pyspider 数据存入Mysql--Python3
一、不写入Mysql
以爬取哪儿网为例。
以下为脚本:
from pyspider.libs.base_handler import * class Handler(BaseHandler):
crawl_config = {
} @every(minutes=24 * 60)
def on_start(self):
self.crawl('https://travel.qunar.com/travelbook/list.htm', callback=self.index_page, validate_cert=False) @config(age=100 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('li > .tit > a').items():
self.crawl(each.attr.href, callback=self.detail_page, validate_cert=False, fetch_type='js')
next = response.doc('.next').attr.href
self.crawl(next, callback=self.index_page) @config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('#booktitle').text(),
"date": response.doc('.when .data').text(),
"day": response.doc('.howlong .data').text(),
"who": response.doc('.who .data').text(),
"text": response.doc('#b_panel_schedule').text(),
"image": response.doc('.cover_img').text(),
}
这个脚本里只是单纯的将结果打印在pyspider 的web ui中,并没有存到其它地方。
二、存入Mysql中
插入数据库的话,需要我们在调用它之前定义一个save_in_mysql函数。 并且需要将连接数据库等初始化放在__init__函数中。
注: pymysql.connect('localhost', '账号', '密码', '数据库', charset='utf8')
# 连接数据库
def __init__(self):
self.db = pymysql.connect('localhost', 'root', 'root', 'qunar', charset='utf8') def save_in_mysql(self, url, title, date, day, who, text, image):
try:
cursor = self.db.cursor()
sql = 'INSERT INTO qunar(url, title, date, day, who, text, image) \
VALUES (%s, %s , %s, %s, %s, %s, %s)' # 插入数据库的SQL语句
print(sql)
cursor.execute(sql, (url, title, date, day, who, text, image))
print(cursor.lastrowid)
self.db.commit()
except Exception as e:
print(e)
self.db.rollback()
然后在detail_page中调用save_in_mysql函数:
@config(priority=2)
def detail_page(self, response):
url = response.url
title = response.doc('title').text()
date = response.doc('.when .data').text()
day = response.doc('.howlong .data').text()
who = response.doc('.who .data').text()
text = response.doc('#b_panel_schedule').text()[0:100].replace('\"', '\'', 10)
image = response.doc('.cover_img').attr.src # 插入数据库
self.save_in_mysql(url, title, date, day, who, text, image)
return {
"url": response.url,
"title": response.doc('title').text(),
"date": response.doc('.when .data').text(),
"day": response.doc('.howlong .data').text(),
"who": response.doc('.who .data').text(),
"text": response.doc('#b_panel_schedule').text(),
"image": response.doc('.cover_img').attr.src
}
三、完整代码、数据库建设及运行结果 (代码可直接跑)
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2019-07-02 21:37:08
# Project: qunar from pyspider.libs.base_handler import *
import pymysql class Handler(BaseHandler):
crawl_config = {
} # 连接数据库
def __init__(self):
self.db = pymysql.connect('localhost', 'root', 'root', 'qunar', charset='utf8') def save_in_mysql(self, url, title, date, day, who, text, image):
try:
cursor = self.db.cursor()
sql = 'INSERT INTO qunar(url, title, date, day, who, text, image) \
VALUES (%s, %s , %s, %s, %s, %s, %s)' # 插入数据库的SQL语句
print(sql)
cursor.execute(sql, (url, title, date, day, who, text, image))
print(cursor.lastrowid)
self.db.commit()
except Exception as e:
print(e)
self.db.rollback() @every(minutes=24 * 60)
def on_start(self):
self.crawl('http://travel.qunar.com/travelbook/list.htm', callback=self.index_page) @config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('li > .tit > a').items():
self.crawl(each.attr.href, callback=self.detail_page, fetch_type='js')
next_url = response.doc('.next').attr.href
self.crawl(next_url, callback=self.index_page) @config(priority=2)
def detail_page(self, response):
url = response.url
title = response.doc('title').text()
date = response.doc('.when .data').text()
day = response.doc('.howlong .data').text()
who = response.doc('.who .data').text()
text = response.doc('#b_panel_schedule').text()[0:100].replace('\"', '\'', 10)
image = response.doc('.cover_img').attr.src # 存入数据库
self.save_in_mysql(url, title, date, day, who, text, image)
return {
"url": response.url,
"title": response.doc('title').text(),
"date": response.doc('.when .data').text(),
"day": response.doc('.howlong .data').text(),
"who": response.doc('.who .data').text(),
"text": response.doc('#b_panel_schedule').text(),
"image": response.doc('.cover_img').attr.src
}
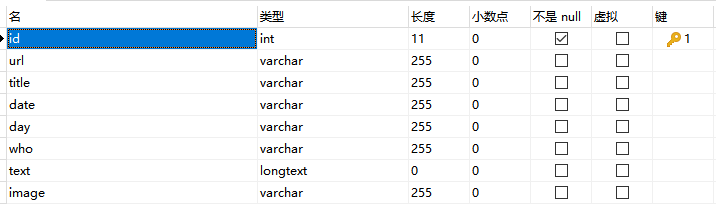
数据库建设:
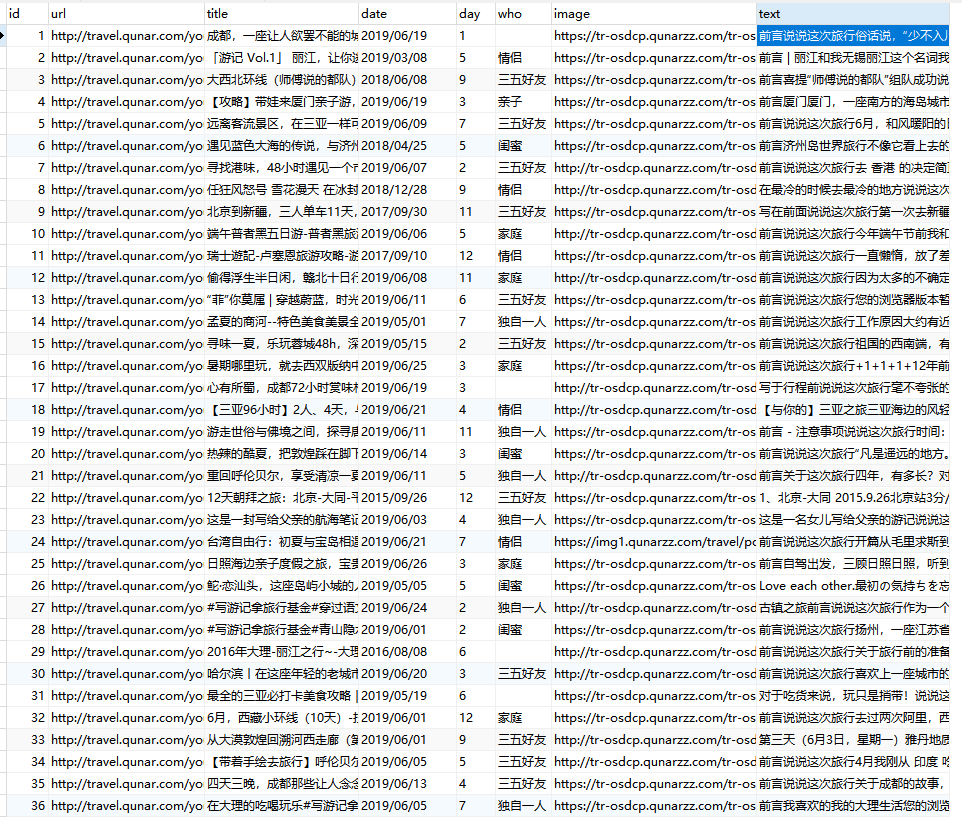
结果:
pyspider 数据存入Mysql--Python3的更多相关文章
- php+phpspreadsheet读取Excel数据存入mysql
先生成Excel模板,然后导入Excel数据到mysql,每条数据对应图片上传到阿里云 <?php /** * Created by PhpStorm. * User: Administrato ...
- Scrapy爬虫实例教程(二)---数据存入MySQL
书接上回 实例教程(一) 本文将详细描述使用scrapy爬去左岸读书所有文章并存入本地MySql数据库中,文中所有操作都是建立在scrapy已经配置完毕,并且系统中已经安装了Mysql数据库(有权限操 ...
- 关于mapreducer 读取hbase数据 存入mysql的实现过程
mapreducer编程模型是一种八股文的代码逻辑,就以用户行为分析求流存率的作为例子 1.map端来说:必须继承hadoop规定好的mapper类:在读取hbase数据时,已经有现成的接口 Tabl ...
- nodejs爬虫数据存入mysql
node爬虫主要用的是三个插件 request cheerio mysql 废话不多说直接上代码 const request=require("request") const ch ...
- web项目数据存入mysql数据库中文乱码问题
刚开始怀疑是项目中编码设置问题,发现在web.xml中已经有过设置:后来dubug显示数据在传输的过程中一切正常,怀疑是数据库编码问题,然后查看mysql编码: show variables like ...
- 【python 2.7】python读取json数据存入MySQL
同上一篇,只是适配 CentOS+ python 2.7 #python 2.7 # -*- coding:utf-8 -*- __author__ = 'BH8ANK' import json im ...
- 【python 3.6】python读取json数据存入MySQL(二)
在网上找到一个包含全国各省市经纬度的json文件,也可以通过上次的办法,解析json关键字,构造SQL语句,插入数据库. JSON文件格式如下: [ { "name": " ...
- 【python 3.6】python读取json数据存入MySQL(一)
整体思路: 1,读取json文件 2,将数据格式化为dict,取出key,创建数据库表头 3,取出dict的value,组装成sql语句,循环执行 4,执行SQL语句 #python 3.6 # -* ...
- 将数据存入mysql中
import pymysql import warnings # 忽略警告 warnings.filterwarnings("ignore") # 连接数据库 db = pymys ...
随机推荐
- Vue项目预渲染机制
我们知道SPA有很多优点,不过一个缺点就是对(不是Google的)愚蠢的搜索引擎的SEO不友好,为了照顾这些引擎,目前主要有两个方案:服务端渲染(Server Side Rendering).预渲染( ...
- web前端开发初级
Web 页面制作基础 Web 的相关概念 WWWWebsiteURLWeb StandardWeb BrowserWeb Server HTML 基础 标记语言从 HTML 到 XHTMLHTML 的 ...
- Windows 10下Xilinx ISE需要注意的事项。
一是安装.可以在Windows 10下安装Xilinx ISE 14.7. 详见:https://www.eevblog.com/forum/xilinx/guide-getting-xilinx-i ...
- nginx 访问控制之deny allow
Nginx的deny和allow指令是由ngx_http_access_module模块提供,Nginx安装默认内置了该模块. 除非在安装时有指定 --without-http_access_modu ...
- python 操作es
Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene™ 基础之上. Lucene 可能是目前存在的,不论开源还是私有的,拥有最先进,高性能和全功能搜索 ...
- pyqt(day1)
参考代码地址:https://github.com/cxinping/Pyqt5 pyqt在线帮助文档:https://www.riverbankcomputing.com/static/Docs/P ...
- Dubbo自定义Filter统一处理异常
Dubbo版本:2.7 使用自定义Filter注意事项 1.自定义名称不能和默认Filter相同,否则可能不生效 2.只用定义Filter类和META-INF下的文本文件,不用添加配置,@Activa ...
- XML External Entity Injection(XXE)
写在前面 安全测试fortify扫描接口项目代码,暴露出标题XXE的问题, 记录一下.官网链接: https://www.owasp.org/index.php/XML_External_Entity ...
- 使用ssh-keygen生成私钥和公钥
1.使用ssh-keygen生成私钥和公钥 命令如下: ssh-keygen -t rsassh-keygen -t rsa -C "用户名自取"可以是邮箱 例子: fdipzon ...
- java上传图片并压缩图片大小
Thumbnailator 是一个优秀的图片处理的Google开源Java类库.处理效果远比Java API的好.从API提供现有的图像文件和图像对象的类中简化了处理过程,两三行代码就能够从现有图片生 ...