Python数据分析--------numpy数据打乱
一、shuffle函数:
import numpy.random
def shuffleData(data):
np.random.shufflr(data)
cols=data.shape[1]
X=data[:,0:cols-1]
Y=data[:,cols-1:]
return X,Y
二、np.random.permutation()函数
这个函数的使用来随机排列一个数组的,
一维数组:

对多维数组来说,是多维随机打乱而不是1维,例如:

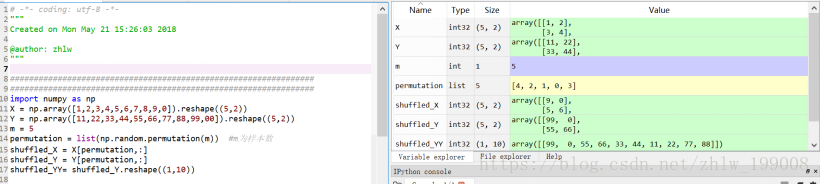
如果要利用次函数对输入数据X、Y进行随机排序,且要求随机排序后的X Y中的值保持原来的对应关系,可以这样处理:
permutation = list(np.random.permutation(m)) #m为样本数
shuffled_X = X[permutation]
shuffled_Y = Y[permutation].reshape((1,m))
图4中的代码是针对一维数组来说的,(图片中右侧为运行结果):

图5中的代码是针对二维数组来说的:
https://blog.csdn.net/zhlw_199008/article/details/80569167
三、sameple函数
sample()参数frac是要返回的比例,比如df中有10行数据,我只想返回其中的30%,那么frac=0.3
以下代码实现了从“CRASHSEV”中选出1,2,3,4的属性,乱序,然后取出前10000行,按行链接成新的数据,重建索引:
def unbanlance(un_data):
data1 = un_data.loc[(data["CRASHSEV"] == 1)].sample(frac=1).iloc[:10000, :]
data2 = un_data.loc[(data["CRASHSEV"] == 2)].sample(frac=1).iloc[:10000, :]
data3 = un_data.loc[(data["CRASHSEV"] == 3)].sample(frac=1).iloc[:10000, :]
data4 = un_data.loc[(data["CRASHSEV"] == 4)].sample(frac=1).iloc[:10000, :]
ba_data = pd.concat([data1,data2,data3,data4], axis=0).sample(frac=1).reset_index(drop=True) #0是按行链接
return ba_data
Python数据分析--------numpy数据打乱的更多相关文章
- Python数据分析-Numpy数值计算
Numpy介绍: NumPy是高性能科学计算和数据分析的基础包.它是pandas等其他各种工具的基础. NumPy的主要功能: 1)ndarray,一个多维数组结构,高效且节省空间 2)无需循环对整组 ...
- python数据分析笔记——数据加载与整理]
[ python数据分析笔记——数据加载与整理] https://mp.weixin.qq.com/s?__biz=MjM5MDM3Nzg0NA==&mid=2651588899&id ...
- python数据分析Numpy(二)
Numpy (Numerical Python) 高性能科学计算和数据分析的基础包: ndarray,多维数组(矩阵),具有矢量运算能力,快速.节省空间: 矩阵运算,无需循环,可以完成类似Matlab ...
- Python数据分析——numpy基础简介
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:基因学苑 NumPy(Numerical Python的简称)是高性 ...
- python 利用numpy同时打乱列表的顺序,同时打乱数据和标签的顺序
可用于网络训练打乱训练数据个标签,不改变对应关系 方法一: np.random.shuffle (无返回值,直接打乱原列表) state = np.random.get_state() np.rand ...
- Python数据分析--Numpy常用函数介绍(4)--Numpy中的线性关系和数据修剪压缩
摘要:总结股票均线计算原理--线性关系,也是以后大数据处理的基础之一,NumPy的 linalg 包是专门用于线性代数计算的.作一个假设,就是一个价格可以根据N个之前的价格利用线性模型计算得出. 前一 ...
- python 数据分析----numpy
NumPy是高性能科学计算和数据分析的基础包.它是pandas等其他各种工具的基础. NumPy的主要功能: ndarray,一个多维数组结构,高效且节省空间 无需循环对整组数据进行快速运算的数学函数 ...
- Python数据分析numpy库
1.简介 Numpy库是进行数据分析的基础库,panda库就是基于Numpy库的,在计算多维数组与大型数组方面使用最广,还提供多个函数操作起来效率也高 2.Numpy库的安装 linux(Ubuntu ...
- python数据分析 Numpy基础 数组和矢量计算
NumPy(Numerical Python的简称)是Python数值计算最重要的基础包.大多数提供科学计算的包都是用NumPy的数组作为构建基础. NumPy的部分功能如下: ndarray,一个具 ...
随机推荐
- App后台开发运维和架构实践学习总结(1)——App后台核心技术之用户验证方案
对于初学者来说,对Token和Session的使用难免会限于困境,开发过程中知道有这个东西,但却不知道为什么要用他?更不知道其原理,今天我就带大家一起分析分析这东西. 一.使用Token进行身份鉴权 ...
- 洛谷 P2056 BZOJ 2743 [HEOI2012]采花
//表示真的更喜欢洛谷的题面 题目描述 萧芸斓是 Z国的公主,平时的一大爱好是采花. 今天天气晴朗,阳光明媚,公主清晨便去了皇宫中新建的花园采花.花园足够大,容纳了 n 朵花,花有 c 种颜色(用整数 ...
- Welcome to the Real World
 Welcome to the Real World Gregor Hohpe EnginEERS liKE pRECiSion, especially software engineers who ...
- 手把手实现Java权限(1)-Shiro介绍
功能介绍 Authentication :身份认证/登录.验证用户是不是拥有对应的身份: Authorization :授权,即权限验证.验证某个已认证的用户是否拥有某个权限:即推断用 户能否做事 ...
- JVM基础(二) 实现自己的ClassLoader
为何要花时间实现自己的ClassLoader 尽管人生的乐趣非常大一部分来自于将时间花在有意思可是无意义的事情上,可是这件事绝对是有意思并且有意义的,有下面几个情景是值得我们花费时间实现自己的clas ...
- HDU 5355 Cake
HDU 5355 Cake 更新后的代码: 今天又一次做这道题的时候想了非常多种思路 最后最终想出了自觉得完美的思路,结果却超时 真的是感觉自己没救了 最后加了记忆化搜索,AC了 好了先说下思路吧.不 ...
- 【JNI探索之路系列】之七:JNI要点总结
作者:郭嘉 邮箱:allenwells@163.com 博客:http://blog.csdn.net/allenwells github:https://github.com/AllenWells ...
- MySQL数据库——索引与视图
索引 MySQL的索引包括普通索引.唯一性索引(unique index).全文索引(fulltext index).单列索引.多列索引和空间索引等. 1.索引的创建 ·创建表的时候创建索引 SQL语 ...
- 初识——Vim
有些东西吧,总是碰见,低头不见抬头见,但又不知道是什么.用来干嘛的?总是搞的心里痒痒.所以一定要学习一下. 近期一段时间,总是碰到一个词儿:VIM,在这儿看到了,我不理他,隔一会儿丫的又跑我眼睛里,总 ...
- [WebServer] Linux下Apache与Tomcat整合的简单方法
Apache与Tomcat比较联系 apache支持静态页,tomcat支持动态的,比如servlet等. 一般使用apache+tomcat的话,apache只是作为一个转发,对jsp的处理是由to ...