ELK多租户方案

一、前言
日志分析是目前重要的系统调试和问题排查的重要手段之一,而目前分布式系统由于实例和机器众多,所以构建一套统一日志系统是非常必要的;ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用,是目前的主流选择之一。
本文主要介绍如何实现一套 ELK日志系统 同时给 多套环境 、多个系统 共同使用/测试,并实现相互之间的数据与视图相互 隔离 互不影响。
二、隔离方式
常见的 ELK 架构如下图所示,分别由 Elasticsearch、Logstash、Kibana 与 FileBeat 组成。
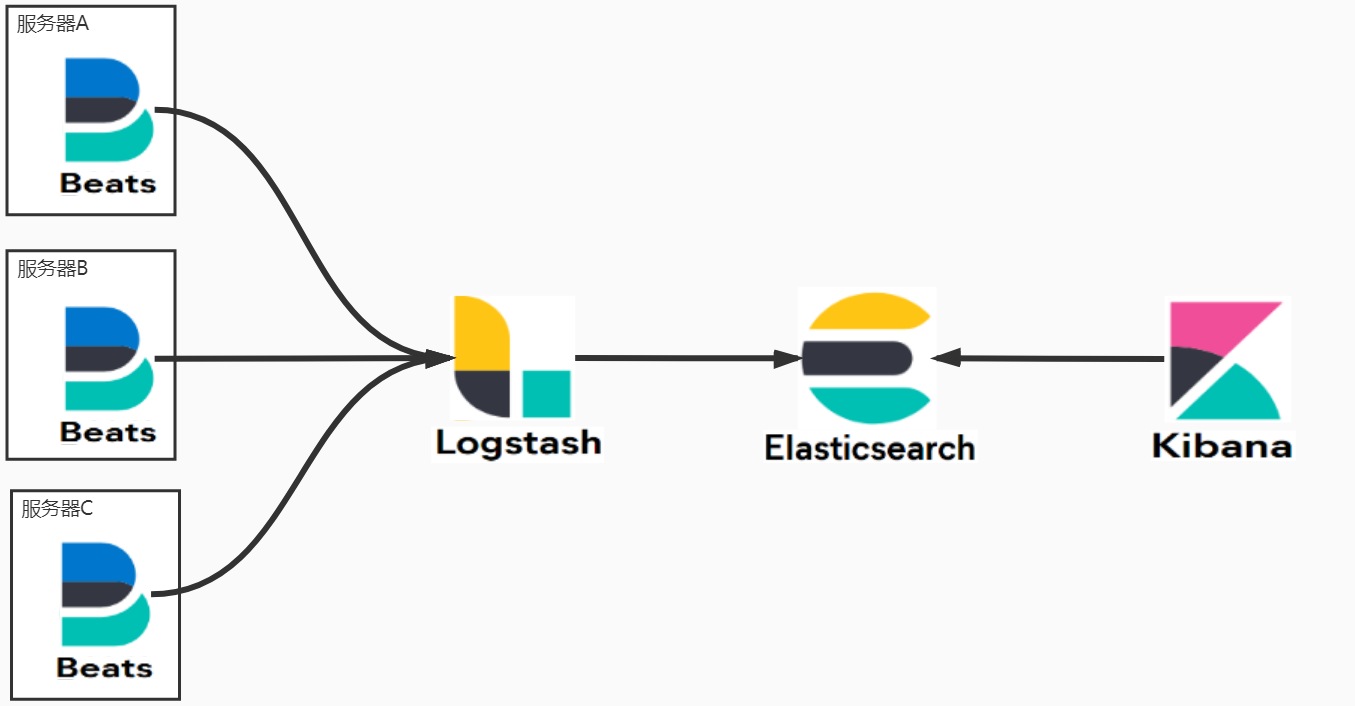
分别在每个应用服务器里部署一个 FileBeat 组件作为日志收集器,通过输入插件从文件中获取数据,然后传输给 Logstash 将通过过滤插件加工并结构化处理日志数据后发送至 Elasticsearch 存储,最后通过 Kibana 进行可视化展示分析。
PS:需要对上图中
ELK的各个组件分别做 隔离 处理
2.1. FileBeat隔离
由于每台机器上都会部署一个 Beat 实例作为日志收集,所以 FileBeat 本身无需做任何隔离配置,但是作为数据的入口需要把所属 租户 相关的信息传递给下游,如下图所示
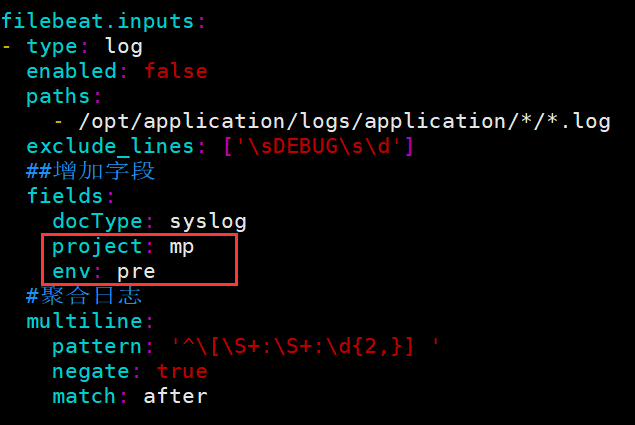
通过 project(项目名) 和 env(环境) 作为 租户 隔离标识
2.2. Logstash隔离
主要是每个项目的日志格式可能会不一样,所以会存在不同的个性化配置文件,这个 日志解析配置文件 需要定义隔离规则进行分离;
使用以下命令启动 logstash 指定 config/conf/ 为配置存放目录,并指定配置文件热加载。
bin/logstash -f config/conf/ --config.reload.automatic
日志解析配置文件隔离方法可参考下图方式:

(1)01-input-beats.conf
为通用 输入 配置,每个租户共享,用于接收来自 Filebeat 的数据
input {
beats {
port => 5044
}
}
(2)02-output-es.conf
为通用 输出 配置,每个租户共享,用于把日志数据按照定义好的 索引命名规则 创建索引写入到es中
需要在数据来源中添加
project、env和docType三个字段分别代表项目名、环境与日志类型
output {
elasticsearch {
hosts => ["localhost"]
user => "elastic"
password => "changeme"
index => "%{[fields][project]}-%{[fields][env]}-%{[fields][docType]}-%{+YYYY.MM.dd}"
}
}
ip、用户名和密码按实际情况修改
(3)mp.conf
为个性化 日志解析 配置,每个租户单独新建一个配置文件配置自己的 filter 内容
filter {
if [fields][project] == "mp" and [fields][env] == "pre" and [fields][docType] == "syslog" {
grok {
..........
}
}
}
PS:必需增加
if语句来确认是否属于自己租户的日志数据!
2.3. Elasticsearch隔离
通过不同的索引命名,创建各自独立的索引实现物理隔离;由前面的 Logstash 在结构化数据后生成索引时,已自动通过 Filebeat 的入参变量动态生成规定的索引名。
索引的命名规则为:${项目名}-${环境}-${日志类型}-%{+YYYY.MM.dd}
例如:mp-pre-syslog-2020.12.01
2.4. Kibana隔离
可通过多工作区的方式进行隔离,每个租户创建自己独立的工作空间,用于隔离自己的索引数据、展示视图等对象,并且 相互不可见。
工作区的配置流程如下:
- 创建工作区
- 创建角色(配置权限)
- 创建用户(关联角色)
2.3.1 创建工作空间
2.3.1.1 超级管理员登录
使用超级管理员账号 elastic 登录Kibana,选择 默认工作区
2.3.1.2 进入管理页面
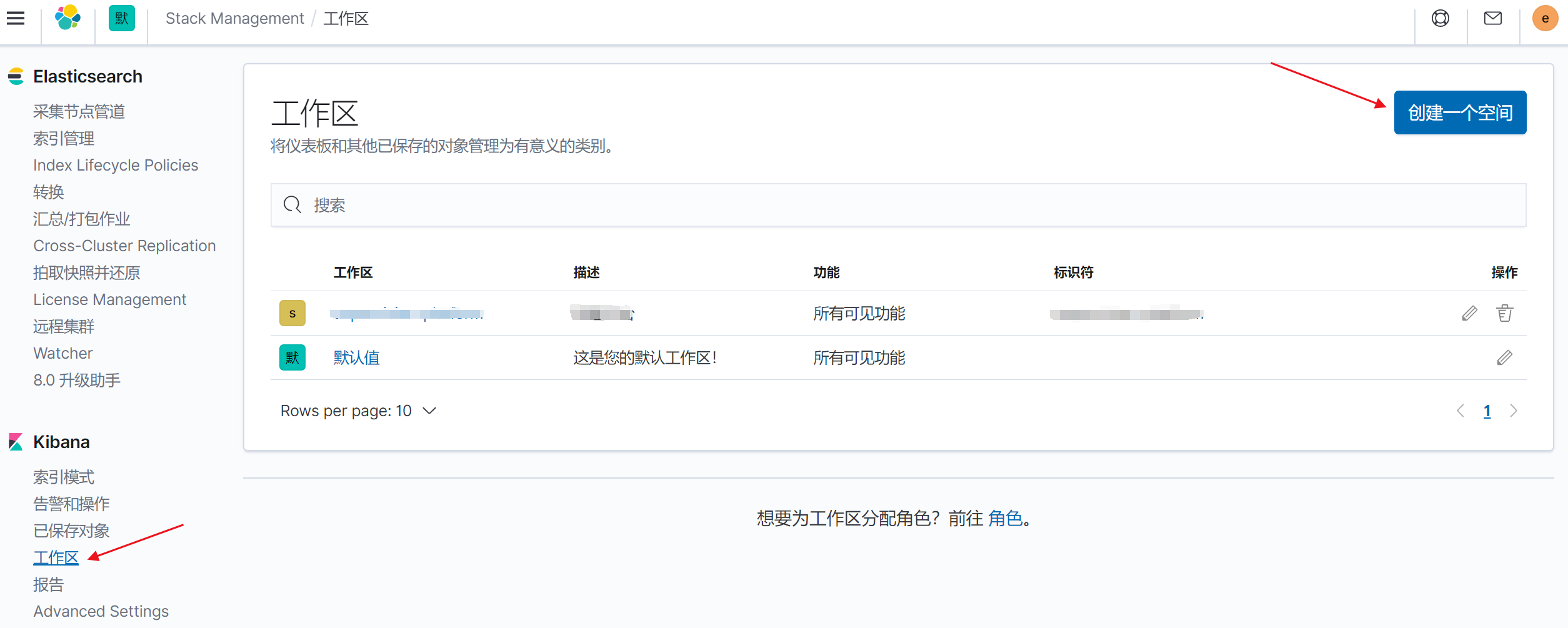
2.3.1.3 创建工作空间
创建工作区,并可定制显示的功能点(默认全部显示)
2.3.2 创建角色绑定工作空间
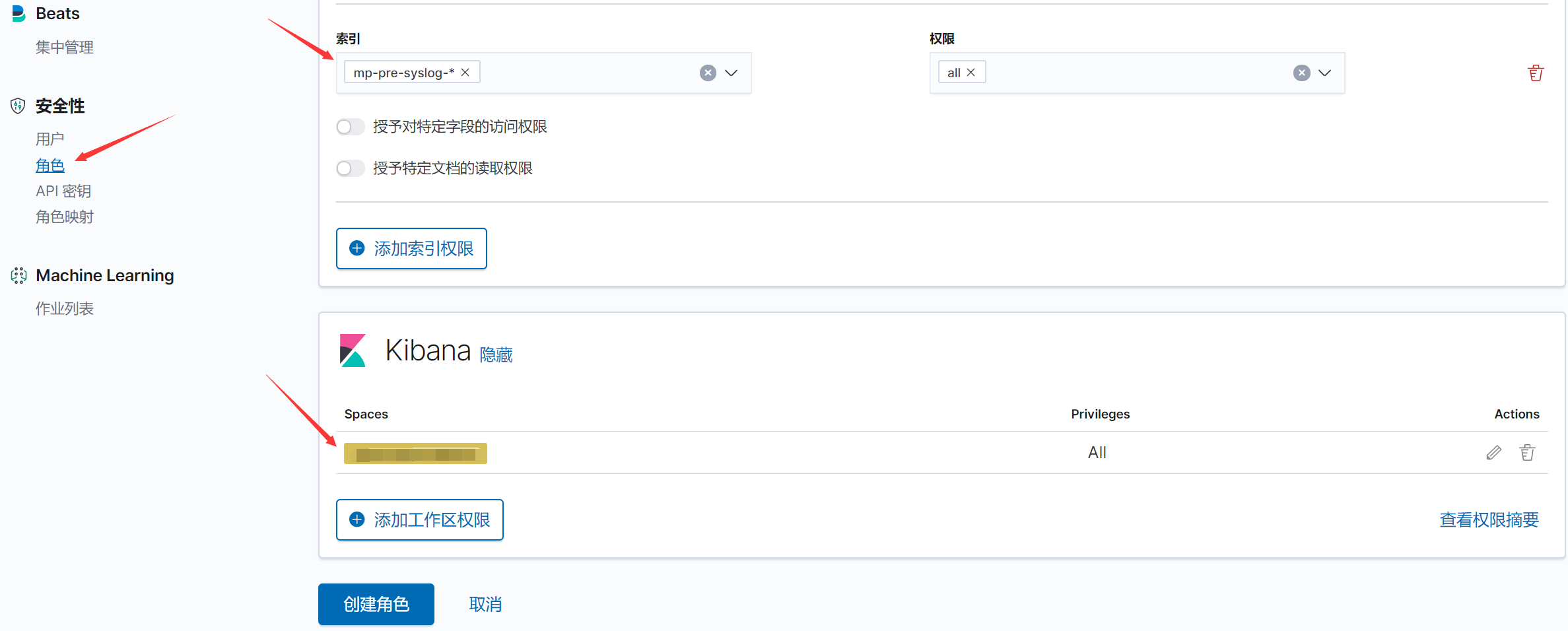
创建一个新的角色,并分配对应的 索引权限 与 工作区权限 等权限给该角色
2.3.3 创建用户
创建用户,并绑定自己 工作空间 下的角色
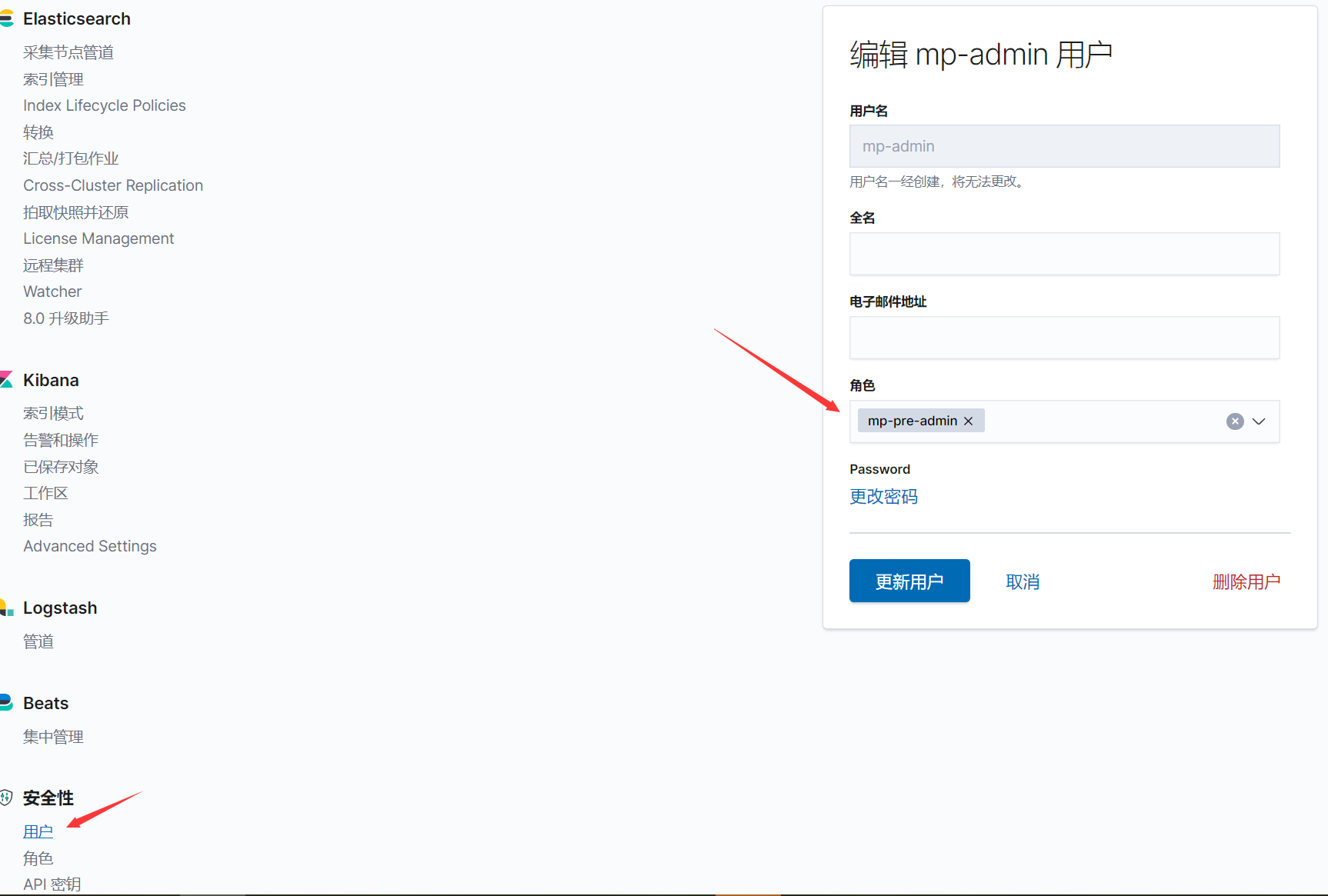
PS:该用户只能看到自己所属
工作区下的索引和仪表板等对象
三、总结
每个 租户 需对 ELK 的各个组件分别做 隔离 处理
- Filebeat:负责把区分 租户 相关的信息传递给下游
- Logstash:独立分开每个租户的个性化
Filter配置文件 - Elasticsearch:通过规范的索引命名,各租户独立的创建索引实现物理隔离
- Kibana:通过多工作区的方式进行隔离,数据与仪表板等互不可见
PS:隔离步骤虽然有点繁琐,但是后期大家可以自行开发产品化日志系统,把上述的步骤放在图形化界面上操作实现。
扫码关注有惊喜!

ELK多租户方案的更多相关文章
- ELK + kafka 日志方案
概述 本文介绍使用ELK(elasticsearch.logstash.kibana) + kafka来搭建一个日志系统.主要演示使用spring aop进行日志收集,然后通过kafka将日志发送给l ...
- FreeSql 将 Saas 租户方案精简到极致[.NET ORM SAAS]
什么是多租户 维基百科:"软件多租户是指一种软件架构,在这种软件架构中,软件的一个实例运行在服务器上并且为多个租户服务".一个租户是一组共享该软件实例特定权限的用户.有了多租户架构 ...
- FreeSql 将 Saas 租户方案精简到极致[.NET ORM]
什么是多租户 维基百科:"软件多租户是指一种软件架构,在这种软件架构中,软件的一个实例运行在服务器上并且为多个租户服务".一个租户是一组共享该软件实例特定权限的用户.有了多租户架构 ...
- ELK日志分析方案
针对公司项目微服务化,随着项目及服务器的不断增多,决定采用ELK(Elasticsearch+Logstash+Kibana)日志分析平台进行微服务日志分析. 1.ELK整体方案 1.1 ELK架构图 ...
- 实现saas多租户方案比较
看到一篇比较多租户数据隔离方案的文章,总结挺不错.其实大部分内容在我前几年写的文章都有. 文章翻译自: https://blog.arkency.com/comparison-of-approache ...
- saas系统多租户数据隔离的实现(一)数据隔离方案
0. 前言 前几天跟朋友聚会的时候,朋友说他们公司准备自己搞一套saas系统,以实现多个第三方平台的业务接入需求.聊完以后,实在手痒难耐,于是花了两天时间自己实现了两个saas系统多租户数据隔离实现方 ...
- 云计算Docker全面项目实战(Maven+Jenkins、日志管理ELK、WordPress博客镜像)
2013年,云计算领域从此多了一个名词“Docker”.以轻量著称,更好的去解决应用打包和部署.之前我们一直在构建Iaas,但通过Iaas去实现统一功 能还是相当复杂得,并且维护复杂.将特殊性封装到 ...
- 初探 ELK - 每天5分钟玩转 Docker 容器技术(89)
在开源的日志管理方案中,最出名的莫过于 ELK 了.ELK 是三个软件的合称:Elasticsearch.Logstash.Kibana. Elasticsearch一个近乎实时查询的全文搜索引擎.E ...
- 多租户实现之基于Mybatis,Mycat的共享数据库,共享数据架构
前言 SaaS模式是什么? 传统的软件模式是在开发出软件产品后,需要去客户现场进行实施,通常部署在局域网,这样开发.部署及维护的成本都是比较高的. 现在随着云服务技术的蓬勃发展,就出现了SaaS模式. ...
- SpringBoot使用ELK日志收集
本文介绍SpringBoot应用配合ELK进行日志收集. 1.有关ELK 1.1 简介 在之前写过一篇文章介绍ELK日志收集方案,感兴趣的可以去看一看,点击这里-----> <ELK日志分 ...
随机推荐
- Java遍历Map集合的方法
Java中遍历Map集合的常用方式主要有以下几种: 1.使用keySet()方法遍历 遍历Map的key集合,然后通过key获取value. Map<String, Integer> ma ...
- 喜讯!INFINI Easysearch 在墨天轮搜索型数据库排名中荣登榜首
近日,2023 年 9 月的 墨天轮中国数据库流行度排行 火热出炉,本月共有 287 个数据库参与排名,中国数据库行业竞争日益激烈.其中,极限科技旗下软件产品 INFINI Easysearch 在 ...
- 网络世界的脊柱——OSI七层模型
简介 OSI代表开放系统互联(Open Systems Interconnection),这是国际标准化组织(ISO)提出的一个概念模型,用于描述网络通信的功能划分.简单来说,OSI模型把复杂的网络通 ...
- skywalking启动配置agent及数据储存对数据源(mysql,es)版本要求
skywalking启动配置agent及数据储存对数据源(mysql,es)版本要求 # skywalking-agent.jar的本地磁盘路径-javaagent:D:\SkyWalking\sky ...
- 博客正式更换为emlog
Tips:当你看到这个提示的时候,说明当前的文章是由原emlog博客系统搬迁至此的,文章发布时间已过于久远,编排和内容不一定完整,还请谅解` 博客正式更换为emlog 日期:2017-4-2 阿珏 谈 ...
- 【长文】带你搞明白Redis
本文使用第一人称来介绍Redis 一.概述 Redis,英文全称是Remote Dictionary Server(远程字典服务),是一个开源的使用ANSI C语言编写.支持网络.可基于内存亦可持久化 ...
- 洛谷 P1216 数字三角形
题目链接:数字三角形 思路 dp:金字塔顶的元素为起点,金字塔每行的最左侧数字只能从上一层的最左侧数字到达,如7 -> 3 -> 8 -> 2 -> 4,这些数字中的每一个(除 ...
- Nuxt3 的生命周期和钩子函数(一)
title: Nuxt3 的生命周期和钩子函数(一) date: 2024/6/25 updated: 2024/6/25 author: cmdragon excerpt: 摘要:本文是关于Nuxt ...
- python基础-字符串str " "
字符串的定义和操作 字符串的特性: 元素数量 支持多个 元素类型 仅字符 下标索引 支持 重复元素 支持 可修改性 不支持 数据有序 是 使用场景 一串字符的记录场景 字符串的相关操作: my_str ...
- 【资料分享】RK3568开发板规格书(4x ARM Cortex-A55(64bit),主频1.8GHz)
1 开发板简介 创龙科技TL3568-EVM是一款基于瑞芯微RK3568J/RK3568B2处理器设计的四核ARM Cortex-A55国产工业评估板,每核主频高达1.8GHz/2.0GHz,由核心板 ...