proxmox ve 部署双节点HA集群及glusterfs分布式文件系统
1.修改hosts文件
root@pve1:~# cat /etc/hosts
192.168.1.50 pve1.local pve1
192.168.1.60 pve2.local pve2
192.168.1.50 gluster1
192.168.1.60 gluster2
2.修改服务器名
在两台pve的/etc/hostname中,增加如下
root@pve1:~# cat /etc/hostname
pve1 root@pve2:~# cat /etc/hostname
pve2
3.安装glusterfs
wget -O - https://download.gluster.org/pub/gluster/glusterfs/9/rsa.pub | apt-key add -
DEBID=$(grep 'VERSION_ID=' /etc/os-release | cut -d '=' -f 2 | tr -d '"')
DEBVER=$(grep 'VERSION=' /etc/os-release | grep -Eo '[a-z]+')
DEBARCH=$(dpkg --print-architecture)
echo deb https://download.gluster.org/pub/gluster/glusterfs/LATEST/Debian/${DEBID}/${DEBARCH}/apt ${DEBVER} main > /etc/apt/sources.list.d/gluster.list
apt update [备注这一步可以不做,当源已经确定使用具体源时]
apt install -y glusterfs-server
option transport.rdma.bind-address gluster1
option transport.socket.bind-address gluster1
option transport.tcp.bind-address gluster1
option transport.rdma.bind-address gluster2
option transport.socket.bind-address gluster2
option transport.tcp.bind-address gluster2
systemctl enable glusterd.service
systemctl start glusterd.service
gluster peer probe gluster1
显示: peer probe: success 就OK
命令分析
* gluster volume create: 这是 GlusterFS 的命令,用于创建一个新的卷。
* VMS: 这是你给新卷指定的名称。在这个例子中,卷的名称是 VMS。
* replica 2: 这指定了卷的类型和复制因子。replica 表示这是一个复制卷,2 表示数据将在两个节点上进行复制。这意味着你有两个副本的数据,一个在主节点上,另一个在复制节点上。
* gluster1:/data/s: 这是第一个存储路径。gluster1 是 GlusterFS 集群中的一个节点的名称或 IP 地址,/data/s 是该节点上用于存储 GlusterFS 卷数据的目录。
* gluster2:/data/s: 这是第二个存储路径。与第一个路径类似,但指定了第二个节点和存储目录。在这个例子中,数据将被复制到 gluster1 和 gluster2 这两个节点上的 /data/s 目录。
当执行这个命令时,GlusterFS 会在 gluster1 和 gluster2 这两个节点上创建一个名为 VMS 的复制卷,并将数据在两个节点的 /data/s 目录中进行复制。这样做可以提高数据的可靠性和可用性,因为如果其中一个节点出现故障,另一个节点上的数据副本仍然可用。
然而,正如你遇到的错误消息所提到的,创建复制卷(特别是只有两个副本时)有脑裂(split-brain)的风险。脑裂是指当两个或多个节点都认为自己是主节点并且都在接受写操作时,数据可能会变得不一致。为了避免这种情况,可以使用仲裁节点(arbiter)或将复制因子增加到 3 或更多。但在许多情况下,简单的双节点复制卷对于大多数应用来说已经足够了。
-------------------------------
gluster vol start VMS命令分析
1. 启动卷服务:该命令会启动 GlusterFS 集群中名为 VMS 的卷的服务,使得客户端可以开始访问该卷上的数据。
2. 确保数据可用性:当卷启动后,GlusterFS 会确保数据在集群中的节点之间是可用的,并会根据卷的类型(如分布式复制卷)来管理和复制数据。
3. 检查节点状态:在启动卷之前,GlusterFS 会检查集群中所有参与该卷的节点的状态,确保它们都是可用的并且处于正确的配置中。
4. 处理客户端请求:一旦卷启动成功,客户端就可以通过挂载该卷来访问存储在上面的数据。GlusterFS 会处理来自客户端的读写请求,并确保数据在集群中的一致性。
5. 负载均衡:对于分布式卷和分布式复制卷,GlusterFS 会在启动时自动进行负载均衡,确保数据在各个节点之间均匀分布,从而提高整体性能和可靠性。
6. 监控和日志记录:在卷启动后,GlusterFS 会持续监控该卷的状态和性能,并记录相关的日志信息。这些信息对于后续的故障排查和性能调优非常有用。
综上所述,gluster volume start VMS 命令的作用是启动 GlusterFS 集群中名为 VMS 的卷,确保数据的可用性、一致性和性能,并处理来自客户端的读写请求。在执行该命令之前,需要确保 GlusterFS 集群中的所有节点都已正确配置并可以相互通信。
3.8增加挂载
两台pve不重启挂载
3.9解决split-brain问题
两个节点的gluster会出现split-brain问题,就是两节点票数一样,谁也不听谁的,解决办法如下:
gluster vol set VMS cluster.heal-timeout 5
gluster volume heal VMS enable
gluster vol set VMS cluster.quorum-reads false
gluster vol set VMS cluster.quorum-count 1
gluster vol set VMS network.ping-timeout 2
gluster volume set VMS cluster.favorite-child-policy mtime
gluster volume heal VMS granular-entry-heal enable
gluster volume set VMS cluster.data-self-heal-algorithm full
4.0pve双节点集群设置
5.0创建共享目录
6.0HA设置
修改 /etc/pve/corosync.conf
在quorum中增加,变成这样:
quorum {
provider: corosync_votequorum
expected_votes: 1
two_node: 1
}
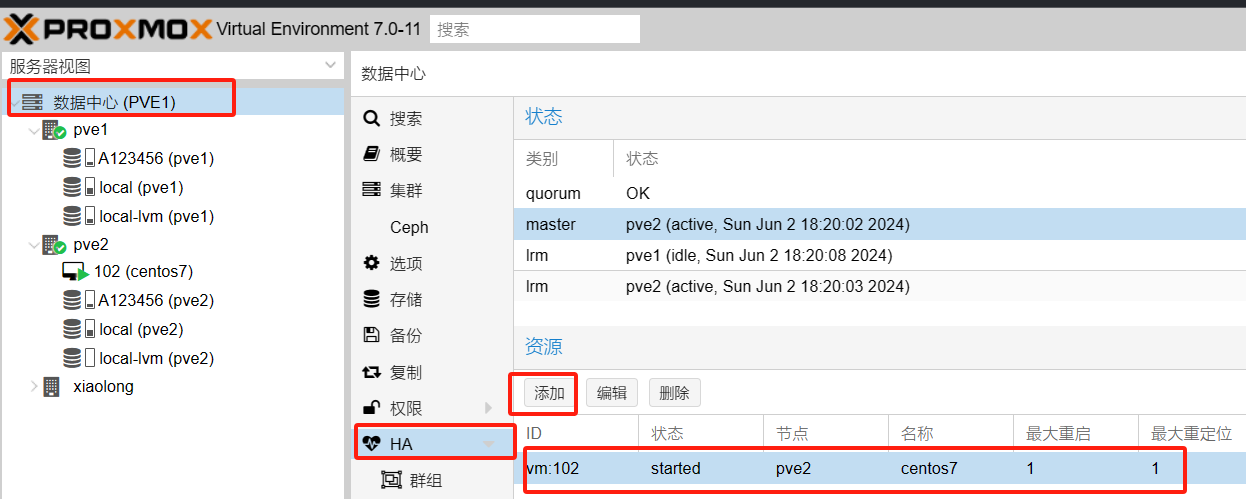
6.1配置自动故障转移进入HA
proxmox ve 部署双节点HA集群及glusterfs分布式文件系统的更多相关文章
- 在 Linux 部署多节点 Kubernetes 集群与 KubeSphere 容器平台
KubeSphere 是在 Kubernetes 之上构建的以应用为中心的企业级容器平台,所有供为用户提供简单易用的操作界面以及向导式操作方式.同时,KubeSphere Installer 提供了 ...
- 【OpenStack云平台】网络控制节点 HA 集群配置
个人名片: 因为云计算成为了监控工程师 个人博客:念舒_C.ying CSDN主页️:念舒_C.ying 网络控制节点运行在管理网络和数据网络中,如果虚拟机实例要连接到互联网,网络控制节点也需要具备 ...
- 双节点weblogic集群安装
一.准备工作 1.环境信息规划 Server name Ip地址 Port 备注 AdminServer 192.168.100.175 7001 管理服务器 Ms1 192.168.100.175 ...
- ACK容器服务发布virtual node addon,快速部署虚拟节点提升集群弹性能力
在上一篇博文中(https://yq.aliyun.com/articles/647119),我们展示了如何手动执行yaml文件给Kubernetes集群添加虚拟节点,然而,手动执行的方式用户体验并不 ...
- K8s二进制部署单节点 etcd集群,flannel网络配置 ——锥刺股
K8s 二进制部署单节点 master --锥刺股 k8s集群搭建: etcd集群 flannel网络插件 搭建master组件 搭建node组件 1.部署etcd集群 2.Flannel 网络 ...
- 在CentOS上部署多节点Citus集群
1 在所有节点执行以下步骤 Step 01 添加Citus Repostory # Add Citus repository for package manager curl https://inst ...
- 手动部署 kubernetes HA 集群
前言 关于kubernetes HA集群部署的方式有很多种(这里的HA指的是master apiserver的高可用),比如通过keepalived vip漂移的方式.haproxy/nginx负载均 ...
- Hadoop HA集群 与 开发环境部署
每一次 Hadoop 生态的更新都是如此令人激动 像是 hadoop3x 精简了内核,spark3 在调用 R 语言的 UDF 方面,速度提升了 40 倍 所以该文章肯定得配备上最新的生态 hadoo ...
- 使用QJM部署HDFS HA集群
一.所需软件 1. JDK版本 下载地址:http://www.oracle.com/technetwork/java/javase/index.html 版本: jdk-7u79-linux-x64 ...
- kubeadm部署kubernetes-1.12.0 HA集群-ipvs
一.概述 主要介绍搭建流程及使用注意事项,如果线上使用的话,请务必做好相关测试及压测. 1.基础环境准备 系统:ubuntu TLS 16.04 5台 docker-ce:17.06.2 kubea ...
随机推荐
- webpack代码分割
在做一些单页应用中,若不做任何处理,所有项目文件会打包为一个文件,这个文件非常的大,造成网页在首次进入时比较缓慢.做了代码分割后,会将代码分离到不同的chunk中,然后进行按需加载这些文件,能够提高页 ...
- 算法学习笔记(46): 离散余弦变换(DCT)
前置知识:离散傅里叶变换 傅里叶变换在上文中更多的是 OI 中的理解以及应用.但是傅里叶变换奥秘还很多. 回顾 \(\omega_n\) 在傅里叶变换中的定义:\(e^{i \frac {2\pi} ...
- 跨域问题CORS笔记
CORS跨域问题 跨域问题简介 跨域资源共享(Cross-origin resource sharing, CORS)是用于让网站资源能被不同源网站访问的一种安全机制,这个机制由浏览器与服务器共同负责 ...
- mongodb QuickStart Demo
import com.mongodb.client.MongoClient; import com.mongodb.client.MongoClients; import com.mongodb.cl ...
- springboot项目添加logback日志
1.application.yml 配置日志文件路径: logging: config: classpath:logback.xml file: /usr/local/log/projectName/ ...
- feildconfig
<template> <div style="float:left;width: 100%"> <el-row> <el-col :spa ...
- InvalidOperationException Cannot modify ServiceCollection after application is built .Net6 异常
背景 我用了一个叫Unchase.Swashbuckle.AspNetCore.Extensions的库来加强Swagger的文档,我一般写法是这样的: builder.Services.AddSwa ...
- 开启PHP-GD库
话不多说,上教程 环境 CentOS7 1. 安装php-gd yum install php-gd 2. 定位gd.so位置 rpm -qal | grep gd.so #第一行即是 3. 定位配置 ...
- Linux连接wifi,亲测成功
环境: 装有CentOS-7的物理机 步骤: 搜索日志,查看是否有安装固件的请求: 1.dmesg | grep firmware #查看是否需要安装wifi固件 如果需要安装固件:(可以先跳过此步骤 ...
- Wireshark抓包分析理解DHCP协议及工作流程
一.DHCP简介 DHCP(Dynamic Host Configuration Protocol)动态主机配置协议,前身是BOOTP协议.在大型局域网中,需要给很多主机配置地址信息,如果采用传统 ...