Causal Inference理论学习篇-Tree Based-Causal Tree
Tree-Based Algorithms
Tree-based这类方法,和之前meta-learning 类的方法最明显的区别是: 这类方法把causal effect 的计算显示的加入了到了树模型节点分裂的标准中 从 response时代过渡到了effect时代。
大量的这类算法基本围绕着树节点分裂方式做文章,普遍采用的是兼容性比较高的[[万字长文讲述树模型的历史|cart树]]
Causal Tree & Honest Tree
causal tree[4] 这篇文章算是较早通过改变树模型node分裂方式来预估[[因果推断及其重要相关概念#heterogeneous causal effects|异质因果效应]](heterogeneous causal effects)的算法。
所以重点还是如何去构建 split criterion,前置可能要说一下相关的符号含义:
在特征空间 \(\mathbb X\) 下存在节点分裂方式的集合:
\]
其中以 \(\ell(x;\prod)\) 表示叶子节点\(\ell\) 属于划分方式 \(\prod\), 此时该划分方式下的,node的条件期望定义为:
\]
那么,自然如果给定样本\(S\) , 其对应节点无偏统计量为:
\]
Causal Tree 学习的目标 or loss func
学习目标使用修改后的MSE, 在标准mse的基础上多减去了一项和模型参数估计无关的\(E[Y^2]\),此外
训练即build tree阶段,train set被切为两部分,一部分训练样本train set:\(S^{tr}\) , 一部分是估计样本 est set \(S^{est}\),还有测试样本test set \(S^{te}\)
这里有点绕:和经典的树模型不一样的是:叶子节点上存储的值不是根据train set来的, 而是划分好之后通过est set进行估计。(显然, 这种方式有点费样本...)。所以,这也是文中为啥把这种方法叫做“Honest”的原因。
假设已经根据训练样本得到划分方式,那么评估这种划分方式好坏被定义为:
\]
整体求期望变成:
\]
算法的整体目标为:
\]
其中,\(\pi(S)\) 定义为:
\]
其实就是比较节点在划分后,左右子节点的输出差异是否满足阈值c,\(\bar Y_L=\mu(L)\)
节点划分方式
作者直接给出了节点划分时的loss计算标准:
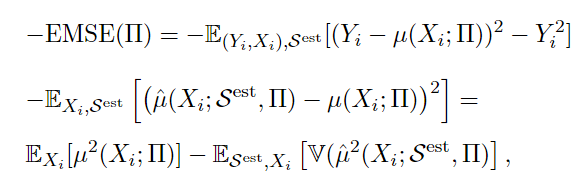
我们来推导一下:
EMSE(\small\prod)&=E_{S^{te},S^{est}}[\frac{1}{\#(S^{te})} \sum_{i\in S^{te}} \{(Y_i-\hat\mu(X_i;S^{est},\small\prod))^2-Y_i^2\}] \\
&=E_{S^{te},S^{est}}[(Y_i-\hat\mu(X_i;S^{est},\small\prod))^2-Y_i^2] \\
&=E_{S^{te},S^{est}}[(Y_i-\mu(X_i;\small\prod)+\mu(X_i;\small\prod)-\hat\mu(X_i;S^{est},\small\prod))^2 - Y_i^2] \\
&=E_{S^{te},S^{est}}[\{Y_i-\mu(X_i;\small\prod)\}^2-Y_i^2] \\
&+2E_{S^{te},S^{est}}[\{Y_i-\mu(X_i;\small\prod)\}\{(\mu(X_i;\small\prod)-\hat\mu(X_i;S^{est},\small\prod)\}] \\
&+E_{S^{te},S^{est}}[\{\mu(X_i;\small\prod)-\hat\mu(X_i;S^{est},\small\prod)\}^2]
\end{aligned}
\]
因为中间展开项期望为0, 所以公式变成:
EMSE(\small\prod)&=E_{S^{te},S^{est}}[\{Y_i-\mu(X_i;\small\prod)\}^2-Y_i^2]+E_{S^{te},S^{est}}[\{\mu(X_i;\small\prod)-\hat\mu(X_i;S^{est},\small\prod)\}^2] \\
&=E_{S^{te},S^{est}}[(\mu(X_i;\small\prod))^2-2Y_i\mu(X_i;\small\prod)]+E_{S^{te},S^{est}}[\{\mu(X_i;\small\prod)-\hat\mu(X_i;S^{est},\small\prod)\}^2]
\end{aligned}
\]
同样的,展开项的项期望为0,由于无偏估计=> \(\mu(X_i;\small \prod)=E_{S^{est}}[\hat \mu(X_i;S^{est};\small\prod)]\) ,最终公式变成:
\]
其中,\(E_{S^{est},X_i}[\mathbb V(\hat\mu(X_i;S^{est}, \small\prod))]=E_{S^{te},S^{est}}[\{\hat\mu(X_i;S^{est},\small\prod)-\mu(X_i;\small\prod\}^2]\)
公式中第一项可以理解为偏差的平方,第二项理解为方差。为什么MSE可以被理解成偏差和方差的组合,以及展开项为0
我们来证明一下:(开个玩笑:),其实我是抄的Wikipedia,可以看证明1和证明2:
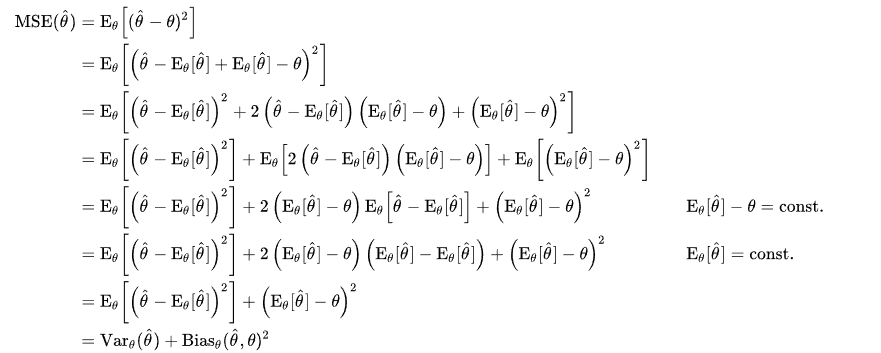
偏差项
接着分析偏差项:
E_{X_i}\left[\mu^2\left(X_i ; \Pi\right)\right] & =E_{X_i}\left\{\left[E_S\left(\hat{\mu}\left(X_i ; S, \Pi\right)\right)\right]^2\right\} \\
& =E_{X_i}\left\{E_S\left[\hat{\mu}^2\left(X_i ; S, \Pi\right)\right]-\mathbb V_S\left[\hat{\mu}\left(X_i ; S, \Pi\right)\right]\right\} \\
& =E_{X_i}\left\{E_S\left[\hat{\mu}^2\left(X_i ; S, \Pi\right)\right]\right\}-E_{X_i}\left\{\mathbb V_S\left[\hat{\mu}\left(X_i ; S, \Pi\right)\right]\right\}
\end{aligned}
\]
第一项总体估计值的期望使用训练集的样本,即:
\]
第二项方差项,叶子节点方差求均值
\]
对于最外层的期望:
\hat{E}_{X_i}\left[\mu^2\left(X_i ; \Pi\right)\right] & =\sum_{l \in \Pi} \frac{N_l^{t r}}{N^{t r}} \hat{\mu}^2\left(X_i ; S^{t r}, \Pi\right)-\sum_{l \in \Pi} \frac{N_l^{t r}}{N^{t r}} \frac{S_{t r}^2[\ell(x, \Pi)]}{N_\ell^{t r}} \\
& =\frac{1}{N^{t r}} \sum_{i \in S^{t r}} \hat{\mu}^2\left(X_i ; S^{t r}, \Pi\right)-\frac{1}{N^{t r}} \sum_{\ell \in \Pi} S_{t r}^2[\ell(x, \Pi)]
\end{aligned}
\]
方差项
\]
\]
整合
最终估计量为:
\]
\]
其中, 偏差和方差不过的est估计量应该用est set,但是此处假设了train set和est set 同分布。
treatment effect 介入划分:处理异质效应
前面定义了MSE的范式,当需要考虑到异质效应时,定义异质效应:
\]
很显然,我们永远观测不到异质性处理效应,因为我们无法观测到反事实,我们只能够估计处理效应,给出异质性处理效应的估计量:
\]
因果效应下的EMSE为:
\]
\]
使用\(\tau\)替代了\(\mu\) , 偏差项, 带入整合公式:
\]
其中,\(p\)表示相应treatment组的样本占比,该子式也是最终的计算节点分类标准的公式
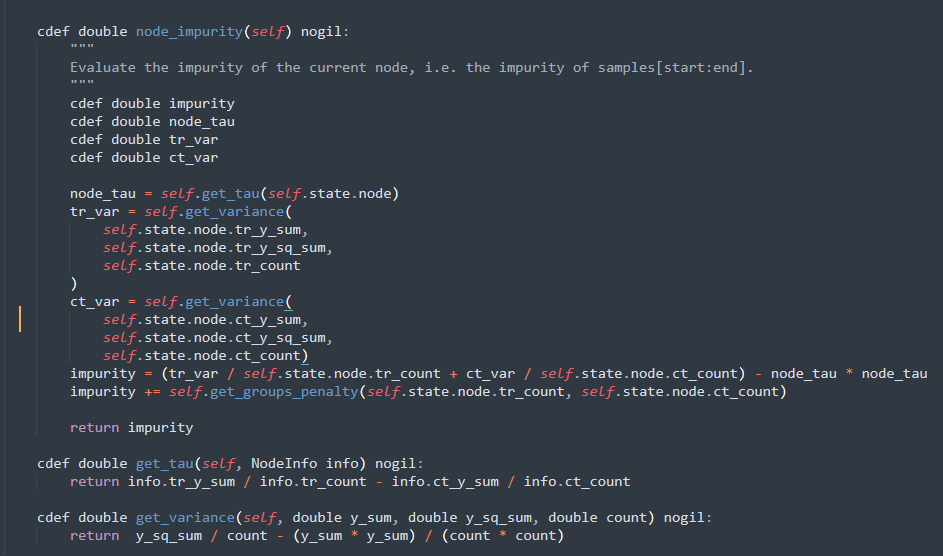
有了节点划分方式之后,build tree的过程和CART树是一样的
推理过程
推理过程和决策树基本一样,树建好之后,只用根据每个node存储的特征和threshold进行path 遍历,走到叶子节点返回值即可。
一般来说,causal tree的叶子节点存储的
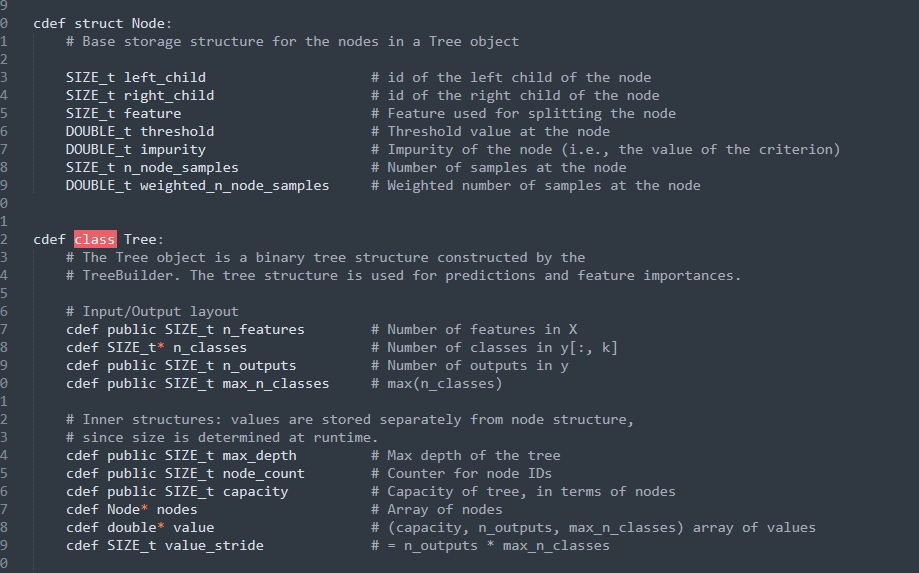
结构体之外还单独存储了一个 叫 value 的数组,主要是存储每个节点的预测值。对于两个Treatment来说,存储的大小就是1x2的list,第一个element存储了control的 正样本比例,第二个element存储了treatment的正样本比例。
一般来说,这个比例会做配平或者说惩罚:
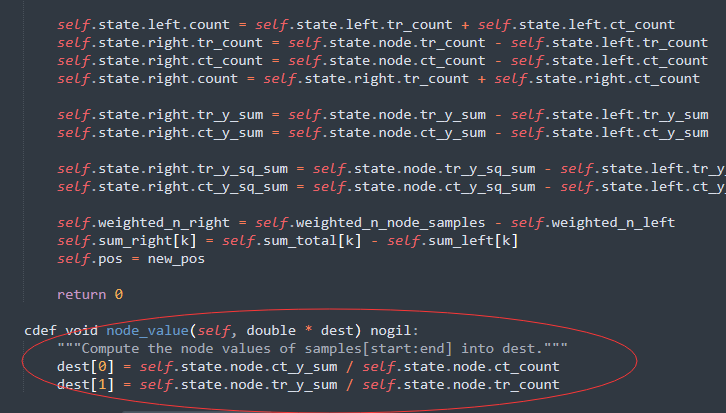
所以,最终推理得到的是一个输入一个样本X,得到T-C的treatment effect,我们不用像meta-learning类的模型一样,自己手动减得到ITE。
Causal Tree总结
- 作者改进了MSE,主动减去了一项模型参数无关的\(E[Y_i^2]\)。改进方法的MSE包含了组内方差,这个方差越大,MSE就会越低,所以它能够在一定程度上限制模型的复杂性
- 把改进的 mse loss apply 到CATE中来指导节点分割 和 建立决策树
- 构建树的过程中,train set切割为了 \(S^{tr}\) 和 \(S^{est}\) 两部分,node的预测值由\(S^{est}\) 进行无偏估计,虽然最后实际上\(S^{est}\) 用train set替代了。
- 理论上causal tree 仅支持 两个Treatment
如果使用causalml的package,如果存在多个T,非C组都会被置为一个T
REF
- https://hwcoder.top/Uplift-1
- 工具: scikit-uplift
- Meta-learners for Estimating Heterogeneous Treatment Effects using Machine Learning
- Athey, Susan, and Guido Imbens. "Recursive partitioning for heterogeneous causal effects." Proceedings of the National Academy of Sciences 113.27 (2016): 7353-7360.
- https://zhuanlan.zhihu.com/p/115223013
Causal Inference理论学习篇-Tree Based-Causal Tree的更多相关文章
- Targeted Learning R Packages for Causal Inference and Machine Learning(转)
Targeted learning methods build machine-learning-based estimators of parameters defined as features ...
- 因果推理综述——《A Survey on Causal Inference》一文的总结和梳理
因果推理 本文档是对<A Survey on Causal Inference>一文的总结和梳理. 论文地址 简介 关联与因果 先有的鸡,还是先有的蛋?这里研究的是因果关系,因果关系与普通 ...
- A Complete Tutorial on Tree Based Modeling from Scratch (in R & Python)
A Complete Tutorial on Tree Based Modeling from Scratch (in R & Python) MACHINE LEARNING PYTHON ...
- Linux 指令篇:磁盘管理--tree
Linux 指令篇:磁盘管理--tree 功能说明:以树状图列出目录的内容. 语 法:tree [-aACdDfFgilnNpqstux][-I <范本样式>][-P <范本样式&g ...
- Python入门篇-数据结构树(tree)的遍历
Python入门篇-数据结构树(tree)的遍历 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.遍历 迭代所有元素一遍. 二.树的遍历 对树中所有元素不重复地访问一遍,也称作扫 ...
- Python入门篇-数据结构树(tree)篇
Python入门篇-数据结构树(tree)篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.树概述 1>.树的概念 非线性结构,每个元素可以有多个前躯和后继 树是n(n& ...
- 【统计】Causal Inference
[统计]Causal Inference 原文传送门 http://www.stat.cmu.edu/~larry/=sml/Causation.pdf 过程 一.Prediction 和 causa ...
- Causal Inference
目录 Standardization 非参数情况 Censoring 参数模型 Time-varying 静态 IP weighting 无参数 Censoring 参数模型 censoring 条件 ...
- 算法---FaceNet理论学习篇
FaceNet算法-理论学习篇 @WP20190228 ==============目 录============ 一.LFW数据集简介 二.FaceNet算法简介 FaceNet算法=MTCNN模型 ...
- B-Tree、B+Tree和B*Tree
B-Tree(这儿可不是减号,就是常规意义的BTree) 是一种多路搜索树: 1.定义任意非叶子结点最多只有M个儿子:且M>2: 2.根结点的儿子数为[2, M]: 3.除根结点以外的非叶子结点 ...
随机推荐
- 苏宁基于 AI 和图技术的智能监控体系的建设
汤泳,苏宁科技集团智能监控与运维产研中心总监,中国商业联合会智库顾问,致力于海量数据分析.基于深度学习的时间序列分析与预测.自然语言处理和图神经网络的研究.在应用实践中,通过基于 AI 的方式不断完善 ...
- 用linux命令cd 查找想要找的文件
如果想找文件Computer下的bin文件,在终端输入绝对路径 cd /bin,不能输入 cd /Computer/bin,因为文件目录不对 文件目录可以在文件的终端看到,/bin就是正确的目录 比如 ...
- 为Oracle链接服务器使用分布式事务
1 现象 在SQL Server中创建指向Oracle的链接服务器,SQL语句在事务中向链接服务器插入数据.返回链接服务器无法启动分布式事务的报错. 2 解决 在Windows平台下,SQL Serv ...
- 面试准备不充分,被Java守护线程干懵了,面试官主打一个东西没用但你得会
写在开头 面试官:小伙子请聊一聊Java中的精灵线程? 我:什么?精灵线程?啥时候精灵线程? 面试官:精灵线程没听过?那守护线程呢? 我:守护线程知道,就是为普通线程服务的线程嘛. 面试官:没了?守护 ...
- Python函数对象与闭包函数
[一]函数对象 函数对象指的是函数可以被当做 数据 来处理,具体可以分为四个方面的使用 [1]函数可以被引用 def add(x,y): return x + y func = add res = f ...
- JS2-DOM
API和Web API API 应用程序编程接口,目的是提供应用程序与开发人员基于某软件或硬件得以访问一组例程的能力,且又无需访问源码,或理解内部工作机制的细节 API是给程序员提供的一种工具,以便能 ...
- 摆脱鼠标操作 vscode-vim-use-readme.md
vscode-vim 学习笔记 梳理下自己定义的快捷键 Normal模式返回 ESC capsLock 双击shift ctrl+[ jj ctrl+c (这个键比较特殊 用习惯y的话,考虑这个) 一 ...
- 新博客 VuejsDev.com 用于梳理知识点
新博客 VuejsDev.com 用于梳理知识点 https://www.vuejsdev.com/ 后期没有精力发布了,迁移到博客园了,防止服务器到期~ [VueJsDev] 目录列表 https: ...
- react 中 动态添加 class,防止图片 重复加载, 主要是 background-image的二次加载会有新请求,和图片的闪烁
react 中 动态添加 class,防止图片 重复加载, 主要是 background-image的二次加载会有新请求,和图片的闪烁 let imageTopBg if (imgSrcBg) { c ...
- c语言随笔
c语言随笔 整型数据类型 unsigned int [signed] int [signed] short [int] unsigned long long [int] // long long 为c ...