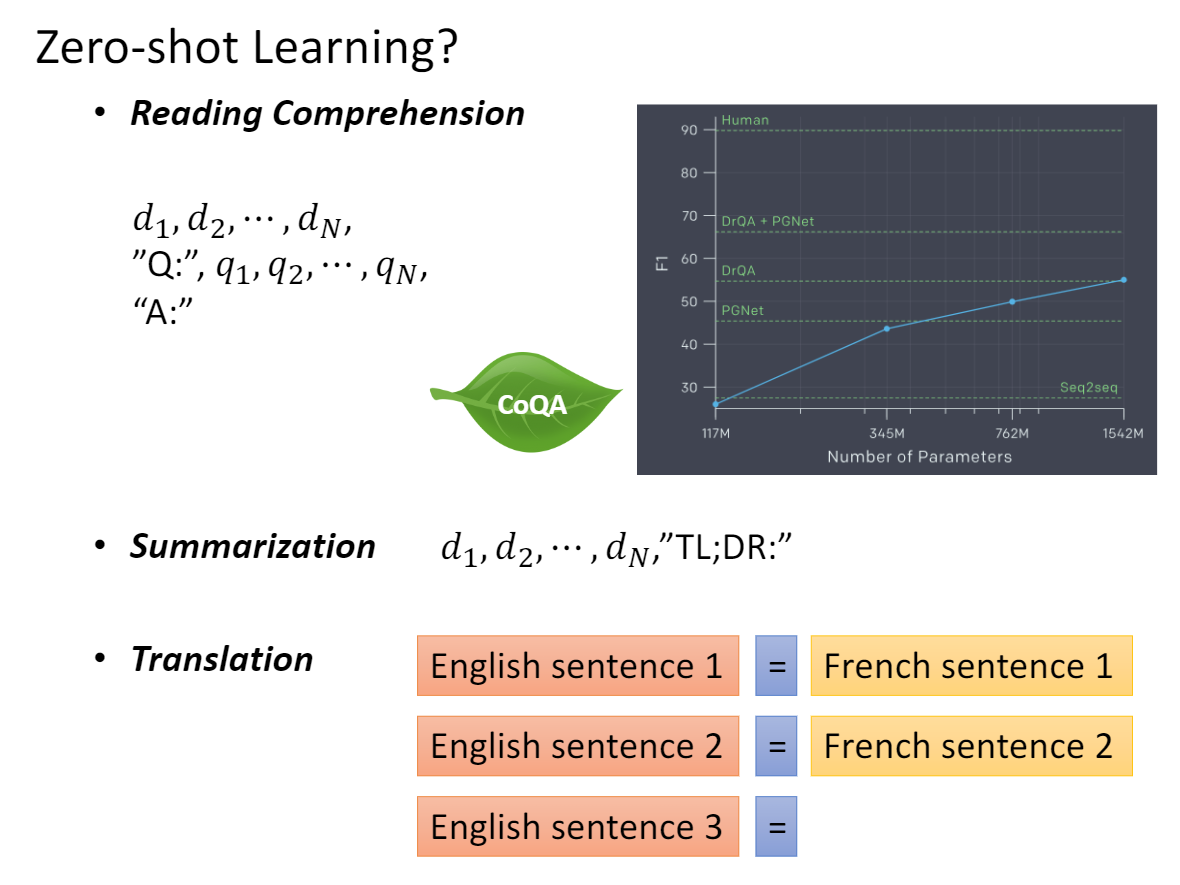
【大语言模型基础】GPT(Generative Pre-training )生成式无监督预训练模型原理


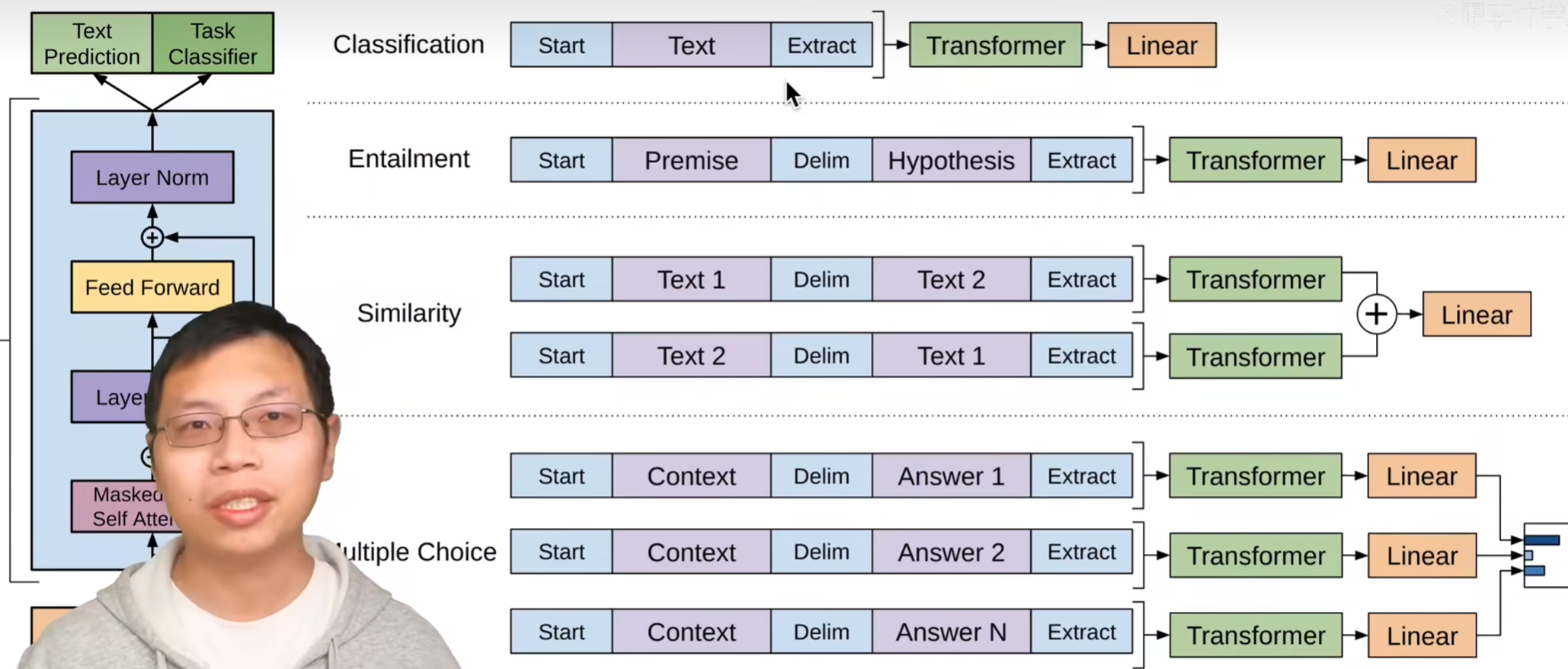
- 分类:句子A
- 蕴含:句子A, 句子B假设, True, False, None, 3分类
- 相似性: Text1,Text2, 相不似相似True/False; 交换顺序Text2,Text1, 相不似相似True/False(单向的,交换顺序不一样,有必要)。抽取特征相加,线性,分类
- 多选择(QA, 摘要): 一个上下文,多个答案, 分别用Transformer编码,多分类
【大语言模型基础】GPT(Generative Pre-training )生成式无监督预训练模型原理的更多相关文章
- 【原创】大数据基础之Spark(6)Spark Rdd Sort实现原理
spark 2.1.1 spark中可以通过RDD.sortBy来对分布式数据进行排序,具体是如何实现的?来看代码: org.apache.spark.rdd.RDD /** * Return thi ...
- 【原创】大数据基础之Spark(8)Spark中Join实现原理
spark中join有两种,一种是RDD的join,一种是sql中的join,分别来看: 1 RDD join org.apache.spark.rdd.PairRDDFunctions /** * ...
- 使用 LoRA 和 Hugging Face 高效训练大语言模型
在本文中,我们将展示如何使用 大语言模型低秩适配 (Low-Rank Adaptation of Large Language Models,LoRA) 技术在单 GPU 上微调 110 亿参数的 F ...
- LLM(大语言模型)解码时是怎么生成文本的?
Part1配置及参数 transformers==4.28.1 源码地址:transformers/configuration_utils.py at v4.28.1 · huggingface/tr ...
- Coursera台大机器学习基础课程1
Coursera台大机器学习基础课程学习笔记 -- 1 最近在跟台大的这个课程,觉得不错,想把学习笔记发出来跟大家分享下,有错误希望大家指正. 一 机器学习是什么? 感觉和 Tom M. Mitche ...
- 本地推理,单机运行,MacM1芯片系统基于大语言模型C++版本LLaMA部署“本地版”的ChatGPT
OpenAI公司基于GPT模型的ChatGPT风光无两,眼看它起朱楼,眼看它宴宾客,FaceBook终于坐不住了,发布了同样基于LLM的人工智能大语言模型LLaMA,号称包含70亿.130亿.330亿 ...
- pytorch在有限的资源下部署大语言模型(以ChatGLM-6B为例)
pytorch在有限的资源下部署大语言模型(以ChatGLM-6B为例) Part1知识准备 在PyTorch中加载预训练的模型时,通常的工作流程是这样的: my_model = ModelClass ...
- 【原创】大数据基础之Zookeeper(2)源代码解析
核心枚举 public enum ServerState { LOOKING, FOLLOWING, LEADING, OBSERVING; } zookeeper服务器状态:刚启动LOOKING,f ...
- Hugging News #0324: 🤖️ 黑客松结果揭晓、一键部署谷歌最新大语言模型、Gradio 新版发布,更新超多!
每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新.社区活动.学习资源和内容更新.开源库和模型更新等,我们将其称之为「Hugging Ne ...
- 保姆级教程:用GPU云主机搭建AI大语言模型并用Flask封装成API,实现用户与模型对话
导读 在当今的人工智能时代,大型AI模型已成为获得人工智能应用程序的关键.但是,这些巨大的模型需要庞大的计算资源和存储空间,因此搭建这些模型并对它们进行交互需要强大的计算能力,这通常需要使用云计算服务 ...
随机推荐
- C# 中的函数与方法
在C#中,函数和方法都是一段可重用的代码块,用于实现特定的功能.函数是C#中的基本代码块之一,用于完成特定的任务和返回一个值.函数可以具有零个或多个参数,并且可以使用关键字来指定函数的访问级别和返回类 ...
- C/C++ Npcap包实现数据嗅探
npcap 是Nmap自带的一个数据包处理工具,Nmap底层就是使用这个包进行收发包的,该库,是可以进行二次开发的,不过使用C语言开发费劲,在进行渗透任务时,还是使用Python构建数据包高效,这东西 ...
- pthread库的使用
目录 1.说明 2.使用 2.1.pthread_create 2.2.pthread_join 2.3.pthread_exit 2.4.pthread_self 2.5.pthraad_detac ...
- FOG Project的 FOS 编译
FOG Project系统是一个免费的开源计算机网络克隆和管理解决方案系统,与传统的Ghost有很大的不同,如果您是计算机维护管理人员,当有大量机器需要同时部署上线的时候FOG Project是一个可 ...
- Java微服务SpringCloud+Uniapp+Vue3+Element Plus开源BizSpring商城
产品介绍 BizSpring电商平台概述 BizSpring电商平台,是基于最新Spring Cloud 微服务架构开发的多语言电商平台,使用领先的 Vue3.0+ElementPlus + unia ...
- CF1853
你谷的加题速度实在太慢了 被 CF 的题目薄纱 A 可以选任意次 \(i\in [1,n]\),使 \(a[1\sim i]++,a[i+1\sim n]--\).求最少操作次数使得原数列变成非从小到 ...
- 思维分析逻辑 5 DAY
目录 如何分析 结构分析 对比分析 时间序列 相关性分析 机器学习 报告撰写 报告撰写三原则 标准化报告的组成 AB测试 AB测试流程 AB测试注意事项 如何分析 结构分析 对比分析 对比分析:所有的 ...
- Maven多模块项目版本统一管理
如图所示,项目中定义了这样几个模块: pdd-workflow-build :定义项目版本,及全局配置 pdd-workflow-dependencies :外部依赖管理,统一管理所有用到的外部依赖的 ...
- Vue+ElementUI实现用户管理前后分离实战一:前端篇
项目介绍 前几天有老铁问我能不能写一个Vue+ElementUI+SpringBoot后端的前后分离项目,最近有点忙,但今天他还是来了!希望对大家能有点帮助,大家还想要点啥也可以加我QQ或给我留言 : ...
- Android里使用AspectJ实现AOP
前言 Aspectj提供一种在字符串里编程的模式,即在字符串里写函数,然后程序启动的时候会动态的把字符串里的函数给执行了. 例如: "execution(* *(..))" 这里 ...