failed to launch: nice -n 0 /home/hadoop/spark-2.3.3-bin-hadoop2.7/bin/spark-class org.apache.spark.deploy.worker.Worker --webui-port 8081 spark://namenode1:7077
spark2.3.3安装完成之后启动报错:
[hadoop@namenode1 sbin]$ ./start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /home/hadoop/spark-2.3.3-bin-hadoop2.7/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-namenode1.out
datanode2: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/spark-2.3.3-bin-hadoop2.7/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-datanode2.out
datanode3: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/spark-2.3.3-bin-hadoop2.7/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-datanode3.out
datanode1: starting org.apache.spark.deploy.worker.Worker, logging to /home/hadoop/spark-2.3.3-bin-hadoop2.7/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-datanode1.out
datanode1: failed to launch: nice -n 0 /home/hadoop/spark-2.3.3-bin-hadoop2.7/bin/spark-class org.apache.spark.deploy.worker.Worker --webui-port 8081 spark://namenode1:7077
datanode1: Spark Command: /usr/java/jdk1.8.0_111/bin/java -cp /home/hadoop/spark-2.3.3-bin-hadoop2.7/conf/:/home/hadoop/spark-2.3.3-bin-hadoop2.7/jars/* -Xmx1g org.apache.spark.deploy.worker.Worker --webui-port 8081 spark://namenode1:7077
datanode1: ========================================
datanode1: full log in /home/hadoop/spark-2.3.3-bin-hadoop2.7/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-datanode1.out
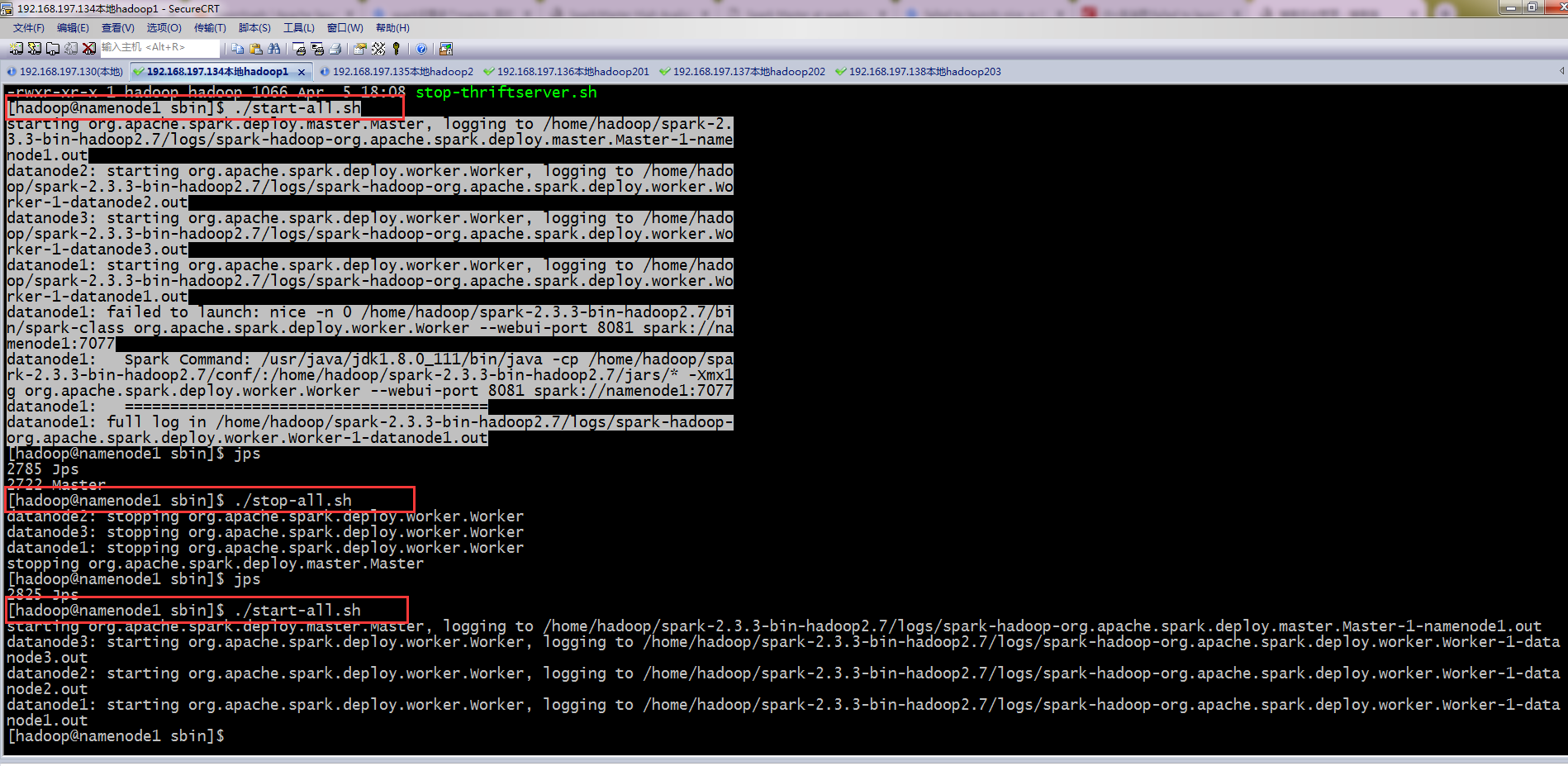
提示说完整的日志路径在哪里,用cat +路径的形式去查看,没有错误,只有警告,我选择stop-all然后重启,通常第二遍启动正常。
failed to launch: nice -n 0 /home/hadoop/spark-2.3.3-bin-hadoop2.7/bin/spark-class org.apache.spark.deploy.worker.Worker --webui-port 8081 spark://namenode1:7077的更多相关文章
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(四)针对hadoop2.9.0启动执行start-all.sh出现异常:failed to launch: nice -n 0 /bin/spark-class org.apache.spark.deploy.worker.Worker
启动问题: 执行start-all.sh出现以下异常信息: failed to launch: nice -n 0 /bin/spark-class org.apache.spark.deploy.w ...
- caffe 训练时,出现错误:Check failed: error == cudaSuccess (4 vs. 0) unspecified launch failure
I0415 15:03:37.603461 27311 solver.cpp:42] Solver scaffolding done.I0415 15:03:37.603549 27311 solve ...
- Hadoop - 操作练习之单机配置 - Hadoop2.8.0/Ubuntu16.04
系统版本 anliven@Ubuntu1604:~$ uname -a Linux Ubuntu1604 4.8.0-36-generic #36~16.04.1-Ubuntu SMP Sun Feb ...
- This server is in the failed servers list: localhost/127.0.0.1:16000 启动hbase api调用错误
api 调用发现错误 Mon Nov 18 23:04:31 CST 2019, RpcRetryingCaller{globalStartTime=1574089469858, pause=100, ...
- MongoDB 由于目标计算机积极拒绝,无法连接 2014-07-25T11:00:48.634+0800 warning: Failed to connect to 127.0.0.1:27017, reason: errno:10061
转载自:http://www.cnblogs.com/xiaoit/p/3867573.html 1:启动MongoDB 2014-07-25T11:00:48.634+0800 warning: F ...
- Spring Boot + Bootstrap 出现"Failed to decode downloaded font"和"OTS parsing error: Failed to convert WOFF 2.0 font to SFNT"
准确来讲,应该是maven项目使用Bootstrap时,出现 "Failed to decode downloaded font"和"OTS parsing error: ...
- 【MongoDB】2014-07-25T11:00:48.634+0800 warning: Failed to connect to 127.0.0.1:27017, reason: errno:10061 由于目标计算机积极拒绝,无法连接。
1:启动MongoDB 2014-07-25T11:00:48.634+0800 warning: Failed to connect to 127.0.0.1:27017, reason: errn ...
- Hadoop 新生报道(二) hadoop2.6.0 集群系统版本安装和启动配置
本次基于Hadoop2.6版本进行分布式配置,Linux系统是基于CentOS6.5 64位的版本.在此设置一个主节点和两个从节点. 准备3台虚拟机,分别为: 主机名 IP地址 master 192. ...
- Hadoop新生报到(一) hadoop2.6.0伪分布式配置详解
首先先不看理论,搭建起环境之后再看: 搭建伪分布式是为了模拟环境,调试方便. 电脑是win10,用的虚拟机VMware Workstation 12 Pro,跑的Linux系统是centos6.5 , ...
随机推荐
- CH3B04 Xiao 9*大战朱最学
题意 3B04 Xiao 9*大战朱最学 0x3B「数学知识」练习 背景 Xiao 9*.朱最学.小全同属LOI,朱某某同学由于学习认真得到了小全的仰慕~~送其外号---朱最学.最学想:神牛我当不成难 ...
- 推荐一些好的linux学习网站
菜鸟教程:这个网站有jsp,php,c,android等等入门教程,很适合入门的新手和想多学一门语言的人 传送门http://www.runoob.com/ linux命令那么多,怎么记,给一个lin ...
- scanf() gets() fgets()使用注意事项
1.scanf() 遇到'\n'停止从输入缓冲区中接收,接收完后‘\n’还存在于缓冲区中.当输入的字符数少于缓冲区大小时,字符后面有自动补上‘\0’,当输入字符大于缓冲区时,也直接拷贝到缓冲中,因此缓 ...
- skipper lua 脚本支持
skipper 对于lua 脚本的支持是通过gopher-lua,支持基本上大部分的lua特性 说明:项目使用docker-compose 运行 环境准备 docker-compose 文件 vers ...
- 普林斯顿数学指南(第一卷) (Timothy Gowers 著)
第I部分 引论 I.1 数学是做什么的 I.2 数学的语言和语法 I.3 一些基本的数学定义 I.4 数学研究的一般目的 第II部分 现代数学的起源 II.1 从数到数系 II.2 几何学 II.3 ...
- Distributed processing
Distributed processing Tool 好处 坏处 类型 支持序列化 支持根据负载动态调度任务 支持c 支持dependency的调度 有成熟的library Actor model ...
- yum和编译两种方式升级or降级Centos内核
http://blog.51cto.com/renzhiyuan/1882599 今天探讨用yum和编译两种方式升级或者降级内核版本: 升级:比如玩kvm,docker等虚拟化,centos内核则升级 ...
- pyquery的使用
常用的三种初始化方法: 1.字符串初始化: from pyquery import PyQuery as pq html=""" <html> <hea ...
- Jmeter JDBC Request--测试数据库连接 拒绝解决方案
有时会遇到回应信息如下: 1 Cannot create PoolableConnectionFactory (Access denied for user 'root'@'10.0.1.23' (u ...
- 用Shell判断字符串包含关系的方法小结
这篇文章主要给大家介绍了关于用Shell判断字符串包含关系的几种方法,其中包括利用grep查找.利用字符串运算符.利用通配符.利用case in 语句以及利用替换等方法,每个方法都给出了详细的示例代 ...