pyspider 数据存入Mysql--Python3
一、不写入Mysql
以爬取哪儿网为例。
以下为脚本:
from pyspider.libs.base_handler import * class Handler(BaseHandler):
crawl_config = {
} @every(minutes=24 * 60)
def on_start(self):
self.crawl('https://travel.qunar.com/travelbook/list.htm', callback=self.index_page, validate_cert=False) @config(age=100 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('li > .tit > a').items():
self.crawl(each.attr.href, callback=self.detail_page, validate_cert=False, fetch_type='js')
next = response.doc('.next').attr.href
self.crawl(next, callback=self.index_page) @config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('#booktitle').text(),
"date": response.doc('.when .data').text(),
"day": response.doc('.howlong .data').text(),
"who": response.doc('.who .data').text(),
"text": response.doc('#b_panel_schedule').text(),
"image": response.doc('.cover_img').text(),
}
这个脚本里只是单纯的将结果打印在pyspider 的web ui中,并没有存到其它地方。
二、存入Mysql中
插入数据库的话,需要我们在调用它之前定义一个save_in_mysql函数。 并且需要将连接数据库等初始化放在__init__函数中。
注: pymysql.connect('localhost', '账号', '密码', '数据库', charset='utf8')
# 连接数据库
def __init__(self):
self.db = pymysql.connect('localhost', 'root', 'root', 'qunar', charset='utf8') def save_in_mysql(self, url, title, date, day, who, text, image):
try:
cursor = self.db.cursor()
sql = 'INSERT INTO qunar(url, title, date, day, who, text, image) \
VALUES (%s, %s , %s, %s, %s, %s, %s)' # 插入数据库的SQL语句
print(sql)
cursor.execute(sql, (url, title, date, day, who, text, image))
print(cursor.lastrowid)
self.db.commit()
except Exception as e:
print(e)
self.db.rollback()
然后在detail_page中调用save_in_mysql函数:
@config(priority=2)
def detail_page(self, response):
url = response.url
title = response.doc('title').text()
date = response.doc('.when .data').text()
day = response.doc('.howlong .data').text()
who = response.doc('.who .data').text()
text = response.doc('#b_panel_schedule').text()[0:100].replace('\"', '\'', 10)
image = response.doc('.cover_img').attr.src # 插入数据库
self.save_in_mysql(url, title, date, day, who, text, image)
return {
"url": response.url,
"title": response.doc('title').text(),
"date": response.doc('.when .data').text(),
"day": response.doc('.howlong .data').text(),
"who": response.doc('.who .data').text(),
"text": response.doc('#b_panel_schedule').text(),
"image": response.doc('.cover_img').attr.src
}
三、完整代码、数据库建设及运行结果 (代码可直接跑)
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2019-07-02 21:37:08
# Project: qunar from pyspider.libs.base_handler import *
import pymysql class Handler(BaseHandler):
crawl_config = {
} # 连接数据库
def __init__(self):
self.db = pymysql.connect('localhost', 'root', 'root', 'qunar', charset='utf8') def save_in_mysql(self, url, title, date, day, who, text, image):
try:
cursor = self.db.cursor()
sql = 'INSERT INTO qunar(url, title, date, day, who, text, image) \
VALUES (%s, %s , %s, %s, %s, %s, %s)' # 插入数据库的SQL语句
print(sql)
cursor.execute(sql, (url, title, date, day, who, text, image))
print(cursor.lastrowid)
self.db.commit()
except Exception as e:
print(e)
self.db.rollback() @every(minutes=24 * 60)
def on_start(self):
self.crawl('http://travel.qunar.com/travelbook/list.htm', callback=self.index_page) @config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('li > .tit > a').items():
self.crawl(each.attr.href, callback=self.detail_page, fetch_type='js')
next_url = response.doc('.next').attr.href
self.crawl(next_url, callback=self.index_page) @config(priority=2)
def detail_page(self, response):
url = response.url
title = response.doc('title').text()
date = response.doc('.when .data').text()
day = response.doc('.howlong .data').text()
who = response.doc('.who .data').text()
text = response.doc('#b_panel_schedule').text()[0:100].replace('\"', '\'', 10)
image = response.doc('.cover_img').attr.src # 存入数据库
self.save_in_mysql(url, title, date, day, who, text, image)
return {
"url": response.url,
"title": response.doc('title').text(),
"date": response.doc('.when .data').text(),
"day": response.doc('.howlong .data').text(),
"who": response.doc('.who .data').text(),
"text": response.doc('#b_panel_schedule').text(),
"image": response.doc('.cover_img').attr.src
}
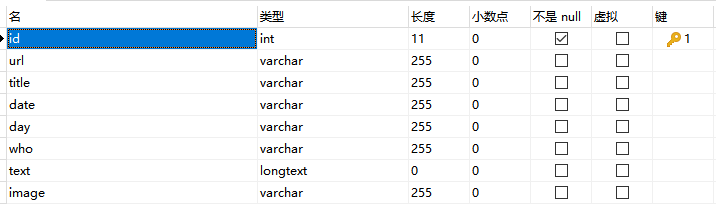
数据库建设:
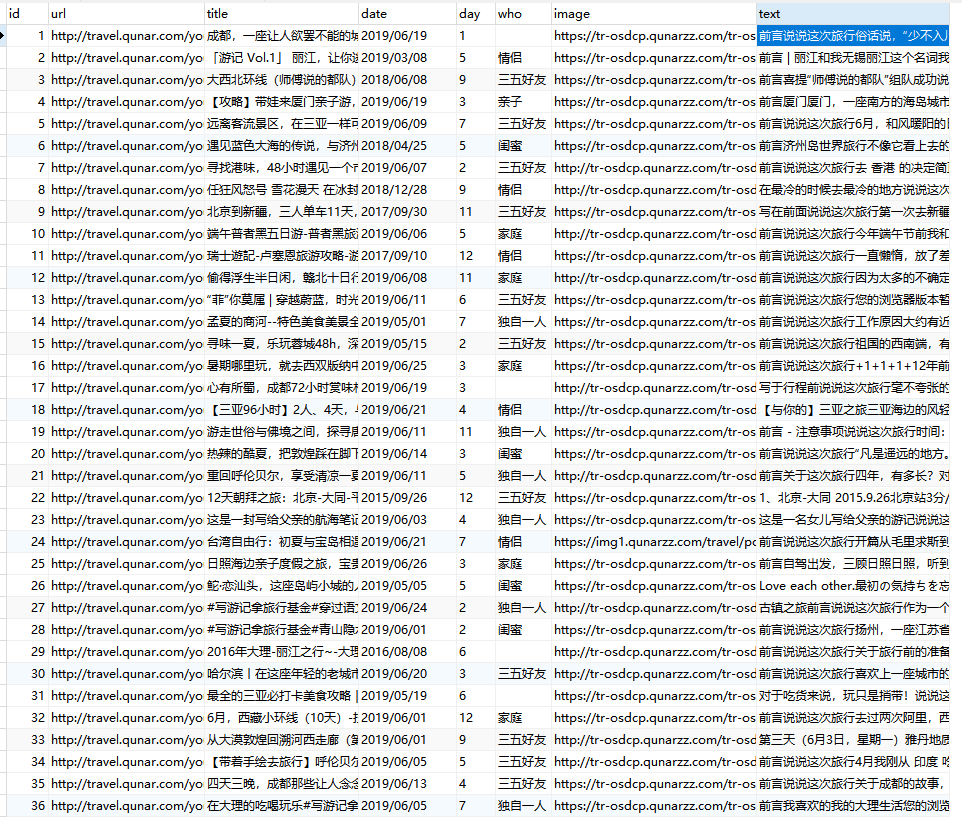
结果:
pyspider 数据存入Mysql--Python3的更多相关文章
- php+phpspreadsheet读取Excel数据存入mysql
先生成Excel模板,然后导入Excel数据到mysql,每条数据对应图片上传到阿里云 <?php /** * Created by PhpStorm. * User: Administrato ...
- Scrapy爬虫实例教程(二)---数据存入MySQL
书接上回 实例教程(一) 本文将详细描述使用scrapy爬去左岸读书所有文章并存入本地MySql数据库中,文中所有操作都是建立在scrapy已经配置完毕,并且系统中已经安装了Mysql数据库(有权限操 ...
- 关于mapreducer 读取hbase数据 存入mysql的实现过程
mapreducer编程模型是一种八股文的代码逻辑,就以用户行为分析求流存率的作为例子 1.map端来说:必须继承hadoop规定好的mapper类:在读取hbase数据时,已经有现成的接口 Tabl ...
- nodejs爬虫数据存入mysql
node爬虫主要用的是三个插件 request cheerio mysql 废话不多说直接上代码 const request=require("request") const ch ...
- web项目数据存入mysql数据库中文乱码问题
刚开始怀疑是项目中编码设置问题,发现在web.xml中已经有过设置:后来dubug显示数据在传输的过程中一切正常,怀疑是数据库编码问题,然后查看mysql编码: show variables like ...
- 【python 2.7】python读取json数据存入MySQL
同上一篇,只是适配 CentOS+ python 2.7 #python 2.7 # -*- coding:utf-8 -*- __author__ = 'BH8ANK' import json im ...
- 【python 3.6】python读取json数据存入MySQL(二)
在网上找到一个包含全国各省市经纬度的json文件,也可以通过上次的办法,解析json关键字,构造SQL语句,插入数据库. JSON文件格式如下: [ { "name": " ...
- 【python 3.6】python读取json数据存入MySQL(一)
整体思路: 1,读取json文件 2,将数据格式化为dict,取出key,创建数据库表头 3,取出dict的value,组装成sql语句,循环执行 4,执行SQL语句 #python 3.6 # -* ...
- 将数据存入mysql中
import pymysql import warnings # 忽略警告 warnings.filterwarnings("ignore") # 连接数据库 db = pymys ...
随机推荐
- C函数之index、strtoul
index函数 函数定义: #include<strings.h> char *index(const char *s, int c); 函数说明: 找出参数s字符串中第一个出现参数c的地 ...
- 新款戴尔笔记本win10系统改win7 安装教程
下载U盘启动制作工具 及戴尔DELL ghost win7 旗舰版GHO 文件 下载地址:http://pan.baidu.com/s/1c17JqpU 插入制作好的U盘启动盘,开机按F2进入BIO ...
- Java8中HashMap扩容算法小计
Java8的HashMap扩容过程主要就是集中在resize()方法中 final Node<K,V>[] resize() { // ...省略不重要的 } 其中,当HashMap扩容完 ...
- BigDecimal代码示例
在平常开发中,如果涉及到计算,要求准确的精度,比如单价*数量=总价之类的计算,那么得用到BigDecimal. 初始化 如下: BigDecimal amount=new BigDecimal(&qu ...
- 自顶向下深入分析Netty(六)--Channel总述
自顶向下深入分析Netty(六)--Channel总述 自顶向下深入分析Netty(六)--Channel源码实现 6.1 总述 6.1.1 Channel JDK中的Channel是通讯的载体,而N ...
- hinkphp项目部署到Linux服务器上报错“模板不存在”如何解决
检查了服务器上的文件,并没有缺少文件,再次上传文件到服务器,还是报错.莫名其妙,怀疑是代码问题. 仔细检查后,发现是模板的文件名问题: 用过TP的都知道:thinkphp会在$this->dis ...
- Shared variable in python's multiprocessing
Shared variable in python's multiprocessing https://www.programcreek.com/python/example/58176/multip ...
- Node.js 动态网页爬取 PhantomJS 使用入门(转)
Node.js 动态网页爬取 PhantomJS 使用入门 原创NeverSettle101 发布于2017-03-24 09:34:45 阅读数 8309 收藏 展开 版权声明:本文为 winte ...
- 运维笔记--Linux查找指定目录下包含某字符串的文件
待整理: 参考:http://blog.sina.com.cn/s/blog_53d496960102xg5c.html 例: find /home/logstash/ -type f | xargs ...
- win10 搜索栏输入后长期没反应
博客转载自:https://blog.csdn.net/qq_40875146/article/details/81742533 Get-AppXPackage -Name Microsoft.Win ...