mybatis查询大批量数据的几种方式
问题背景
公司里有很多需要跑批数据的场景,这些数据几十万到几千万不等,目前我们采用的是分页查询,但是分页查询有个深度分页问题,上百万的数据就会查询的很慢
常规解决方案
- 全量查询
- 分页查询
- 流式查询
- 游标查询
1. 全量查询
默认情况下,全量查询的话系统会把所有结果集存储在内存中,在数据库中准备了大概200w的数据:
<select id="listUser" resultType="com.sun.ddd.infra.po.User">
select * from user
</select>
@Test
public void test() {
StopWatch stopWatch = new StopWatch();
stopWatch.start("全量查询");
List<User> users = userService.listUser();
stopWatch.stop();
System.out.println(stopWatch.getLastTaskName() + ":" + stopWatch.getLastTaskTimeMillis() + ":代码行数:" + users.size());
}
全量查询:21757:代码行数:2778523
利用JDK自带的java VisualVM监控全量查询时的内存占用情况
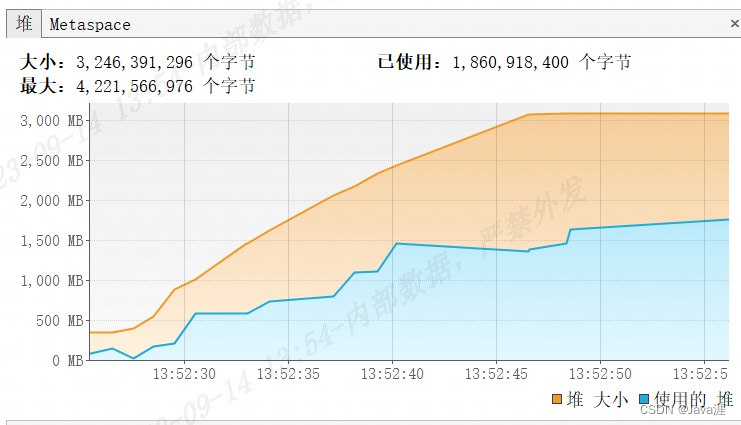
- 可以很明显的看出
200w的数据一次性查询占用总体内存1500MB,这个内存占用还是很大的,如果还有其他服务在运行,很容易导致OOM
2. 分页查询
为了解决全量查询占用内存过大,可能导致OOM问题,我们可以选择使用分页查询,这样就不会导致内存溢出问题了
@Override
public List<User> pageUser(Integer pageNum, Integer pageSize) {
pageNum = (pageNum - 1) * pageSize;
return userDao.pageUser(pageNum, pageSize);
}
<select id="pageUser" resultType="com.sun.ddd.infra.po.User">
select * from user limit #{pageNum},#{pageSize}
</select>
@Test
public void test() {
StopWatch stopWatch = new StopWatch();
stopWatch.start("分页查询");
int pageCount = 0;
for (int i = 1; i < 1000; i++) {
List<User> users1 = userService.pageUser(i, 2000);
pageCount = pageCount + users1.size();
}
stopWatch.stop();
System.out.println(stopWatch.getLastTaskName() + ":" + stopWatch.getLastTaskTimeMillis() + ":代码行数:" + pageCount);
}
分页查询:285343:代码行数:1998000
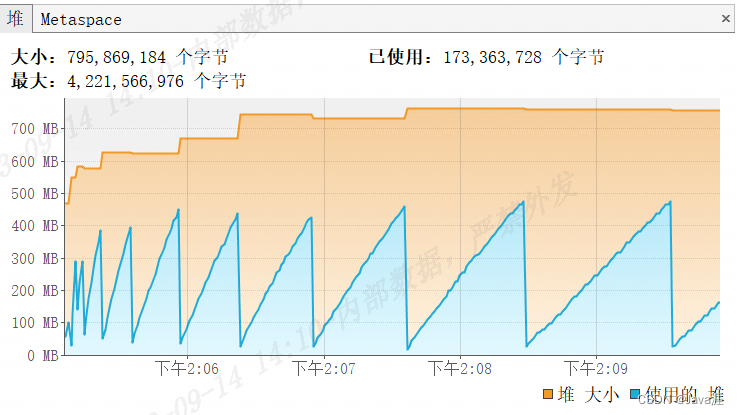
- 使用分页后,查询内存使用情况,最多占用内存不到
500MB,是全量查询占用内存的1/3不到,但是由于深度分页和多次与数据库连接的缘故,导致整个查询时间很长,长达280s,如果数据更多点查询时间则更多
3. 流式查询
那有没有什么方式,可以查的又快,占用内存又小呢?答案当然是有的了
客户端 JDBC 发起 SQL 查询,等待服务端准备数据。MySQL 服务端会向 JDBC 代表的客户端内核源源不断的输送数据,直到客户端请求 Socket 缓冲区满,这时的 MySQL服务端会阻塞。对于 JDBC 客户端而言,数据每次读取都是从本机器的内核缓冲区,所以性能会更快一些。类似服务端向客户端不断push的过程
是否使用流式的标志:
/**
* We only stream result sets when they are forward-only, read-only, and the
* fetch size has been set to Integer.MIN_VALUE
*
* @return true if this result set should be streamed row at-a-time, rather
* than read all at once.
*/
protected boolean createStreamingResultSet() {
return ((this.query.getResultType() == Type.FORWARD_ONLY) && (this.resultSetConcurrency == java.sql.ResultSet.CONCUR_READ_ONLY)
&& (this.query.getResultFetchSize() == Integer.MIN_VALUE));
}
其中我们只要关注this.query.getResultFetchSize() == Integer.MIN_VALUE,对应xml配置就是fetchSize="-2147483648"
<select id="listUserByStream" fetchSize="-2147483648" resultType="com.sun.ddd.infra.po.User">
select * from user
</select>
这里mapper接口不需要返回值,因为数据都存储在ResultHandler<User>中了
void listUserByStream(ResultHandler<User> handler);
@Test
public void test() {
StopWatch stopWatch = new StopWatch();
stopWatch.start("流式查询");
AtomicInteger totalCount = new AtomicInteger(0);
userService.listUserByStream(context -> {
// 处理查询结果
context.getResultObject();
totalCount.incrementAndGet();
});
stopWatch.stop();
System.out.println(stopWatch.getLastTaskName() + ":" + stopWatch.getLastTaskTimeMillis() + ":代码行数:" + totalCount.get());
}
流式查询:9967:代码行数:2778523
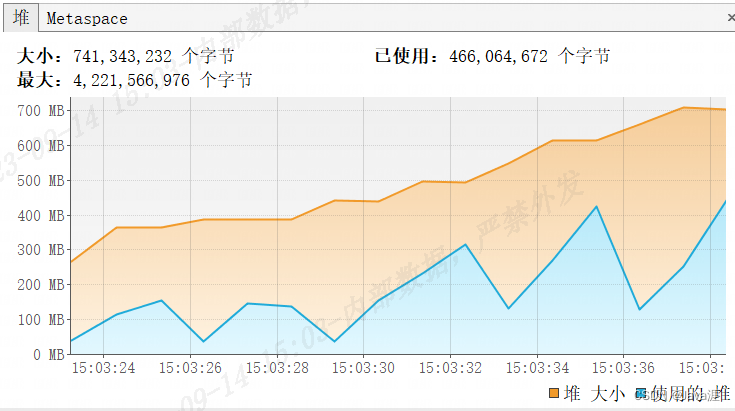
同样是
200w数据,可以明显看出查询时间只要9s多,占用内存也保持在500MB之内4. 游标查询
客户端
JDBC发起SQL查询,等待服务端准备数据。服务端数据准备完成后,进行数据传输,它允许应用程序在数据库服务器上打开一个游标并按需检索数据,而不是一次性获取整个结果集,类似客户端向服务端分批pull的过程。mapper接口层接收参数方式使用Cursor<User>Cursor<User> listUserByCursor();
<select id="listUserByCursor" fetchSize="-2147483648" resultType="com.sun.ddd.infra.po.User">
select * from user
</select>
@Test
@Transactional
public void test() {
StopWatch stopWatch = new StopWatch();
stopWatch.start("游标查询");
AtomicInteger totalCountCursor = new AtomicInteger(0);
Cursor<User> users2 = userService.listUserByCursor();
for (User user : users2) {
totalCountCursor.incrementAndGet();
}
stopWatch.stop();
System.out.println(stopWatch.getLastTaskName() + ":" + stopWatch.getLastTaskTimeMillis() + ":代码行数:" + totalCountCursor.get());
}
由于Cursor是一条条查,所以会关闭会话,需要在方法上加@Transactional即可
游标查询:9813:代码行数:2778523
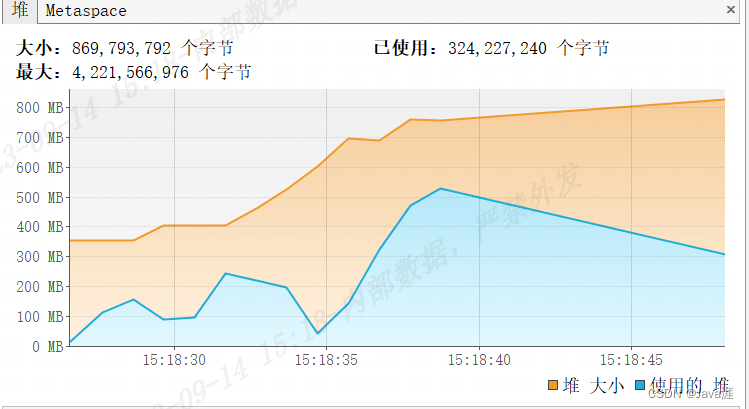
从测试结果来看,查询
200w条数据时间跟流式查询差不多,占用的内存也不到500MB
总结:
| 查询方式 | 数据条数 | 查询时间 | 占用内存 |
|---|---|---|---|
| 全量查询 | 2778523 | 21757 | 1600MB |
| 分页查询 | 1998000 | 285343 | 500MB |
| 流式查询 | 2778523 | 9967 | 450MB |
| 游标查询 | 2778523 | 9813 | 550MB |
推荐使用流式查询,游标查询还跟指定数据库有关
mybatis查询大批量数据的几种方式的更多相关文章
- android sqlite使用之模糊查询数据库数据的三种方式
android应用开发中常常需要记录一下数据,而在查询的时候如何实现模糊查询呢?很少有文章来做这样的介绍,所以这里简单的介绍下三种sqlite的模糊查询方式,直接上代码把: package com.e ...
- mybatis批量添加数据的三种方式
原文地址:https://www.cnblogs.com/gxyandwmm/p/9565002.html
- mybatis中批量插入的两种方式(高效插入)
MyBatis简介 MyBatis是一个支持普通SQL查询,存储过程和高级映射的优秀持久层框架.MyBatis消除了几乎所有的JDBC代码和参数的手工设置以及对结果集的检索封装.MyBatis可以使用 ...
- Linux就这个范儿 第15章 七种武器 linux 同步IO: sync、fsync与fdatasync Linux中的内存大页面huge page/large page David Cutler Linux读写内存数据的三种方式
Linux就这个范儿 第15章 七种武器 linux 同步IO: sync.fsync与fdatasync Linux中的内存大页面huge page/large page David Cut ...
- Solr 删除数据的几种方式
原文出处:http://blog.chenlb.com/2010/03/solr-delete-data.html 有时候需要删除 Solr 中的数据(特别是不重做索引的系统中,在重做索引期间).删除 ...
- 查询json数据结构的8种方式
查询json数据结构的8种方式 你有没有对“在复杂的JSON数据结构中查找匹配内容”而烦恼.这里有8种不同的方式可以做到: JsonSQL JsonSQL实现了使用SQL select语句在json数 ...
- MyBatis开发Dao层的两种方式(原始Dao层开发)
本文将介绍使用框架mybatis开发原始Dao层来对一个对数据库进行增删改查的案例. Mapper动态代理开发Dao层请阅读我的下一篇博客:MyBatis开发Dao层的两种方式(Mapper动态代理方 ...
- MyBatis开发Dao层的两种方式(Mapper动态代理方式)
MyBatis开发原始Dao层请阅读我的上一篇博客:MyBatis开发Dao层的两种方式(原始Dao层开发) 接上一篇博客继续介绍MyBatis开发Dao层的第二种方式:Mapper动态代理方式 Ma ...
- Day20-单表中获取表单数据的3种方式
1. 搭建环境请参考:http://www.cnblogs.com/momo8238/p/7508677.html 2. 创建表结构 models.py from django.db import m ...
- python爬虫---爬虫的数据解析的流程和解析数据的几种方式
python爬虫---爬虫的数据解析的流程和解析数据的几种方式 一丶爬虫数据解析 概念:将一整张页面中的局部数据进行提取/解析 作用:用来实现聚焦爬虫的吧 实现方式: 正则 (针对字符串) bs4 x ...
随机推荐
- SqlSugar子查询
1.基础教程 1.1 API目录 *****只查一列***** //First: SqlFunc.Subqueryable<School>().Where(s => s.Id == ...
- PGL图学习项目合集&数据集分享&技术归纳业务落地技巧[系列十]
PGL图学习项目合集&数据集分享&技术归纳业务落地技巧[系列十] 1.PGL图学习项目合集 1.1 关于图计算&图学习的基础知识概览:前置知识点学习(PGL)[系列一] :ht ...
- VSCode实现GDB图形界面远程调试
前言 在习惯了集成开发环境的图形界面调试时,首次使用GDB远程调试必定很不习惯,下面讲述如何利用VSCode实现GDB图形界面远程调试 代码在Linux服务器上,而平常都在Windows上使用,那么V ...
- 执行orachk检查数据库环境
Exadata环境巡检需要执行专有的exachk,而普通Oracle环境可以通过执行orachk来检查集群和数据库相关健康状况. 1.使用orachk检查健康状态 使用root用户执行,期间可能需要多 ...
- JDK + Tomcat 安装 + 制作自定义镜像【第 2.1 篇 Tomcat 日志满问题】
更好的方法,跨平台(不依赖平台,比如阿里云的后台)的方法是:spring boot 定时任务,直接在程序里写定时清除日志的任务:以后再说: ============================== ...
- Shell中调用可执行文件,手动执行可以执行,crontab执行就报错:exec: java: not found
今天发现一个很奇怪的问题,就是我编写的shell脚本, 手动执行可以正常执行,但是放到crontab中就报错.line 60: exec: java: not found 百度搜索发现原来是java ...
- 零基础入门Vue之拘元遣将——其他常用指令&自定义指令
回首 在 零基础入门Vue之梦开始的地方--插值语法 我记录了v-bind.v-on.v-model的学习 在 零基础入门Vue之To be or not to be--条件渲染 我记录了v-if.v ...
- 吉特日化MES & WMS 与周边系统集成架构
作者:情缘 出处:http://www.cnblogs.com/qingyuan/ 关于作者:从事仓库,生产软件方面的开发,在项目管理以及企业经营方面寻求发展之路 版权声明:本文版权归作者和博客园 ...
- 如何从零实现属于自己的 API 网关?
序言 上一篇文章:你连对外接口签名都不会知道?有时间还是要学习学习. 有很多小伙伴反应,对外的 API 中相关的加签,验签这些工作可以统一使用网关去处理. 说到网关,大家肯定比较熟悉.市面上使用比较广 ...
- Ubuntu18.04 Server部署Flannel网络的Kubernetes
准备服务器 ESXi6.5安装Ubuntu18.04 Server, 使用三台主机, 计划使用hostname为 kube01, kube02, kube03, 配置为2核4G/160G, K8s要求 ...