58.fetch phbase
1、fetch phbase工作流程
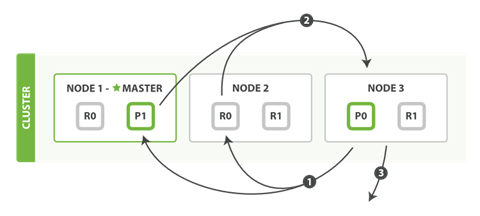
- The coordinating node identifies which documents need to be fetched and issues a multi GETrequest to the relevant shards.
- Each shard loads the documents and enriches them, if required, and then returns the documents to the coordinating node.
- Once all documents have been fetched, the coordinating node returns the results to the client.
The coordinating node first decides which documents actually need to be fetched. For instance, if our query specified { "from": 90, "size": 10 }, the first 90 results would be discarded and only the next 10 results would need to be retrieved. These documents may come from one, some, or all of the shards involved in the original search request.
The coordinating node builds a multi-get request for each shard that holds a pertinent document and sends the request to the same shard copy that handled the query phase.
The shard loads the document bodies—the _source field—and, if requested, enriches the results with metadata and search snippet highlighting. Once the coordinating node receives all results, it assembles them into a single response that it returns to the client.
(1)各个shard 返回的只是各文档的id和排序值( IDs and sort values ,coordinate node根据这些id&sort values 构建完priority queue之后,然后把程序需要的document 的id发送mget请求去所有shard上获取对应的document
(2)各个shard将document返回给coordinate node
(3)coordinate node将合并后的document结果返回给client客户端
2、一般搜索,如果不加from和size,就默认搜索前10条,按照_score排序
延伸阅读
The query-then-fetch process supports pagination with the from and size parameters, but within limits. Remember that each shard must build a priority queue of length from + size, all of which need to be passed back to the coordinating node. And the coordinating node needs to sort through number_of_shards * (from + size) documents in order to find the correct size documents.
Depending on the size of your documents, the number of shards, and the hardware you are using, paging 10,000 to 50,000 results (1,000 to 5,000 pages) deep should be perfectly doable. But with big-enough from values, the sorting process can become very heavy indeed, using vast amounts of CPU, memory, and bandwidth. For this reason, we strongly advise against deep paging.
In practice, "deep pagers" are seldom human anyway. A human will stop paging after two or three pages and will change the search criteria. The culprits are usually bots or web spiders that tirelessly keep fetching page after page until your servers crumble at the knees.
If you do need to fetch large numbers of docs from your cluster, you can do so efficiently by disabling sorting with the scroll query, which we discuss later in this chapter.
58.fetch phbase的更多相关文章
- ES--06
第51.初识搜索引擎_上机动手实战多搜索条件组合查询 课程大纲 GET /website/article/_search{ "query": { "bool": ...
- Swift - 后台获取数据(Background Fetch)的实现
前面讲了如何让程序申请后台短时运行.但这个额外延长的时间毕竟有限.所以从iOS7起又引入两种在后台运行任务的方式:后台获取和后台通知. 1,后台获取介绍 后台获取(Background Fetch)是 ...
- FW: How to use Hibernate Lazy Fetch and Eager Fetch Type – Spring Boot + MySQL
原帖 https://grokonez.com/hibernate/use-hibernate-lazy-fetch-eager-fetch-type-spring-boot-mysql In the ...
- python 读写西门子PLC 包含S7协议和Fetch/Write协议,s7支持200smart,300PLC,1200PLC,1500PLC
本文将使用一个gitHub开源的组件技术来读写西门子plc数据,使用的是基于以太网的TCP/IP实现,不需要额外的组件,读取操作只要放到后台线程就不会卡死线程,本组件支持超级方便的高性能读写操作 nu ...
- kafka启动失败错误:: replica.fetch.max.bytes should be equal or greater than message.max.bytes
1 详细异常 2019-10-14 14:38:21,260 FATAL kafka.Kafka$: java.lang.IllegalArgumentException: requirement f ...
- Git 少用 Pull 多用 Fetch 和 Merge
本文有点长而且有点乱,但就像Mark Twain Blaise Pascal的笑话里说的那样:我没有时间让它更短些.在Git的邮件列表里有很多关于本文的讨论,我会尽量把其中相关的观点列在下面. 我最常 ...
- git提示:Fatal:could not fetch refs from ....
在git服务器上新建项目提示: Fatal:could not fetch refs from git..... 百度搜索毫无头绪,最后FQgoogle,找到这篇文章http://www.voidcn ...
- sublime 插件推荐: Nettuts+ Fetch
Nettuts+ Fetch github地址:Nettuts-Fetch 在sublime中直接用 ctrl+shift+P -> pci -> Nettuts-Fetch 即可下载 这 ...
- git pull和git fetch的区别
Git中从远程的分支获取最新的版本到本地有这样2个命令:1. git fetch:相当于是从远程获取最新版本到本地,不会自动merge Git fetch origin master git log ...
随机推荐
- UpMarqueeTextView-模仿淘宝client向上滚动的广告条
UpMarqueeTextView一个简单的向上滚动的相似跑马灯效果,项目中用到的时候是接受到推送过来的消息向上滚动一次.没有做动态的gif效果,所以都是一些纯文字的简单记录. UpMarqueeTe ...
- linux面试之--堆、栈、自由存储区、全局/静态存储区和常量存储区
栈,就是那些由编译器在须要的时候分配,在不须要的时候自己主动清除的变量的存储区.里面的变量一般是局部变量.函数參数等.在一个进程中.位于用户虚拟地址空间顶部的是用户栈,编译器用它来实现函数的调用.和堆 ...
- 冒泡排序Vs直接选择排序
什么是排序?为什么要使用排序?事实上我们生活中处处都用到了排序.拿字典来说,如今,我们要在字典中查找某个字(已经知道这个字的读音),首先.我们须要依据这个字的读音,找到它所所在文件夹中的位置,然后依据 ...
- boost库生成文件命名和编译
生成文件命名规则:boost中有许多库,有的库需要编译.而有的库不需要编译,只需包含头文件就可以使用.编译生成的文件名字普遍较长,同一个库根据编译链接选项不同,又可以生成多个不同名字的文件.生成的文件 ...
- ECharts-热力图实例
1.引入echarts.js 2.页面js代码 //用ajax获取所需要的json数据 $.get("../../../mall/queryPageWtSrPost.do", { ...
- 关于sklearn中的导包交叉验证问题
机器学习sklearn中的检查验证模块: 原版本导包: from sklearn.cross_validation import cross_val_score 导包报错: 模块继承在cross_va ...
- LocalDateTime相关处理,得到零点以及24点值,最近五分钟点位,与Date互转,时间格式
最近一直使用LocalDateTime,老是忘记怎么转换,仅此记录一下 import java.time.Instant; import java.time.LocalDateTime; import ...
- POJ 1330 Tarjan LCA、ST表(其实可以数组模拟)
题意:给你一棵树,求两个点的最近公共祖先. 思路:因为只有一组询问,直接数组模拟好了. (写得比较乱) 原题请戳这里 #include <cstdio> #include <bits ...
- ViewPager PagerAdapter 的使用
1: 目的,实现全屏滑动的效果 2:类似于BaseAdapter public class MyPagerAdapter extends PagerAdapter { private Context ...
- System.DateTime.Now 24小时制。
this.Label6.Text = "当前时间:" + System.DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss") ...