【数据结构】7.java源码关于LinkedList
关于LinkedList的源码关注点
1.从底层数据结构,扩容策略
2.LinkedList的增删改查
3.特殊处理重点关注
4.遍历的速度,随机访问和iterator访问效率对比
1.从底层数据结构,扩容策略
构造函数不做任何操作,只要再add的时候进行数据初始化操作,以操作推动逻辑,而且linkedlist是一个双向链表,所以可以向前向后双向遍历
由于构造函数并没有任何操作,其实这里我们可以先看新增操作,并且因为用的是链表所以无法随机访问,这里随机读取就会比较慢

底层结构就是size,首节点,尾节点,还有就是一个List都有的共性就是modCount,这值用来记录这个list被修改了多少次
2.LinkedList的增删改查
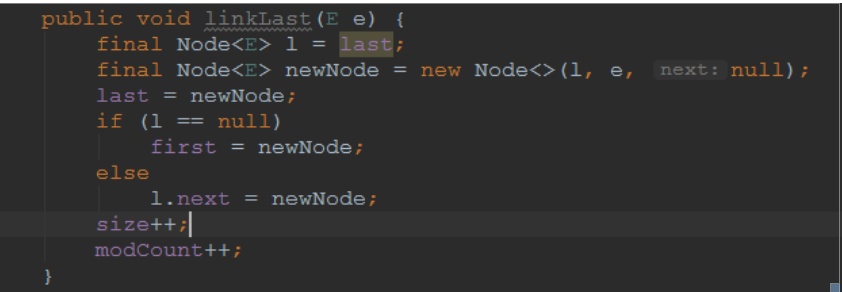
2.1 add操作,linklast
Add操作的实质就是进行linklast操作
linklast的操作就是再最后吧节点添加到尾部,并修正size大小
public boolean add(E ele) {
linkLast(ele);
return true;
}
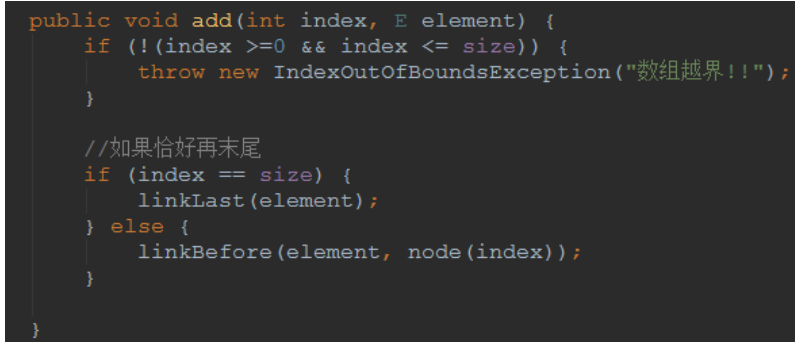
我们看看如果是在指定的位置插入元素的操作
首先要确认index再指定范围内
这里有个小优化,如果是在末尾进行添加的话,我们直接调用linklast就可以了
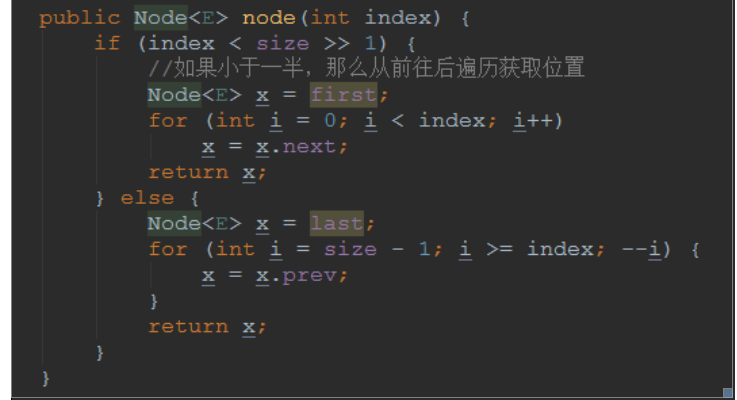
如果不是最后一个,那么首先要获取指定位置的node节点,我们遍历指定位置的时候
可以确定index的位置如果过半了,那么就从后往前,如果没有过半,那么就从前往后
1.直接再index创建一个节点,然后前后合并一下
2.吧原来的index位置的节点断开,吧这个节点的pre指向新节点
3.判断前置节点是否到头了,为空
4.把前置节点的next指向新节点
先看看node定位操作
然后我们看看linkbefore,前置插入
public void linkBefore(E e, Node<E> succ) {
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
那么我们需要插入到指定的位置的方法就可以很简单的实现了
Linkbefore(e, node(index))即可
2.2 删除
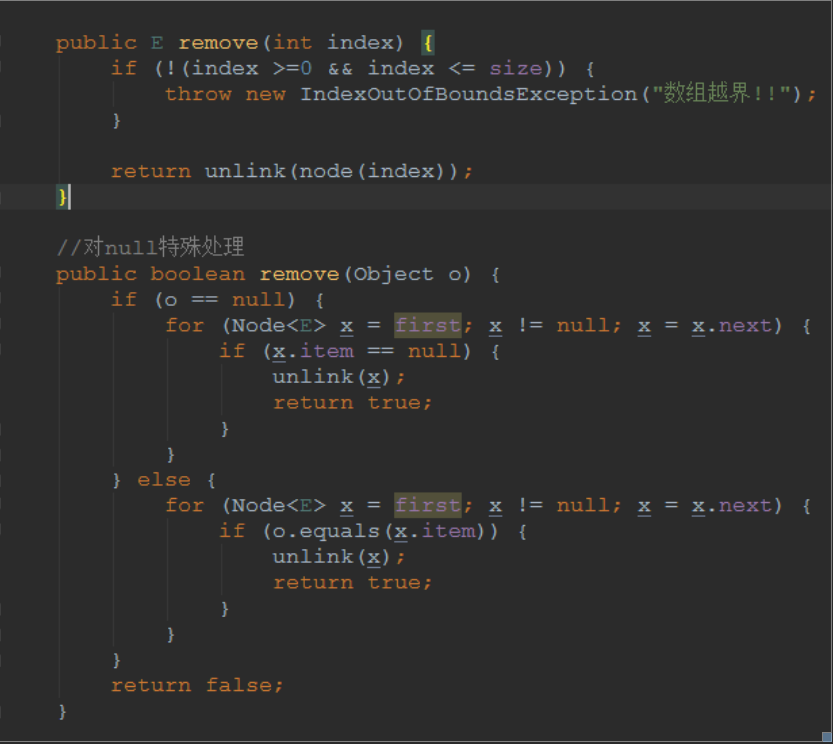
查看源码,比较remove(),remove(object),remove(index)等等操作,归根到底还是一个unlink操作
我们需要对指定的节点进行unlink操作
就2步操作
1.当前节点的前一个节点指向当前节点的下一个节点,说白了node.pre.next = node.next;
2.当前节点的下一个节点的前置节点指向当前节点的上一个节点:node.next.pre = node.pre;
其他细节部分就是首尾节点的处理
public E unlink(Node<E> node) {
// assert x != null;
//这里需要操作的就是三个节点,前置节点,当前节点,后置节点
final E element = node.item;
final Node<E> prev = node.prev;
final Node<E> next = node.next;
//当前节点的前一个节点指向当前节点的下一个节点,说白了node.pre.next = node.next;
if (prev == null) {
//避免首节点操作
first = next;
} else {
prev.next = next;
node.prev = null; //断开原始连接
}
//当前节点的下一个节点的前置节点指向当前节点的上一个节点:node.next.pre = node.pre;
if (next == null) {
last = prev;
} else {
next.prev = prev;
node.next = null;
}
//清除当前节点
node.item = null;
size--;
modCount++;
return element;
}
其余操作基本就是调用unlink方法进行操作
修改set和获取get就不多说了,就注意一点就是set操作的时候,会返回旧值,并且这两个操作不会修改modCount值,也就是不会产生链表变动
3.特殊处理重点关注,iterator,序列化
对于iterator这个就不多说了,其实还是调用上面的那些方法,遍历也就是next和pre和循环遍历没差别
但是注意一点就是通过迭代器进行remove和add是可以的,但是注意一点,如果使用迭代器进行remove或者add操作的通过,还使用了一般的remove和add那么就会使迭代器失效
序列化这里我们先只做一个了解,后续开章节专门学习一下java的序列化:
进行序列化、反序列化时,虚拟机会首先试图调用对象里的writeObject和readObject方法,进行用户自定义的序列化和反序列化。如果没有这样的方法,那么默认调用的是ObjectOutputStream的defaultWriteObject以及ObjectInputStream的defaultReadObject方法。换言之,利用自定义的writeObject方法和readObject方法,用户可以自己控制序列化和反序列化的过程。
---------------------
版权声明:本文为CSDN博主「zthgreat」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u014634338/article/details/78165127
4.遍历的速度,随机访问和iterator访问效率对比
这个问题其实也可以舍弃掉了,这里遍历的实质还是使用链表的遍历方式进行遍历
5.是否支持多线程
LinkedList 是线程不安全的,允许元素为null的双向链表。
参考:https://blog.csdn.net/u014634338/article/details/78165127
【数据结构】7.java源码关于LinkedList的更多相关文章
- 浅析Java源码之LinkedList
可以骂人吗???辛辛苦苦写了2个多小时搞到凌晨2点,点击保存草稿退回到了登录页面???登录成功草稿没了???喵喵喵???智障!!气! 很厉害,隔了30分钟,我的登录又失效了,草稿再次回滚,不客气了,* ...
- Java源码-集合-LinkedList
基于JDK1.8.0_191 介绍 LinkedList是以节点来保存数据的,不像数组在创建的时候需要申请一段连续的空间,LinkedList里的数据是可以存放在不同的空间当中,然后以内存地址作为 ...
- java源码阅读LinkedList
1类签名与注释 public class LinkedList<E> extends AbstractSequentialList<E> implements List< ...
- 如何阅读Java源码 阅读java的真实体会
刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动. 源码阅读,我觉得最核心有三点:技术基础+强烈的求知欲+耐心. 说到技术基础,我打个比 ...
- 如何阅读Java源码
刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动.源码阅读,我觉得最核心有三点:技术基础+强烈的求知欲+耐心. 说到技术基础,我打个比方吧, ...
- Java 源码学习线路————_先JDK工具包集合_再core包,也就是String、StringBuffer等_Java IO类库
http://www.iteye.com/topic/1113732 原则网址 Java源码初接触 如果你进行过一年左右的开发,喜欢用eclipse的debug功能.好了,你现在就有阅读源码的技术基础 ...
- [收藏] Java源码阅读的真实体会
收藏自http://www.iteye.com/topic/1113732 刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动. 源码阅读,我 ...
- 如何阅读Java源码?
阅读本文大概需要 3.6 分钟. 阅读Java源码的前提条件: 1.技术基础 在阅读源码之前,我们要有一定程度的技术基础的支持. 假如你从来都没有学过Java,也没有其它编程语言的基础,上来就啃< ...
- Java源码阅读的真实体会(一种学习思路)
Java源码阅读的真实体会(一种学习思路) 刚才在论坛不经意间,看到有关源码阅读的帖子.回想自己前几年,阅读源码那种兴奋和成就感(1),不禁又有一种激动. 源码阅读,我觉得最核心有三点:技术基础+强烈 ...
随机推荐
- A`>G?~C009
A`>G?~C009 这场怎么才5题...看完猫的提交记录以为猫猫没写这场F A Multiple Array 直接做 B Tournament 直接树d C Division into Two ...
- cogs 999. [東方S2]雾雨魔理沙
二次联通门 : cogs 999. [東方S2]雾雨魔理沙 摸你傻赛高!! /* cogs 999. [東方S2]雾雨魔理沙 原来以为是一道计算几何的题 可是细细一想发现.. 这就是一道dp 由于给定 ...
- 原创:Kmeans算法实战+改进(java实现)
kmeans算法的流程: EM思想很伟大,在处理含有隐式变量的机器学习算法中很有用.聚类算法包括kmeans,高斯混合聚类,快速迭代聚类等等,都离不开EM思想.在了解kmeans算法之前,有必要详 ...
- navicat提示无法连接解决办法
1.错误如下图: 2.这个是由于mysql中user表中未设置允许该ip访问导致,解决办法: 1)查下user表:select user,host from user; 这张表就是mysql.user ...
- Hadoop FairScheduler
目标 本文档描述FairScheduler,一个允许YARN应用程序公平共享集群资源的调度插件. 概述 公平调度是一个分配资源给所有application的方法,平均来看,是随着时间的进展平等分享资源 ...
- k8s相关
卸载kubernetes-dashboard kubectl get secret,sa,role,rolebinding,services,deployments --namespace=kube- ...
- php error_reporting()关闭报错
错误报告级别:指定了在什么情况下,脚本代码中的错误(这里的错误是广义的错误,包括E_NOTICE注意.E_WARNING警告.E_ERROR致命错误等)会以错误报告的形式输出. 一.常用设置说明 er ...
- docker使用dnnmmp安装gocron
使用dnnmmp安装mysql和phpmyadmin默认使用dnnmmp_default网络,因为在安装其他依赖mysql的应用时,需指定网络 ,同时需指定mysql名称 原命令: docker ru ...
- SNF快速开发平台2019-权限管理模型实践-权限都在这里
其它权限实践系列文章: 1.角色.权限.账户的概念理解-非常全的理论讲解权限控制 https://www.cnblogs.com/spring_wang/p/10954370.html 2.权限管理模 ...
- win10 搜索栏输入后长期没反应
博客转载自:https://blog.csdn.net/qq_40875146/article/details/81742533 Get-AppXPackage -Name Microsoft.Win ...