pytorch torch.nn 实现上采样——nn.Upsample
Vision layers
1)Upsample
CLASS torch.nn.Upsample(size=None, scale_factor=None, mode='nearest', align_corners=None)
上采样一个给定的多通道的 1D (temporal,如向量数据), 2D (spatial,如jpg、png等图像数据) or 3D (volumetric,如点云数据)数据
假设输入数据的格式为minibatch x channels x [optional depth] x [optional height] x width。因此对于一个空间spatial输入,我们期待着4D张量的输入,即minibatch x channels x height x width。而对于体积volumetric输入,我们则期待着5D张量的输入,即minibatch x channels x depth x height x width
对于上采样有效的算法分别有对 3D, 4D和 5D 张量输入起作用的 最近邻、线性,、双线性, 双三次(bicubic)和三线性(trilinear)插值算法
你可以给定scale_factor来指定输出为输入的scale_factor倍或直接使用参数size指定目标输出的大小(但是不能同时制定两个)
参数:
size (int or Tuple[int] or Tuple[int, int] or Tuple[int, int, int], optional) – 根据不同的输入类型制定的输出大小
scale_factor (float or Tuple[float] or Tuple[float, float] or Tuple[float, float, float], optional) – 指定输出为输入的多少倍数。如果输入为tuple,其也要制定为tuple类型
mode (str, optional) – 可使用的上采样算法,有
'nearest','linear','bilinear','bicubic'and'trilinear'.默认使用'nearest'align_corners (bool, optional) – 如果为True,输入的角像素将与输出张量对齐,因此将保存下来这些像素的值。仅当使用的算法为
'linear','bilinear'or'trilinear'时可以使用。默认设置为False
输入输出形状:
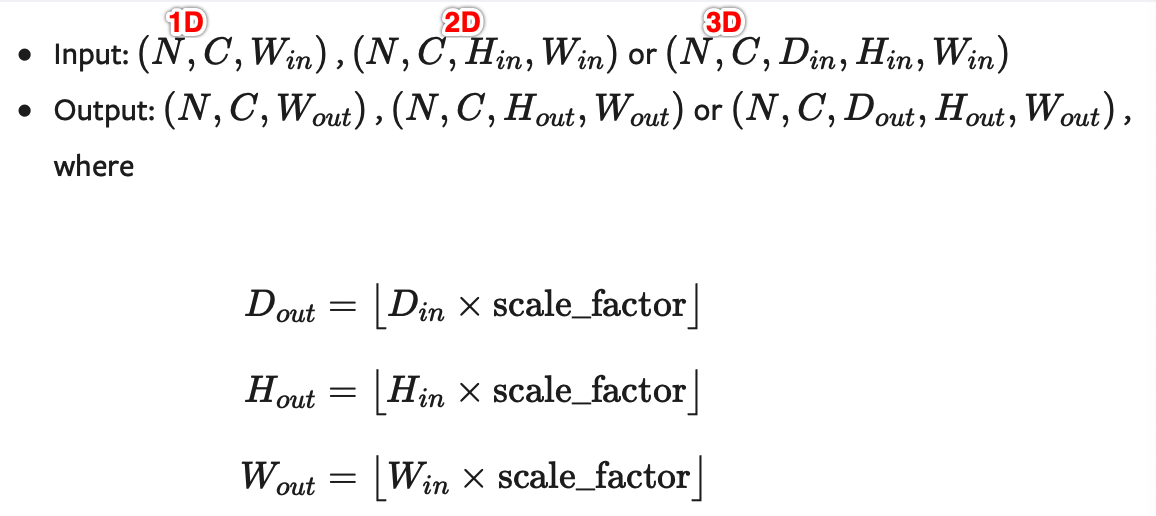
注意:
当align_corners = True时,线性插值模式(线性、双线性、双三线性和三线性)不按比例对齐输出和输入像素,因此输出值可以依赖于输入的大小。这是0.3.1版本之前这些模式的默认行为。从那时起,默认行为是align_corners = False,如下图:
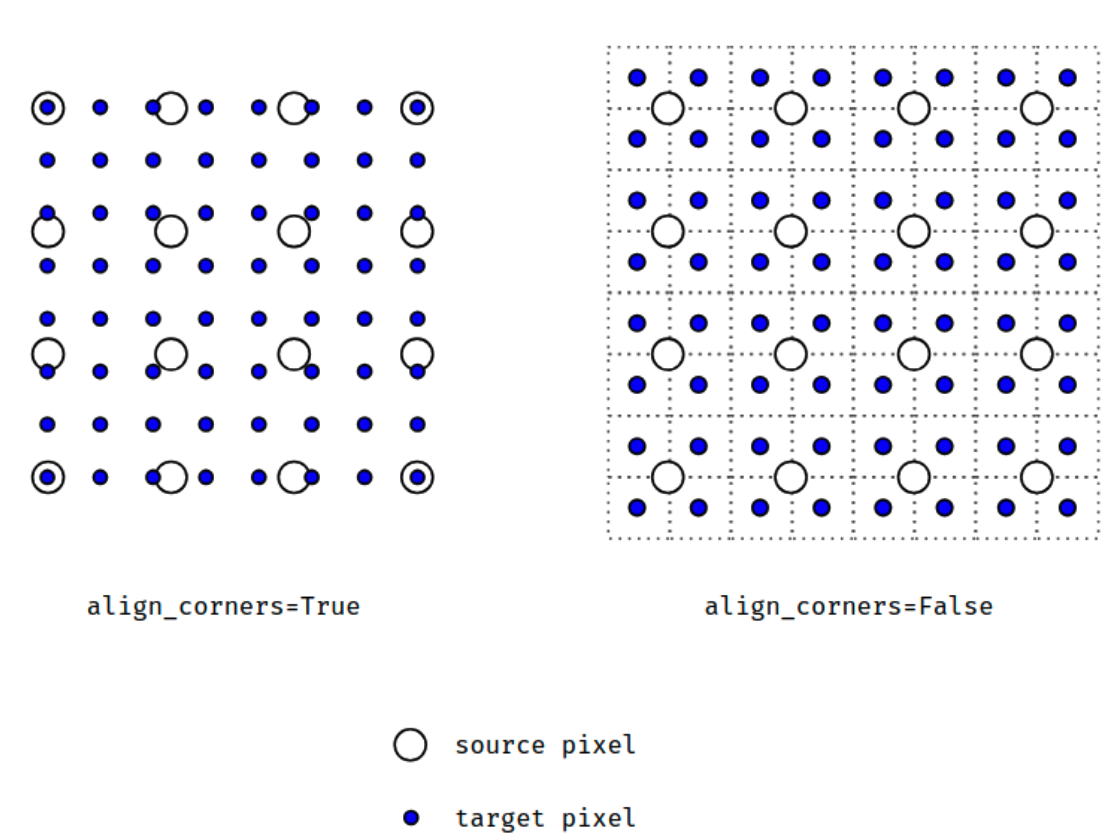
上面的图是source pixel为4*4上采样为target pixel为8*8的两种情况,这就是对齐和不对齐的差别,会对齐左上角元素,即设置为align_corners = True时输入的左上角元素是一定等于输出的左上角元素。但是有时align_corners = False时左上角元素也会相等,官网上给的例子就不太能说明两者的不同(也没有试出不同的例子,大家理解这个概念就行了)
如果您想下采样/常规调整大小,您应该使用interpolate()方法,这里的上采样方法已经不推荐使用了。
举例:
import torch
from torch import nn
input = torch.arange(, , dtype=torch.float32).view(, , , )
input
返回:
tensor([[[[., .],
[., .]]]])
m = nn.Upsample(scale_factor=, mode='nearest')
m(input)
返回:
tensor([[[[., ., ., .],
[., ., ., .],
[., ., ., .],
[., ., ., .]]]])
m = nn.Upsample(scale_factor=, mode='bilinear',align_corners=False)
m(input)
返回:
tensor([[[[1.0000, 1.2500, 1.7500, 2.0000],
[1.5000, 1.7500, 2.2500, 2.5000],
[2.5000, 2.7500, 3.2500, 3.5000],
[3.0000, 3.2500, 3.7500, 4.0000]]]])
m = nn.Upsample(scale_factor=, mode='bilinear',align_corners=True)
m(input)
返回:
tensor([[[[1.0000, 1.3333, 1.6667, 2.0000],
[1.6667, 2.0000, 2.3333, 2.6667],
[2.3333, 2.6667, 3.0000, 3.3333],
[3.0000, 3.3333, 3.6667, 4.0000]]]])
m = nn.Upsample(size=(,), mode='bilinear',align_corners=True)
m(input)
返回:
tensor([[[[1.0000, 1.2500, 1.5000, 1.7500, 2.0000],
[2.0000, 2.2500, 2.5000, 2.7500, 3.0000],
[3.0000, 3.2500, 3.5000, 3.7500, 4.0000]]]])
如果你使用的数据都是JPG等图像数据,那么你就能够直接使用下面的用于2D数据的方法:
2)UpsamplingNearest2d
CLASS torch.nn.UpsamplingNearest2d(size=None, scale_factor=None)
专门用于2D数据的线性插值算法,参数等跟上面的差不多,省略
形状:

举例:
m = nn.UpsamplingNearest2d(scale_factor=)
m(input)
input即上面例子的input,返回:
tensor([[[[., ., ., .],
[., ., ., .],
[., ., ., .],
[., ., ., .]]]])
m = nn.UpsamplingNearest2d(size=(,))
m(input)
返回:
tensor([[[[., ., ., ., .],
[., ., ., ., .],
[., ., ., ., .]]]])
3)UpsamplingBilinear2d
CLASS torch.nn.UpsamplingBilinear2d(size=None, scale_factor=None)
专门用于2D数据的双线性插值算法,参数等跟上面的差不多,省略
形状:
注意:最好还是使用nn.functional.interpolate(..., mode='bilinear', align_corners=True)
举例:
m = nn.UpsamplingBilinear2d(scale_factor=)
m(input)
返回:
tensor([[[[1.0000, 1.3333, 1.6667, 2.0000],
[1.6667, 2.0000, 2.3333, 2.6667],
[2.3333, 2.6667, 3.0000, 3.3333],
[3.0000, 3.3333, 3.6667, 4.0000]]]])
m = nn.UpsamplingBilinear2d(size=(,))
m(input)
返回:
tensor([[[[1.0000, 1.2500, 1.5000, 1.7500, 2.0000],
[2.0000, 2.2500, 2.5000, 2.7500, 3.0000],
[3.0000, 3.2500, 3.5000, 3.7500, 4.0000]]]])
更复杂的例子可见:pytorch 不使用转置卷积来实现上采样
pytorch torch.nn 实现上采样——nn.Upsample的更多相关文章
- pytorch 不使用转置卷积来实现上采样
上采样(upsampling)一般包括2种方式: Resize,如双线性插值直接缩放,类似于图像缩放,概念可见最邻近插值算法和双线性插值算法——图像缩放 Deconvolution,也叫Transpo ...
- 上采样和PixelShuffle(转)
有些地方还没看懂, mark一下 文章来源: https://blog.csdn.net/g11d111/article/details/82855946 去年曾经使用过FCN(全卷积神经网络)及其派 ...
- pytorch torch.nn.functional实现插值和上采样
interpolate torch.nn.functional.interpolate(input, size=None, scale_factor=None, mode='nearest', ali ...
- PyTorch : torch.nn.xxx 和 torch.nn.functional.xxx
PyTorch : torch.nn.xxx 和 torch.nn.functional.xxx 在写 PyTorch 代码时,我们会发现一些功能重复的操作,比如卷积.激活.池化等操作.这些操作分别可 ...
- Pytorch——torch.nn.Sequential()详解
参考:官方文档 源码 官方文档 nn.Sequential A sequential container. Modules will be added to it in the order th ...
- 『PyTorch』第十三弹_torch.nn.init参数初始化
初始化参数的方法 nn.Module模块对于参数进行了内置的较为合理的初始化方式,当我们使用nn.Parameter时,初始化就很重要,而且我们也可以指定代替内置初始化的方式对nn.Module模块进 ...
- 上采样 及 Sub-pixel Convolution (子像素卷积)
参考:https://blog.csdn.net/leviopku/article/details/84975282 参考:https://blog.csdn.net/g11d111/article/ ...
- [源码解析] PyTorch 分布式(2) ----- DataParallel(上)
[源码解析] PyTorch 分布式(2) ----- DataParallel(上) 目录 [源码解析] PyTorch 分布式(2) ----- DataParallel(上) 0x00 摘要 0 ...
- 图像的下采样Subsampling 与 上采样 Upsampling
I.目的 缩小图像(或称为下采样(subsampled)或降采样(downsampled))的主要目的: 1.使得图像符合显示区域的大小: 2.生成对应图像的缩略图. 放大图像(或称为上采样(ups ...
随机推荐
- python get/post接口使用
背景: 使用python调用get post接口,入参.出参都需要转换,在使用时经常会忘记其中的一步,本文用来记录,后面再使用时直接参考使用 代码如下 post: headers = {'Conten ...
- 结构型模式(三) 装饰模式(Decorator)
一.动机(Motivate) 在房子装修的过程中,各种功能可以相互组合,来增加房子的功用.类似的,如果我们在软件系统中,要给某个类型或者对象增加功能,如果使用"继承"的方案来写代码 ...
- used to do 与be used to doing /n.
1.used to do:表示过去的习惯性动作,过去如此,现在不再这样了.常译作“过去常常”.(过去时+动词不定式) He used to play basketball when he was yo ...
- Centos7 安装谷歌浏览器
配置下载yum源 cd /etc/yum.repos.d vim google-chrome.repo [google-chrome] name=google-chrome baseurl=http: ...
- jsp里导入java包的问题
写jsp导包的时候出了两处错误(什么?特么两处,总共就一句话啊...): 新建jsp文件会自动生成一句: <%@ page language="java" import=&q ...
- Python + Apache Kylin 让数据分析更加简单!
现如今,大数据.数据科学和机器学习不仅是技术圈的热门话题,也是当今社会的重要组成.数据就在每个人身边,同时每天正以惊人的速度快速增长,据福布斯报道:到 2025 年,每年将产生大约 175 个 Zet ...
- 自用java购物
@RequestMapping("listgoodscart") public ResultEntity listGoodsCart(@RequestParam(name = &q ...
- 了解区块链&比特币
https://www.bilibili.com/video/av45247943 假如有ABCD四个比特币交易者,其中A交易给B者10个比特币(BTC),而这条信息要广播给其他所有的交易者知道. 假 ...
- tar归档压缩命令和zip归档 和7zip压缩命令;库文件归档ar命令
第一.tar 归档 tar -c 创建归档文件包 tar -x 释放归档文件包 tar -t 查看归档文件包 tar -v 显示归档包操作过程信息 tar -f 指定归档文件名 案例1:归档 /hom ...
- 关于size
关于size它确实可以帮人算内存 但是: 在不会用到整个数组(尤其是在状压的时候) 不要用它,它只能算你申请了多少内存,但算不了会用多少!!! and 有人能告诉我,交题前不好好看看交的哪份代码是什么 ...