Spark RDD :Spark API--Spark RDD
一、RDD的概述
1.1 什么是RDD?
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。RDD具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。
1.2 RDD的属性
(1)一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
(2)一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
(3)RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
(4)一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
(5)一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
1.3 WordCount粗图解RDD
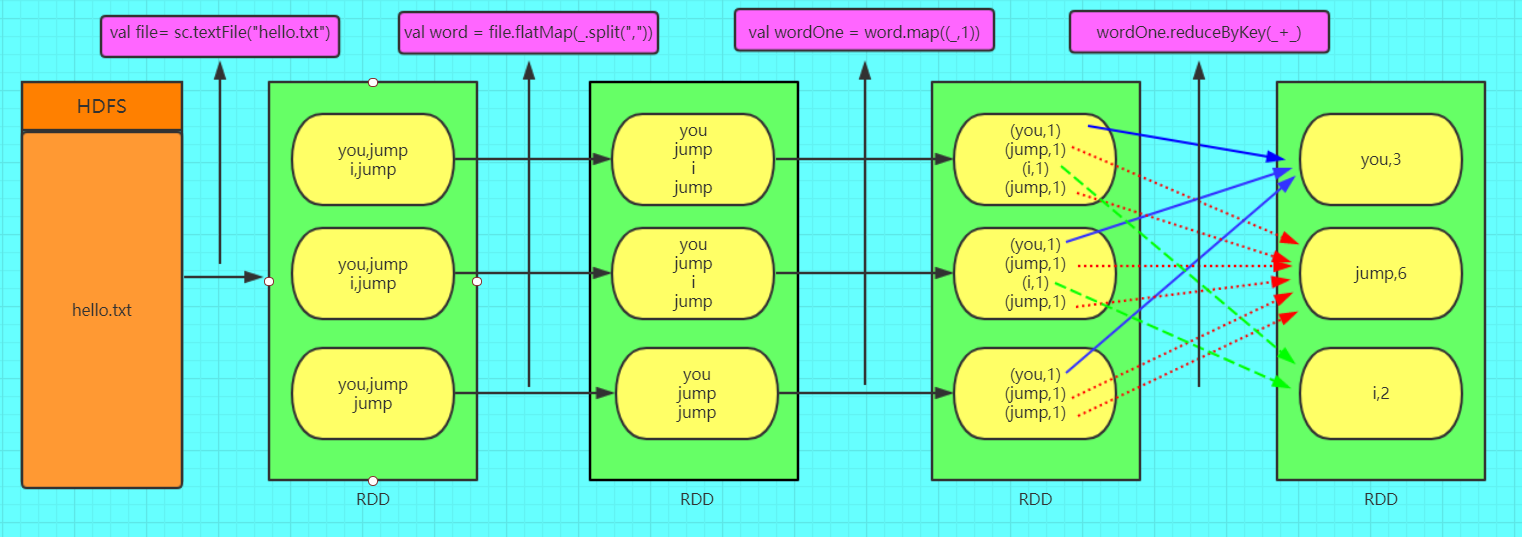
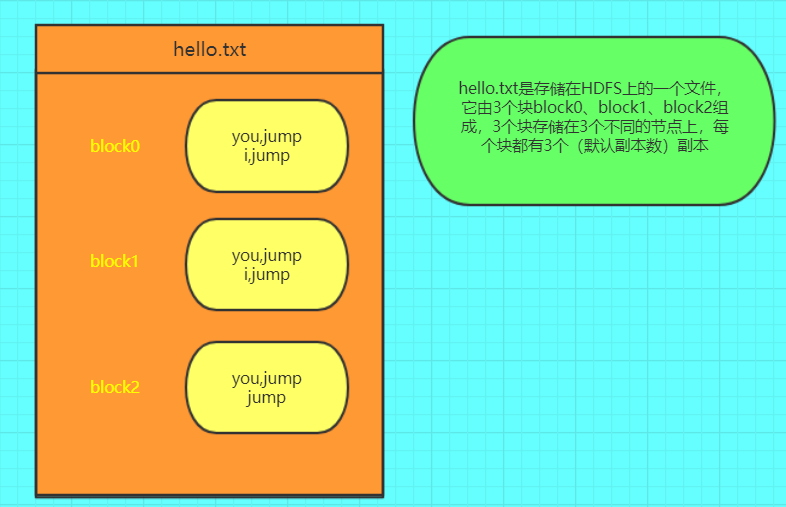
其中hello.txt
二、RDD的创建方式
2.1 通过读取文件生成的
由外部存储系统的数据集创建,包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等
scala> val file = sc.textFile("/spark/hello.txt")
2.2 通过并行化的方式创建RDD
由一个已经存在的Scala集合创建。
scala> val array = Array(1,2,3,4,5)
array: Array[Int] = Array(1, 2, 3, 4, 5) scala> val rdd = sc.parallelize(array)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[27] at parallelize at <console>:26 scala>

2.3 其他方式
读取数据库等等其他的操作。也可以生成RDD。
RDD可以通过其他的RDD转换而来的。
三、RDD编程API
Spark支持两个类型(算子)操作:Transformation和Action
3.1 Transformation
主要做的是就是将一个已有的RDD生成另外一个RDD。Transformation具有lazy特性(延迟加载)。Transformation算子的代码不会真正被执行。只有当我们的程序里面遇到一个action算子的时候,代码才会真正的被执行。这种设计让Spark更加有效率地运行。
常用的Transformation:
|
转换 |
含义 |
|
map(func) |
返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 |
|
filter(func) |
返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成 |
|
flatMap(func) |
类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) |
|
mapPartitions(func) |
类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U] |
|
mapPartitionsWithIndex(func) |
类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是 (Int, Interator[T]) => Iterator[U] |
|
sample(withReplacement, fraction, seed) |
根据fraction指定的比例对数据进行采样,可以选择是否使用随机数进行替换,seed用于指定随机数生成器种子 |
|
union(otherDataset) |
对源RDD和参数RDD求并集后返回一个新的RDD |
|
intersection(otherDataset) |
对源RDD和参数RDD求交集后返回一个新的RDD |
|
distinct([numTasks])) |
对源RDD进行去重后返回一个新的RDD |
|
groupByKey([numTasks]) |
在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
|
reduceByKey(func, [numTasks]) |
在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置 |
|
aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) |
先按分区聚合 再总的聚合 每次要跟初始值交流 例如:aggregateByKey(0)(_+_,_+_) 对k/y的RDD进行操作 |
|
sortByKey([ascending], [numTasks]) |
在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
|
sortBy(func,[ascending], [numTasks]) |
与sortByKey类似,但是更灵活 第一个参数是根据什么排序 第二个是怎么排序 false倒序 第三个排序后分区数 默认与原RDD一样 |
|
join(otherDataset, [numTasks]) |
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD 相当于内连接(求交集) |
|
cogroup(otherDataset, [numTasks]) |
在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的RDD |
|
cartesian(otherDataset) |
两个RDD的笛卡尔积 的成很多个K/V |
|
pipe(command, [envVars]) |
调用外部程序 |
|
coalesce(numPartitions) |
重新分区 第一个参数是要分多少区,第二个参数是否shuffle 默认false 少分区变多分区 true 多分区变少分区 false |
|
repartition(numPartitions) |
重新分区 必须shuffle 参数是要分多少区 少变多 |
|
repartitionAndSortWithinPartitions(partitioner) |
重新分区+排序 比先分区再排序效率高 对K/V的RDD进行操作 |
|
foldByKey(zeroValue)(seqOp) |
该函数用于K/V做折叠,合并处理 ,与aggregate类似 第一个括号的参数应用于每个V值 第二括号函数是聚合例如:_+_ |
|
combineByKey |
合并相同的key的值 rdd1.combineByKey(x => x, (a: Int, b: Int) => a + b, (m: Int, n: Int) => m + n) |
|
partitionBy(partitioner) |
对RDD进行分区 partitioner是分区器 例如new HashPartition(2 |
|
cache |
RDD缓存,可以避免重复计算从而减少时间,区别:cache内部调用了persist算子,cache默认就一个缓存级别MEMORY-ONLY ,而persist则可以选择缓存级别 |
|
persist |
|
|
|
|
|
Subtract(rdd) |
返回前rdd元素不在后rdd的rdd |
|
leftOuterJoin |
leftOuterJoin类似于SQL中的左外关联left outer join,返回结果以前面的RDD为主,关联不上的记录为空。只能用于两个RDD之间的关联,如果要多个RDD关联,多关联几次即可。 |
|
rightOuterJoin |
rightOuterJoin类似于SQL中的有外关联right outer join,返回结果以参数中的RDD为主,关联不上的记录为空。只能用于两个RDD之间的关联,如果要多个RDD关联,多关联几次即可 |
|
subtractByKey |
substractByKey和基本转换操作中的subtract类似只不过这里是针对K的,返回在主RDD中出现,并且不在otherRDD中出现的元素 |
3.2 Action
触发代码的运行,我们一段spark代码里面至少需要有一个action操作。
常用的Action:
|
动作 |
含义 |
|
reduce(func) |
通过func函数聚集RDD中的所有元素,这个功能必须是课交换且可并联的 |
|
collect() |
在驱动程序中,以数组的形式返回数据集的所有元素 |
|
count() |
返回RDD的元素个数 |
|
first() |
返回RDD的第一个元素(类似于take(1)) |
|
take(n) |
返回一个由数据集的前n个元素组成的数组 |
|
takeSample(withReplacement,num, [seed]) |
返回一个数组,该数组由从数据集中随机采样的num个元素组成,可以选择是否用随机数替换不足的部分,seed用于指定随机数生成器种子 |
|
takeOrdered(n, [ordering]) |
|
|
saveAsTextFile(path) |
将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本 |
|
saveAsSequenceFile(path) |
将数据集中的元素以Hadoop sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。 |
|
saveAsObjectFile(path) |
|
|
countByKey() |
针对(K,V)类型的RDD,返回一个(K,Int)的map,表示每一个key对应的元素个数。 |
|
foreach(func) |
在数据集的每一个元素上,运行函数func进行更新。 |
|
aggregate |
先对分区进行操作,在总体操作 |
|
reduceByKeyLocally |
|
|
lookup |
|
|
top |
|
|
fold |
|
|
foreachPartition |
|
|
|
3.3 Spark WordCount代码编写
使用maven进行项目构建
(1)使用scala进行编写
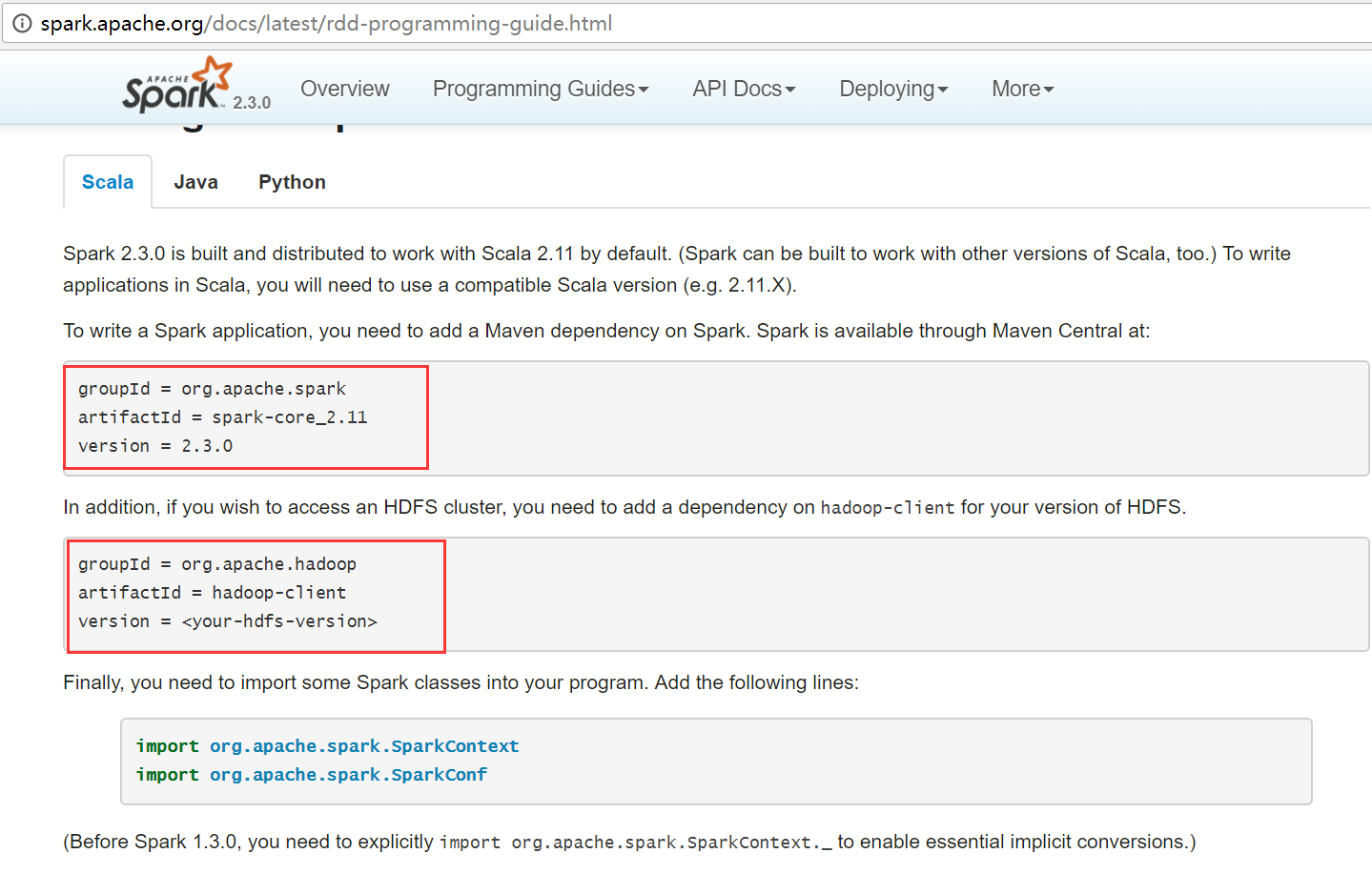
查看官方网站,需要导入2个依赖包
详细代码
SparkWordCountWithScala.scala
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext} object SparkWordCountWithScala {
def main(args: Array[String]): Unit = { val conf = new SparkConf()
/**
* 如果这个参数不设置,默认认为你运行的是集群模式
* 如果设置成local代表运行的是local模式
*/
conf.setMaster("local")
//设置任务名
conf.setAppName("WordCount")
//创建SparkCore的程序入口
val sc = new SparkContext(conf)
//读取文件 生成RDD
val file: RDD[String] = sc.textFile("E:\\hello.txt")
//把每一行数据按照,分割
val word: RDD[String] = file.flatMap(_.split(","))
//让每一个单词都出现一次
val wordOne: RDD[(String, Int)] = word.map((_,1))
//单词计数
val wordCount: RDD[(String, Int)] = wordOne.reduceByKey(_+_)
//按照单词出现的次数 降序排序
val sortRdd: RDD[(String, Int)] = wordCount.sortBy(tuple => tuple._2,false)
//将最终的结果进行保存
sortRdd.saveAsTextFile("E:\\result") sc.stop()
}
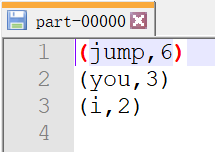
运行结果
3.4 WordCount执行过程图
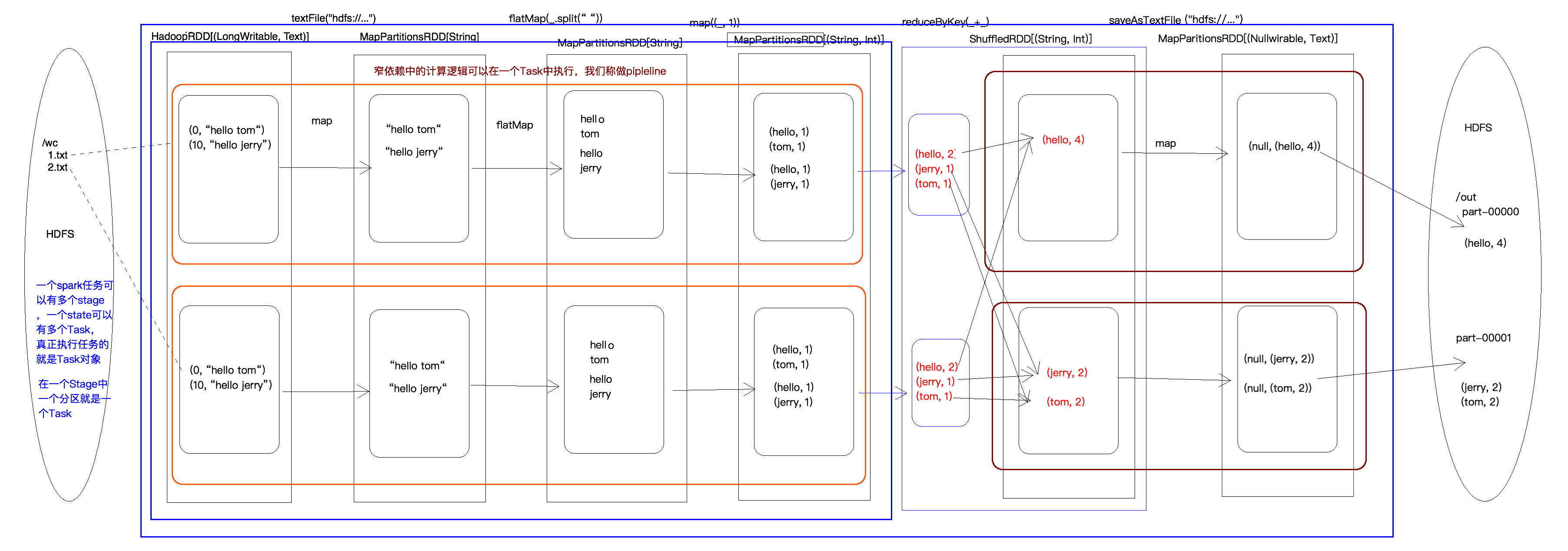
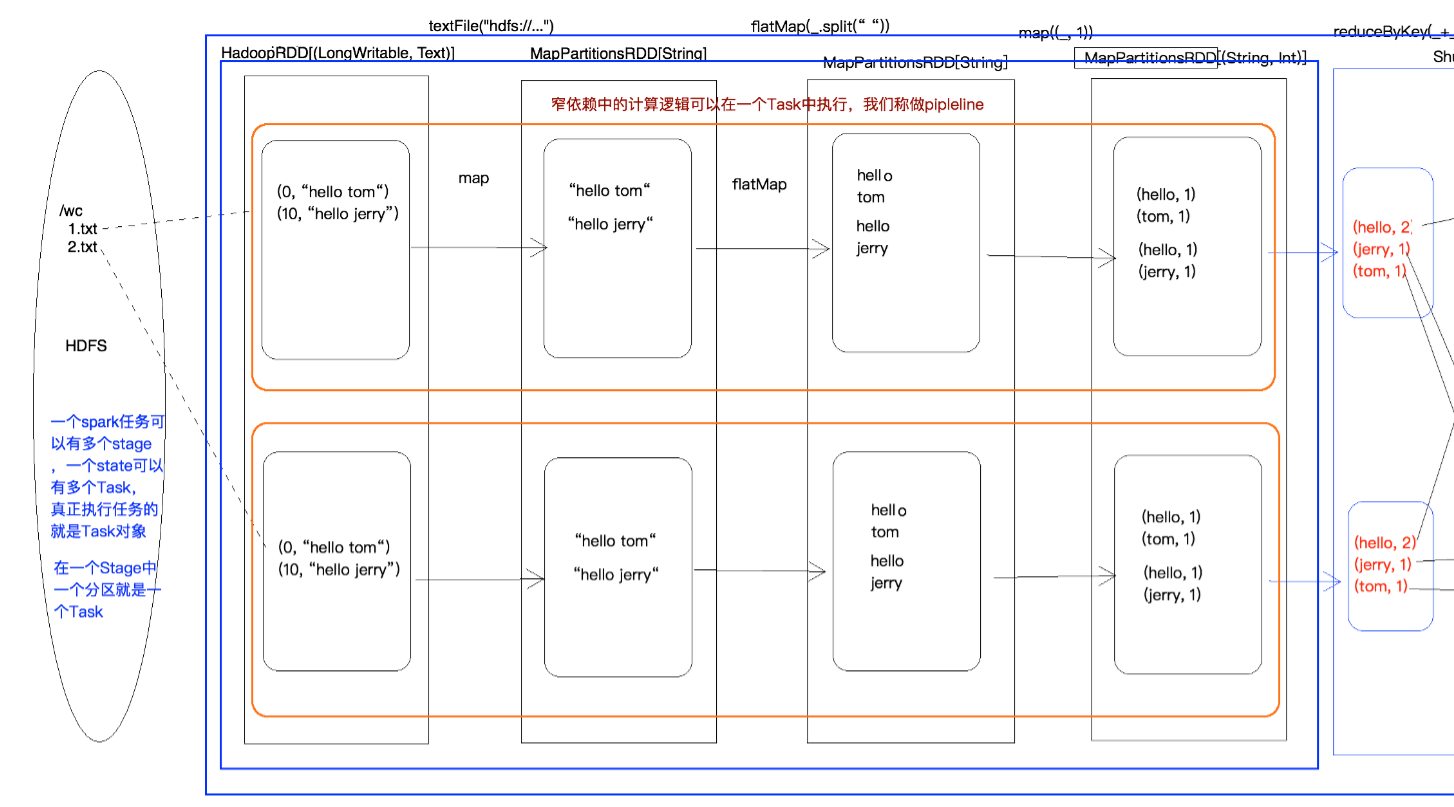
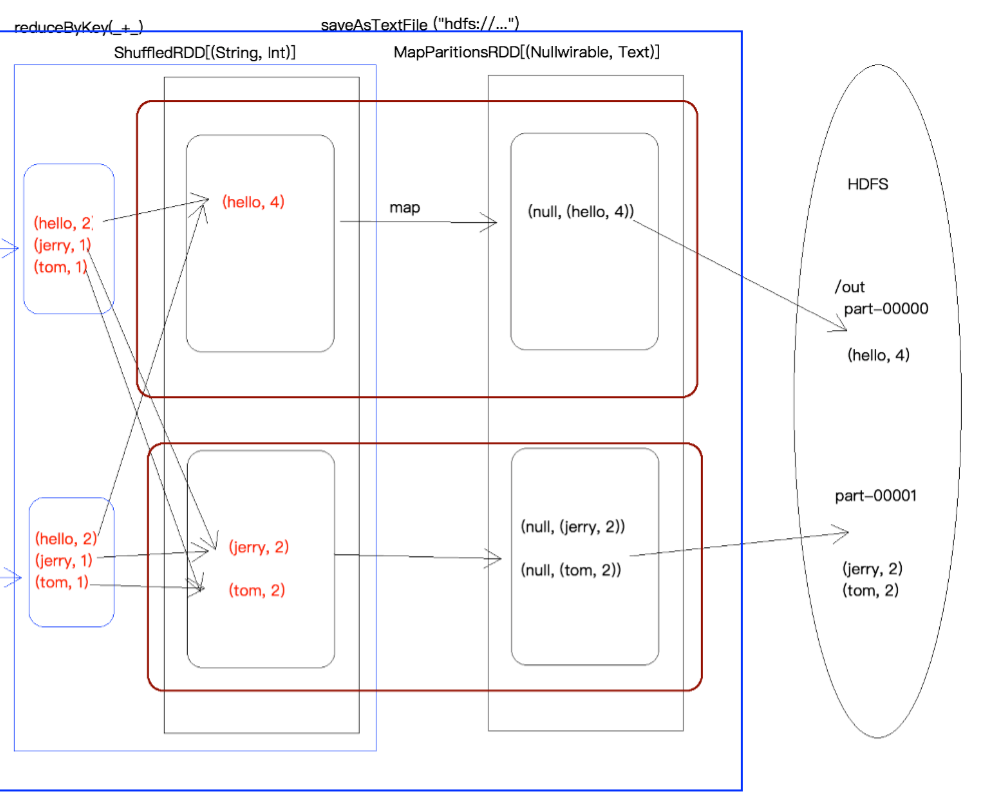
四、RDD的宽依赖和窄依赖
4.1 RDD依赖关系的本质内幕
由于RDD是粗粒度的操作数据集,每个Transformation操作都会生成一个新的RDD,所以RDD之间就会形成类似流水线的前后依赖关系;RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。如图所示显示了RDD之间的依赖关系。
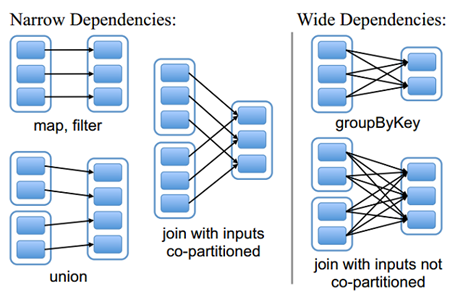
从图中可知:
窄依赖:是指每个父RDD的一个Partition最多被子RDD的一个Partition所使用,例如map、filter、union等操作都会产生窄依赖;(独生子女)
宽依赖:是指一个父RDD的Partition会被多个子RDD的Partition所使用,例如groupByKey、reduceByKey、sortByKey等操作都会产生宽依赖;(超生)
需要特别说明的是对join操作有两种情况:
(1)图中左半部分join:如果两个RDD在进行join操作时,一个RDD的partition仅仅和另一个RDD中已知个数的Partition进行join,那么这种类型的join操作就是窄依赖,例如图1中左半部分的join操作(join with inputs co-partitioned);
(2)图中右半部分join:其它情况的join操作就是宽依赖,例如图1中右半部分的join操作(join with inputs not co-partitioned),由于是需要父RDD的所有partition进行join的转换,这就涉及到了shuffle,因此这种类型的join操作也是宽依赖。
总结:
在这里我们是从父RDD的partition被使用的个数来定义窄依赖和宽依赖,因此可以用一句话概括下:如果父RDD的一个Partition被子RDD的一个Partition所使用就是窄依赖,否则的话就是宽依赖。因为是确定的partition数量的依赖关系,所以RDD之间的依赖关系就是窄依赖;由此我们可以得出一个推论:即窄依赖不仅包含一对一的窄依赖,还包含一对固定个数的窄依赖。
一对固定个数的窄依赖的理解:即子RDD的partition对父RDD依赖的Partition的数量不会随着RDD数据规模的改变而改变;换句话说,无论是有100T的数据量还是1P的数据量,在窄依赖中,子RDD所依赖的父RDD的partition的个数是确定的,而宽依赖是shuffle级别的,数据量越大,那么子RDD所依赖的父RDD的个数就越多,从而子RDD所依赖的父RDD的partition的个数也会变得越来越多。
4.2 依赖关系下的数据流视图
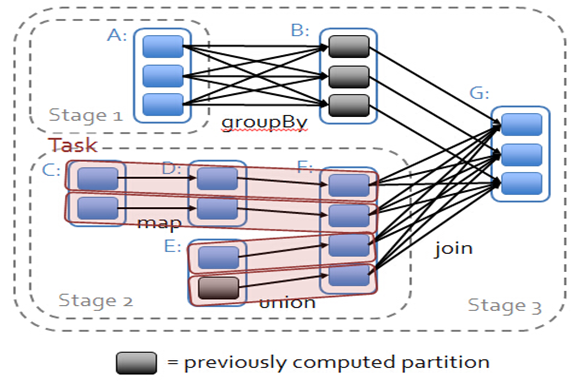
在spark中,会根据RDD之间的依赖关系将DAG图(有向无环图)划分为不同的阶段,对于窄依赖,由于partition依赖关系的确定性,partition的转换处理就可以在同一个线程里完成,窄依赖就被spark划分到同一个stage中,而对于宽依赖,只能等父RDD shuffle处理完成后,下一个stage才能开始接下来的计算。
因此spark划分stage的整体思路是:从后往前推,遇到宽依赖就断开,划分为一个stage;遇到窄依赖就将这个RDD加入该stage中。因此在图2中RDD C,RDD D,RDD E,RDDF被构建在一个stage中,RDD A被构建在一个单独的Stage中,而RDD B和RDD G又被构建在同一个stage中。
在spark中,Task的类型分为2种:ShuffleMapTask和ResultTask;
简单来说,DAG的最后一个阶段会为每个结果的partition生成一个ResultTask,即每个Stage里面的Task的数量是由该Stage中最后一个RDD的Partition的数量所决定的!而其余所有阶段都会生成ShuffleMapTask;之所以称之为ShuffleMapTask是因为它需要将自己的计算结果通过shuffle到下一个stage中;也就是说上图中的stage1和stage2相当于mapreduce中的Mapper,而ResultTask所代表的stage3就相当于mapreduce中的reducer。
在之前动手操作了一个wordcount程序,因此可知,Hadoop中MapReduce操作中的Mapper和Reducer在spark中的基本等量算子是map和reduceByKey;不过区别在于:Hadoop中的MapReduce天生就是排序的;而reduceByKey只是根据Key进行reduce,但spark除了这两个算子还有其他的算子;因此从这个意义上来说,Spark比Hadoop的计算算子更为丰富。
Spark RDD :Spark API--Spark RDD的更多相关文章
- APACHE SPARK 2.0 API IMPROVEMENTS: RDD, DATAFRAME, DATASET AND SQL
What’s New, What’s Changed and How to get Started. Are you ready for Apache Spark 2.0? If you are ju ...
- Spark笔记:复杂RDD的API的理解(上)
本篇接着讲解RDD的API,讲解那些不是很容易理解的API,同时本篇文章还将展示如何将外部的函数引入到RDD的API里使用,最后通过对RDD的API深入学习,我们还讲讲一些和RDD开发相关的scala ...
- Spark菜鸟学习营Day3 RDD编程进阶
Spark菜鸟学习营Day3 RDD编程进阶 RDD代码简化 对于昨天练习的代码,我们可以从几个方面来简化: 使用fluent风格写法,可以减少对于中间变量的定义. 使用lambda表示式来替换对象写 ...
- Spark Streaming揭秘 Day18 空RDD判断及程序中止机制
Spark Streaming揭秘 Day18 空RDD判断及程序中止机制 空RDD的处理 从API我们可以知道在SparkStreaming中,对于RDD的操作一般都是在foreachRDD和Tra ...
- Spark踩坑记——从RDD看集群调度
[TOC] 前言 在Spark的使用中,性能的调优配置过程中,查阅了很多资料,之前自己总结过两篇小博文Spark踩坑记--初试和Spark踩坑记--数据库(Hbase+Mysql),第一篇概况的归纳了 ...
- Spark核心RDD、什么是RDD、RDD的属性、创建RDD、RDD的依赖以及缓存、
1:什么是Spark的RDD??? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行 ...
- 【spark 深入学习 05】RDD编程之旅基础篇-01
---------------- 本节内容 1.RDD的工作流程 2.WordCount解说 · shell版本WordCount · java版本WordCount -------------- ...
- Spark Core (一) 什么是RDD的Transformation和Action以及Dependency(转载)
1. Spark的RDD RDD(Resilient Distributed Datasets),弹性分布式数据集,是对分布式数据集的一种抽象. RDD所具备5个主要特性: 一组分区列表 计算每一个数 ...
- Hive数据分析——Spark是一种基于rdd(弹性数据集)的内存分布式并行处理框架,比于Hadoop将大量的中间结果写入HDFS,Spark避免了中间结果的持久化
转自:http://blog.csdn.net/wh_springer/article/details/51842496 近十年来,随着Hadoop生态系统的不断完善,Hadoop早已成为大数据事实上 ...
- Spark快速大数据分析之RDD基础
Spark 中的RDD 就是一个不可变的分布式对象集合.每个RDD 都被分为多个分区,这些分区运行在集群中的不同节点上.RDD 可以包含Python.Java.Scala中任意类型的对象,甚至可以包含 ...
随机推荐
- 五、Spring中的@Import注解
一.使用@Import注解导入组件 @Import注解的作用是给容器中导入组件,回顾下我们给容器中导入组件的方式,可以通过Spring的xm配置方式,可以通过注解,如@Component等,也可以通过 ...
- 1.2.1LVM逻辑卷镜像实现方法
LVM逻辑卷镜像实现方法 本文演示了在CentOS5系统中实现LVM逻辑卷镜像的方法.LVM的镜像功能,有点儿类似于Raid1,即多块儿磁盘互相同步,确保资料不会丢失. 创建物理卷,卷组的步骤这里就先 ...
- 绘制UML图的工具
目前在用processOn网站进行绘制:https://www.processon.com/ 学习其简单的入门教程: https://www.processon.com/support https:/ ...
- visual studio ------- 更改字体和背景颜色
1.打开vs 点击工具 选择选项 2.想要更换主题的也可以更换主题, 3.更改字体 4.更改为护眼小背景 参数为 85 123 205 ee
- 远程登录Linux系统(使用xshell),远程上传加载文件(使用Xftp)
一.Xshell(远程登录Linux系统) 1.安装xshell 自己百度找安装包 2.连接登录 1.连接前提 需要Linux开启一个sshd的服务,监听22号端口,一般默认是开启的 查看是否开启: ...
- pytest_用例a失败,跳过测试用例b和c并标记失败xfail
前言 当用例a失败的时候,如果用例b和用例c都是依赖于第一个用例的结果,那可以直接跳过用例b和c的测试,直接给他标记失败xfail用到的场景,登录是第一个用例,登录之后的操作b是第二个用例,登录之后操 ...
- C# vb .net实现负片特效滤镜
在.net中,如何简单快捷地实现Photoshop滤镜组中的负片特效呢?答案是调用SharpImage!专业图像特效滤镜和合成类库.下面开始演示关键代码,您也可以在文末下载全部源码: 设置授权 第一步 ...
- Excel 2010同时打开2个或多个独立窗口
亲测有效 参考下面的网址 https://jingyan.baidu.com/article/86fae346acca7d3c49121ad4.html 1. 在win+r 输入框里面输入“rege ...
- 如何使用Git 优雅的版本回退呢?
在版本迭代开发过程中,相信很多人都会有过错误提交的时候(至少良许有过几次这样的体验).这种情况下,菜鸟程序员可能就会虎驱一震,紧张得不知所措.而资深程序员就会微微一笑,摸一摸锃亮的脑门,然后默默的进行 ...
- Visual Studio 2012 VC下 OpenGL 配置与使用
Windows环境下的GLUT下载地址:(大小约为150k) Download 1 32位Windows环境下安装GLUT的步骤1.将glut.h复制到C:\Program Files (x86 ...