集成算法——Ensemble learning
目的:让机器学习效果更好,单个不行,群殴啊!
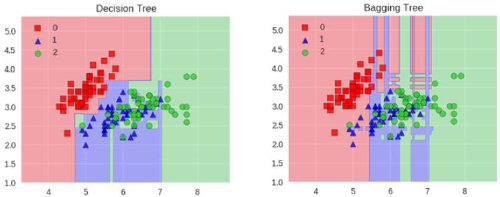
Bagging:训练多个分类器取平均
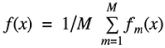
Boosting:从弱学习器开始加强,通过加权来进行训练

(加入一棵树,比原来要强)
Stacking:聚合多个分类或回归模型(可以分阶段来做)
bagging模型
全称:bootstrap aggregation(说白了就是并行训练一堆分类器)
最典型代表:随机森林
随机:数据采样随机,特征选择随机
森林:很多个决策树并行放在一起
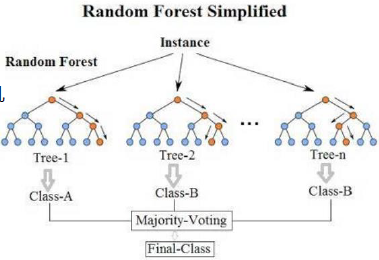
构造树模型
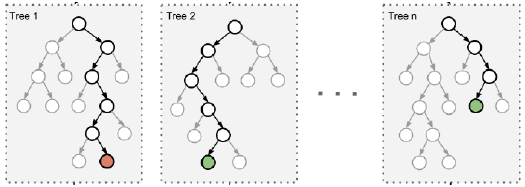
由于二重随机性,使得每个树基本上都不会一样,最终的结果也会不一样。
树模型:
之所以要进行随机,是要保证泛化能力,如果树都一样,就没有意义了。
随机森林优势
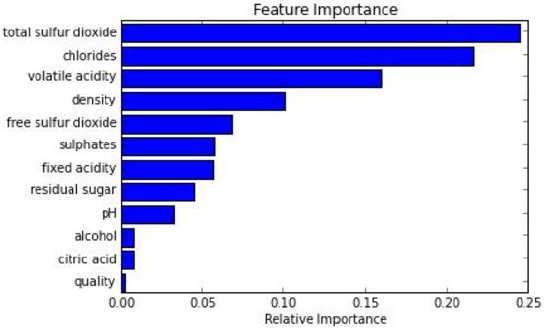
能够处理很高维度(feature很多)的数据,并且不用做特征选择
在训练完后,它能够给出哪些feature比较重要
容易做成并行化方法,速度比较快
可以进行可视化展示,便于分析
KNN模型
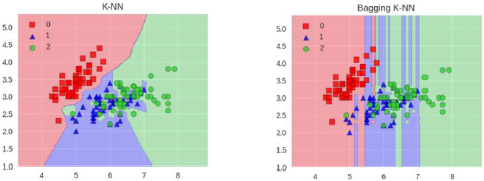
KNN就不太适合,因为很难去随机让泛化能力变强!
树模型
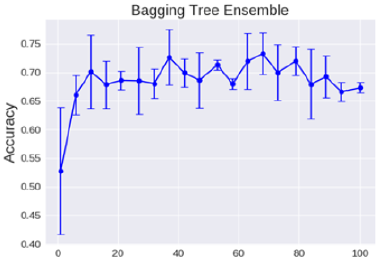
理论上越多的树效果会越好,但实际上基本超过一定数量就差不多上下浮动了。
Boosting模型
典型代表:AdaBoost,Xgboost
Adaboost会根据前一次的分类效果调整数据权重
如果某一个数据在这次分错了,那么在下一次就会给它更大的权重
最终结果:每个分类器根据自身的准确性来确定各自的权重,再合体
Adaboost工作流程
每一次切一刀
最终合在一起
弱分类器就升级了
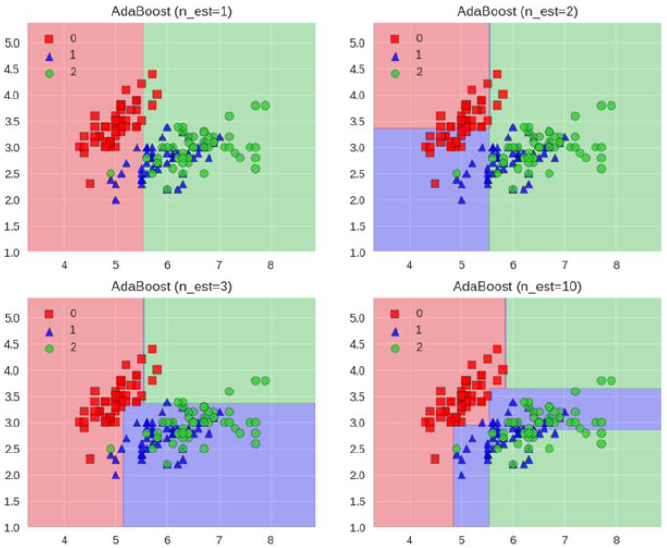
Stacking模型
堆叠:很暴力,拿来一堆直接上(各种分类器都来了)
可以堆叠各种各样的分类器(KNN,SVM,RF等等)
分阶段:第一阶段得出各自结果,第二阶段再用前一阶段结果训练
为了刷结果,不择手段!
堆叠在一起确实能使得准确率提升,但是速度是个问题
集成算法是竞赛与论文神器,当我们更关注与结果时不妨试试!
集成算法——Ensemble learning的更多相关文章
- 【Supervised Learning】 集成学习Ensemble Learning & Boosting 算法(python实现)
零. Introduction 1.learn over a subset of data choose the subset uniformally randomly (均匀随机地选择子集) app ...
- 笔记︱集成学习Ensemble Learning与树模型、Bagging 和 Boosting
本杂记摘录自文章<开发 | 为什么说集成学习模型是金融风控新的杀手锏?> 基本内容与分类见上述思维导图. . . 一.机器学习元算法 随机森林:决策树+bagging=随机森林 梯度提升树 ...
- 【软件分析与挖掘】Multiple kernel ensemble learning for software defect prediction
摘要: 利用软件中的历史缺陷数据来建立分类器,进行软件缺陷的检测. 多核学习(Multiple kernel learning):把历史缺陷数据映射到高维特征空间,使得数据能够更好地表达: 集成学习( ...
- 6. 集成学习(Ensemble Learning)算法比较
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- 第七章——集成学习和随机森林(Ensemble Learning and Random Forests)
俗话说,三个臭皮匠顶个诸葛亮.类似的,如果集成一系列分类器的预测结果,也将会得到由于单个预测期的预测结果.一组预测期称为一个集合(ensemble),因此这一技术被称为集成学习(Ensemble Le ...
- 7. 集成学习(Ensemble Learning)Stacking
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- 5. 集成学习(Ensemble Learning)GBDT
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- 3. 集成学习(Ensemble Learning)随机森林(Random Forest)
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- 4. 集成学习(Ensemble Learning)Adaboost
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
随机推荐
- 微信小程序制作家庭记账本之七
最后一天,程序完成的仍然不是很好,作品很简陋,不过还是可以记账的,没有购买域名,别人无法使用,下次我会完成的更好.
- nextjs 服务端渲染请求参数
Post.getInitialProps = async function (context) { const { id } = context.query const res = await fet ...
- usdt钱包开发,比特币协议 Omni 层协议 USDT
usdt钱包开发 比特币协议 -> Omni 层协议 -> USDT USDT是基于比特币omni协议的一种代币: https://omniexplorer.info/asset/31 I ...
- How to install john deere service advisor 4.2.005 on win 10 64bit
How to install john deere service advisor 4.2.005 with the February 2016 data base disks on a machin ...
- 每日linux命令学习-sed
Linux的文本处理实用工具主要由sed和awk命令,二者虽然略有差异,但都使用正则表达式,默认使用标准I/O,并且使用管道命令可以将前一个命令的输出作为下一个命令的输入.笔者将在本节学习sed命令. ...
- JOBDU 题目1100:最短路径
时间限制:1 秒 内存限制:32 兆 特殊判题:否 提交:5786 解决:902 题目描述: N个城市,标号从0到N-1,M条道路,第K条道路(K从0开始)的长度为2^K,求编号为0的城市到其他城市的 ...
- TensorFlow练习24: GANs-生成对抗网络 (生成明星脸)
http://blog.topspeedsnail.com/archives/10977 从2D图片生成3D模型(3D-GAN) https://blog.csdn.net/u014365862/ar ...
- JDK源码之HashSet
1.定义 HashSet继承AbstractSet类,实现Set,Cloneable,Serializable接口.Set 接口是一种不包括重复元素的 Collection,它维持它自己的内部排序,所 ...
- Golang的值类型和引用类型的范围、存储区域、区别
常见的值类型和引用类型分别有哪些? 值类型:基本数据类型 int 系列, float 系列, bool, string .数组和结构体struct,使用这些类型的变量直接指向存在内存中的值,值类型的变 ...
- Django XSS攻击
Django XSS攻击 XSS(cross-site scripting跨域脚本攻击)攻击是最常见的web攻击,其特点是“跨域”和“客户端执行”,XSS攻击分为三种: Reflected XSS(基 ...