集成算法——Ensemble learning
目的:让机器学习效果更好,单个不行,群殴啊!
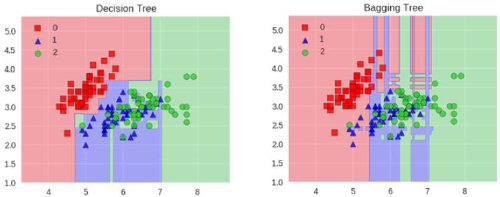
Bagging:训练多个分类器取平均
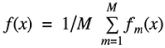
Boosting:从弱学习器开始加强,通过加权来进行训练

(加入一棵树,比原来要强)
Stacking:聚合多个分类或回归模型(可以分阶段来做)
bagging模型
全称:bootstrap aggregation(说白了就是并行训练一堆分类器)
最典型代表:随机森林
随机:数据采样随机,特征选择随机
森林:很多个决策树并行放在一起
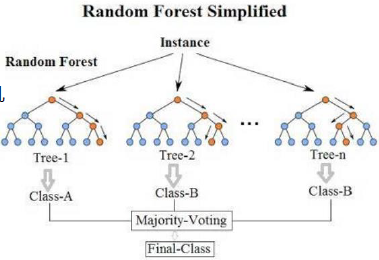
构造树模型
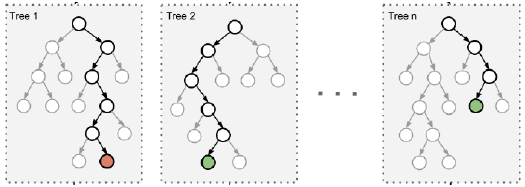
由于二重随机性,使得每个树基本上都不会一样,最终的结果也会不一样。
树模型:
之所以要进行随机,是要保证泛化能力,如果树都一样,就没有意义了。
随机森林优势
能够处理很高维度(feature很多)的数据,并且不用做特征选择
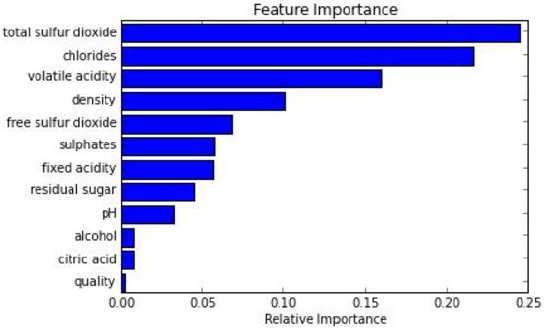
在训练完后,它能够给出哪些feature比较重要
容易做成并行化方法,速度比较快
可以进行可视化展示,便于分析
KNN模型
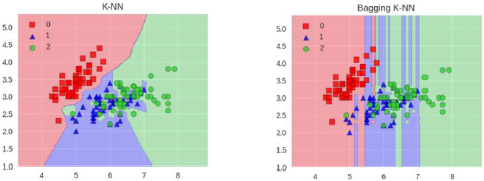
KNN就不太适合,因为很难去随机让泛化能力变强!
树模型
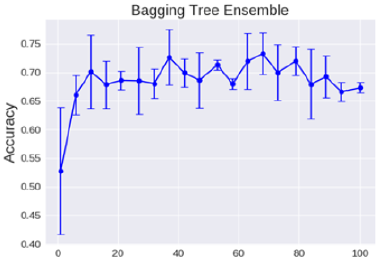
理论上越多的树效果会越好,但实际上基本超过一定数量就差不多上下浮动了。
Boosting模型
典型代表:AdaBoost,Xgboost
Adaboost会根据前一次的分类效果调整数据权重
如果某一个数据在这次分错了,那么在下一次就会给它更大的权重
最终结果:每个分类器根据自身的准确性来确定各自的权重,再合体
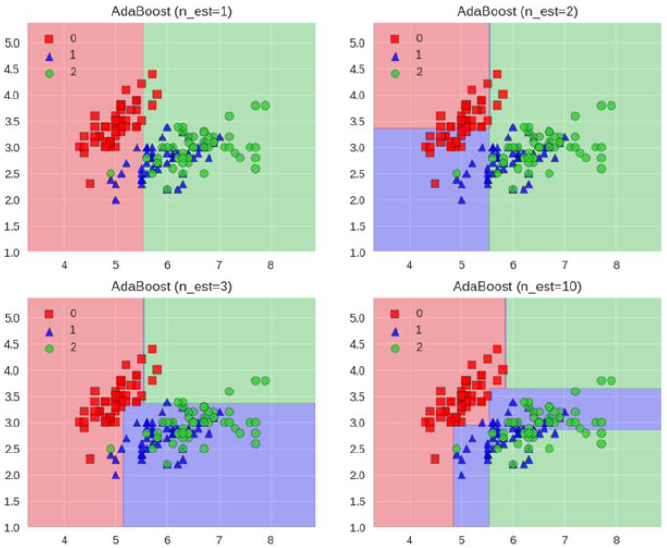
Adaboost工作流程
每一次切一刀
最终合在一起
弱分类器就升级了
Stacking模型
堆叠:很暴力,拿来一堆直接上(各种分类器都来了)
可以堆叠各种各样的分类器(KNN,SVM,RF等等)
分阶段:第一阶段得出各自结果,第二阶段再用前一阶段结果训练
为了刷结果,不择手段!
堆叠在一起确实能使得准确率提升,但是速度是个问题
集成算法是竞赛与论文神器,当我们更关注与结果时不妨试试!
集成算法——Ensemble learning的更多相关文章
- 【Supervised Learning】 集成学习Ensemble Learning & Boosting 算法(python实现)
零. Introduction 1.learn over a subset of data choose the subset uniformally randomly (均匀随机地选择子集) app ...
- 笔记︱集成学习Ensemble Learning与树模型、Bagging 和 Boosting
本杂记摘录自文章<开发 | 为什么说集成学习模型是金融风控新的杀手锏?> 基本内容与分类见上述思维导图. . . 一.机器学习元算法 随机森林:决策树+bagging=随机森林 梯度提升树 ...
- 【软件分析与挖掘】Multiple kernel ensemble learning for software defect prediction
摘要: 利用软件中的历史缺陷数据来建立分类器,进行软件缺陷的检测. 多核学习(Multiple kernel learning):把历史缺陷数据映射到高维特征空间,使得数据能够更好地表达: 集成学习( ...
- 6. 集成学习(Ensemble Learning)算法比较
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- 第七章——集成学习和随机森林(Ensemble Learning and Random Forests)
俗话说,三个臭皮匠顶个诸葛亮.类似的,如果集成一系列分类器的预测结果,也将会得到由于单个预测期的预测结果.一组预测期称为一个集合(ensemble),因此这一技术被称为集成学习(Ensemble Le ...
- 7. 集成学习(Ensemble Learning)Stacking
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- 5. 集成学习(Ensemble Learning)GBDT
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- 3. 集成学习(Ensemble Learning)随机森林(Random Forest)
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- 4. 集成学习(Ensemble Learning)Adaboost
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
随机推荐
- DataX介绍
一. DataX3.0概览 DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL.Oracle等).HDFS.Hive.ODPS.HBase.FTP等各种异构数据源之间稳定 ...
- Linux基础命令---arp
arp arp指令用来管理系统的arp缓冲区,可以显示.删除.添加静态mac地址.ARP以各种方式操纵内核的ARP缓存.主要选项是清除地址映射项并手动设置.为了调试目的,ARP程序还允许对ARP缓存进 ...
- API gateway 之 kong 安装
kong安装: https://getkong.org/install/centos/ 下载指定版本rpm: wget https://bintray.com/kong/kong-community- ...
- 运行tomcat报Exception in thread "ContainerBackgroundProcessor[StandardEngine[Catalina]]"
解决方法1: 手动设置MaxPermSize大小,如果是linux系统,修改TOMCAT_HOME/bin/catalina.sh,如果是windows系统,修改TOMCAT_HOME/bin/c ...
- 计算概论(A)/基础编程练习(数据成分)/1:短信计费
#include<stdio.h> int main() { // 输入当月发送短信的总次数n和每次短信的字数words int n,words; scanf("%d" ...
- Spring MVC数据绑定
1.绑定默认数据类型 当前端请求参数较为简单的时候,后台形参可以直接使用SpringMVC提供的参数类型来绑定数据. HttpServletRequest:通过request对象获取请求信息: Htt ...
- PKUWC2018 5/6
总结: D1T1T2的思路较为好想,D1T3考试时估计是战略放弃的对象,D2T1思路容易卡在优化状态上(虽然明显3n的状态中有很多无用状态,从而想到子集最优,选择子集最优容易发现反例,从而考虑连带周边 ...
- window apidoc的安装和使用
apidoc是一个轻量级的在线REST接口文档生成系统,支持多种主流语言,包括Java.C.C#.PHP和Javascript等.使用者仅需要按照要求书写相关注释,就可以生成可读性好.界面美观的在线接 ...
- Strom学习笔记2:Storm Maven Project-StromStack工程
1:IntelliJ新建Maven工程
- ReentrantLock$Sync.tryRelease java.lang.IllegalMonitorStateException
早上一来,例行性的看主要环境的运行情况,发现有个环境中有如下异常: 17-02-28 08:13:37.368 ERROR pool-2-thread-65 com.ld.net.spider.Spi ...